
Heim >Technologie-Peripheriegeräte >KI >Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen

- PHPznach vorne
- 2024-04-29 18:55:141550Durchsuche
Ich weine zu Tode, die Welt baut wahnsinnig große Modelle, die Daten im Internet reichen nicht aus, überhaupt nicht.
Das Trainingsmodell ist wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese großen Datenfresser ernähren können.
Besonders bei multimodalen Aufgaben tritt dieses Problem besonders hervor. Als
ratlos war, nutzte ein Start-up-Team der Abteilung der Renmin-Universität ein eigenes neues Modell, um als erstes in China den „modellgenerierten Datenfeed selbst“ Wirklichkeit werden zu lassen.
Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern.
Was ist das Modell?
Das multimodale Großmodell Awaker 1.0 ist gerade im Zhongguancun-Forum erschienen.
Wer ist das Team?
Sophon Engine. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University of China, mit Professor Lu Zhiwu von der Hillhouse School of Artificial Intelligence als Berater. Mit der Gründung im Jahr 2021 betrat das Unternehmen schon früh das „Niemandsland“ der Multimodalität.
MOE-Architektur löst das Konfliktproblem des multimodalen und Multitasking-Trainings
Dies ist nicht das erste Mal, dass Sophon Engine ein Modell veröffentlicht.
Am 8. März letzten Jahres veröffentlichte das Team, das zwei Jahre Forschung und Entwicklung investiert hat, das erste selbst entwickelte multimodale Modell, das ChatImg-Sequenzmodell mit Dutzenden Milliarden Parametern, und brachte auf dieser Grundlage das weltweit erste auf den Markt öffentliche Bewertung multimodaler Dialog ChatImg anwenden(元 multiplizieren xiang).
Später iterierte ChatImg weiter und parallel wurde auch die Forschung und Entwicklung des neuen Modells Awaker vorangetrieben. Letzterer erbt auch die Grundfähigkeiten des Vorgängermodells.
Im Vergleich zum ChatImg-Sequenzmodell der vorherigen Generation übernimmt Awaker 1.0 die MoE-Modellarchitektur.
Der Grund ist, dass wir das Problem schwerwiegender Konflikte im multimodalen und multitaskigen Training lösen wollen.
Mithilfe der MoE-Modellarchitektur können multimodale allgemeine Fähigkeiten und die für jede Aufgabe erforderlichen einzigartigen Fähigkeiten besser erlernt werden, wodurch die Fähigkeiten des gesamten Awaker 1.0 für mehrere Aufgaben weiter verbessert werden.
Daten sagen mehr als tausend Worte:
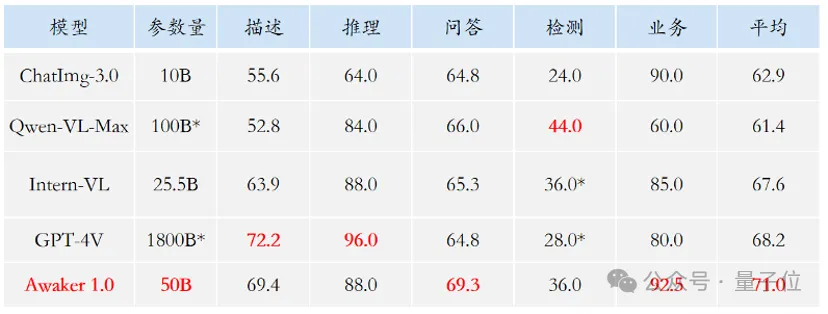
Angesichts des Problems des Verlusts von Bewertungsdaten in den gängigen multimodalen Bewertungslisten hat das Tomoko-Team streng seinen eigenen Bewertungssatz erstellt, und die meisten Testbilder stammten von Privatpersonen Handyalben.
Die Tabelle zeigt, dass das Team Awaker 1.0 und die drei fortschrittlichsten multimodalen Großmodelle im In- und Ausland bewertet hat.
Noch etwas zu erwähnen: Da GPT-4V und Intern-VL Erkennungsaufgaben nicht direkt unterstützen, werden ihre Erkennungsergebnisse dadurch erhalten, dass das Modell eine Sprache zur Beschreibung der Objektorientierung verwenden muss.
