
Heim >Technologie-Peripheriegeräte >KI >Werfen Sie einen Blick auf die Vergangenheit und Gegenwart von Occ und autonomem Fahren! Die erste Rezension fasst die drei Hauptthemen Funktionserweiterung/Massenproduktionsbereitstellung/effiziente Annotation umfassend zusammen.
Werfen Sie einen Blick auf die Vergangenheit und Gegenwart von Occ und autonomem Fahren! Die erste Rezension fasst die drei Hauptthemen Funktionserweiterung/Massenproduktionsbereitstellung/effiziente Annotation umfassend zusammen.

- 王林nach vorne
- 2024-05-08 11:40:01719Durchsuche
Vorab geschrieben und persönliches Verständnis des Autors
In den letzten Jahren hat autonomes Fahren aufgrund seines Potenzials, die Belastung des Fahrers zu verringern und die Fahrsicherheit zu verbessern, zunehmende Aufmerksamkeit erhalten. Die visionsbasierte dreidimensionale Belegungsvorhersage ist eine neue Wahrnehmungsaufgabe, die sich für eine kostengünstige und umfassende Untersuchung der Sicherheit autonomen Fahrens eignet. Obwohl viele Studien die Überlegenheit von 3D-Belegungsvorhersagetools im Vergleich zu objektzentrierten Wahrnehmungsaufgaben gezeigt haben, gibt es immer noch Rezensionen, die diesem sich schnell entwickelnden Bereich gewidmet sind. In diesem Artikel wird zunächst der Hintergrund der visionsbasierten 3D-Belegungsvorhersage vorgestellt und die bei dieser Aufgabe auftretenden Herausforderungen erörtert. Als nächstes diskutieren wir umfassend den aktuellen Status und die Entwicklungstrends aktueller 3D-Belegungsvorhersagemethoden unter drei Aspekten: Funktionsverbesserung, Bereitstellungsfreundlichkeit und Kennzeichnungseffizienz. Abschließend werden aktuelle Forschungstrends zusammengefasst und einige ermutigende Zukunftsaussichten vorgeschlagen.
Open-Source-Link: https://github.com/zya3d/Awesome-3D-Occupancy-Prediction
Zusammenfassend sind die Hauptbeiträge dieses Papiers wie folgt:
- Soweit wir wissen, ist dieses Papier der erste Eine umfassende Übersicht über visionsbasierte 3D-Belegungsvorhersagemethoden für autonomes Fahren.
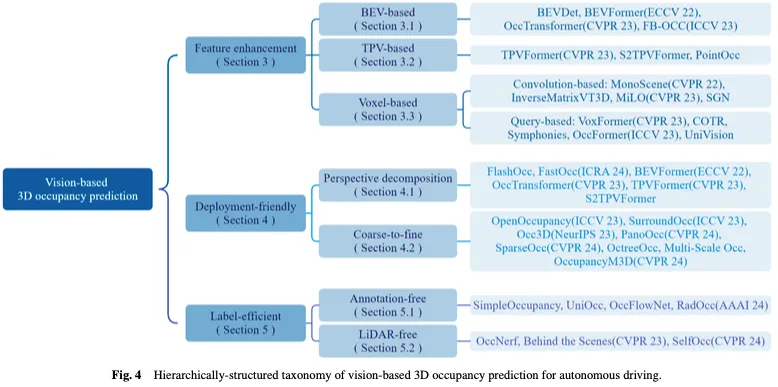
- Dieser Artikel bietet eine strukturelle Zusammenfassung visionsbasierter dreidimensionaler Belegungsvorhersagemethoden aus drei Perspektiven: Funktionsverbesserung, Rechenfreundlichkeit und Etiketteneffizienz und führt eine eingehende Analyse und einen Vergleich verschiedener Methodenkategorien durch.
- Dieses Papier stellt einige inspirierende Zukunftsaussichten für visionsbasierte 3D-Belegungsvorhersagen vor und bietet ein regelmäßig aktualisiertes Github-Repository zum Sammeln relevanter Papiere, Datensätze und Codes.
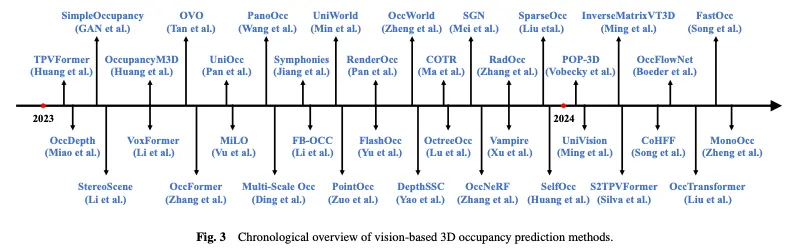
Abbildung 3 zeigt einen zeitlichen Überblick über visionsbasierte 3D-Belegungsvorhersagemethoden und Abbildung 4 zeigt die entsprechende hierarchische Strukturtaxonomie.
Zugehöriger Hintergrund
Echte Wertgenerierung
Die Generierung von GT-Labels ist eine Herausforderung für die 3D-Belegungsvorhersage. Obwohl viele 3D-Wahrnehmungsdatensätze wie nuScenes und Waymo Segmentierungsbeschriftungen für LIDAR-Punktwolken bereitstellen, sind diese Beschriftungen spärlich und es ist schwierig, dichte 3D-Belegungsvorhersageaufgaben zu überwachen. Die Bedeutung der Verwendung einer dichten Belegung als GT-Kennzeichnung wurde von Wei et al. demonstriert. Einige neuere Forschungsarbeiten konzentrieren sich auf die Generierung dichter Belegungsbeschriftungen mithilfe dünner LIDAR-Punktwolken-Segmentierungsanmerkungen und liefern einige nützliche Datensätze und Benchmarks für 3D-Belegungsvorhersageaufgaben.
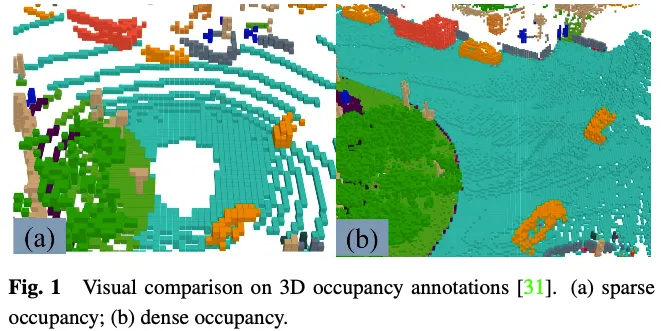
Die GT-Beschriftung in der 3D-Belegungsvorhersageaufgabe gibt an, ob jedes Element im 3D-Raum belegt ist, und die semantische Bezeichnung des besetzten Elements. Aufgrund der großen Anzahl von Elementen im dreidimensionalen Raum ist es schwierig, jedes Element manuell zu beschriften. Ein gängiger Ansatz besteht darin, die Grundwahrheit bestehender 3D-Punktwolken-Segmentierungsaufgaben zu voxelisieren und dann GTs für 3D-Belegungsvorhersagen durch Abstimmung basierend auf den semantischen Bezeichnungen der Voxelmittelpunkte zu generieren. Die auf diese Weise generierte Grundwahrheit wird jedoch tatsächlich vereinfacht. Wie in Abbildung 1 dargestellt, gibt es an Orten wie Straßen, die nicht als besetzt gekennzeichnet sind, immer noch viele besetzte Elemente. Überwachungstools, die über Modelle mit dieser vereinfachten Geländerealität verfügen, führen zu einer verminderten Modellleistung. Daher arbeiten einige daran, automatisch oder halbautomatisch hochwertige, dichte 3D-Belegungsanmerkungen zu generieren.
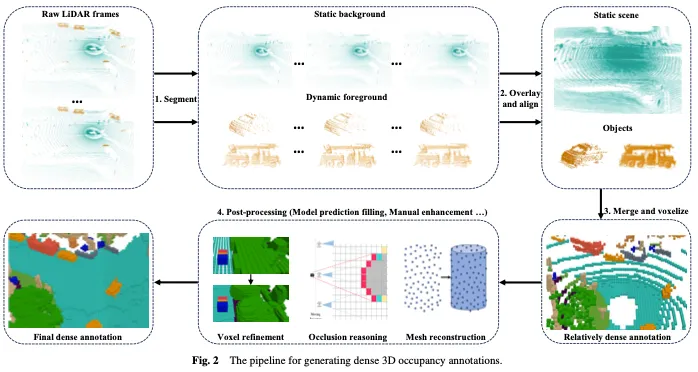
Wie in Abbildung 2 dargestellt, umfasst die Generierung dichter 3D-Belegungsanmerkungen normalerweise die folgenden vier Schritte:
- Nehmen Sie kontinuierliche Roh-Lidar-Frames und segmentieren Sie die LIDAR-Punkte in statischen Hintergrund und dynamischen Vordergrund.
