In the field of AI, scaling laws are a powerful tool for understanding the scaling trend of LM. They provide a guideline for researchers. This law provides an important guide for understanding how the performance of language models changes with scale. Unfortunately, scaling analysis is not common in many benchmarking and post-training studies because most researchers do not have the computational resources to build scaling laws from scratch, And the open model is trained on too few scales to make reliable scaling predictions. Researchers from Stanford University, University of Toronto and other institutions have proposed an alternative observation method: Observational Scaling Laws, which combines language models ( The functionality of LM) is tied to downstream performance across multiple model families, rather than just within a single family as is the case with standard computational expansion laws. #This approach bypasses model training and instead builds scaling laws based on approximately 80 publicly available models. But this leads to another problem. Constructing a single expansion law from multiple model families faces huge challenges because of the large differences in training computational efficiency and capabilities between different models. Nevertheless, the study shows that these changes are consistent with a simple, generalized expansion law in which language model performance is a low-dimensional capability space (low-dimensional capability space), and the entire model family only differs in the efficiency of converting training calculations into capabilities. Using the above method, this study demonstrates the surprising predictability of many other types of extension studies, and they found that: some emergent phenomena follow smooth sigmoidal behavior and can Predict from small models; agent performance like GPT-4 can be accurately predicted from simpler non-agent benchmarks. Additionally, the study shows how to predict the impact of post-training interventions such as thought chains on the model. Research shows that even when fitted using only a small sub-GPT-3 model, observable expansion laws can accurately predict complex phenomena such as emergent capabilities, agents Extensions to performance and post-training methods (e.g. thought chains).