Es ist ersichtlich, dass das Basismodell von Awaker 1.0 bei der visuellen Beantwortung von Fragen und Geschäftsanwendungsaufgaben GPT-4V, Qwen-VL-Max und Intern-VL übertrifft.
Das Basismodell von Awaker 1.0 erzielte die zweitbesten Ergebnisse bei Beschreibungs-, Argumentations- und Erkennungsaufgaben.
Wenn man sich schließlich die durchschnittliche Punktzahl ansieht, hat Awaker 1.0 den höchsten Wert unter ihnen.
Daher bestätigen die obigen Ergebnisse auch die Wirksamkeit des multimodalen Multitask-Modells unter Verwendung der MoE-Architektur.
Die Ergebnisse der Datensatzauswertung liegen vor, der tatsächliche Effekt muss jedoch noch weiter erlebt werden.
Hier stellen wir hauptsächlich einige Fragen zur chinesischen OCR (Bildtexterkennung) und zu Zählproblemen, detaillierten Beschreibungsaufgaben usw. zwischen diesem und dem großen Vergleichsmodell.
Dies hauptsächlich Tests zählen:
Awaker 1.0 kann die richtige Antwort geben, während die anderen drei Modelle alle falsch antworten.
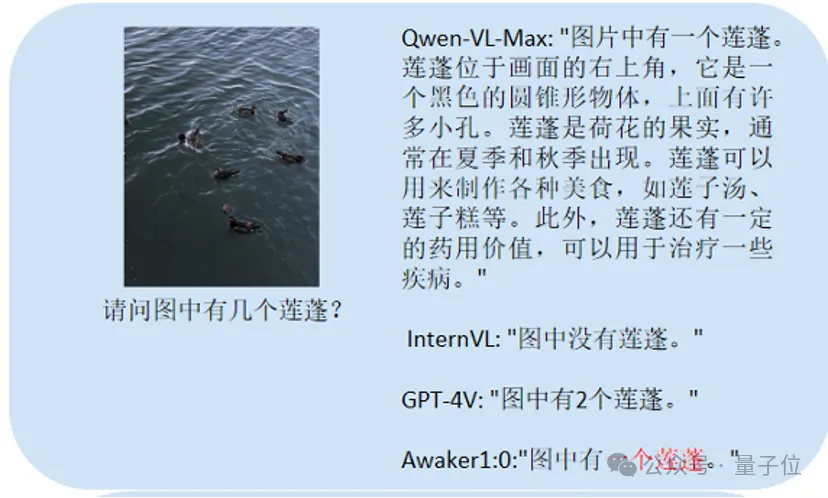
Dieser Haupttest ist Chinese OCR:
Die Spieler, die richtig geantwortet haben, sind Qwen-VL-Max und Awaker 1.0.

Die letzte Frage prüft, den Inhalt des Bildes zu verstehen.
GPT-4V und Awaker 1.0 können nicht nur den Inhalt des Bildes detailliert beschreiben, sondern auch die Details im Bild genau identifizieren, wie zum Beispiel die im Bild gezeigte Coca-Cola.

Ich muss erwähnen, dass Awaker 1.0 einige der Forschungsergebnisse übernimmt, die dem Sophon-Team zuvor viel Aufmerksamkeit geschenkt haben.
Ich spreche von Ihnen – der generierten Seite von Awaker 1.0.
Die Generierungsseite von Awaker 1.0 ist die Sora-ähnliche Videogenerierungsbasis VDT (Video Diffusion Transformer), die unabhängig von Sophon Engine entwickelt wurde.
VDTs wissenschaftliche Arbeit ging der Veröffentlichung von OpenAI Sora (im Mai letzten Jahres) voraus und wurde von der Top-Konferenz ICLR 2024 angenommen.

VDTs einzigartige Innovationen umfassen hauptsächlich zwei Punkte.
Erstens wurde der Diffusion Transformer in die technische Architektur übernommen. Vor OpenAI zeigte sich das enorme Potenzial von Transformer im Bereich der Videogenerierung. Sein Vorteil liegt in seinen hervorragenden zeitabhängigen Aufnahmefähigkeiten, die in der Lage sind, zeitlich kohärente Videobilder zu erzeugen, einschließlich der Simulation der physikalischen Dynamik dreidimensionaler Objekte im Zeitverlauf.