- Überlagern Sie kontinuierliche Lidar-Frames mit einem statischen Hintergrund und führen Sie eine Bewegungskompensation basierend auf Positionsinformationen durch, um Punktwolken mit mehreren Frames auszurichten und dichtere Punktwolken zu erhalten. Kontinuierliche LIDAR-Frames werden dem dynamischen Vordergrund überlagert und die Punktwolke des dynamischen Vordergrunds wird entsprechend dem Zielframe und der Ziel-ID ausgerichtet, um sie dichter zu machen. Beachten Sie, dass die Punktwolke zwar relativ dicht ist, nach der Voxelisierung jedoch noch einige Lücken bestehen, die einer weiteren Verarbeitung bedürfen.
- Führen Sie Vordergrund- und Hintergrundpunktwolken zusammen, voxelisieren Sie sie dann und verwenden Sie einen Abstimmungsmechanismus, um die Semantik der Voxel zu bestimmen, was zu relativ dichten Voxelanmerkungen führt.
- Die im vorherigen Schritt erhaltenen Voxel werden durch Nachbearbeitung verfeinert, um dichtere und feinere Anmerkungen als GT zu erhalten.
Datensätze
In diesem Abschnitt stellen wir einige groß angelegte Open-Source-Datensätze vor, die häufig für die 3D-Belegungsvorhersage verwendet werden. Ein Vergleich zwischen ihnen ist in Tabelle 1 aufgeführt.
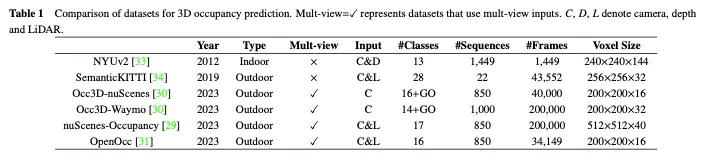
Der NUYv2-Datensatz besteht aus Videosequenzen aus verschiedenen Innenszenen, aufgenommen mit den RGB- und Tiefenkameras von Microsoft Kinect. Es enthält 1449 Paare dicht beschrifteter, ausgerichteter RGB- und Tiefenbilder und 407024 unbeschriftete Frames aus drei Städten. Obwohl dieser Datensatz hauptsächlich für die Verwendung in Innenräumen gedacht und nicht für autonome Fahrszenarien geeignet ist, wurde dieser Datensatz in einigen Studien für die 3D-Belegungsvorhersage verwendet.
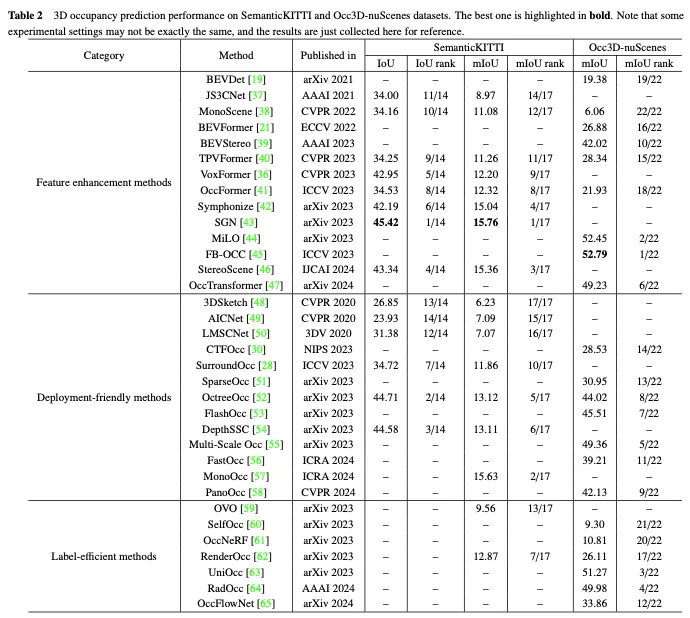
SemanticKITTI ist ein weit verbreiteter Datensatz für die 3D-Belegungsvorhersage, einschließlich 22 Sequenzen und mehr als 43.000 Frames aus dem KITTI-Datensatz. Es erstellt dichte 3D-Belegungsanmerkungen, indem zukünftige Frames überlagert, Voxel segmentiert und Beschriftungen per Punktabstimmung zugewiesen werden. Darüber hinaus verfolgt es Strahlen, um für jede Position des Fahrzeugs zu prüfen, welche Voxel für den Sensor sichtbar sind, und ignoriert unsichtbare Voxel während des Trainings und der Auswertung. Da es jedoch auf dem KITTI-Datensatz basiert, verwendet es nur Bilder der Frontkamera als Eingabe, während nachfolgende Datensätze normalerweise Mehransichtsbilder verwenden. Wie in Tabelle 2 gezeigt, haben wir die Bewertungsergebnisse vorhandener Methoden für den SemanticKITTI-Datensatz gesammelt.
NuScenes Occupancy ist ein 3D-Belegungsvorhersagedatensatz, der auf NuScenes basiert, einem groß angelegten Datensatz für autonomes Fahren in Außenumgebungen. Es enthält 850 Sequenzen, 200.000 Frames und 17 semantische Kategorien. Der Datensatz verwendet zunächst eine Augmentation and Purification (AAP)-Pipeline, um grobe 3D-Belegungsbeschriftungen zu generieren, und dann wird eine manuelle Erweiterung verwendet, um die Beschriftungen zu verfeinern. Darüber hinaus wird OpenOccupancy vorgestellt, der erste Benchmark für das semantische Belegungsbewusstsein in der Umgebung, um fortschrittliche 3D-Belegungsvorhersagemethoden zu bewerten.
Anschließend erstellten Tian et al. die Occ3D nuScenes- und Occ3D Waymo-Datensätze für die 3D-Belegungsvorhersage basierend auf den nuScenes- und Waymo-Datensätzen zum autonomen Fahren. Sie führen eine halbautomatische Etikettengenerierungspipeline ein, die vorhandene beschriftete 3D-Wahrnehmungsdatensätze nutzt und Voxeltypen anhand ihrer Sichtbarkeit identifiziert. Darüber hinaus haben sie den Occ3d-Benchmark für groß angelegte 3D-Belegungsvorhersagen etabliert, um die Bewertung und den Vergleich verschiedener Methoden zu verbessern. Wie in Tabelle 2 gezeigt, haben wir die Bewertungsergebnisse vorhandener Methoden für den Occ3D nuScenes-Datensatz gesammelt.
Darüber hinaus ist OpenOcc, ähnlich wie Occ3D Nude und Nude Occupancy, auch ein Datensatz, der für die 3D-Belegungsvorhersage basierend auf dem Nude-Datensatz erstellt wurde. Es enthält 850 Sequenzen, 34149 Frames und 16 Klassen. Beachten Sie, dass dieser Datensatz zusätzliche Anmerkungen für acht Vordergrundobjekte bereitstellt, was bei nachgelagerten Aufgaben wie der Bewegungsplanung hilfreich ist.
Hauptherausforderungen
Obwohl die visionsbasierte 3D-Belegungsvorhersage in den letzten Jahren erhebliche Fortschritte gemacht hat, stößt sie immer noch auf Einschränkungen aufgrund der Funktionsdarstellung, der praktischen Anwendung und der Anmerkungskosten. Für diese Aufgabe gibt es drei zentrale Herausforderungen: (1) Es ist schwierig, perfekte 3D-Funktionen aus 2D-visuellen Eingaben zu erhalten. Das Ziel der visionsbasierten 3D-Belegungsvorhersage besteht darin, eine detaillierte Wahrnehmung und ein Verständnis von 3D-Szenen allein anhand der Bildeingabe zu erreichen. Der Mangel an Tiefe und geometrischen Informationen stellt jedoch eine erhebliche Herausforderung für das direkte Erlernen von 3D-Merkmalsdarstellungen dar. (2) Hohe Rechenlast im dreidimensionalen Raum. Die 3D-Belegungsvorhersage erfordert normalerweise die Verwendung von 3D-Voxelmerkmalen zur Darstellung des Umgebungsraums, was zwangsläufig Operationen wie die 3D-Faltung zur Merkmalsextraktion erfordert, was den Rechen- und Speicheraufwand erheblich erhöht und den praktischen Einsatz behindert. (3) Teure feinkörnige Anmerkungen. Bei der 3D-Belegungsvorhersage geht es um die Vorhersage des Belegungsstatus und der semantischen Kategorie hochauflösender Voxel. Um dies zu erreichen, ist jedoch häufig eine feinkörnige semantische Annotation jedes Voxels erforderlich, was zeitaufwändig und teuer ist und einen Engpass für diese Aufgabe darstellt.