- Paper address: https://arxiv.org/pdf/2405.10938
- Paper title: Observational Scaling Laws and the Predictability of Language Model Performance
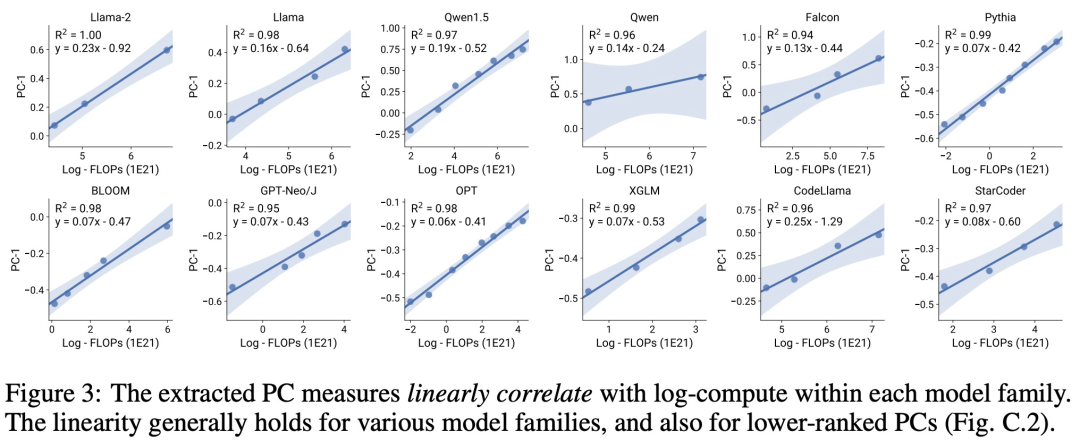
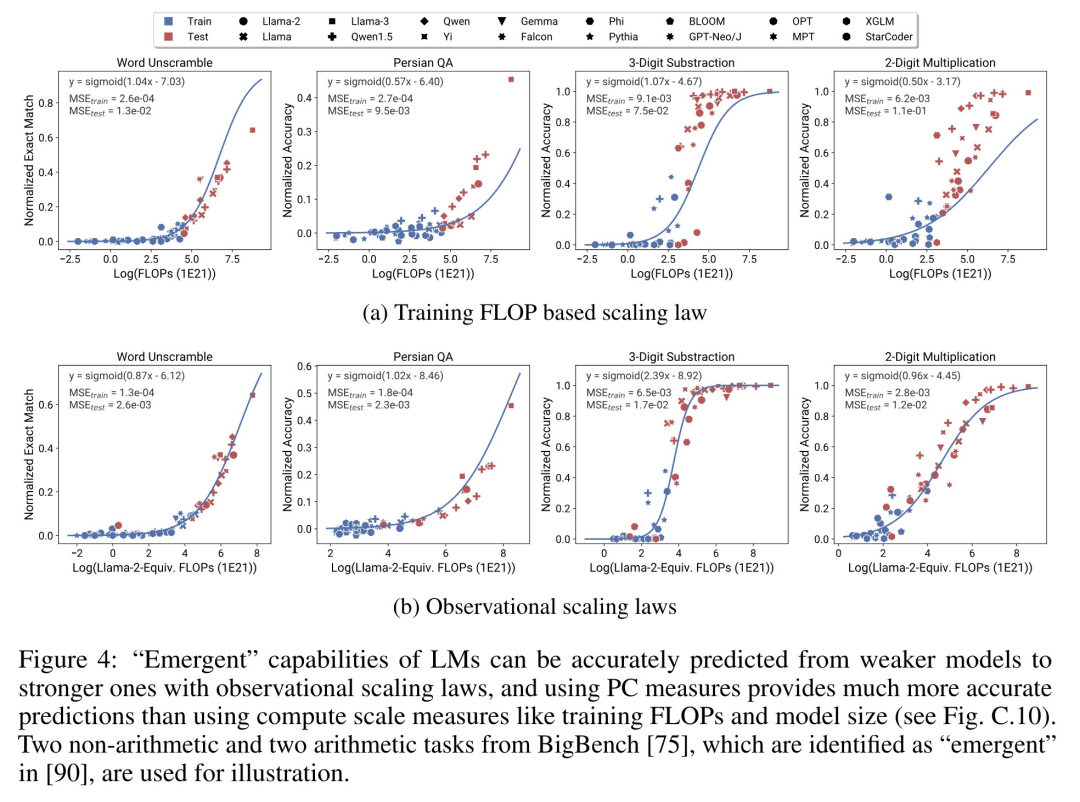
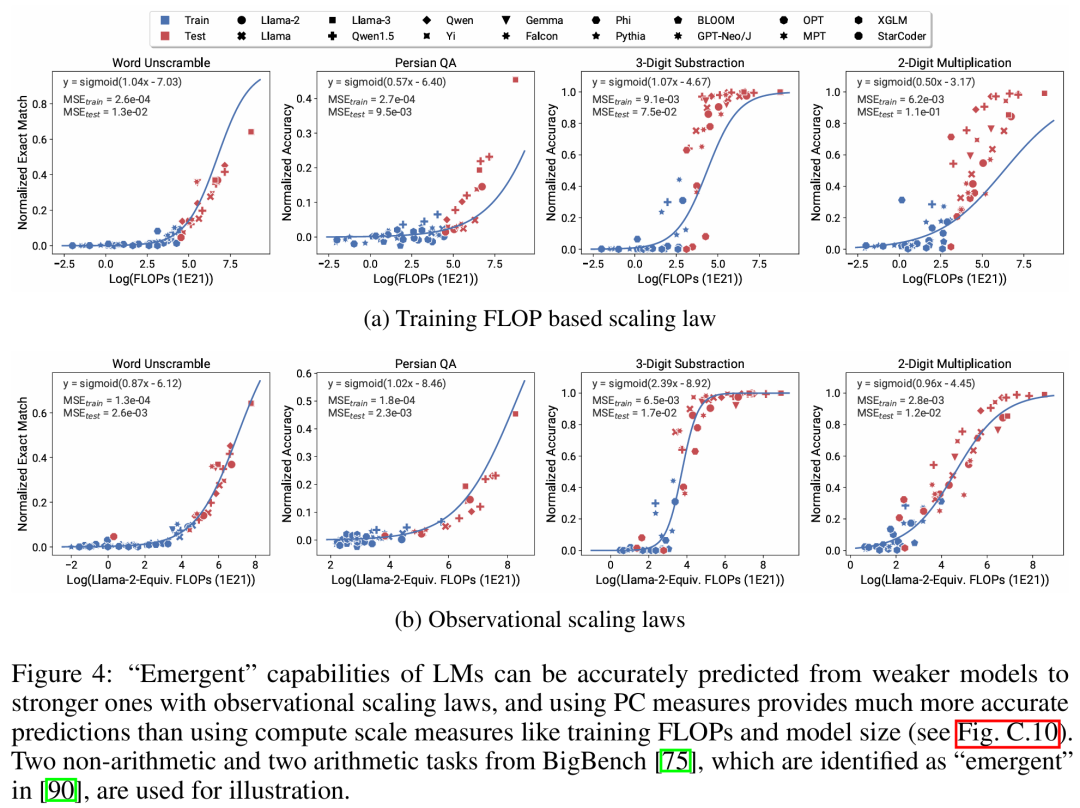
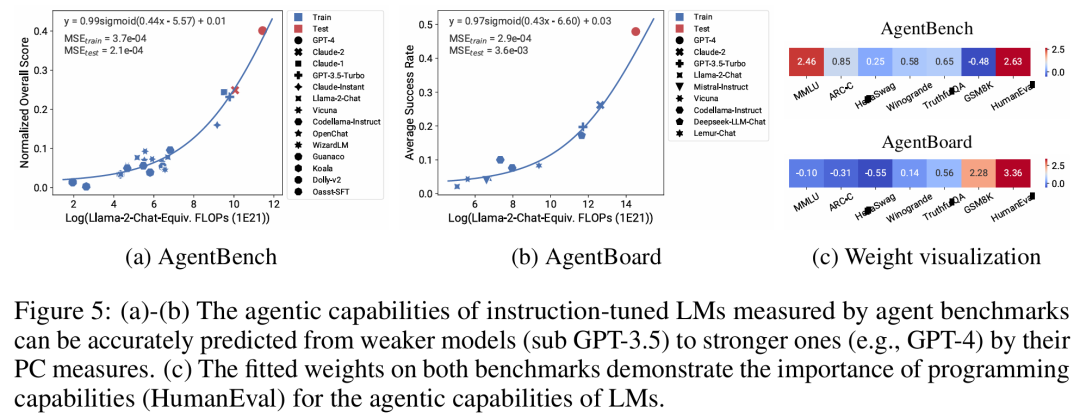
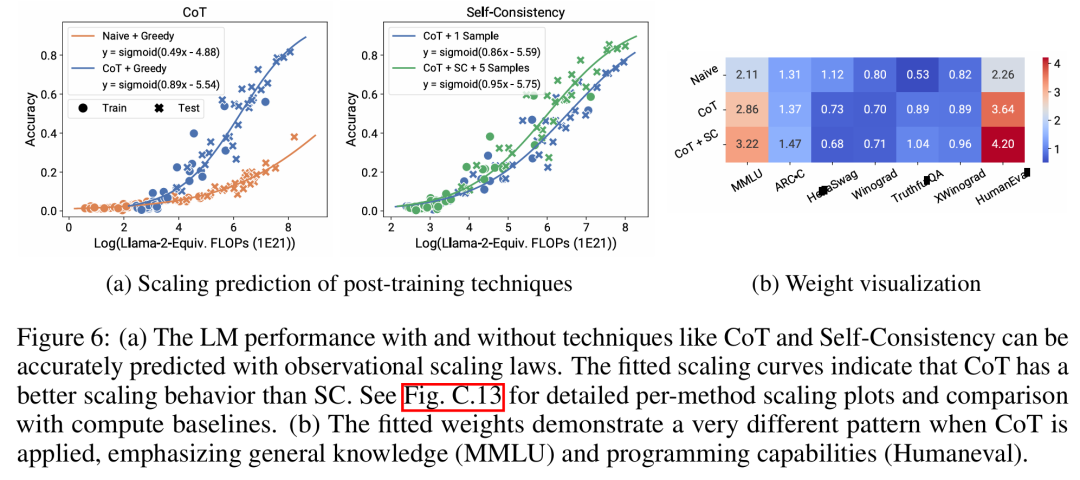
There are three authors of the paper, among which Yangjun Ruan is a Chinese author. He graduated from Zhejiang University with a bachelor's degree . This paper also received forwarded comments from Jason Wei, the proposer of the thinking chain. Jason Wei said that he liked this research very much. The study observed that hundreds of open models currently exist, These models come in different sizes and capabilities. However, researchers cannot directly use these models to calculate expansion laws (because the computational efficiency of training varies greatly between model families), but researchers hope that there is a more general expansion law that applies to model families. In particular, this paper assumes that the downstream performance of LM is a function of low-dimensional capability space (such as natural language understanding, reasoning and code generation), and the model family changes only in that they will The efficiency of training calculations translates into these capabilities. If this relationship holds true, it would mean that there is a log-linear relationship from low-dimensional capabilities to downstream capabilities across model families (which would allow researchers to establish scaling laws using existing models) (Figure 1). This study obtained low-cost, high-resolution extension predictions using nearly 80 publicly available LMs (right). 