Die zweite besteht darin, einen einheitlichen räumlich-zeitlichen Maskenmodellierungsmechanismus vorzuschlagen, damit VDT eine Vielzahl von Videogenerierungsaufgaben bewältigen kann. VDTs flexible bedingte Informationsverarbeitungsmethoden, wie z. B. einfaches Token-Space-Splicing, vereinheitlichen effektiv Informationen unterschiedlicher Länge und Modalitäten.
Gleichzeitig ist VDT durch die Kombination mit dem in dieser Arbeit vorgeschlagenen räumlich-zeitlichen Maskenmodellierungsmechanismus zu einem universellen Videodiffusionstool geworden, das auf die bedingungslose Generierung, die Vorhersage nachfolgender Videobilder, das Einfügen von Bildern usw. angewendet werden kann, ohne das zu ändern Modellstruktur: Verschiedene Aufgaben zur Videogenerierung, z. B. zur Erstellung von Bildern und zur Vervollständigung des Videobildschirms.
Es versteht sich, dass das Sophon-Engine-Team nicht nur die VDT-Simulation einfacher physikalischer Gesetze erforscht hat, sondern auch herausgefunden hat, dass
physikalische Prozesse simulieren kann:
 wurde auch am
wurde auch am
Hyper- durchgeführt. Realistische Aufgabe zur Erstellung von Porträtvideos Erkunden Sie sie ausführlich. Da das bloße Auge sehr empfindlich auf dynamische Veränderungen in Gesichtern und Personen reagiert, stellt diese Aufgabe sehr hohe Anforderungen an die Qualität der Videoerzeugung. Die Sophon-Engine hat jedoch die meisten Schlüsseltechnologien für die Erzeugung hyperrealistischer Porträtvideos durchbrochen und ist nicht weniger beeindruckend als Sora.
Es gibt keine Grundlage für das, was Sie sagen.
Dies ist der Effekt der Sophon-Engine, die VDT und steuerbare Generierung kombiniert, um die Qualität der Porträtvideogenerierung zu verbessern:
Es wird berichtet, dass die Sophon-Engine den steuerbaren Generierungsalgorithmus von Charakteren weiter optimieren und aktiv die Kommerzialisierung erforschen wird.
Generierung eines stetigen Stroms neuer interaktiver Daten
Bemerkenswerter ist, dass das Sophon-Engine-Team betont hat:
Awaker 1.0 ist
das weltweit erste multimodale große Modell, das unabhängig aktualisiert werden kann. Mit anderen Worten, Awaker 1.0 ist „live“ und seine Parameter können kontinuierlich in Echtzeit aktualisiert werden – das unterscheidet Awaker 1.0 von allen anderen großen multimodalen Modellen
Der autonome Aktualisierungsmechanismus von Awaker 1.0 umfasst drei Der Schlüssel Technologien sind:
Aktive Datengenerierung- Modellreflexion und -bewertung
- Kontinuierliche Modellaktualisierung
- Diese drei Technologien geben Awaker 1.0 die Fähigkeit, autonom zu lernen, automatisch zu reflektieren und autonom zu aktualisieren und können in dieser Welt verwendet werden Fühlen Sie sich frei Menschen zu erkunden und sogar mit ihnen zu interagieren.
Auf dieser Grundlage kann Awaker 1.0 sowohl auf der Verständnisseite als auch auf der Generierungsseite einen stetigen Strom neuer interaktiver Daten generieren.
Wie geht das?
Auf der Verständnisseite interagiert Awaker 1.0 mit der digitalen und realen Welt. Während der Ausführung von Aufgaben gibt Awaker 1.0 Szenenverhaltensdaten zurück an das Modell, um eine kontinuierliche Aktualisierung und Schulung zu erreichen.
Auf der Generierungsseite kann Awaker 1.0 eine hochwertige multimodale Inhaltsgenerierung durchführen und so mehr Trainingsdaten für das Verständnisseitenmodell bereitstellen. In den beiden Schleifen der Verständnisseite und der Generierungsseite realisiert Awaker 1.0 tatsächlich die Integration von visuellem Verständnis und visueller Generierung.