Als Reaktion auf diese zentralen Herausforderungen hat die Forschungsarbeit zur visionsbasierten dreidimensionalen Belegungsvorhersage für autonomes Fahren nach und nach drei Hauptlinien gebildet: Funktionsverbesserung, Einsatzfreundlichkeit und Kennzeichnungseffizienz. Methoden zur Merkmalsverbesserung verringern den Unterschied zwischen der 3D-Raumausgabe und der 2D-Raumeingabe, indem sie die Merkmalsdarstellungsfähigkeiten des Netzwerks optimieren. Der einsatzfreundliche Ansatz zielt darauf ab, den Ressourcenverbrauch deutlich zu reduzieren und gleichzeitig die Leistung durch den Entwurf einer einfachen und effizienten Netzwerkarchitektur sicherzustellen. Von effizienten Kennzeichnungsmethoden wird erwartet, dass sie auch dann eine zufriedenstellende Leistung erzielen, wenn die Anmerkungen unzureichend sind oder ganz fehlen. Anschließend geben wir einen umfassenden Überblick über aktuelle Ansätze rund um diese drei Branchen.
Funktionsverbesserungsmethode
Die Aufgabe der visionsbasierten 3D-Belegungsvorhersage besteht darin, den Belegungsstatus und die semantischen Informationen des 3D-Voxelraums aus dem 2D-Bildraum vorherzusagen, was eine zentrale Herausforderung darstellt, um perfekte 3D-Merkmale aus 2D-visuellen Eingaben zu erhalten. Um dieses Problem anzugehen, verbessern einige Methoden die Belegungsvorhersage aus Sicht der Merkmalsverbesserung, einschließlich des Lernens aus der Vogelperspektive (BEV), der Drei-Ansicht-Ansicht (TPV) und der dreidimensionalen Voxeldarstellung.
BEV-basierte Methoden
Eine effektive Methode zum Erlernen der Belegung basiert auf der Vogelperspektive (Bird’s Eye View, BEV), die Funktionen bietet, die unempfindlich gegenüber Verdeckungen sind und bestimmte geometrische Tiefeninformationen enthalten. Durch das Erlernen starker BEV-Darstellungen kann eine robuste 3D-Belegungsszenenrekonstruktion erreicht werden. Zunächst wird ein 2D-Backbone-Netzwerk verwendet, um Bildmerkmale aus visuellen Eingaben zu extrahieren, dann werden BEV-Merkmale durch Blickpunkttransformation erhalten und schließlich wird die 3D-Belegungsvorhersage basierend auf der BEV-Merkmalsdarstellung abgeschlossen. Die BEV-basierte Methode ist in Abbildung 5 dargestellt.
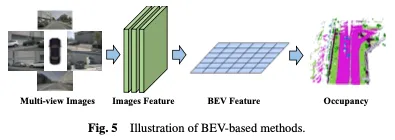
Ein einfacher Ansatz besteht darin, das BEV-Lernen aus anderen Aufgaben zu nutzen, beispielsweise durch die Verwendung von Methoden wie BEVDet und BEVFormer bei der 3D-Objekterkennung. Um diese Belegungslernmethoden zu erweitern, können Belegungsköpfe während des Trainings hinzugefügt oder ausgetauscht werden, um die endgültigen Ergebnisse zu erhalten. Diese Anpassung ermöglicht die Integration der Belegungsschätzung in bestehende BEV-basierte Frameworks und ermöglicht so die gleichzeitige Erkennung und Rekonstruktion der 3D-Belegung in einer Szene. Basierend auf dem leistungsstarken Basismodell BEVFormer nutzt OccTransformer Datenerweiterung, um die Vielfalt der Trainingsdaten zu erhöhen, die Fähigkeiten zur Modellverallgemeinerung zu verbessern und das leistungsstarke Bild-Backbone zu nutzen, um informativere Funktionen aus den Eingabedaten zu extrahieren. Außerdem werden ein 3D-Unet-Kopf eingeführt, um die räumlichen Informationen der Szene besser zu erfassen, sowie zusätzliche Verlustfunktionen zur Verbesserung der Modelloptimierung.
TPV-basierte Methoden
Während BEV-basierte Darstellungen im Vergleich zu Bildern gewisse Vorteile haben, da sie im Wesentlichen eine Top-Down-Projektion des 3D-Raums bieten, fehlt ihnen von Natur aus die Möglichkeit, eine einzelne Ebene zur Beschreibung zu verwenden feinkörnige 3D-Struktur einer Szene. Die auf drei Betrachtungswinkeln (TPV) basierende Methode nutzt drei orthogonale Projektionsebenen zur Modellierung der 3D-Umgebung, was die Darstellungsfähigkeit visueller Merkmale für die Belegungsvorhersage weiter verbessert. Zunächst werden Bildmerkmale mithilfe eines 2D-Backbone-Netzwerks aus visuellen Eingaben extrahiert. Anschließend werden diese Bildmerkmale in einen Raum mit drei Ansichten befördert, und schließlich wird eine 3D-Belegungsvorhersage basierend auf der Merkmalsdarstellung von drei Projektionsansichten erreicht. Die BEV-basierte Methode ist in Abbildung 7 dargestellt.
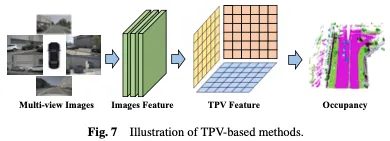
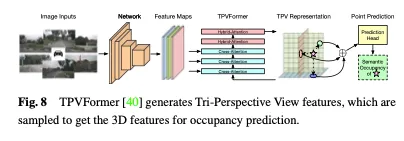
Zusätzlich zu BEV-Features generiert TPVFormer auf die gleiche Weise auch Features in Vorder- und Seitenansicht. Jede Ebene modelliert die 3D-Umgebung aus einer anderen Perspektive und ihre Kombination liefert eine umfassende Beschreibung der gesamten 3D-Struktur. Um insbesondere die Merkmale eines Punktes im dreidimensionalen Raum zu erhalten, projizieren wir ihn zunächst auf jede der drei Ebenen und verwenden dann bilineare Interpolation, um die Merkmale jedes projizierten Punkts zu erhalten. Anschließend fassen wir die drei Projektionsmerkmale zu synthetischen Merkmalen von 3D-Punkten zusammen. Daher kann die TPV-Darstellung 3D-Szenen mit beliebigen Auflösungen beschreiben und unterschiedliche Merkmale für verschiedene Punkte im 3D-Raum generieren. Darüber hinaus wird ein transformatorbasierter Encoder (TPVFormer) vorgeschlagen, um TPV-Merkmale effizient aus 2D-Bildern zu erhalten und Bildkreuzabfragen zwischen TPV-Rasterabfragen und entsprechenden 2D-Bildmerkmalen durchzuführen und so 2D-Informationen in einen 3D-Raum umzuwandeln. Schließlich ermöglicht die ansichtsübergreifende hybride Aufmerksamkeit zwischen TPV-Merkmalen die Interaktion zwischen den drei Ebenen. Die Gesamtarchitektur von TPVFormer ist in Abbildung 8 dargestellt.