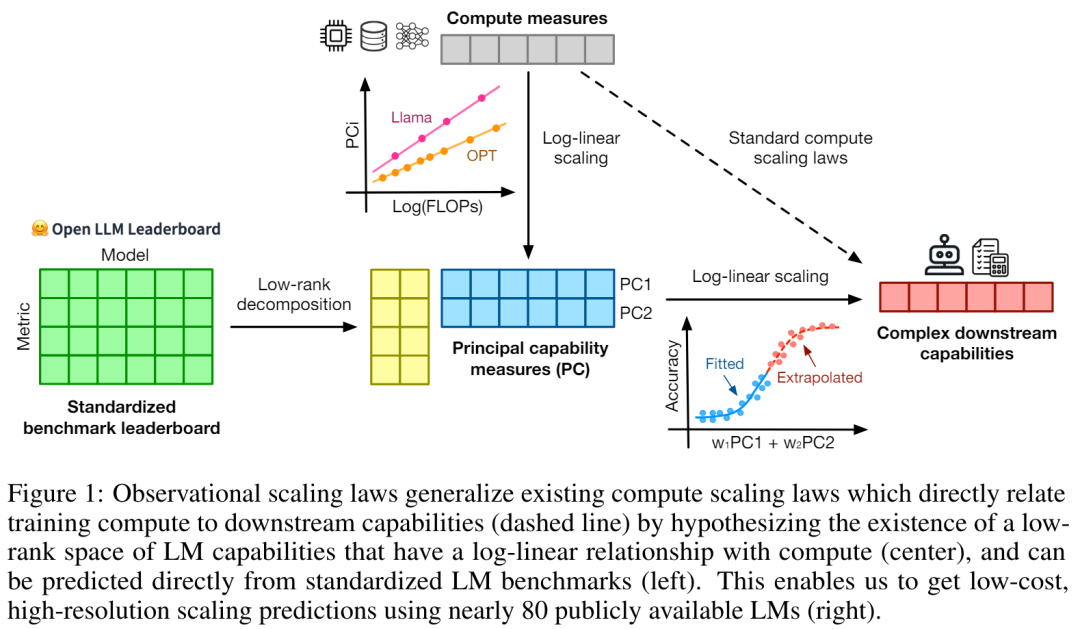 Through analysis of standard LM benchmarks (e.g., Open LLM Leaderboard), researchers have discovered a number of such capability measures that vary within model families compared to the amount of computation. There is an expansion law relationship (R^2 > 0.9) (see Figure 3 below), and this relationship also exists in different model families and downstream indicators. This article calls this expansion relationship the observable expansion law. Finally, this study shows that using observable expansion laws is cheap and simple because there are a few series of models that are sufficient to replicate many of the study's core findings. Using this approach, the study found that scaling predictions for baseline and post-training interventions can be easily achieved by evaluating only 10-20 models. Regarding whether LM has discontinuity under certain computational thresholds The emergence of “emergent” capabilities, and whether these capabilities can be predicted using small models, has been hotly debated. Observable expansion laws suggest that some of these phenomena follow smooth S-shaped curves and can be accurately predicted using small sub Llama-2 7B models. The research Show that the more advanced and complex capabilities of LM as an agent, as measured by AgentBench and AgentBoard, can be predicted using observable scaling laws. Through observable scaling laws, the study was able to accurately predict the performance of GPT-4 using only a weaker model (sub GPT-3.5) and identified programming ability as a factor driving agent performance. Post-training method expansionThis study shows that even if the expansion law is fitted On weaker models (sub Llama-2 7B), the expansion law can also reliably predict the benefits of post-training methods, such as Chain-of-Thought, Self-Consistency, etc. Overall, the contribution of this study is to propose observable expansion laws that exploit predictable logarithms between calculations, simple capability measures, and complex downstream metrics linear relationship. Verification of the Observable Expansion LawThe researchers verified these expansions experimentally The usefulness of the law. In addition, after the paper was published, the researchers also pre-registered predictions for future models to test whether the expansion