

 Technology peripheralsAITowards 'Closed Loop' | PlanAgent: New SOTA for closed-loop planning of autonomous driving based on MLLM!
Technology peripheralsAITowards 'Closed Loop' | PlanAgent: New SOTA for closed-loop planning of autonomous driving based on MLLM!Towards 'Closed Loop' | PlanAgent: New SOTA for closed-loop planning of autonomous driving based on MLLM!

The deep reinforcement learning team of the Institute of Automation, Chinese Academy of Sciences, together with Li Auto and others, proposed a new closed-loop planning framework for autonomous driving based on the multimodal large language model MLLM—PlanAgent. This method takes a bird's-eye view of the scene and graph-based text prompts as input, and uses the multi-modal understanding and common sense reasoning capabilities of the multi-modal large language model to perform hierarchical reasoning from scene understanding to the generation of horizontal and vertical movement instructions, and Further generate the instructions required by the planner. The method is tested on the large-scale and challenging nuPlan benchmark, and experiments show that PlanAgent achieves state-of-the-art (SOTA) performance on both regular and long-tail scenarios. Compared with conventional large language model (LLM) methods, the amount of scene description tokens required by PlanAgent is only about 1/3.
Paper information
- Paper title: PlanAgent: A Multi-modal Large Language Agent for Closed loop Vehicle Motion Planning
- Papers published by: Institute of Automation, Chinese Academy of Sciences, Li Auto, Tsinghua University, Beihang University
- Paper address: https://arxiv .org/abs/2406.01587


1 Introduction
As the core module of autonomous driving One, the goal of motion planning is to generate a safe and comfortable optimal trajectory. Rule-based algorithms, such as the PDM [1] algorithm, perform well in handling common scenarios, but are often difficult to cope with long-tail scenarios that require more complex driving operations [2]. Learning-based algorithms [2,3] often overfit in long-tail situations, resulting in performance in nuPlan that is not as good as the rule-based method PDM.
Recently, the development of large language models has opened up new possibilities for autonomous driving planning. Some recent research attempts to use the powerful reasoning capabilities of large language models to enhance the planning and control capabilities of autonomous driving algorithms. However, they encountered some problems: (1) The experimental environment was not based on real closed environment scenarios (2) Using a number of coordinate numbers to represent map details or motion status greatly increased the number of required tokens; (3) ) It is difficult to ensure safety by directly generating trajectory points from a large language model. To address the above challenges, this paper proposes the PlanAgent method.
2 Method
The MLLM-based closed-loop planning agent PlanAgent framework is shown in Figure 1. This paper designs three modules to solve the problem of automatic Complex issues in driving:
- Scene information extraction module (Environment Transformation module): In order to achieve efficient scene information representation, an environment information extraction module is designed that can extract Multimodal input of lane information.
- Reasoning module (Reasoning module): In order to achieve scene understanding and common sense reasoning, a reasoning module is designed, which uses the multi-modal large language model MLLM to generate a reasonable and safe planner code.
- Reflection module: In order to ensure safe planning, a reflection mechanism is designed that can verify the planner through simulation and filter out unreasonable MLLM proposals.
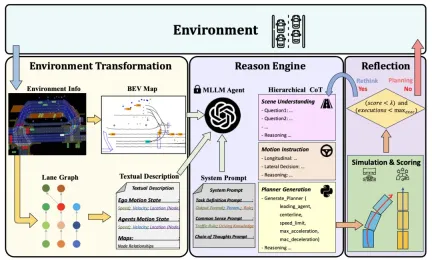
Figure 1 The overall framework of PlanAgent, including the scene information extraction/reasoning/reflection module
2.1 Environmental information extraction Module
The prompt words (prompt) in the large language model have an important impact on the quality of the output it generates. In order to improve the generation quality of MLLM, the scene information extraction module can extract the scene context information and convert it into a bird view (BEV) image and text representation, making it consistent with the input of MLLM. First, this paper converts scene information into Bird Escape (BEV) images to enhance MLLM's ability to understand the global scene. At the same time, the road information needs to be represented graphically, as shown in Figure 2. On this basis, key vehicle motion information is extracted, so that MLLM can focus on the area most relevant to its own position.
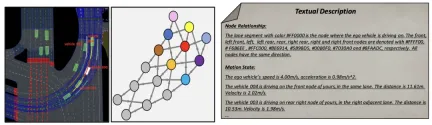
Figure 2 Text prompt description based on graph representation
2.2 Reasoning module
How to introduce the reasoning capabilities of large language models into the autonomous driving planning process and realize a planning system with common sense reasoning capabilities is a key issue. The method designed in this article can take user messages containing current scene information and predefined system messages as input, and generate the planner code of the intelligent driver model (IDM) through multiple rounds of reasoning in the hierarchical thinking chain. As a result, PlanAgent can embed the powerful reasoning capabilities of MLLM into autonomous driving planning tasks through contextual learning.
Among them, the user message includes BEV coding and surrounding vehicle motion information extracted based on graph representation. System messages include task definition, common sense knowledge and thinking chain steps, as shown in Figure 3.