Voxelbasierte Methoden
Neben der Umwandlung des 3D-Raums in eine projizierte Perspektive (wie BEV oder TPV) gibt es auch Methoden, die direkt auf der 3D-Voxeldarstellung operieren. Ein wesentlicher Vorteil dieser Methoden ist die Möglichkeit, direkt aus dem ursprünglichen 3D-Raum zu lernen und so den Informationsverlust zu minimieren. Durch die Nutzung roher dreidimensionaler Voxeldaten können diese Methoden vollständige räumliche Informationen effektiv erfassen und nutzen, was zu einem genaueren und umfassenderen Verständnis der Belegung führt. Zuerst wird ein 2D-Backbone-Netzwerk verwendet, um Bildmerkmale zu extrahieren, und dann wird ein speziell entwickelter Faltungsmechanismus verwendet, um 2D- und 3D-Darstellungen zu überbrücken, oder es wird ein abfragebasierter Ansatz verwendet, um die 3D-Darstellung direkt zu erhalten. Abschließend wird ein 3D-Belegungskopf verwendet, um die endgültige Vorhersage basierend auf der erlernten 3D-Darstellung zu vervollständigen. Die voxelbasierte Methode ist in Abbildung 9 dargestellt.
Faltungsbasierte Methoden
Ein Ansatz besteht darin, eine speziell entwickelte Faltungsarchitektur zu verwenden, um die Lücke von 2D zu 3D zu schließen und die 3D-Belegungsdarstellung zu erlernen. Ein prominentes Beispiel für diesen Ansatz ist die Einführung der U-Net-Architektur als Träger von Feature Bridging. Die U-Net-Architektur verwendet eine Encoder-Decoder-Struktur mit Skip-Verbindungen zwischen Upsampling- und Downsampling-Pfaden und behält so Low-Level- und High-Level-Feature-Informationen bei, um Informationsverluste zu minimieren. Durch Faltungsschichten unterschiedlicher Tiefe kann die U-Net-Struktur Merkmale unterschiedlichen Maßstabs extrahieren und dem Modell dabei helfen, lokale Details und globale Kontextinformationen im Bild zu erfassen, wodurch das Verständnis des Modells für komplexe Szenen verbessert und eine effektive Belegungsvorhersage durchgeführt wird.
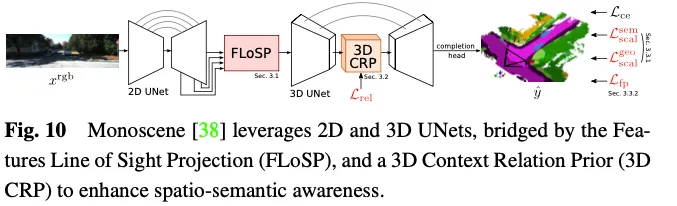
Monoscene nutzt U-net für eine visionsbasierte 3D-Belegungsvorhersage. Es führt einen Mechanismus namens zweidimensionale Merkmalslinienprojektion (FLoSP) ein, der die perspektivische Merkmalsprojektion verwendet, um zweidimensionale Merkmale auf den dreidimensionalen Raum zu projizieren, und den dreidimensionalen Merkmalsraum auf der Grundlage zweidimensionaler Merkmale berechnet Auf dem Bildgebungsprinzip und den Kameraparametern werden die Koordinaten jedes Punktes zum Abtasten von Merkmalen im dreidimensionalen Merkmalsraum verwendet. Diese Methode wandelt 2D-Features in eine einheitliche 3D-Feature-Map um und dient als Schlüsselkomponente, die 2D- und 3D-U-Net verbindet. Monoscene schlägt außerdem eine 3D Contextual Relation Prior (3D CRP)-Schicht vor, die am 3D-UNet-Engpass eingefügt wird und einen n-Wege-Voxel-zu-Voxel-semantischen Szenenbeziehungsgraphen lernt. Dies stellt dem Netzwerk ein globales Empfangsfeld zur Verfügung und verbessert das räumliche semantische Bewusstsein aufgrund des Beziehungserkennungsmechanismus. Die Gesamtarchitektur von Monoscene ist in Abbildung 10 dargestellt.
Abfragebasierte Methoden
Eine andere Möglichkeit, aus dem 3D-Raum zu lernen, besteht darin, eine Reihe von Abfragen zu generieren, um eine Darstellung der Szene zu erfassen. Bei diesem Ansatz werden abfragebasierte Techniken zur Generierung von Abfragevorschlägen verwendet, mit denen dann umfassende Darstellungen von 3D-Szenen erlernt werden. Anschließend werden Queraufmerksamkeits- und Selbstaufmerksamkeitsmechanismen auf Bilder angewendet, um die erlernten Darstellungen zu verfeinern und zu verbessern. Dieser Ansatz verbessert nicht nur das Szenenverständnis, sondern ermöglicht auch eine genaue Rekonstruktion und Belegungsvorhersage im 3D-Raum. Darüber hinaus bietet der abfragebasierte Ansatz eine größere Flexibilität bei der Anpassung und Optimierung auf der Grundlage verschiedener Datenquellen und Abfragestrategien und ermöglicht eine bessere Erfassung lokaler und globaler Kontextinformationen, um die 3D-Belegungsvorhersagedarstellung zu erleichtern.
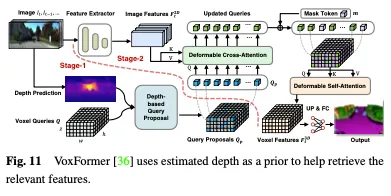
Die Tiefe kann als wertvoller Prior für die Auswahl von Belegungsabfragen verwendet werden. In Voxformer wird die geschätzte Tiefe als Aprior für die Vorhersage der Belegung und die Auswahl relevanter Abfragen verwendet. Nur besetzte Abfragen werden verwendet, um mithilfe deformierbarer Aufmerksamkeit Informationen aus Bildern zu sammeln. Die aktualisierten Abfragevorschläge und maskierten Token werden dann kombiniert, um Voxelmerkmale zu rekonstruieren. Voxformer extrahiert 2D-Merkmale aus RGB-Bildern und verwendet dann einen spärlichen Satz von 3D-Voxelabfragen, um diese 2D-Merkmale zu indizieren, wobei die Kameraprojektionsmatrix verwendet wird, um die 3D-Positionen mit dem Bildstrom zu verknüpfen. Voxelabfragen sind insbesondere lernbare Parameter von 3D-Netzformen, die dazu dienen, mithilfe von Aufmerksamkeitsmechanismen Merkmale aus Bildern in 3D-Volumina abzufragen. Das gesamte Framework ist eine zweistufige Kaskade, bestehend aus klassenunabhängigen Vorschlägen und klassenspezifischer Segmentierung. Stufe 1 generiert klassenunabhängige Abfragevorschläge, während Stufe 2 eine MAE-ähnliche Architektur übernimmt, um Informationen an alle Voxel weiterzugeben. Schließlich werden die Voxelmerkmale zur semantischen Segmentierung hochgetastet. Die Gesamtarchitektur von VoxFormer ist in Abbildung 11 dargestellt.
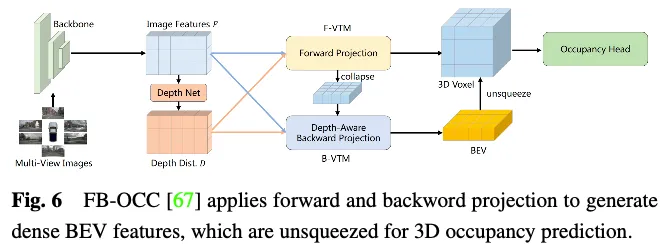
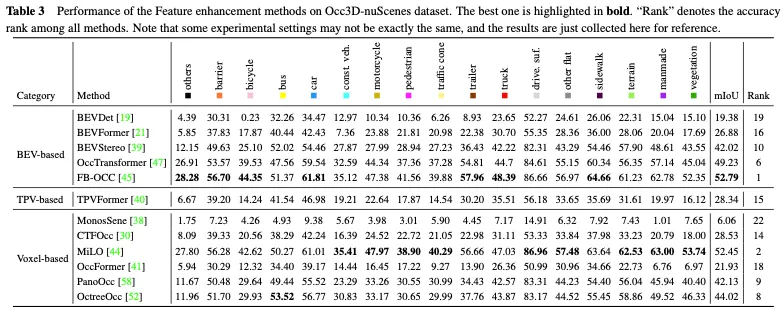
Der Leistungsvergleich der Methoden zur Funktionsverbesserung im Occ3D nuScenes-Datensatz ist in Tabelle 3 dargestellt. Die Ergebnisse zeigen, dass Methoden, die sich direkt mit Voxeldarstellungen befassen, häufig eine hohe Leistung erzielen, da sie während der Berechnung keinen nennenswerten Informationsverlust erleiden. Obwohl BEV-basierte Methoden nur einen projizierten Blickwinkel für die Merkmalsdarstellung haben, können sie aufgrund der reichhaltigen Informationen, die in der Vogelperspektive enthalten sind, und ihrer Unempfindlichkeit gegenüber Verdeckungs- und Maßstabsänderungen dennoch eine vergleichbare Leistung erzielen. Darüber hinaus sind durch die Rekonstruktion von 3D-Informationen aus mehreren komplementären Ansichten TPV-basierte Methoden (Three-View View) in der Lage, potenzielle geometrische Mehrdeutigkeiten zu mildern und einen umfassenderen Szenenkontext zu erfassen, wodurch eine effektive 3D-Belegungsvorhersage ermöglicht wird. Insbesondere nutzt FB-OCC sowohl Vorwärts- als auch Rückwärtsansichtskonvertierungsmodule, wodurch sie sich gegenseitig ergänzen können, um eine hochwertigere Darstellung reiner Elektrofahrzeuge zu erhalten und eine hervorragende Leistung zu erzielen. Dies zeigt, dass BEV-basierte Methoden auch großes Potenzial haben, die 3D-Belegungsvorhersage durch effektive Funktionserweiterung zu verbessern.
