
Home >Web Front-end >JS Tutorial >Talk about functions and closures in JavaScript_Basic knowledge
Talk about functions and closures in JavaScript_Basic knowledge

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2016-05-16 17:37:09938browse
闭包这东西,说难也难,说不难也不难,下面我就以自己的理解来说一下闭包
一、闭包的解释说明
对于函数式语言来说,函数可以保存内部的数据状态。对于像C#这种编译型命令式语言来说,由于代码总是在代码段中执行,而代码段是只读的,因此函数中的数据只能是静态数据。函数内部的局部变量存放在栈上,在函数执行结束以后,所占用的栈被释放,因此局部变量是不能保存的。
Javascript采用词法作用域,函数的执行依赖于变量作用域,这个作用域是在定义函数时确定的。因此Javascript中函数对象不仅保存代码逻辑,还必须引用当前的作用域链。Javascript中函数内部的局部变量可以被修改,而且当再次进入到函数内部的时候,上次被修改的状态仍然持续。这是因为因为局部变量并不保存在栈上,而是通过一个对象来保存。
决定使用哪个变量是由作用域链决定的,每次生成函数实例时,都会为之创建一个对象用来保存局部变量,并且把这个用于保存局部变量的对象加入作用域链中。不同函数对象可以通过作用域链关联起来。Javascript中所有函数都是闭包,我们不能避免“产生”闭包。
引用一张《Javascript高级程序设计》中的图来说明,虽然这张图并不完全说明所有情况。图中的activation object就是用于保存变量的对象。
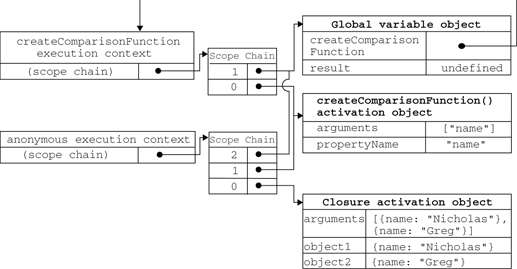
简而言之,在Javascript中:
闭包:函数实例保存着在执行时所需要的变量的引用,而不会复制保存当时变量的值。(在Object C的实现中,我们可以选择保存当时的值或者是引用)
作用域链:解析变量时查找变量所在的方式,以var作为终止符号,如果链上一直没有var,则一直追溯到全局对象为止。
C#中的闭包特性是由编译器把局部变量转换成引用类型的对象成员实现的。
二、闭包的使用
下面通过一些具体例子来说明如何利用闭包这一特性:
1.闭包是在定义的时候产生的
function Foo(){ function A(){} function B(){} function C(){}}
我们每次执行Foo()的时候,都有有A,B,C这三个函数实例(闭包)产生,当Foo执行完毕,生成的实例没有其他引用,因此会被当成垃圾随之销毁(不一定是马上销毁)。
我们来证实一下作用域链是在函数定义时确定的,所以这里显示的应该是'local scope'
var scope = "global scope"; function checkscope() { var scope = "local scope"; function f() { return scope; } return f;}checkscope()()
同样道理:
(function(){ function A(){} function B(){} function C(){}}())
上面的表达式执行完后也会有A,B,C这三个函数实例(闭包)产生,因为这是一个立即执行的匿名函数,这三个闭包只能产生一次。生成的闭包没有其他引用,因此会被当成垃圾随之销毁(不一定是马上销毁)。
我们之所以这么写,目地有两个
1.避免污染全局对象
2.避免多次产生相同的函数实例
对比下面两个例子,闭包是如何保存作用域链的:
function A(){} //比较省内存的写法,创建对象速度快,开销小 (function(prototype){ var name = "a"; function sayName () { alert(name); } function ChangeName() { name += "_changed" } prototype.sayName = sayName;//引用通过执行匿名函数产生的闭包,闭包只会产生一次 prototype.changeName = ChangeName; }(A.prototype)) var a1 = new A(); var a2 = new A();
a1.sayName(); a1.changeName(); a2.sayName();
--------------------------------------------------------------------------------
function B(){ //The prototype chain is relatively short, and the method is found quickly, but it consumes more memory. Each time new calls the constructor, 2 function instances and 1 variable are generated. var name = "b"; function sayName () { alert(name); } function changeName() { name = "_changed"; } this.sayName = sayName;//Reference closure, each time function B is called, a new Closure of this.changeName = changeName; }//If the function call is preceded by the new keyword, the function is used as a constructor. //Essentially, there is no difference between calling it as a constructor and calling it as an ordinary function. If B() is called directly, then this object will be bound to the global object, and the newly generated closure will replace the old closure and be assigned to the changeName and sayName properties of the global object, so the old closure will be treated as garbage collection. //If used as a constructor, the new keyword will generate a new object (this points to this new object) and initialize the sayName and changeName properties of this new object, so each generated closure will be retained because of the reference. var b1 = new B(); b1.sayName(); b1.changeName(); b1.sayName(); var b2 = new B(); b2.sayName(); b1.sayName();
3. Leakage problem: In compiled languages, the function body is always in the code segment of the file, and is loaded into the memory area marked as executable during runtime. In fact, we don't think that the function itself has a life cycle. In most cases, we think of "reference type data structures" as having life cycle and leak problems, such as pointers, objects, etc.
The essence of memory leaks in JavaScript is that the objects generated when defining functions to hold local variables are not treated as garbage and collected because of the existence of references.
1. There is a circular reference
2. Some objects can never be destroyed, such as IE6's memory leak in the DOM, or the Javascript engine cannot be notified when destroyed, so some Javascript closures can never be destroyed. These situations usually occur due to miscommunication between the Javascript host object and the native object in Javascript.
Related articles
See more- An in-depth analysis of the Bootstrap list group component
- Detailed explanation of JavaScript function currying
- Complete example of JS password generation and strength detection (with demo source code download)
- Angularjs integrates WeChat UI (weui)
- How to quickly switch between Traditional Chinese and Simplified Chinese with JavaScript and the trick for websites to support switching between Simplified and Traditional Chinese_javascript skills