
Heim >Technologie-Peripheriegeräte >KI >Schließlich untersuchte jemand die Überanpassung kleiner Modelle: Zwei Drittel von ihnen wiesen Datenverschmutzung auf, und Microsoft Phi-3 und Mixtral 8x22B wurden benannt
Schließlich untersuchte jemand die Überanpassung kleiner Modelle: Zwei Drittel von ihnen wiesen Datenverschmutzung auf, und Microsoft Phi-3 und Mixtral 8x22B wurden benannt

- 王林nach vorne
- 2024-05-04 13:05:13699Durchsuche
Die Verbesserung der Argumentationsfähigkeiten großer Sprachmodelle ist eine der wichtigsten Richtungen der aktuellen Forschung. Bei dieser Art von Aufgaben scheinen viele kleine Modelle, die kürzlich veröffentlicht wurden, gute Leistungen zu erbringen und solche Aufgaben gut zu bewältigen. Zum Beispiel Microsofts Phi-3, Mistral 8x22B und andere Modelle.
Forscher wiesen darauf hin, dass es im aktuellen Bereich der Großmodellforschung ein zentrales Problem gibt: Viele Studien versäumen es, die Fähigkeiten bestehender LLMs genau zu bewerten. Dies deutet darauf hin, dass wir mehr Zeit damit verbringen müssen, das aktuelle LLM-Fähigkeitsniveau zu bewerten und zu testen.

Das liegt daran, dass die meisten aktuellen Forschungsergebnisse Testsätze wie GSM8k, MATH, MBPP, HumanEval, SWEBench usw. als Benchmarks verwenden. Da das Modell anhand eines großen Datensatzes aus dem Internet trainiert wird, kann der Trainingsdatensatz Beispiele enthalten, die den Fragen im Benchmark sehr ähnlich sind.
Diese Art der Kontamination kann dazu führen, dass die Denkfähigkeit des Modells falsch eingeschätzt wird – Es kann sein, dass sie während des Trainingsprozesses einfach durch die Frage verwirrt werden und zufällig die richtige Antwort rezitieren.
Gerade wurde in einem Artikel von Scale AI eine eingehende Untersuchung der beliebtesten großen Modelle durchgeführt, darunter OpenAIs GPT-4, Gemini, Claude, Mistral, Llama, Phi, Abdin und andere Serien mit unterschiedlichen Parametermengen . Modell.
Die Testergebnisse bestätigen einen weit verbreiteten Verdacht: Viele Modelle sind durch Benchmark-Daten verunreinigt.
Papiertitel: A Careful Examination of Large Language Model Performance on Grade School Arithmetic
Papierlink: https://arxiv.org/pdf/2405.00332
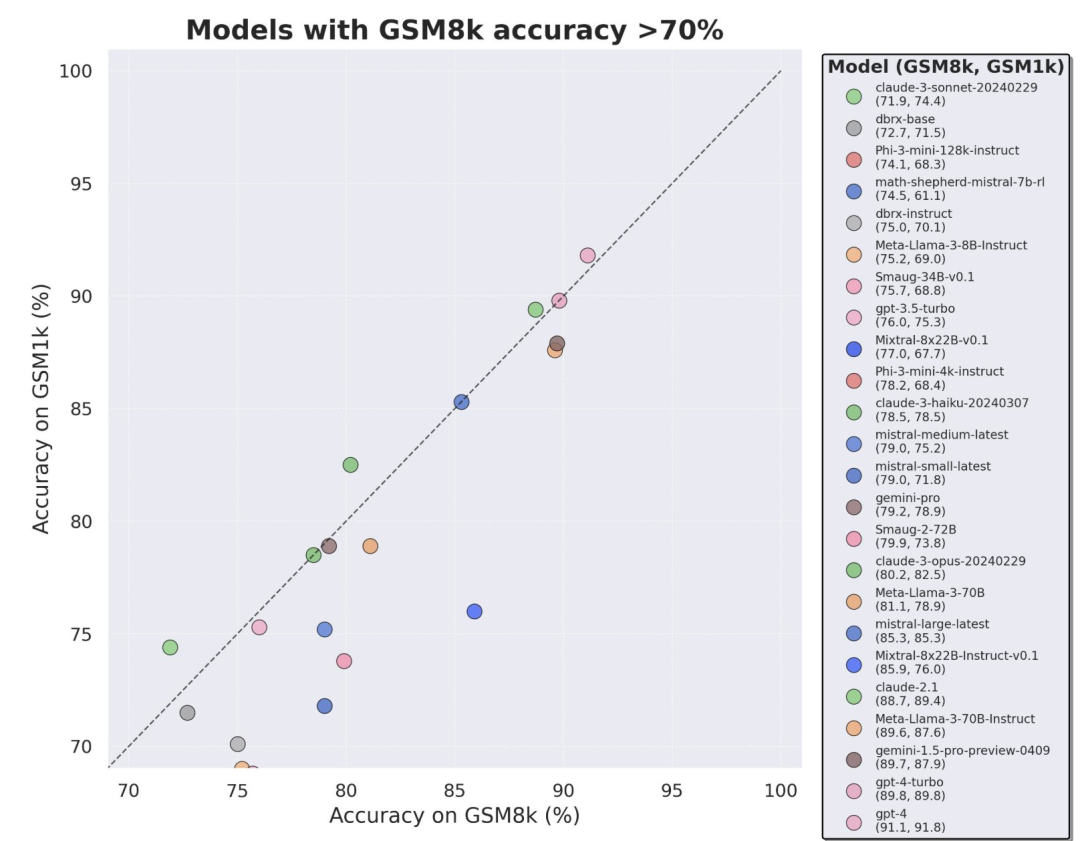
Um Daten zu vermeiden Aufgrund der Verschmutzungsprobleme verwendeten die Forscher von Scale AI kein LLM oder andere synthetische Datenquellen und verließen sich bei der Erstellung des GSM1k-Datensatzes vollständig auf manuelle Annotation. Ähnlich wie GSM8k enthält GSM1k 1250 mathematische Probleme der Grundstufe. Um faire Benchmark-Tests zu gewährleisten, haben die Forscher ihr Bestes gegeben, um sicherzustellen, dass die Schwierigkeitsverteilung von GSM1k der von GSM8k ähnelt. Auf GSM1k verglichen die Forscher eine Reihe führender Open-Source- und Closed-Source-Sprachmodelle im großen Maßstab und stellten fest, dass das Modell mit der schlechtesten Leistung auf GSM1k 13 % schlechter abschnitt als auf GSM8k.