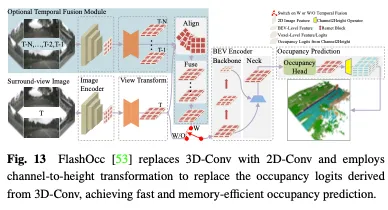
Bereitstellungsfreundliche Methoden
Das Erlernen von Belegungsdarstellungen direkt aus dem 3D-Raum ist aufgrund seines großen Umfangs und der komplexen Datenbeschaffenheit äußerst anspruchsvoll. Die hohe Dimensionalität und die intensive Berechnung, die mit der 3D-Voxeldarstellung verbunden sind, machen den Lernprozess sehr ressourcenintensiv, was für praktische Einsatzanwendungen nicht förderlich ist. Daher zielen Methoden zur Gestaltung einsatzfreundlicher 3D-Darstellungen darauf ab, die Rechenkosten zu senken und die Lerneffizienz zu verbessern. In diesem Abschnitt werden Methoden zur Bewältigung rechnerischer Herausforderungen bei der Schätzung der 3D-Szenenbelegung vorgestellt, wobei der Schwerpunkt auf der Entwicklung genauer und effizienter Methoden liegt, anstatt den gesamten 3D-Raum direkt zu verarbeiten. Zu den besprochenen Techniken gehören die perspektivische Zerlegung und die Grob-zu-Fein-Verfeinerung, die in jüngsten Arbeiten gezeigt wurden, um die Recheneffizienz von 3D-Belegungsvorhersagen zu verbessern.
Perspektivische Zerlegungsmethoden
Durch die Trennung von Blickpunktinformationen von 3D-Szenenmerkmalen oder deren Projektion in einen einheitlichen Darstellungsraum kann die Rechenkomplexität effektiv reduziert werden, wodurch das Modell robuster und verallgemeinerbarer wird. Die Kernidee dieser Methode besteht darin, die Darstellung der dreidimensionalen Szene von den Blickpunktinformationen zu entkoppeln, wodurch die Anzahl der Variablen reduziert wird, die im Feature-Lernprozess berücksichtigt werden müssen, und die Rechenkomplexität verringert wird. Durch die Entkopplung von Standpunktinformationen kann das Modell besser verallgemeinert und an unterschiedliche Standpunkttransformationen angepasst werden, ohne dass das gesamte Modell neu erlernt werden muss.
Um den Rechenaufwand beim Lernen aus dem gesamten 3D-Raum zu bewältigen, besteht ein gängiger Ansatz darin, Darstellungen aus der Vogelperspektive (BEV) und der Drei-Ansicht-Ansicht (TPV) zu verwenden. Durch die Zerlegung des 3D-Raums in diese einzelnen Ansichtsdarstellungen wird die Rechenkomplexität erheblich reduziert, während dennoch wesentliche Informationen für die Belegungsvorhersage erfasst werden. Die Kernidee besteht darin, zunächst aus der BEV- und TPV-Perspektive zu lernen und dann die vollständigen 3D-Belegungsinformationen durch die Kombination der aus diesen verschiedenen Ansichten gewonnenen Erkenntnisse wiederherzustellen. Diese perspektivische Zerlegungsstrategie ermöglicht eine effizientere und effektivere Belegungsschätzung im Vergleich zum direkten Lernen aus dem gesamten 3D-Raum.
Grob-zu-Fein-Methoden
Das Erlernen hochauflösender, feinkörniger globaler Voxelmerkmale direkt aus großen 3D-Räumen ist zeitaufwändig und herausfordernd. Daher haben einige Methoden damit begonnen, das Paradigma des Lernens von groben bis feinen Merkmalen zu untersuchen. Konkret lernt das Netzwerk zunächst eine grobe Darstellung aus einem Bild und verfeinert und stellt dann eine feinkörnige Darstellung der gesamten Szene wieder her. Dieser zweistufige Prozess trägt dazu bei, genauere und effizientere Vorhersagen der Szenenbelegung zu erzielen.
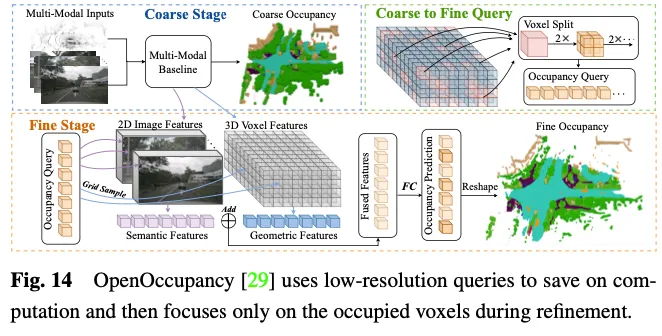
OpenOccupancy verfolgt einen zweistufigen Ansatz, um die Belegungsdarstellung im 3D-Raum zu erlernen. Wie in Abbildung 14 dargestellt.
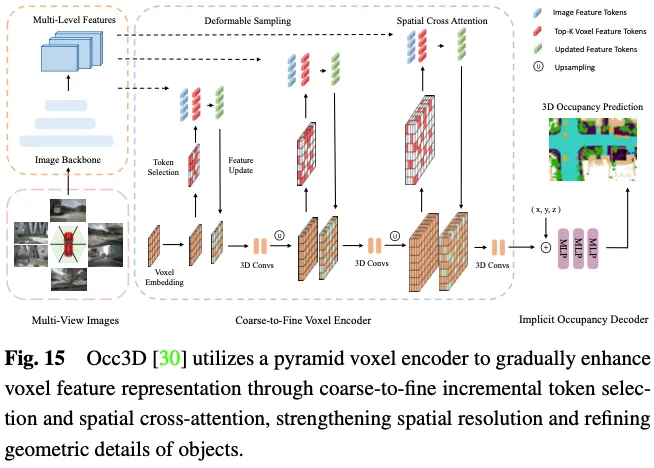
Die Vorhersage der 3D-Belegung erfordert eine detaillierte geometrische Darstellung, und die Verwendung aller 3D-Voxelmarkierungen zur Interaktion mit ROIs in Bildern mit mehreren Ansichten verursacht erhebliche Rechen- und Speicherkosten. Wie in Abbildung 15 dargestellt, schlägt Occ3D eine inkrementelle Token-Auswahlstrategie vor, um während des Cross-Attention-Berechnungsprozesses selektiv Vordergrund- und unsichere Voxel-Token auszuwählen und so eine Anpassung zu erreichen, ohne die Genauigkeit zu beeinträchtigen. Insbesondere wird am Anfang jeder Pyramidenschicht jede Voxelbezeichnung in einen binären Klassifikator eingegeben, um vorherzusagen, ob das Voxel leer ist oder nicht, überwacht durch binäre Ground-Truth-Belegungskarten, um den Klassifikator zu trainieren. PanoOcc schlägt vor, Objekterkennung und semantische Segmentierung nahtlos in einen gemeinsamen Lernrahmen zu integrieren, um ein umfassenderes Verständnis von 3D-Umgebungen zu fördern. Die Methode nutzt Voxelabfragen, um raumzeitliche Informationen aus Bildern mit mehreren Frames und mehreren Ansichten zu aggregieren und dabei Feature-Learning und Szenendarstellung in einer einheitlichen Belegungsdarstellung zusammenzuführen. Darüber hinaus untersucht es die spärliche Belegung des 3D-Raums durch die Einführung eines Belegungssparsitätsmoduls, das die Belegung während des Upsampling-Prozesses schrittweise von grob auf fein reduziert und so die Speichereffizienz erheblich verbessert.
