
 Technology peripheralsAIThe world model also spreads! The trained agent turns out to be pretty good
Technology peripheralsAIThe world model also spreads! The trained agent turns out to be pretty goodThe world model also spreads! The trained agent turns out to be pretty good

World models provide a way to train reinforcement learning agents in a safe and sample-efficient manner. Recently, world models have mainly operated on discrete latent variable sequences to simulate environmental dynamics.
However, this method of compressing into compact discrete representations may ignore visual details that are important for reinforcement learning. On the other hand, diffusion models have become the dominant method for image generation, posing challenges to discrete latent models.
To promote this paradigm shift, researchers from the University of Geneva, the University of Edinburgh, and Microsoft Research jointly proposed a reinforcement learning agent trained in a diffuse world model—DIAMOND (DIffusion As a Model Of eNvironment Dreams).

- ##Paper address: https://arxiv .org/abs/2405.12399
- Project address: https://github.com/eloialonso/diamond
- Paper title: Diffusion for World Modeling: Visual Details Matter in Atari
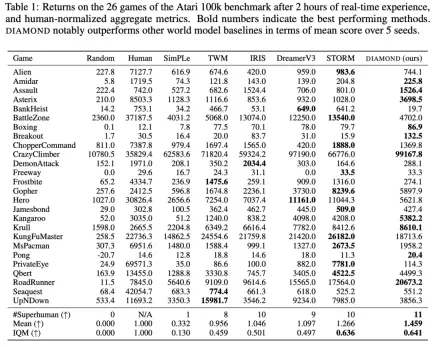
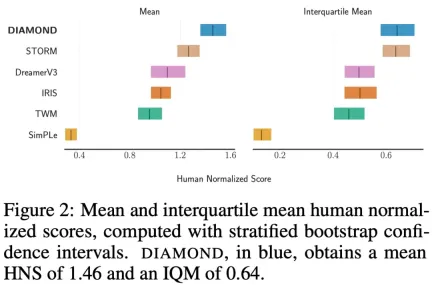
In the Atari 100k benchmark, DIAMOND+ achieved an average Human Normalized Score (HNS) of 1.46. This means that an agent trained in the world model can be fully trained at the SOTA level of an agent trained in the world model. This study provides a stability analysis to illustrate that DIAMOND design choices are necessary to ensure the long-term efficient stability of the diffusive world model.
In addition to the benefit of operating in image space, it enables the diffuse world model to become a direct representation of the environment, thus providing a deeper understanding of the world model and agent behavior. In particular, the study found that performance improvements in certain games result from better modeling of key visual details.
Method Introduction
Next, this article introduces DIAMOND, a reinforcement learning agent trained in a diffusion world model. Specifically, we base this on the drift and diffusion coefficients f and g introduced in Section 2.2, which correspond to a specific choice of diffusion paradigm. Furthermore, this study also chose the EDM formulation based on Karras et al.
First define a disturbance kernel, , where  is a real-valued function related to the diffusion time, called the noise schedule. This corresponds to setting the drift and diffusion coefficients to
is a real-valued function related to the diffusion time, called the noise schedule. This corresponds to setting the drift and diffusion coefficients to  and
and  .
. 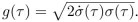
Then use the network preprocessing introduced by Karras et al. (2022), and parameterize in formula (5) as noise observations and neural network predictions Weighted sum of values: 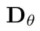
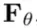
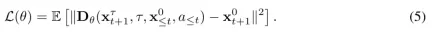
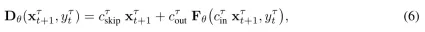
includes all condition variables. 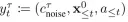
Preprocessor selection. Choose preprocessors  and
and  to maintain unit variance of network inputs and outputs at any noise level
to maintain unit variance of network inputs and outputs at any noise level  .
.  is the empirical conversion of noise level,
is the empirical conversion of noise level,  is given by
is given by  and the standard deviation of the data distribution
and the standard deviation of the data distribution  , the formula is
, the formula is 
Combined with formula 5 and 6. Get the  training target:
training target:

##This study uses standard U-Net 2D to construct the vector field, and retain a buffer containing the past L observations and actions to condition the model. Next they concatenated these past observations channel-wise with the next noisy observation and fed the actions into the residual block of U-Net via an adaptive group normalization layer. As discussed in Section 2.3 and Appendix A, there are many possible sampling methods to generate the next observation from a trained diffusion model. While the code base released by the study supports multiple sampling schemes, the study found that Euler methods are effective without requiring additional NFE (number of function evaluations) and avoiding the unnecessary complexity of higher-order samplers or random sampling. Effective. 
Experiment
To fully evaluate DIAMOND, the study used the well-established Atari 100k benchmark, which included 26 games, using For testing the broad capabilities of an agent. For each game, the agent was only allowed 100k actions in the environment, which is roughly equivalent to 2 hours of human game time, to learn to play the game before being evaluated. For reference, an Atari agent without constraints is typically trained for 50 million steps, which corresponds to a 500-fold increase in experience. The researchers trained DIAMOND from scratch on each game using 5 random seeds. Each run used approximately 12GB of VRAM and took approximately 2.9 days on a single Nvidia RTX 4090 (1.03 GPU years total).
Table 1 compares different scores for training agents on the world model:
In order to study the stability of diffusion variables, this study analyzed the imagined trajectory generated by autoregression, as shown in Figure 3 below:
The study found that some situations require an iterative solver to drive the sampling process to a specific mode, such as the boxing game shown in Figure 4:

As shown in Figure 5, compared with the trajectories imagined by IRIS, the trajectories imagined by DIAMOND generally have higher visual quality and are more consistent with the real environment.