Besonders die Modellreihen Mistral und Phi, die für ihre geringe Stückzahl und hohe Qualität bekannt sind, weisen laut Testergebnissen von GSM1k durchweg Hinweise auf Überanpassung auf.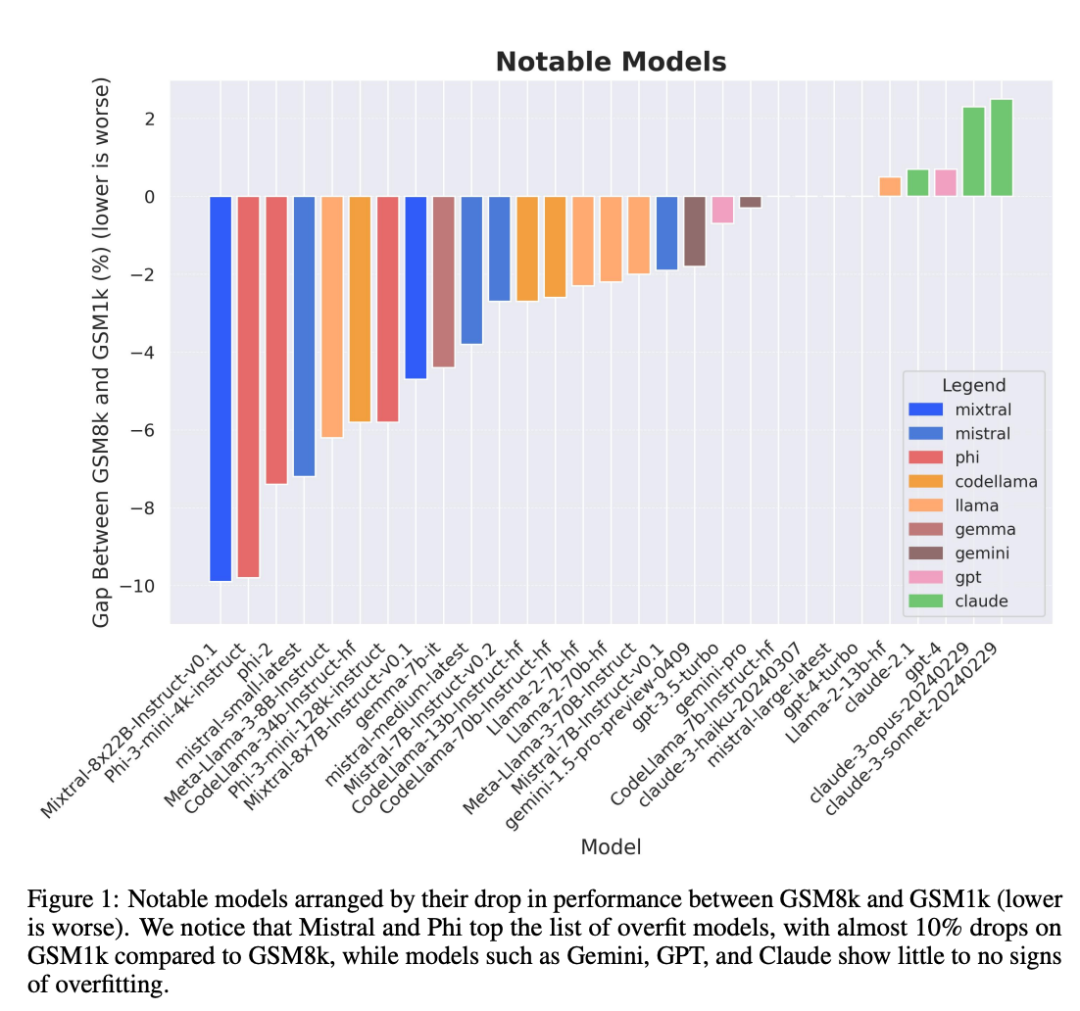
Allerdings haben die Serien Gemini, GPT, Claude und Llama2 nur sehr wenige Anzeichen einer Anpassung gezeigt. Darüber hinaus waren alle Modelle, einschließlich des am stärksten überangepassten Modells, immer noch in der Lage, erfolgreich auf neue mathematische Probleme der Grundschule zu verallgemeinern, wenn auch manchmal mit geringeren Erfolgsraten als in den Basisdaten angegeben.

GSM1k-Datensatz
GSM1k enthält 1250 Mathematikfragen für die Grundschule. Diese Probleme können nur mit einfachen mathematischen Überlegungen gelöst werden. Scale AI zeigte jedem menschlichen Annotator drei Beispielfragen aus GSM8k und forderte ihn auf, neue Fragen mit ähnlichem Schwierigkeitsgrad zu stellen, was zum GSM1k-Datensatz führte. Forscher forderten menschliche Annotatoren auf, keine fortgeschrittenen mathematischen Konzepte zu verwenden und nur grundlegende Arithmetik (Addition, Subtraktion, Multiplikation und Division) zur Formulierung von Fragen zu verwenden. Wie bei GSM8k sind die Lösungen aller Probleme positive ganze Zahlen. Bei der Erstellung des GSM1k-Datensatzes wurde kein Sprachmodell verwendet.