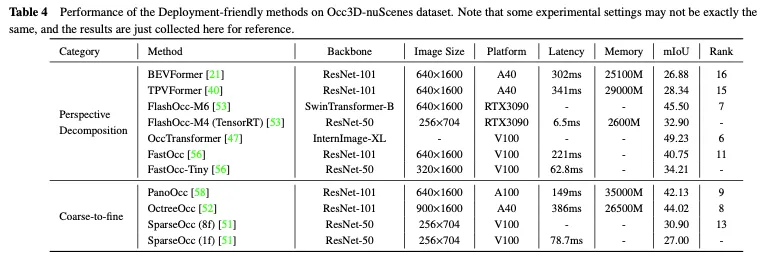
Der Leistungsvergleich einsatzfreundlicher Methoden im Occ3D nuScenes-Datensatz ist in Tabelle 4 dargestellt. Da die Ergebnisse aus verschiedenen Arbeiten mit Unterschieden in Bezug auf Backbone, Bildgröße und Computerplattform stammen, können nur einige vorläufige Schlussfolgerungen gezogen werden. Im Allgemeinen übertreffen bei ähnlichen experimentellen Einstellungen grob-zu-fein-Methoden die perspektivischen Zerlegungsmethoden hinsichtlich der Leistung aufgrund des geringeren Informationsverlusts, während die perspektivische Zerlegung normalerweise eine bessere Echtzeitleistung und eine geringere Speichernutzung aufweist. Darüber hinaus können Modelle mit schwereren Rückgraten und der Verarbeitung größerer Bilder eine bessere Genauigkeit erreichen, beeinträchtigen aber auch die Echtzeitleistung. Obwohl leichte Versionen von Methoden wie FlashOcc und FastOcc den Anforderungen für den praktischen Einsatz nahekommen, muss ihre Genauigkeit noch weiter verbessert werden. Für einsatzfreundliche Methoden streben sowohl die perspektivische Zerlegungsstrategie als auch die Grob-zu-Fein-Strategie danach, die Rechenlast kontinuierlich zu reduzieren und gleichzeitig die Genauigkeit der 3D-Belegungsvorhersage beizubehalten.
Etiketteneffiziente Methoden
Unter den vorhandenen Methoden zur Erstellung genauer Belegungsetiketten gibt es zwei grundlegende Schritte. Die erste besteht darin, LIDAR-Punktwolken zu sammeln, die Multi-View-Bildern entsprechen, und sie zur semantischen Segmentierung mit Anmerkungen zu versehen. Die andere besteht darin, die Tracking-Informationen dynamischer Objekte zu nutzen, um Punktwolken mit mehreren Frames durch komplexe Algorithmen zu verschmelzen. Beide Schritte sind recht teuer, was die Fähigkeit des Belegungsnetzwerks einschränkt, die große Anzahl von Multi-View-Bildern in autonomen Fahrszenarien zu nutzen. In den letzten Jahren wurden neuronale Strahlungsfelder (Nerf) häufig bei der zweidimensionalen Bildwiedergabe eingesetzt. Es gibt mehrere Methoden, die die vorhergesagte 3D-Belegung auf Nerf-ähnliche Weise in 2D-Karten darstellen und das Belegungsnetzwerk ohne die Beteiligung feinkörniger Annotationen oder LIDAR-Punktwolken trainieren, was die Kosten der Datenannotation erheblich senkt.
Annotationsfreie Methoden
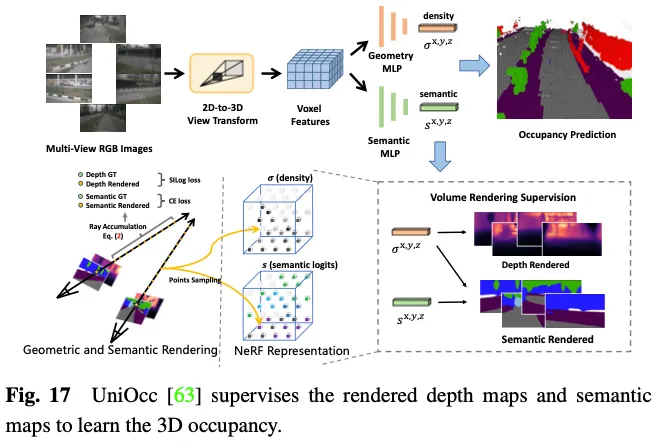
SimpleOccupancy generiert zunächst explizite 3D-Voxelmerkmale der Szene aus Bildmerkmalen über eine Ansichtstransformation und rendert sie dann im Nerf-Stil in eine 2D-Tiefenkarte. Die 2D-Tiefenkarte wird durch eine spärliche Tiefenkarte überwacht, die aus der LIDAR-Punktwolke generiert wird. Tiefenkarten werden auch zur Synthese von Umgebungsbildern zur Selbstüberwachung verwendet. UniOcc verwendet zwei separate MLPs, um 3D-Voxel-Logits in Voxeldichte und semantische Voxel-Logits umzuwandeln. Anschließend folgt UniOCC dem allgemeinen Volumenrendering, um Tiefenkarten und semantische Karten mit mehreren Ansichten zu erhalten, wie in Abbildung 17 dargestellt. Diese 2D-Karten werden durch Beschriftungen überwacht, die aus segmentierten LiDAR-Punktwolken generiert werden. RenderOcc erstellt NeRF-ähnliche volumetrische 3D-Darstellungen aus Bildern mit mehreren Ansichten und generiert 2D-Renderings mithilfe fortschrittlicher volumetrischer Rendering-Techniken, die eine direkte 3D-Überwachung nur mit 2D-Semantik- und Tiefenbezeichnungen ermöglichen können. Mit dieser 2D-Rendering-Überwachung erlernt das Modell die Multi-View-Konsistenz, indem es Schnittpunkte von Strahlen aus verschiedenen Kamerastümpfen analysiert, um ein tieferes Verständnis der geometrischen Beziehungen im 3D-Raum zu gewinnen. Darüber hinaus wird das Konzept der Hilfsstrahlen eingeführt, um Strahlen von benachbarten Frames zu nutzen, um die Multiview-Konsistenzbeschränkung des aktuellen Frames zu verbessern, und es wird eine dynamische Sampling-Trainingsstrategie entwickelt, um falsch ausgerichtete Strahlen zu filtern. Um das Ungleichgewichtsproblem zwischen dynamischen und statischen Kategorien anzugehen, führt OccFlowNet außerdem den Belegungsfluss ein, um den Szenenfluss für jedes dynamische Voxel basierend auf 3D-Begrenzungsrahmen vorherzusagen. Mithilfe von Voxel-Streaming können dynamische Voxel im Zeitrahmen an die richtige Position verschoben werden, wodurch die Notwendigkeit einer dynamischen Objektfilterung während des Renderns entfällt. Während des Trainings werden korrekt vorhergesagte Voxel und Voxel innerhalb von Begrenzungsrahmen mithilfe von Flüssen transformiert, um sie an der Zielposition im Zeitrahmen auszurichten, gefolgt von einer Gitterausrichtung mithilfe abstandsbasierter gewichteter Interpolation.
Der obige Ansatz macht explizite 3D-Belegungsanmerkungen überflüssig, wodurch der Aufwand für manuelle Anmerkungen erheblich reduziert wird. Allerdings verlassen sie sich immer noch auf Lidar-Punktwolken, um Tiefen- oder semantische Beschriftungen zur Überwachung der gerenderten Karten bereitzustellen, wodurch noch kein vollständig selbstüberwachter Rahmen für die 3D-Belegungsvorhersage erreicht werden kann.