Figure 3 System prompt template
After getting the prompt information, MLLM will reason about the current scene from three levels: scene understanding, motion instructions and code generation, and finally generate the code of the planner. In PlanAgent, car following, center line, speed limit, maximum acceleration and maximum deceleration parameter codes will be generated, and then the instantaneous acceleration in a certain scene will be generated by IDM, and finally a trajectory will be generated.
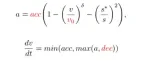

2.3 Reflection module
Pass the above two modules Strengthens MLLM's understanding and reasoning capabilities of scenarios. However, the illusion of MLLM still poses a challenge to the safety of autonomous driving. Inspired by human beings’ decision-making process of “thinking twice before leaping”, this article adds a reflection mechanism to the algorithm design. Simulate the planner generated by MLLM, and evaluate the planner's driving score through indicators such as collision likelihood, driving distance, and comfort. When the score is lower than a certain threshold τ, it indicates that the planner generated by MLLM is inadequate, and MLLM will be requested to regenerate the planner.
3 Experiments and results
This paper conducts closed-loop planning experiments on nuPlan[4], a closed-loop planning platform for large-scale real scenarios, to evaluate PlanAgent performance, the experimental results are as follows.
3.1 Main experiments
Table 1 Comparison between PlanAgent and other algorithms on nuPlan’s val14 and test-hard benchmarks
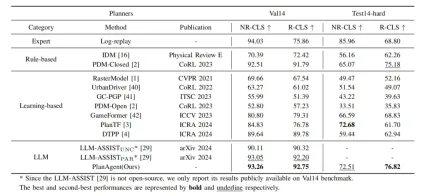
As shown in Table 1, this article compares the proposed PlanAgent with three types of cutting-edge algorithms, and compares the two of nuPlan Tested on benchmark val14 and test-hard. PlanAgent shows competitive and generalizable results compared with other methods.
- Competitive results: On the common scenario val14 benchmark, PlanAgent outperforms other rule-based, learning-based and large language model-based methods, in NR-CLS and All achieved the best ratings in R-CLS.
- Generalizable results: Neither the rule method represented by PDM-Closed[1] nor the learning method represented by planTF[2] can be used in both val14 and test at the same time. -Performs well on hard. Compared with these two types of methods, PlanAgent can overcome long-tail scenarios while ensuring performance in common scenarios.
Table 2 Comparison of tokens used by different methods to describe scenarios

# #At the same time, PlanAgent uses fewer tokens than other methods based on large models. As shown in Table 2, it only requires 1/3 of GPT-Driver[5] or LLM-ASSIST[6]. This shows that PlanAgent can describe the scene more effectively with fewer tokens. This is especially important for the use of closed-source large language models.
3.2 Ablation experiment
Table 3 Ablation experiment of different parts in the scene extraction module

Table 4 Ablation experiments of different parts in the hierarchical thinking chain
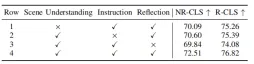
##As shown in Table 3 and 4. This paper conducts ablation experiments on different parts of the scene information extraction module and reasoning module. The experiments prove the effectiveness and necessity of each module. MLLM's understanding of the scene can be enhanced through BEV image and graph representation, and MLLM's reasoning ability for the scene can be enhanced through hierarchical thinking chains.
Table 5 Experiments of PlanAgent on different language models
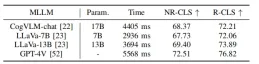
At the same time , as shown in Table 5, this article uses some open source large language models for testing. Experimental results show that on the Test-hard NR-CLS benchmark, PlanAgent using different large language models can achieve 4.1%, 5.1% and 6.7% higher driving scores than PDM-Closed respectively. This demonstrates PlanAgent’s compatibility with various multi-modal large language models.
3.3 Visual analysis
Roundabout traffic scenarioPDM selects the outside lane as the centerline, and the vehicle drives on the outside lane. The vehicle got stuck while merging. PlanAgent determines that a vehicle is merging, outputs a reasonable left lane change command, and generates a lateral action to select the inner lane of the roundabout as centerline, and the vehicle drives on the inner lane.