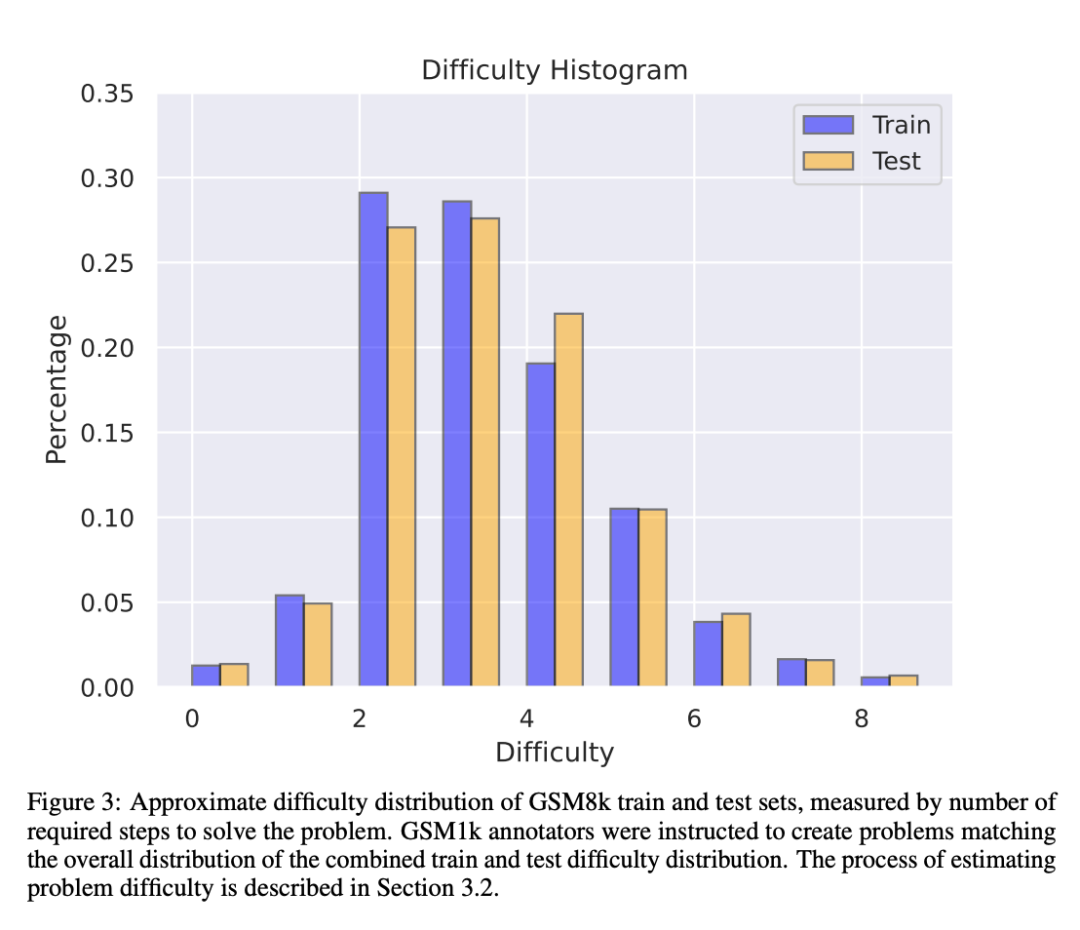
Um Datenverschmutzungsprobleme mit dem GSM1k-Datensatz zu vermeiden, wird Scale AI den Datensatz zu diesem Zeitpunkt nicht öffentlich veröffentlichen, sondern das GSM1k-Bewertungsframework als Open Source bereitstellen, das auf dem LM Evaluation Harness von EleutherAI basiert.
Aber Scale AI verspricht: Der vollständige GSM1k-Datensatz wird unter der MIT-Lizenz veröffentlicht, nachdem zuerst eine der folgenden beiden Bedingungen erfüllt ist: (1) Es gibt drei Open-Source-Modelle, die auf verschiedenen vorab trainierten Grundmodelllinien basieren. Bis Ende 2025 eine Genauigkeit von 95 % auf GSM1k erreichen. Zu diesem Zeitpunkt ist es wahrscheinlich, dass Grundschulmathematik kein gültiger Maßstab für die Beurteilung der LLM-Leistung mehr sein wird.
Um proprietäre Modelle zu bewerten, werden Forscher Datensätze über APIs veröffentlichen. Der Grund für diesen Release-Ansatz liegt darin, dass die Autoren glauben, dass LLM-Anbieter im Allgemeinen keine API-Datenpunkte zum Trainieren von Modellmodellen verwenden. Wenn jedoch GSM1k-Daten über die API verloren gehen, haben die Autoren Datenpunkte beibehalten, die nicht im endgültigen GSM1k-Datensatz enthalten sind, und diese Backup-Datenpunkte werden mit GSM1k freigegeben, wenn die oben genannten Bedingungen erfüllt sind.
Sie hoffen, dass künftige Benchmark-Releases einem ähnlichen Muster folgen werden – sie werden zunächst nicht öffentlich veröffentlicht, sondern im Voraus versprochen, sie zu einem späteren Zeitpunkt oder wenn eine bestimmte Bedingung erfüllt ist, um Manipulationen zu verhindern.
Auch trotz der Bemühungen von Scale AI, maximale Konsistenz zwischen GSM8k und GSM1k sicherzustellen. Der Testsatz von GSM8k wurde jedoch öffentlich veröffentlicht und häufig für Modelltests verwendet, sodass GSM1k und GSM8k unter idealen Bedingungen nur Näherungswerte sind. Die folgenden Bewertungsergebnisse werden erhalten, wenn die Verteilungen von GSM8k und GSM1k nicht genau gleich sind.
Bewertungsergebnisse
Zur Bewertung des Modells verwendeten die Forscher den LM Evaluation Harness-Zweig von EleutherAI und verwendeten die Standardeinstellungen. Die laufenden Eingabeaufforderungen für GSM8k- und GSM1k-Probleme sind dieselben. Sie wählen zufällig 5 Proben aus dem GSM8k-Trainingssatz aus, was auch die Standardkonfiguration in diesem Bereich ist (vollständige Informationen zu Eingabeaufforderungen finden Sie in Anhang B).
Alle Open-Source-Modelle werden bei einer Temperatur von 0°C evaluiert, um die Wiederholbarkeit sicherzustellen. Das LM Assessment Kit extrahiert die letzte numerische Antwort in der Antwort und vergleicht sie mit der richtigen Antwort. Daher werden Modellantworten, die „richtige“ Antworten in einem Format liefern, das nicht mit der Stichprobe übereinstimmt, als falsch markiert.
Wenn das Modell bei Open-Source-Modellen mit der Bibliothek kompatibel ist, wird vLLM verwendet, um die Modellinferenz zu beschleunigen. Andernfalls wird standardmäßig die Standard-HuggingFace-Bibliothek für die Inferenz verwendet. Closed-Source-Modelle werden über die LiteLLM-Bibliothek abgefragt, die das API-Aufrufformat für alle evaluierten proprietären Modelle vereinheitlicht. Alle API-Modellergebnisse stammen aus Abfragen zwischen dem 16. und 28. April 2024 und verwenden Standardeinstellungen.