LiDAR-freie Methoden
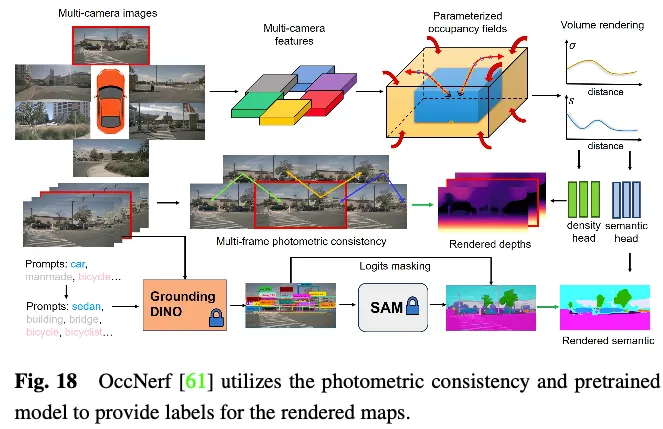
OccNerf verwendet keine LiDAR-Punktwolken, um Tiefe und semantische Beschriftungen bereitzustellen. Stattdessen wird, wie in Abbildung 18 dargestellt, ein parametrisiertes Belegungsfeld verwendet, um grenzenlose Außenszenen zu verarbeiten, die Sampling-Strategie neu organisiert und das Belegungsfeld mithilfe von Volumenrendering in eine Tiefenkarte mit mehreren Kameras umgewandelt und schließlich von mehreren Bildern überwacht photometrische Konsistenz. Darüber hinaus nutzt die Methode ein vorab trainiertes semantisches Segmentierungsmodell mit offenem Vokabular, um semantische 2D-Bezeichnungen zu generieren, und überwacht das Modell, um semantische Informationen an besetzte Felder zu liefern. Hinter den Kulissen wird eine einzelne Bildsequenz verwendet, um die Fahrszene zu rekonstruieren. Es behandelt die Kegelstumpfmerkmale des Eingabebilds als Dichtefeld und rendert eine Zusammensetzung aus den anderen Ansichten. Das gesamte Modell wird mit einem speziell entwickelten Bildrekonstruktionsverlust trainiert. SelfOcc sagt vorzeichenbehaftete Distanzfeldwerte von BEV- oder TPV-Features voraus, um 2D-Tiefenkarten zu rendern. Darüber hinaus werden auch Originalfarb- und semantische Karten gerendert und durch Beschriftungen überwacht, die aus Bildsequenzen mit mehreren Ansichten generiert werden.
Diese Methoden umgehen die Notwendigkeit von Tiefen- oder semantischen Beschriftungen aus LIDAR-Punktwolken. Stattdessen nutzen sie Bilddaten oder vorab trainierte Modelle, um diese Etiketten zu erhalten, was einen wirklich selbstüberwachten Rahmen für die 3D-Belegungsvorhersage ermöglicht. Obwohl mit diesen Methoden Trainingsmuster erzielt werden können, die der praktischen Anwendungserfahrung am besten entsprechen, sind weitere Untersuchungen erforderlich, um eine zufriedenstellende Leistung zu erzielen.
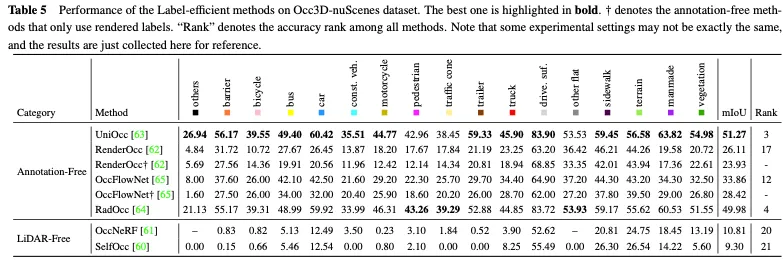
Tabelle 5 zeigt den Leistungsvergleich etiketteneffizienter Methoden für den Occ3D nuScenes-Datensatz. Die meisten annotationsfreien Methoden nutzen die 2D-Rendering-Überwachung als Ergänzung zur expliziten 3D-Belegungsüberwachung und erzielen bestimmte Leistungsverbesserungen. Unter ihnen erzielten UniOcc und RadOcc unter allen Methoden sogar hervorragende Platzierungen von 3 bzw. 4, was voll und ganz beweist, dass der annotationsfreie Mechanismus die Extraktion zusätzlicher wertvoller Informationen fördern kann. Wenn nur die 2D-Rendering-Überwachung eingesetzt wird, können sie immer noch eine vergleichbare Genauigkeit erreichen, was verdeutlicht, dass es möglich ist, die Kosten für die explizite 3D-Belegungsanmerkung einzusparen. Der Lidar-freie Ansatz schafft ein umfassendes selbstüberwachtes Framework für die 3D-Belegungsvorhersage, wodurch die Notwendigkeit von Tags und Lidar-Daten weiter entfällt. Da es der Punktwolke selbst jedoch an präzisen Tiefen- und Geometrieinformationen mangelt, ist ihre Leistung stark eingeschränkt.
Zukunftsausblick
Motiviert durch die oben genannten Ansätze fassen wir aktuelle Trends zusammen und schlagen mehrere wichtige Forschungsrichtungen vor, die das Potenzial haben, visionbasiertes Sehen aus Daten-, Methoden- und Aufgabenperspektive erheblich voranzutreiben .
Datenebene
Die Beschaffung ausreichender realer Fahrdaten ist entscheidend für die Verbesserung der Gesamtfähigkeiten des autonomen Fahrwahrnehmungssystems. Die Datengenerierung ist ein vielversprechender Ansatz, da sie keine Anschaffungskosten verursacht und die Flexibilität bietet, die Datenvielfalt nach Bedarf zu manipulieren. Obwohl einige Methoden Hinweise wie Text verwenden, um den Inhalt der generierten Fahrdaten zu steuern, können sie die Genauigkeit der räumlichen Informationen nicht garantieren. Im Gegensatz dazu bietet 3D Occupancy eine feinkörnige und umsetzbare Darstellung der Szene und erleichtert im Vergleich zu Punktwolken, Multi-View-Bildern und BEV-Layouts die steuerbare Datengenerierung und die Anzeige räumlicher Informationen. WoVoGen schlägt eine volumenbewusste Diffusion vor, die die 3D-Belegung realistischen Bildern mit mehreren Ansichten zuordnen kann. Nachdem Änderungen an der 3D-Belegung vorgenommen wurden, z. B. das Hinzufügen eines Baums oder das Ändern eines Autos, synthetisiert das Diffusionsmodell die entsprechende neue Fahrszene. Die modifizierte dreidimensionale Belegung erfasst dreidimensionale Positionsinformationen und stellt so die Authentizität der synthetischen Daten sicher.
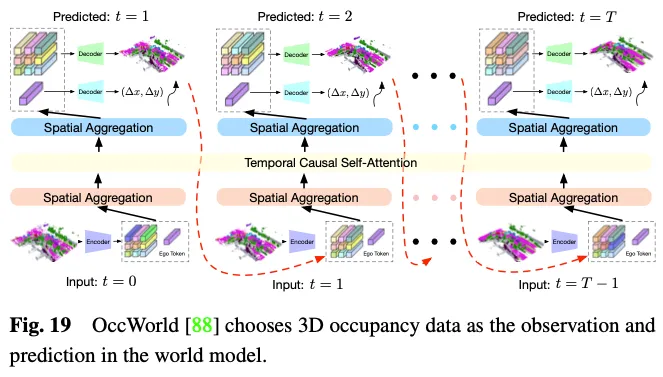
Das Weltmodell des autonomen Fahrens gewinnt immer mehr an Bedeutung. Es bietet einen einfachen und eleganten Rahmen, der die Fähigkeit des Modells verbessert, die gesamte Szene basierend auf Umgebungseingabebeobachtungen zu verstehen und entsprechende dynamische Szenenentwicklungsdaten direkt auszugeben. Die Nutzung der 3D-Belegung als Umgebungsbeobachtung in einem Weltmodell hat klare Vorteile, da sie gesamte Fahrszenendaten fachmännisch und detailliert darstellen kann. Wie in Abbildung 19 dargestellt, wählt OccWorld die 3D-Belegung als Eingabe des Weltmodells und verwendet ein GPT-ähnliches Modul, um vorherzusagen, wie zukünftige 3D-Belegungsdaten aussehen sollten. UniWorld nutzt handelsübliche BEV-basierte 3D-Belegungsmodelle, erstellt aber auch ein Weltmodell, indem vergangene Multi-View-Bilder verarbeitet werden, um zukünftige 3D-Belegungsdaten vorherzusagen. Unabhängig vom Mechanismus besteht jedoch zwangsläufig eine Domänenlücke zwischen generierten Daten und realen Daten. Um dieses Problem zu lösen, besteht ein möglicher Ansatz darin, die 3D-Belegungsvorhersage mit der neuen 3D-AIGC-Methode (Artificial Intelligence Generated Content) zu kombinieren, um realistischere Szenendaten zu generieren, während ein anderer Ansatz darin besteht, Domänenanpassungsmethoden zu kombinieren, um die Feldlücke zu verringern.