Interested readers can read the original text of the paper to learn more about the research content.
The above is the detailed content of The world model also spreads! The trained agent turns out to be pretty good. For more information, please follow other related articles on the PHP Chinese website!

 The Hidden Dangers Of AI Internal Deployment: Governance Gaps And Catastrophic RisksApr 28, 2025 am 11:12 AM
The Hidden Dangers Of AI Internal Deployment: Governance Gaps And Catastrophic RisksApr 28, 2025 am 11:12 AMThe unchecked internal deployment of advanced AI systems poses significant risks, according to a new report from Apollo Research. This lack of oversight, prevalent among major AI firms, allows for potential catastrophic outcomes, ranging from uncont
 Building The AI PolygraphApr 28, 2025 am 11:11 AM
Building The AI PolygraphApr 28, 2025 am 11:11 AMTraditional lie detectors are outdated. Relying on the pointer connected by the wristband, a lie detector that prints out the subject's vital signs and physical reactions is not accurate in identifying lies. This is why lie detection results are not usually adopted by the court, although it has led to many innocent people being jailed. In contrast, artificial intelligence is a powerful data engine, and its working principle is to observe all aspects. This means that scientists can apply artificial intelligence to applications seeking truth through a variety of ways. One approach is to analyze the vital sign responses of the person being interrogated like a lie detector, but with a more detailed and precise comparative analysis. Another approach is to use linguistic markup to analyze what people actually say and use logic and reasoning. As the saying goes, one lie breeds another lie, and eventually
 Is AI Cleared For Takeoff In The Aerospace Industry?Apr 28, 2025 am 11:10 AM
Is AI Cleared For Takeoff In The Aerospace Industry?Apr 28, 2025 am 11:10 AMThe aerospace industry, a pioneer of innovation, is leveraging AI to tackle its most intricate challenges. Modern aviation's increasing complexity necessitates AI's automation and real-time intelligence capabilities for enhanced safety, reduced oper
 Watching Beijing's Spring Robot RaceApr 28, 2025 am 11:09 AM
Watching Beijing's Spring Robot RaceApr 28, 2025 am 11:09 AMThe rapid development of robotics has brought us a fascinating case study. The N2 robot from Noetix weighs over 40 pounds and is 3 feet tall and is said to be able to backflip. Unitree's G1 robot weighs about twice the size of the N2 and is about 4 feet tall. There are also many smaller humanoid robots participating in the competition, and there is even a robot that is driven forward by a fan. Data interpretation The half marathon attracted more than 12,000 spectators, but only 21 humanoid robots participated. Although the government pointed out that the participating robots conducted "intensive training" before the competition, not all robots completed the entire competition. Champion - Tiangong Ult developed by Beijing Humanoid Robot Innovation Center
 The Mirror Trap: AI Ethics And The Collapse Of Human ImaginationApr 28, 2025 am 11:08 AM
The Mirror Trap: AI Ethics And The Collapse Of Human ImaginationApr 28, 2025 am 11:08 AMArtificial intelligence, in its current form, isn't truly intelligent; it's adept at mimicking and refining existing data. We're not creating artificial intelligence, but rather artificial inference—machines that process information, while humans su
 New Google Leak Reveals Handy Google Photos Feature UpdateApr 28, 2025 am 11:07 AM
New Google Leak Reveals Handy Google Photos Feature UpdateApr 28, 2025 am 11:07 AMA report found that an updated interface was hidden in the code for Google Photos Android version 7.26, and each time you view a photo, a row of newly detected face thumbnails are displayed at the bottom of the screen. The new facial thumbnails are missing name tags, so I suspect you need to click on them individually to see more information about each detected person. For now, this feature provides no information other than those people that Google Photos has found in your images. This feature is not available yet, so we don't know how Google will use it accurately. Google can use thumbnails to speed up finding more photos of selected people, or may be used for other purposes, such as selecting the individual to edit. Let's wait and see. As for now
 Guide to Reinforcement Finetuning - Analytics VidhyaApr 28, 2025 am 09:30 AM
Guide to Reinforcement Finetuning - Analytics VidhyaApr 28, 2025 am 09:30 AMReinforcement finetuning has shaken up AI development by teaching models to adjust based on human feedback. It blends supervised learning foundations with reward-based updates to make them safer, more accurate, and genuinely help
 Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AM
Let's Dance: Structured Movement To Fine-Tune Our Human Neural NetsApr 27, 2025 am 11:09 AMScientists have extensively studied human and simpler neural networks (like those in C. elegans) to understand their functionality. However, a crucial question arises: how do we adapt our own neural networks to work effectively alongside novel AI s


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Dreamweaver CS6
Visual web development tools

SublimeText3 Linux new version
SublimeText3 Linux latest version

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Atom editor mac version download
The most popular open source editor