Die Forscher wählten die bewerteten Modelle aufgrund ihrer Beliebtheit aus und bewerteten auch mehrere weniger bekannte Modelle, die im OpenLLMLeaderboard einen hohen Rang einnahmen.
Interessanterweise fanden die Forscher dabei Beweise für das Goodhart-Gesetz: Viele Modelle schnitten bei GSM1k viel schlechter ab als bei GSM8k, was darauf hindeutet, dass sie sich hauptsächlich an der GSM8k-Benchmark orientierten und nicht die Modellschlussfähigkeiten wirklich verbesserten. Die Leistung aller Modelle ist im Anhang D unten dargestellt.
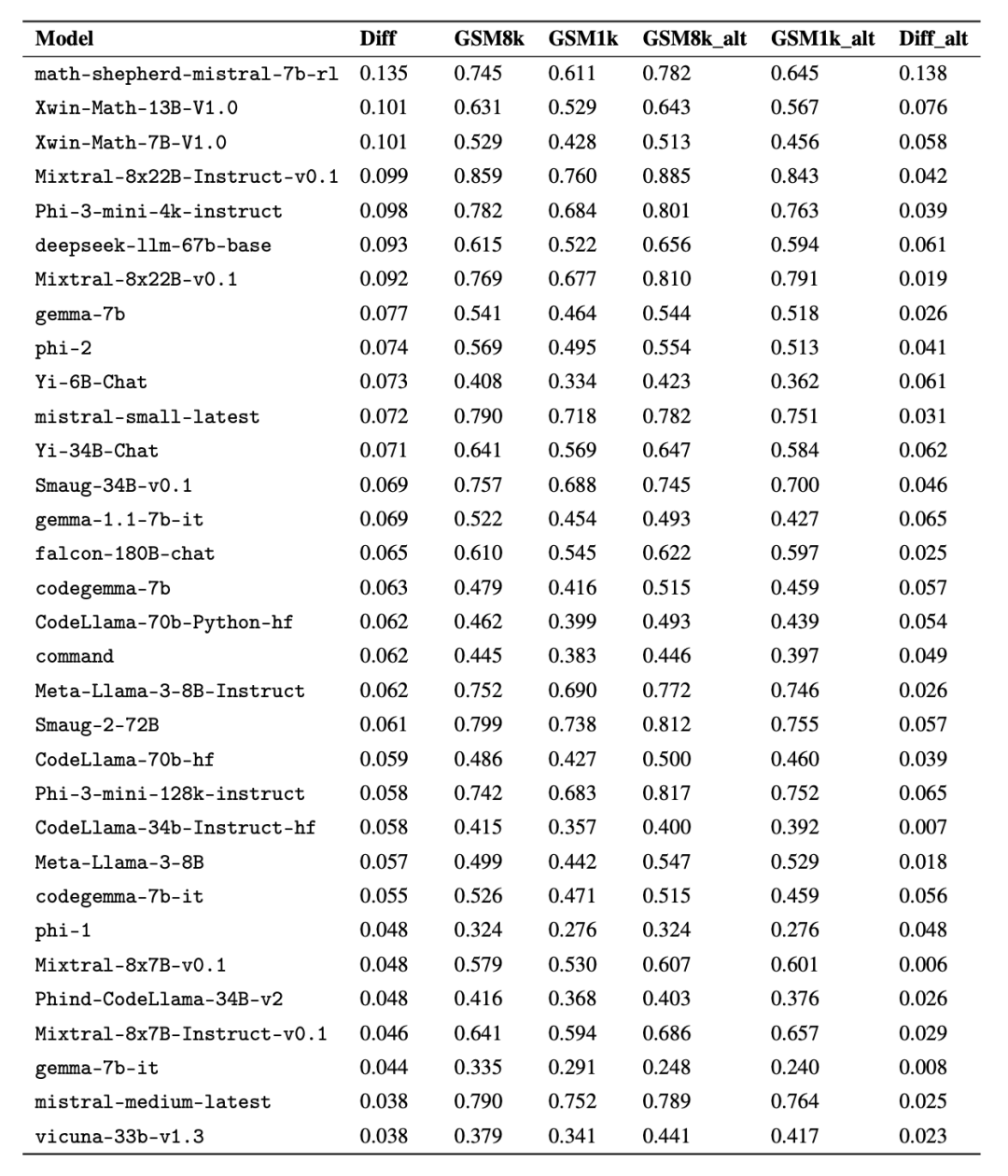
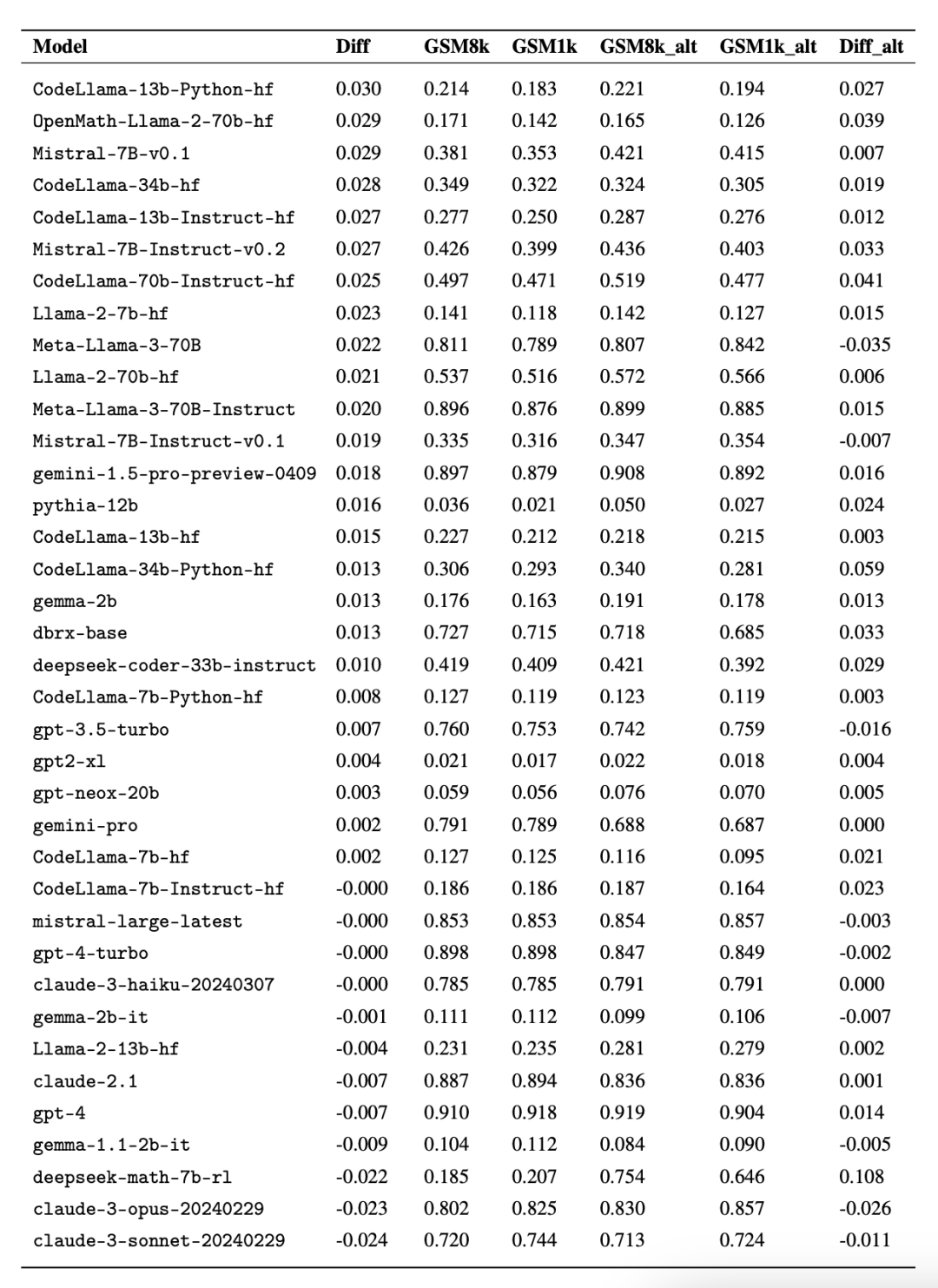
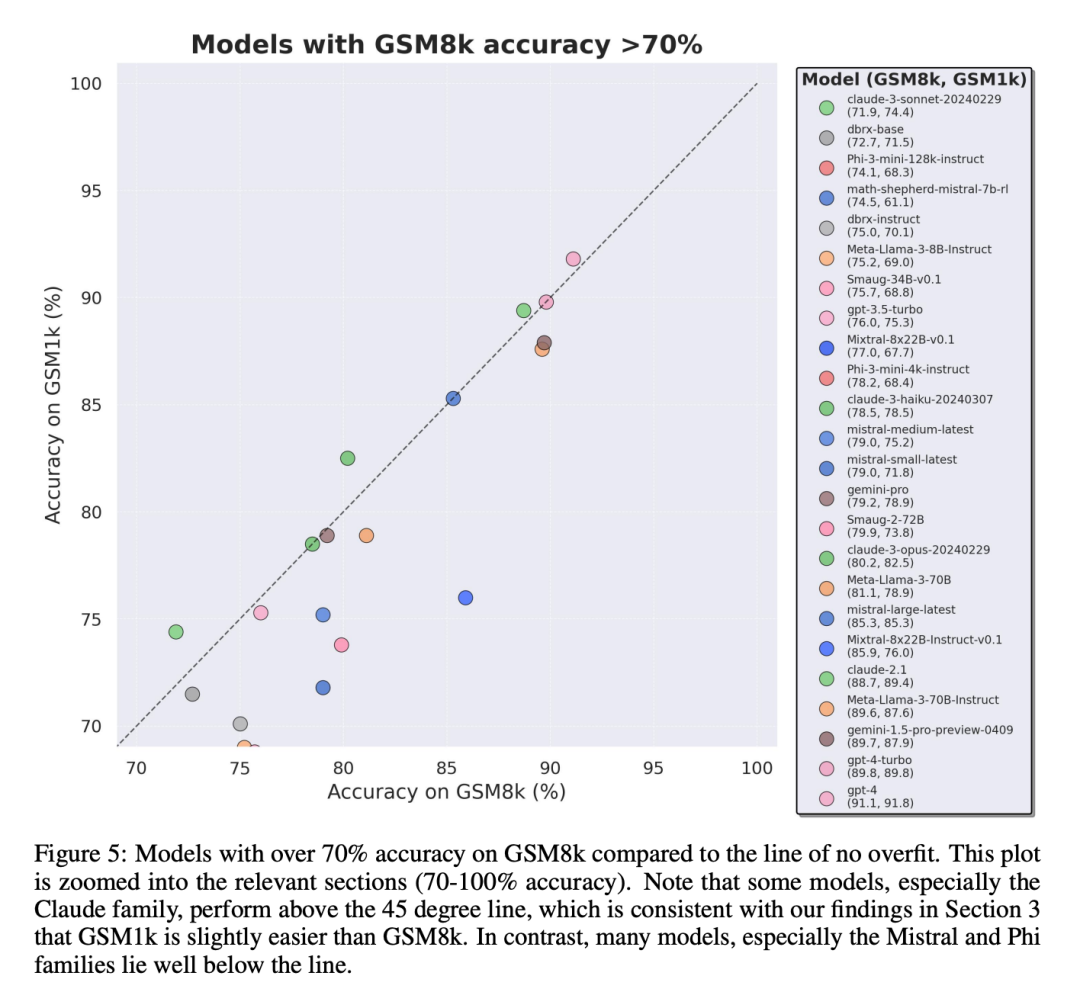
Um einen fairen Vergleich zu ermöglichen, haben die Forscher die Modelle nach ihrer Leistung auf GSM8k unterteilt und sie mit anderen Modellen mit ähnlicher Leistung verglichen (Abbildung 5, Abbildung 6, Abbildung 7).