Sie müssen wissen, dass nach der Ankunft von Sora immer mehr Stimmen erklärten, dass zur Erreichung von AGI eine „Einheit von Verständnis und Generation“ erreicht werden muss.
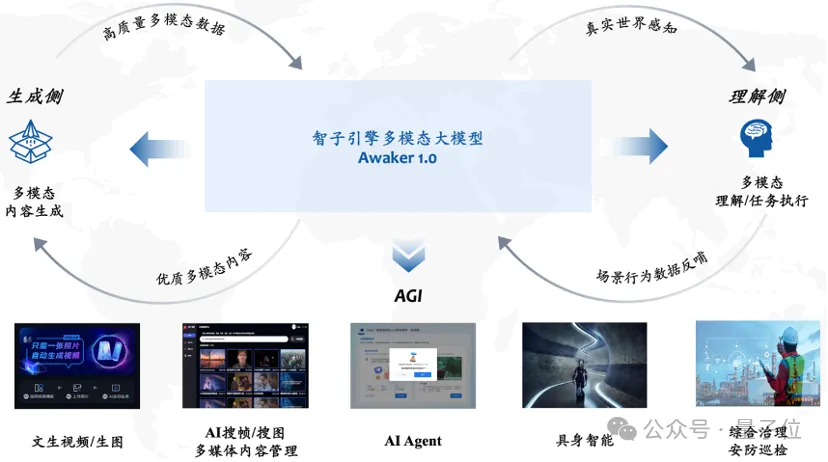 Nehmen wir als Beispiel die Einführung neuen Wissens und schauen wir uns ein konkretes Beispiel für den Durchlauf an.
Nehmen wir als Beispiel die Einführung neuen Wissens und schauen wir uns ein konkretes Beispiel für den Durchlauf an.
Awaker 1.0 kann kontinuierlich Echtzeit-Nachrichteninformationen aus dem Internet lernen und gleichzeitig neu gelernte Nachrichteninformationen kombinieren, um verschiedene komplexe Fragen zu beantworten.
Dies unterscheidet sich von den beiden aktuellen Mainstream-Methoden, nämlich RAG und traditionellen Long-Context-Methoden. Awaker 1.0 „merkt“ sich tatsächlich neues Wissen in den Parametern seines eigenen Modells
.
Sie können sehen, dass Awaker 1.0 während der drei aufeinanderfolgenden Tage der Selbstaktualisierung jeden Tag die Nachrichteninformationen des Tages lernen und die entsprechenden Informationen in der Beschreibung genau angeben kann. Und obwohl es gelernt hat, hat Awaker 1.0 das eine oder andere nicht aus den Augen verloren. Es wird das gelernte Wissen nicht so schnell vergessen.
Und obwohl es gelernt hat, hat Awaker 1.0 das eine oder andere nicht aus den Augen verloren. Es wird das gelernte Wissen nicht so schnell vergessen.
Zum Beispiel konnte sich Awaker 1.0 zwei Tage später noch an das am 16. April erlernte Wissen im Zusammenhang mit Zhijie S7 erinnern oder es verstehen.
In einer Zeit, in der Daten wie Gold sind, sollten Sie also aufhören, sich über „nicht genügend Daten“ zu beschweren.
Ist Awaker 1.0 für Teams, die mit Datenengpässen konfrontiert sind, nicht eine praktikable und nutzbare neue Option?
Das „lebende“ Gehirn der verkörperten Intelligenz
Mit anderen Worten: Gerade aufgrund der Integration von visuellem Verständnis und visueller Generierung ist der Stolz von Awaker 1.0 Es wurde deutlich enthüllt.
Die Sache ist folgende:
Awaker 1.0, ein großes multimodales Modell, verfügt über visuelle Verständnisfähigkeiten, die auf natürliche Weise mit den „Augen“ der verkörperten Intelligenz kombiniert werden können.
Und Mainstream-Stimmen glauben auch, dass „multimodale große Modelle + verkörperte Intelligenz“ die Anpassungsfähigkeit und Kreativität der verkörperten Intelligenz erheblich verbessern und möglicherweise sogar einen praktikablen Weg zur Verwirklichung von AGI darstellen können.