PDM selected the traffic light category as the car following category. PlanAgent outputs reasonable instructions and selects the stop line as the car-following category.
4 Conclusion
This paper proposes a new MLLM-based closed-loop planning framework for autonomous driving, called PlanAgent. This method introduces a scene information extraction module to extract BEV images and extract the motion information of surrounding vehicles based on the graph representation of the road. At the same time, a reasoning module with a hierarchical structure is proposed to guide MLLM to understand scene information, generate motion instructions, and finally generate planner code. In addition, PlanAgent also imitates human decision-making for reflection, and re-plans when the trajectory score is lower than the threshold to enhance the safety of decision-making. The autonomous driving closed-loop planning agent PlanAgent based on the multi-modal large model has achieved SOTA performance in closed-loop planning on the nuPlan benchmark.
The above is the detailed content of Towards 'Closed Loop' | PlanAgent: New SOTA for closed-loop planning of autonomous driving based on MLLM!. For more information, please follow other related articles on the PHP Chinese website!

 AI Therapists Are Here: 14 Groundbreaking Mental Health Tools You Need To KnowApr 30, 2025 am 11:17 AM
AI Therapists Are Here: 14 Groundbreaking Mental Health Tools You Need To KnowApr 30, 2025 am 11:17 AMWhile it can’t provide the human connection and intuition of a trained therapist, research has shown that many people are comfortable sharing their worries and concerns with relatively faceless and anonymous AI bots. Whether this is always a good i
 Calling AI To The Grocery AisleApr 30, 2025 am 11:16 AM
Calling AI To The Grocery AisleApr 30, 2025 am 11:16 AMArtificial intelligence (AI), a technology decades in the making, is revolutionizing the food retail industry. From large-scale efficiency gains and cost reductions to streamlined processes across various business functions, AI's impact is undeniabl
 Getting Pep Talks From Generative AI To Lift Your SpiritApr 30, 2025 am 11:15 AM
Getting Pep Talks From Generative AI To Lift Your SpiritApr 30, 2025 am 11:15 AMLet’s talk about it. This analysis of an innovative AI breakthrough is part of my ongoing Forbes column coverage on the latest in AI including identifying and explaining various impactful AI complexities (see the link here). In addition, for my comp
 Why AI-Powered Hyper-Personalization Is A Must For All BusinessesApr 30, 2025 am 11:14 AM
Why AI-Powered Hyper-Personalization Is A Must For All BusinessesApr 30, 2025 am 11:14 AMMaintaining a professional image requires occasional wardrobe updates. While online shopping is convenient, it lacks the certainty of in-person try-ons. My solution? AI-powered personalization. I envision an AI assistant curating clothing selecti
 Forget Duolingo: Google Translate's New AI Feature Teaches LanguagesApr 30, 2025 am 11:13 AM
Forget Duolingo: Google Translate's New AI Feature Teaches LanguagesApr 30, 2025 am 11:13 AMGoogle Translate adds language learning function According to Android Authority, app expert AssembleDebug has found that the latest version of the Google Translate app contains a new "practice" mode of testing code designed to help users improve their language skills through personalized activities. This feature is currently invisible to users, but AssembleDebug is able to partially activate it and view some of its new user interface elements. When activated, the feature adds a new Graduation Cap icon at the bottom of the screen marked with a "Beta" badge indicating that the "Practice" feature will be released initially in experimental form. The related pop-up prompt shows "Practice the activities tailored for you!", which means Google will generate customized
 They're Making TCP/IP For AI, And It's Called NANDAApr 30, 2025 am 11:12 AM
They're Making TCP/IP For AI, And It's Called NANDAApr 30, 2025 am 11:12 AMMIT researchers are developing NANDA, a groundbreaking web protocol designed for AI agents. Short for Networked Agents and Decentralized AI, NANDA builds upon Anthropic's Model Context Protocol (MCP) by adding internet capabilities, enabling AI agen
 The Prompt: Deepfake Detection Is A Booming BusinessApr 30, 2025 am 11:11 AM
The Prompt: Deepfake Detection Is A Booming BusinessApr 30, 2025 am 11:11 AMMeta's Latest Venture: An AI App to Rival ChatGPT Meta, the parent company of Facebook, Instagram, WhatsApp, and Threads, is launching a new AI-powered application. This standalone app, Meta AI, aims to compete directly with OpenAI's ChatGPT. Lever
 The Next Two Years In AI Cybersecurity For Business LeadersApr 30, 2025 am 11:10 AM
The Next Two Years In AI Cybersecurity For Business LeadersApr 30, 2025 am 11:10 AMNavigating the Rising Tide of AI Cyber Attacks Recently, Jason Clinton, CISO for Anthropic, underscored the emerging risks tied to non-human identities—as machine-to-machine communication proliferates, safeguarding these "identities" become


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