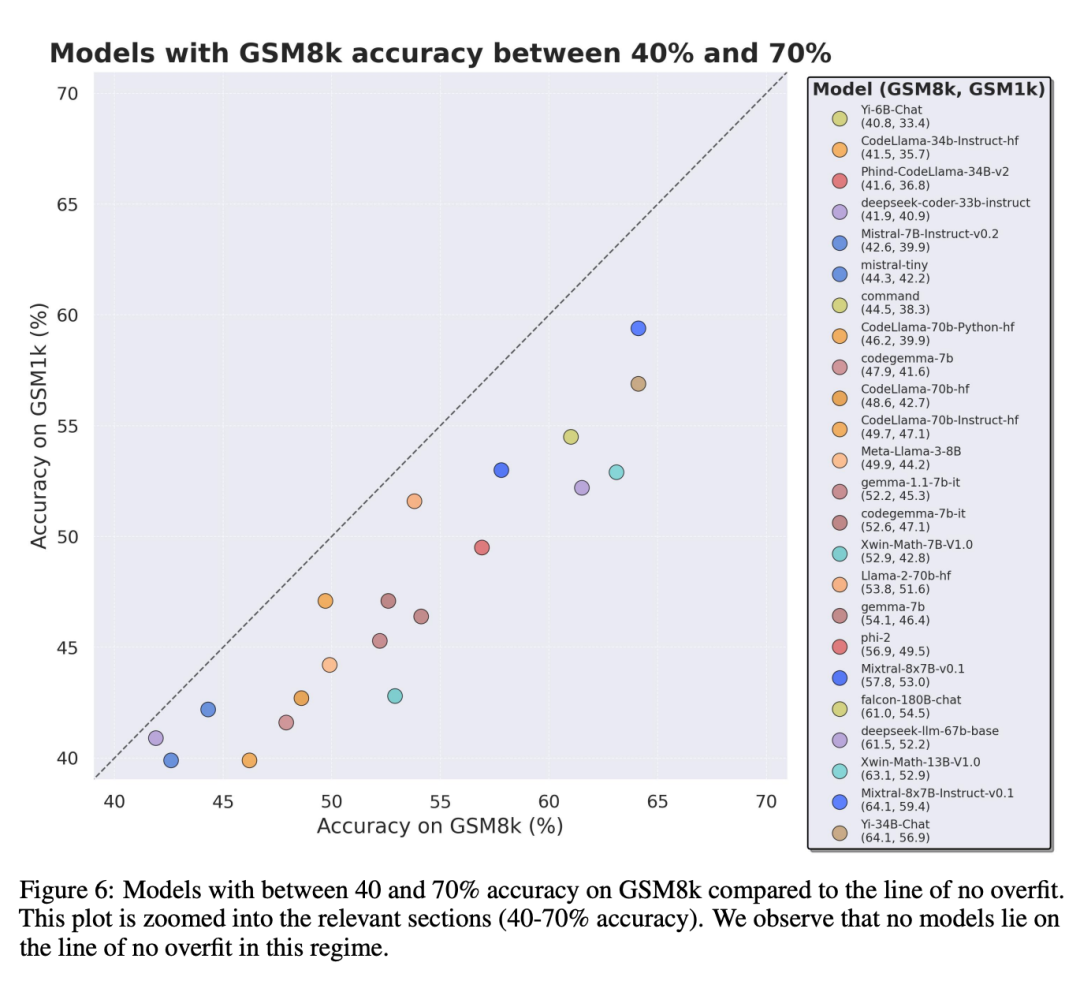
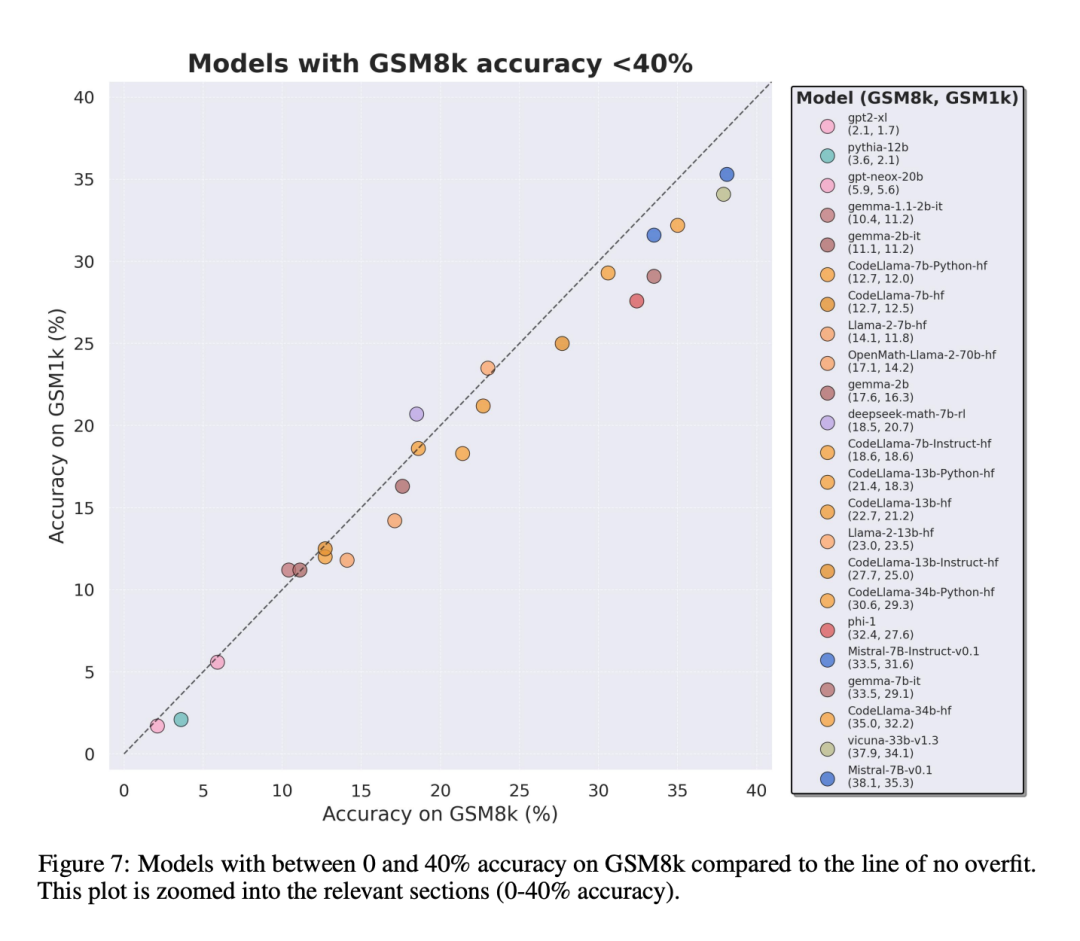
Welche Schlussfolgerungen wurden gezogen?