law overfits the current model. The relevant code about the implementation process and data collection has been released on GitHub: GitHub address: https://github.com/ryoungj/ObsScalingPredictability of emergent capability Figure 4 below shows the prediction using the PC (principal capability) metric results, as well as baseline results for predicting performance based on training FLOPs. It can be found that these capabilities can be accurately predicted using our PC metric even when using only a poorly performing model. In contrast, using training FLOPs results in significantly worse extrapolation on the test set and significantly worse fit on the training set, as indicated by higher MSE values. These differences may be caused by training FLOPs for different model families. Agent capability predictabilityFigure 5 below shows the use of PC metrics Finally, the prediction results of the observable expansion law. It can be found that on both agent benchmarks, the performance of the hold-out model (GPT-4 or Claude-2) using the PC metric can be accurately predicted from the weaker performing (more than 10% gap) model. This shows that the more complex agent capabilities of LMs are closely related to their underlying model capabilities and are able to make predictions based on the latter. This also illustrates that as backbone LMs continue to expand in scale, LM-based agent capabilities have good scalability characteristics. The impact of post-training techniquesFigure 6a below illustrates the use of observable Expansion laws, expansion prediction results of CoT and SC (Self-Consistency, self-consistency). It can be found that the performance of stronger, larger models using CoT and CoT+SC but without (Naive) post-training techniques can be accurately predicted from weaker models with smaller computational scale (such as model size and training FLOPs) out. It is worth noting that the scaling trends are different between the two technologies, with CoT showing a more obvious scaling trend compared to using the self-consistency of CoT.Please refer to the original paper for more technical details.