Methodologische Ebene
Wenn es um 3D-Belegungsvorhersagemethoden geht, gibt es fortlaufende Herausforderungen, die innerhalb der zuvor skizzierten Kategorien weitere Aufmerksamkeit erfordern: funktionssteigernde Methoden, einsatzfreundliche Methoden und kennzeichnungseffiziente Methoden. Methoden zur Funktionsverbesserung müssen dahingehend entwickelt werden, dass sie die Leistung deutlich verbessern und gleichzeitig den Verbrauch von Rechenressourcen kontrollierbar halten. Es sollte ein einsatzfreundlicher Ansatz im Auge behalten werden, um die Speichernutzung und Latenz zu reduzieren und gleichzeitig sicherzustellen, dass Leistungseinbußen minimiert werden. Etiketteneffiziente Methoden sollten dahingehend entwickelt werden, den Bedarf an teuren Anmerkungen zu reduzieren und gleichzeitig eine zufriedenstellende Leistung zu erzielen. Das ultimative Ziel könnte darin bestehen, ein einheitliches Framework zu erreichen, das Funktionserweiterungen, Bereitstellungsfreundlichkeit und Kennzeichnungseffizienz kombiniert, um die Erwartungen realer autonomer Fahranwendungen zu erfüllen.
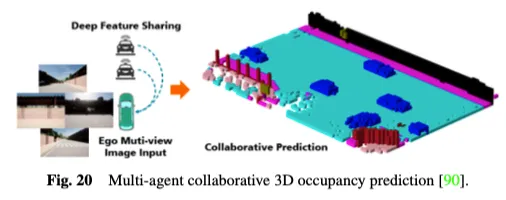
Darüber hinaus sind bestehende Einzelagenten-Wahrnehmungssysteme für autonomes Fahren von Natur aus nicht in der Lage, wichtige Probleme zu lösen, wie z. B. die Empfindlichkeit gegenüber Verdeckungen, unzureichende Fernerfassungsfähigkeiten und ein begrenztes Sichtfeld, was es schwierig macht, ein umfassendes Umweltbewusstsein zu erreichen. Um den Engpass von Einzelagenten zu überwinden, eröffnen kollaborative Erfassungsmethoden mit mehreren Agenten eine neue Dimension, die es Fahrzeugen ermöglicht, ergänzende Informationen mit anderen Verkehrselementen auszutauschen, um eine Gesamtwahrnehmung der Umgebung zu erhalten. Wie in Abbildung 20 dargestellt, nutzt die kollaborative 3D-Belegungsvorhersagemethode mit mehreren Agenten die Leistungsfähigkeit der kollaborativen Erfassung und des Lernens für die 3D-Belegungsvorhersage. Durch die gemeinsame Nutzung von Funktionen zwischen vernetzten automatisierten Fahrzeugen kann ein tieferes Verständnis der 3D-Straßenumgebung gewonnen werden. CoHFF ist das erste visionsbasierte kollaborative semantische Belegungsvorhersage-Framework, das die lokale semantische 3D-Belegungsvorhersage durch eine hybride Fusion von Semantik- und Belegungsaufgabenmerkmalen sowie komprimierten orthogonalen Aufmerksamkeitsmerkmalen, die zwischen Fahrzeugen geteilt werden, verbessert und so die Leistung erheblich verbessert Das Fahrradsystem. Allerdings erfordert diese Methode oft die gleichzeitige Kommunikation mit mehreren Agenten, was zu einem Widerspruch zwischen Genauigkeit und Bandbreite führt. Daher ist es eine interessante Forschungsrichtung, herauszufinden, welche Agenten am meisten Koordination benötigen, und die Bereiche zu identifizieren, in denen Zusammenarbeit am wertvollsten ist, um das beste Gleichgewicht zwischen Genauigkeit und Geschwindigkeit zu erreichen.
Aufgabenebene
In aktuellen 3D-Belegungsbenchmarks haben einige Kategorien eine klare Semantik, wie zum Beispiel „Auto“, „Fußgänger“ und „LKW“. Im Gegensatz dazu ist die Semantik anderer Kategorien wie „künstlich“ und „Vegetation“ tendenziell vage und allgemein. Diese Kategorien enthalten eine breite, undefinierte Semantik und sollten in detailliertere Kategorien unterteilt werden, um detaillierte Beschreibungen von Fahrszenarien bereitzustellen. Darüber hinaus werden unbekannte Kategorien, die noch nie zuvor gesehen wurden, häufig als allgemeines Hindernis für die flexible Erweiterung der Wahrnehmung neuer Kategorien auf der Grundlage menschlicher Hinweise angesehen. Für dieses Problem zeigen Aufgaben mit offenem Vokabular eine starke Leistung bei der 2D-Bildwahrnehmung und können erweitert werden, um 3D-Belegungsvorhersageaufgaben zu verbessern. OVO schlägt ein Framework vor, das die 3D-Belegungsvorhersage mit offenem Vokabular unterstützt. Es nutzt eingefrorene 2D-Segmentierer und Text-Encoder, um semantische Referenzen für offene Vokabulare zu erhalten. Anschließend werden drei verschiedene Ausrichtungsebenen verwendet, um das 3D-Belegungsmodell zu extrahieren, sodass offene Wortvorhersagen durchgeführt werden können. POP-3D hat ein selbstüberwachtes Framework entwickelt, das mithilfe leistungsstarker vorab trainierter visueller Sprachmodelle drei Modalitäten kombiniert. Es erleichtert Open-Lexicon-Aufgaben wie die Zero-Shot-Belegungssegmentierung und den textbasierten 3D-Abruf.
Die Wahrnehmung dynamischer Veränderungen in der Umgebung ist entscheidend für die sichere und zuverlässige Ausführung nachgelagerter Aufgaben beim autonomen Fahren. Obwohl 3D-Belegungsvorhersagen auf der Grundlage aktueller Beobachtungen dichte Belegungsdarstellungen großräumiger Szenen liefern können, beschränken sie sich meist auf die Darstellung des aktuellen 3D-Raums und berücksichtigen nicht die zukünftigen Zustände umgebender Objekte entlang der Zeitachse. Kürzlich wurden mehrere Methoden vorgeschlagen, um zeitliche Informationen weiter zu berücksichtigen und 4D-Belegungsvorhersageaufgaben einzuführen, die in realen autonomen Fahrszenarien praktischer sind. Cam4Occ setzt erstmals einen neuen Maßstab für die 4D-Belegungsvorhersage unter Verwendung des weit verbreiteten nuScenes-Datensatzes. Der Benchmark umfasst verschiedene Metriken zur Bewertung der Belegungsprognosen für General Movable Objects (GMO) bzw. General Static Objects (GSO). Darüber hinaus werden mehrere Basismodelle bereitgestellt, um den Aufbau eines 4D-Belegungsvorhersage-Frameworks zu veranschaulichen. Obwohl die 3D-Belegungsvorhersageaufgabe mit offenem Vokabular und die 4D-Belegungsvorhersageaufgabe darauf abzielen, die Wahrnehmungsfähigkeiten des autonomen Fahrens in offenen dynamischen Umgebungen aus verschiedenen Perspektiven zu verbessern, werden sie dennoch als unabhängige Optimierungsaufgaben betrachtet. Ein modulares, aufgabenbasiertes Paradigma, bei dem mehrere Module inkonsistente Optimierungsziele haben, kann zu Informationsverlust und angehäuften Fehlern führen. Die Kombination offener dynamischer Belegungsvorhersagen mit durchgängigen autonomen Fahraufgaben und der direkten Zuordnung von Rohsensordaten zu Steuersignalen ist eine vielversprechende Forschungsrichtung.
Das obige ist der detaillierte Inhalt vonWerfen Sie einen Blick auf die Vergangenheit und Gegenwart von Occ und autonomem Fahren! Die erste Rezension fasst die drei Hauptthemen Funktionserweiterung/Massenproduktionsbereitstellung/effiziente Annotation umfassend zusammen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!