Obwohl die Forscher objektive Bewertungsergebnisse mehrerer Modelle lieferten, gaben sie auch an, dass die Interpretation der Bewertungsergebnisse, wie die Interpretation von Träumen, oft eine sehr subjektive Aufgabe sei. Im letzten Teil des Papiers gehen sie auf eine subjektivere Art und Weise auf vier Implikationen der obigen Bewertung ein:
Schlussfolgerung 1: Einige Modellfamilien sind systematisch überfit
Obwohl es oft schwierig ist, dies anhand eines einzelnen Datenpunkts zu bestimmen oder Modellversionsschlussfolgerung, aber die Untersuchung der Modellfamilie und die Beobachtung von Überanpassungsmustern ermöglichen es, eine definitivere Aussage zu treffen. Einige Modellfamilien, darunter Phi und Mistral, zeigen in fast allen Modellversionen und -größen einen Trend zu einer stärkeren Systemleistung auf GSM8k als auf GSM1k. Es gibt andere Modellfamilien wie Yi, Xwin, Gemma und CodeLlama, die dieses Muster ebenfalls in geringerem Maße aufweisen.
Schlussfolgerung 2: Andere Modelle, insbesondere Modelle der Spitzenklasse, zeigen keine Anzeichen einer Überanpassung.
Viele Modelle weisen in allen Leistungsbereichen leichte Anzeichen einer Überanpassung auf, insbesondere einschließlich des proprietären Mistral Large. Edge-Modelle innerhalb von , scheinen auf GSM8k und GSM1k eine ähnliche Leistung zu erbringen. In diesem Zusammenhang stellen die Forscher zwei mögliche Hypothesen auf: 1) Frontier-Modelle verfügen über ausreichend fortgeschrittene Argumentationsfähigkeiten, sodass sie, selbst wenn das GSM8k-Problem bereits in ihrem Trainingssatz aufgetaucht ist, auf neue Probleme verallgemeinert werden können Seien Sie vorsichtiger hinsichtlich der Datenkontamination.
Während es unmöglich ist, sich den Trainingssatz jedes Modells anzusehen und diese Annahmen zu bestimmen, ist ein Beweis für ersteres, dass Mistral Large das einzige Modell in der Mistral-Serie ist, das keine Anzeichen einer Überanpassung aufweist. Die Annahme, dass Mistral nur sicherstellt, dass sein größtes Modell frei von Datenverunreinigungen ist, erscheint unwahrscheinlich, daher bevorzugen Forscher, dass ein ausreichend leistungsfähiges LLM während des Trainings auch grundlegende Inferenzfähigkeiten erlernt. Wenn ein Modell lernt, gut genug zu argumentieren, um ein Problem mit einem bestimmten Schwierigkeitsgrad zu lösen, kann es auf neue Probleme verallgemeinern, selbst wenn GSM8k in seinem Trainingssatz vorhanden ist.
Schlussfolgerung 3: Das Überanpassungsmodell hat immer noch die Fähigkeit zu argumentieren
Eine der Sorgen vieler Forscher bezüglich der Modellüberanpassung besteht darin, dass das Modell keine Argumentation durchführen kann und sich nur die Antworten in den Trainingsdaten merkt, in diesem Artikel jedoch die Ergebnisse stützte diese Hypothese nicht. Die Tatsache, dass ein Modell übergeeignet ist, bedeutet nicht, dass seine Inferenzfähigkeiten schlecht sind, sondern lediglich, dass es nicht so gut ist, wie der Benchmark anzeigt. Tatsächlich haben Forscher herausgefunden, dass viele überangepasste Modelle immer noch in der Lage sind, neue Probleme zu begründen und zu lösen. Beispielsweise sank die Genauigkeit von Phi-3 zwischen GSM8k und GSM1k um fast 10 %, aber es löste immer noch mehr als 68 % der GSM1k-Probleme korrekt – Probleme, die in seiner Trainingsverteilung sicherlich nicht auftauchten. Diese Leistung ähnelt größeren Modellen wie dbrx-instruct, die fast 35-mal mehr Parameter enthalten. Auch unter Berücksichtigung der Überanpassung ist das Mistral-Modell immer noch eines der stärksten Open-Source-Modelle. Dies liefert weitere Belege für die Schlussfolgerung dieses Artikels, dass ein ausreichend leistungsstarkes Modell grundlegende Schlussfolgerungen lernen kann, selbst wenn die Benchmark-Daten versehentlich in die Trainingsverteilung gelangen, was bei den meisten Overfit-Modellen wahrscheinlich der Fall ist.
Schlussfolgerung 4: Datenkontamination ist möglicherweise keine vollständige Erklärung für Überanpassung.
Eine a priori natürliche Hypothese ist, dass die Hauptursache für Überanpassung Datenkontamination ist, beispielsweise im Vortraining oder in Anweisungen zur Erstellung des Modells Für den Feinabstimmungsteil wurde das Testset durchgesickert. Frühere Untersuchungen haben gezeigt, dass Modelle den Daten, die sie während des Trainings gesehen haben, höhere Log-Likelihoods zuordnen (Carlini et al. [2023]). Die Forscher testeten die Hypothese, dass Datenkontamination die Ursache für Überanpassung ist, indem sie die Wahrscheinlichkeit maßen, mit der das Modell Stichproben aus dem GSM8k-Testsatz generierte, und den Grad der Überanpassung mit GSM8k und GSM1k verglichen.