Through analysis of standard LM benchmarks (e.g., Open LLM Leaderboard), researchers have discovered a number of such capability measures that vary within model families compared to the amount of computation. There is an expansion law relationship (R^2 > 0.9) (see Figure 3 below), and this relationship also exists in different model families and downstream indicators. This article calls this expansion relationship the observable expansion law. Finally, this study shows that using observable expansion laws is cheap and simple because there are a few series of models that are sufficient to replicate many of the study's core findings. Using this approach, the study found that scaling predictions for baseline and post-training interventions can be easily achieved by evaluating only 10-20 models. Regarding whether LM has discontinuity under certain computational thresholds The emergence of “emergent” capabilities, and whether these capabilities can be predicted using small models, has been hotly debated. Observable expansion laws suggest that some of these phenomena follow smooth S-shaped curves and can be accurately predicted using small sub Llama-2 7B models. The research Show that the more advanced and complex capabilities of LM as an agent, as measured by AgentBench and AgentBoard, can be predicted using observable scaling laws. Through observable scaling laws, the study was able to accurately predict the performance of GPT-4 using only a weaker model (sub GPT-3.5) and identified programming ability as a factor driving agent performance. Post-training method expansionThis study shows that even if the expansion law is fitted On weaker models (sub Llama-2 7B), the expansion law can also reliably predict the benefits of post-training methods, such as Chain-of-Thought, Self-Consistency, etc. Overall, the contribution of this study is to propose observable expansion laws that exploit predictable logarithms between calculations, simple capability measures, and complex downstream metrics linear relationship. Verification of the Observable Expansion LawThe researchers verified these expansions experimentally The usefulness of the law. In addition, after the paper was published, the researchers also pre-registered predictions for future models to test whether the expansion law overfits the current model. The relevant code about the implementation process and data collection has been released on GitHub: GitHub address: https://github.com/ryoungj/ObsScalingPredictability of emergent capability Figure 4 below shows the prediction using the PC (principal capability) metric results, as well as baseline results for predicting performance based on training FLOPs. It can be found that these capabilities can be accurately predicted using our PC metric even when using only a poorly performing model. In contrast, using training FLOPs results in significantly worse extrapolation on the test set and significantly worse fit on the training set, as indicated by higher MSE values. These differences may be caused by training FLOPs for different model families. Agent capability predictabilityFigure 5 below shows the use of PC metrics Finally, the prediction results of the observable expansion law. It can be found that on both agent benchmarks, the performance of the hold-out model (GPT-4 or Claude-2) using the PC metric can be accurately predicted from the weaker performing (more than 10% gap) model. This shows that the more complex agent capabilities of LMs are closely related to their underlying model capabilities and are able to make predictions based on the latter. This also illustrates that as backbone LMs continue to expand in scale, LM-based agent capabilities have good scalability characteristics. The impact of post-training techniquesFigure 6a below illustrates the use of observable Expansion laws, expansion prediction results of CoT and SC (Self-Consistency, self-consistency). It can be found that the performance of stronger, larger models using CoT and CoT+SC but without (Naive) post-training techniques can be accurately predicted from weaker models with smaller computational scale (such as model size and training FLOPs) out. It is worth noting that the scaling trends are different between the two technologies, with CoT showing a more obvious scaling trend compared to using the self-consistency of CoT.Please refer to the original paper for more technical details. The above is the detailed content of Constructing Scaling Law from 80 models: a new work by a Chinese doctoral student, highly recommended by the author of the thinking chain. For more information, please follow other related articles on the PHP Chinese website!
Statement:The content of this article is voluntarily contributed by netizens, and the copyright belongs to the original author. This site does not assume corresponding legal responsibility. If you find any content suspected of plagiarism or infringement, please contact admin@php.cn