
Home >Web Front-end >JS Tutorial >Usage examples of NodeJS's url interception module url-extract_Basic knowledge
Usage examples of NodeJS's url interception module url-extract_Basic knowledge

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2016-05-16 17:14:421244browse
Last time we introduced how to use NodeJS PhantomJS to take screenshots, but since a PhantomJS process is enabled for each screenshot operation, the efficiency is worrying when the concurrency increases, so we rewrote all the code and made it independent Become a module for easy calling.
How to improve? Control the number of threads and the number of URLs processed by a single thread. Use Standard Output & WebSocket for communication. Add caching mechanism, currently using Javascript Object. Provides a simple interface to the outside world.
Design
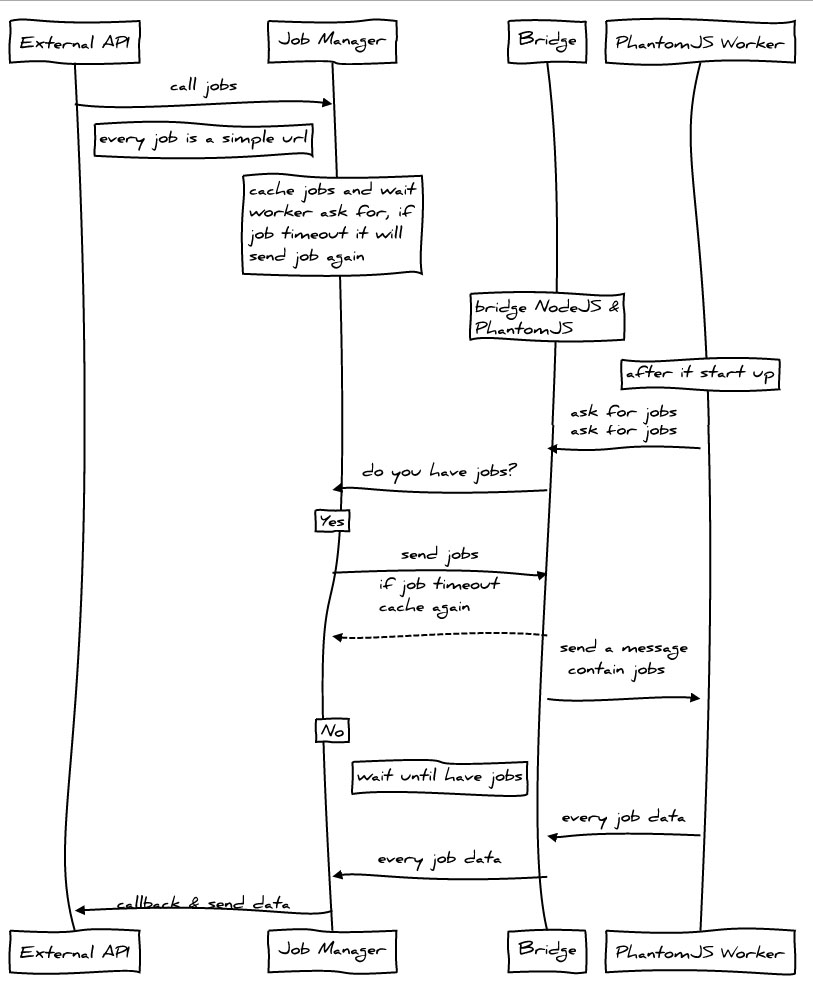
Dependencies & Installation
Since PhantomJS 1.9.0 only started to support Websocket, we must first make sure that the PhantomJS in PATH is version 1.9.0 or above. At the command line type:
$ phantomjs -v
If the version number 1.9.x can be returned, you can continue the operation. If the version is too low or an error occurs, please go to PhantomJS official website to download the latest version.
If you have Git installed, or have a Git Shell, then type at the command line:
$ npm install url-extract
Proceed to install.
A simple example
For example, if we want to intercept the Baidu homepage, we can do this:
The following is the print:

Among them, the image attribute is the address of the screenshot relative to the working path. We can use the getData interface of Job to get clearer data, for example:
The printing will look like this:

image represents the address of the screenshot relative to the working path, status represents whether the status is normal, true represents normal, and false represents the screenshot failed.
For more examples, please see: https://github.com/miniflycn/url-extract/tree/master/examples
Main API
.snapshot
url snapshot
.snapshot(url, [callback]).snapshot(urls, [callback]).snapshot(url, [option]).snapshot(urls, [option])Copy code The code is as follows:url {String} The address to be intercepted urls {Array} The address to be intercepted Address array callback {Function} Callback function option {Object} Optional parameters ┝ id {String} The id of the custom url. If the first parameter is urls, this parameter is invalid ┝ image {String} The saving address of the custom screenshot, if The first parameter is urls, this parameter is invalid┝ groupId {String} defines the groupId of a group of URLs, used to identify which group of URLs it is when returning ┝ ignoreCache {Boolean} whether to ignore the cache┗ callback {Function} callback function.extract
Grab url information and get snapshots
.extract(url, [callback]).extract(urls, [callback]).extract(url, [option]).extract( urls, [option])url {String} The address to be intercepted
urls {Array} Array of addresses to intercept
callback {Function} callback function
option {Object} optional parameter
┝ id {String} The id of the custom URL. If the first parameter is urls, this parameter is invalid
┝ image {String} Customize the saving address of the screenshot. If the first parameter is urls, this parameter is invalid
┝ groupId {String} defines the groupId of a group of URLs, used to identify which group of URLs it is when returning
┝ignoreCache {Boolean} Whether to ignore the cache
┗ callback {Function} callback function
Job (class)
Each URL corresponds to a job object, and the relevant information of the URL is stored in the job object.
Field
url {String} link address content {Boolean} whether to crawl the page's title and description information id {String} job's idgroupId {String} group id of a bunch of jobs cache {Boolean} whether to enable caching callback {Function} callback function image {String} Image address status {Boolean} Whether the job is currently normalPrototype
getData() gets job related dataGlobal configuration
The config file in the root directory of url-extract can be configured globally. The default is as follows:
module.exports = { wsPort: 3001, maxJob: 100, maxQueueJob: 400, cache: 'object', maxCache: 10000, workerNum: 0};wsPort {Number} The port address occupied by websocket maxJob {Number} The number of concurrent workers that each PhantomJS thread can have maxQueueJob {Number} The maximum number of waiting jobs, 0 means no limit, beyond this number, any job will directly return to failure (i.e. status = false) cache {String} cache implementation, currently only object implements maxCache {Number} maximum number of cache links workerNum {Number} PhantomJS thread number, 0 means the same as the number of CPUsA simple service example
https://github.com/miniflycn/url-extract-server-example
Note that connect and url-extract need to be installed:
$ npm install
If you downloaded the network disk file, please install connect:
$ npm install connect
Then type:
$ node bin/server
Open:
View the effect.
;
Related articles
See more- An in-depth analysis of the Bootstrap list group component
- Detailed explanation of JavaScript function currying
- Complete example of JS password generation and strength detection (with demo source code download)
- Angularjs integrates WeChat UI (weui)
- How to quickly switch between Traditional Chinese and Simplified Chinese with JavaScript and the trick for websites to support switching between Simplified and Traditional Chinese_javascript skills