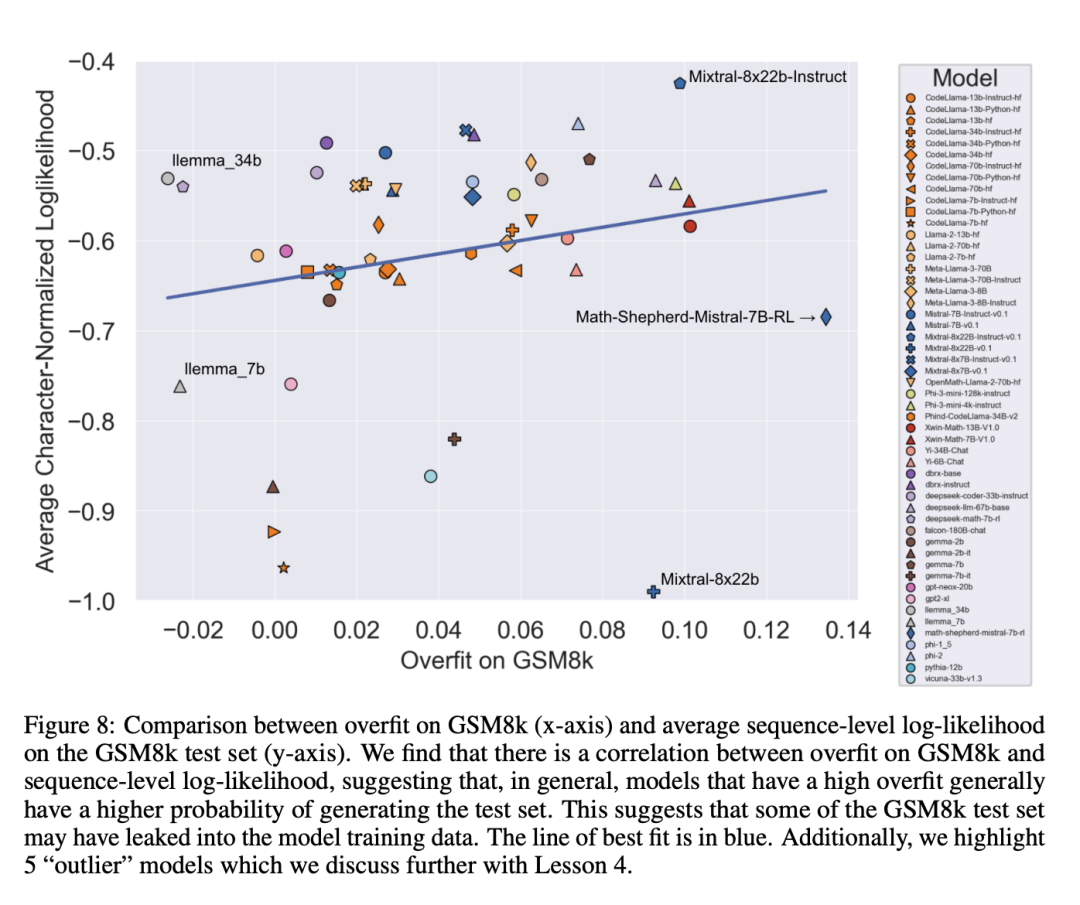
Forscher sagen, dass Datenverschmutzung möglicherweise nicht der einzige Grund ist. Sie beobachteten dies bei mehreren Ausreißern. Ein genauerer Blick auf diese Ausreißer zeigt, dass das Modell mit der niedrigsten Log-Likelihood pro Zeichen (Mixtral-8x22b) und das Modell mit der höchsten Log-Likelihood pro Zeichen (Mixtral-8x22b-Instruct) nicht nur Varianten desselben Modells sind. und weist einen ähnlichen Grad an Überanpassung auf. Interessanter ist, dass das am stärksten angepasste Modell (Math-Shepherd-Mistral-7B-RL (Yu et al. [2023])) eine relativ geringe Log-Likelihood pro Zeichen aufweist (Math Shepherd nutzt synthetische Daten und trainiert Belohnungsmodelle auf Daten auf Prozessebene ).
Daher stellten die Forscher die Hypothese auf, dass der Belohnungsmodellierungsprozess möglicherweise Informationen über die korrekten Inferenzketten für GSM8k durchsickern ließ, obwohl die Probleme selbst nie im Datensatz auftauchten. Schließlich stellten sie fest, dass das Llema-Modell eine hohe Log-Likelihood und eine minimale Überanpassung aufwies. Da diese Modelle Open Source sind und ihre Trainingsdaten bekannt sind, treten im Trainingskorpus mehrere Fälle des GSM8k-Problems auf, wie im Llema-Artikel beschrieben. Die Autoren stellten jedoch fest, dass diese wenigen Fälle nicht zu einer schwerwiegenden Überanpassung führten. Das Vorhandensein dieser Ausreißer deutet darauf hin, dass eine Überanpassung bei GSM8k nicht ausschließlich auf Datenverunreinigungen zurückzuführen ist, sondern auch durch andere indirekte Ursachen verursacht werden kann, beispielsweise dadurch, dass der Modellersteller Daten mit ähnlichen Eigenschaften wie die Basislinie als Trainingsdaten sammelt oder auf der Leistung basiert Benchmark wählt den endgültigen Modellprüfpunkt aus, auch wenn das Modell selbst den GSM8k-Datensatz möglicherweise zu keinem Zeitpunkt während des Trainings gesehen hat. Das Gegenteil ist auch der Fall: Eine geringe Datenverunreinigung führt nicht zwangsläufig zu einer Überanpassung.
Weitere Forschungsdetails finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonSchließlich untersuchte jemand die Überanpassung kleiner Modelle: Zwei Drittel von ihnen wiesen Datenverschmutzung auf, und Microsoft Phi-3 und Mixtral 8x22B wurden benannt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Ronglian Cloud wurde in die Global Generative AI Industry Map 2023 aufgenommen
- Technologische Innovationen beschleunigen die Umsetzung der Gehirn-Computer-Schnittstellenindustrie meines Landes
- Branchenallianz für Gehirn-Computer-Schnittstellen veröffentlicht zehn Schlüsseltechnologien für Gehirn-Computer-Schnittstellen
- OpenAI arbeitet mit Scale AI zusammen, um die Feinabstimmungsfunktionen für Unternehmens-GPT-Modelle zu verbessern
- Lassen Sie uns gemeinsam das digitale Guangxi aufbauen und gemeinsam in eine digitale Zukunft gehen! Die ökologische Konferenz der Industrie für künstliche Intelligenz in Guangxi Kunpeng Shengteng 2023 wurde erfolgreich abgehalten