Die Gründe sind nichts weiter als zwei Punkte.
Erstens Menschen erwarten, dass verkörperte Intelligenz anpassungsfähig ist, das heißt, der Agent kann sich durch kontinuierliches Lernen an sich ändernde Anwendungsumgebungen anpassen.
Auf diese Weise kann die verkörperte Intelligenz nicht nur bekannte multimodale Aufgaben immer besser bewältigen, sondern sich auch schnell an unbekannte multimodale Aufgaben anpassen.
Zweitens Menschen erwarten auch, dass verkörperte Intelligenz wirklich kreativ ist, in der Hoffnung, dass sie durch autonome Erkundung der Umgebung neue Strategien und Lösungen entdecken und die Grenzen der KI-Fähigkeiten erkunden kann.
Aber die Anpassung der beiden ist nicht so einfach wie die einfache Verknüpfung eines großen multimodalen Modells mit dem Körper oder die direkte Installation eines Gehirns in der verkörperten Intelligenz.
Am Beispiel multimodaler Großmodelle stehen uns mindestens zwei offensichtliche Probleme gegenüber.
Erstens ist der iterative Aktualisierungszyklus des Modells lang, was einen hohen Personalaufwand erfordert
Zweitens werden die Trainingsdaten des Modells alle aus vorhandenen Daten abgeleitet und das Modell kann nicht kontinuierlich sein Erwerben Sie viel neues Wissen. Obwohl es auch möglich ist, durch RAG und die Erweiterung des Kontextfensters kontinuierlich neu entstehendes Wissen einzubringen, kann sich das Modell nicht daran erinnern, und die Korrekturmethode bringt zusätzliche Probleme mit sich.
Kurz gesagt, die aktuellen großen multimodalen Modelle verfügen nicht über eine starke Anpassungsfähigkeit an tatsächliche Anwendungsszenarien, geschweige denn über Kreativität, was bei der Implementierung in der Branche zu verschiedenen Schwierigkeiten führt.
Wunderbar – denken Sie daran, was wir zuvor erwähnt haben: Awaker 1.0 kann nicht nur neues Wissen erlernen, sondern sich auch an neues Wissen erinnern, und diese Art des Lernens erfolgt täglich, kontinuierlich und zeitnah.
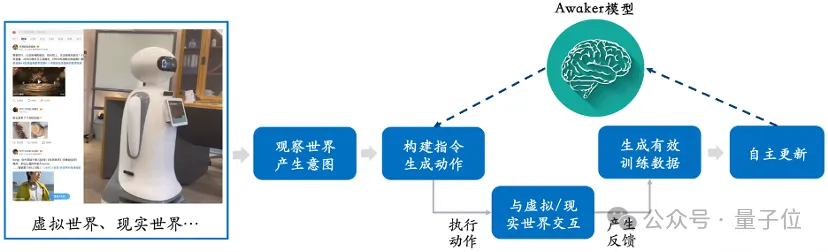
Wie aus diesem Rahmendiagramm ersichtlich ist, kann Awaker 1.0 mit verschiedenen intelligenten Geräten kombiniert werden, die Welt durch intelligente Geräte beobachten, Handlungsabsichten generieren und automatisch Anweisungen erstellen, um intelligente Geräte zu steuern, um verschiedene Aktionen auszuführen.
Nach Abschluss verschiedener Aktionen generiert das Smart-Gerät automatisch verschiedene Rückmeldungen. Awaker 1.0 kann aus diesen Aktionen und Rückmeldungen effektive Trainingsdaten erhalten, um sich kontinuierlich zu aktualisieren und die verschiedenen Fähigkeiten des Modells kontinuierlich zu stärken.
Das ist gleichbedeutend damit, dass verkörperte Intelligenz ein lebendes Gehirn hat.
Wer hat nicht gesagt, wie man zahlt? (Hundekopf) breiteres Anwendungsspektrum in Industrieszenarien und kann komplexere praktische Aufgaben lösen.
Zum Beispiel ist Awaker 1.0 in verschiedene Smart-Geräte integriert, um eine Cloud-Edge-Zusammenarbeit zu erreichen. Derzeit ist Awaker 1.0 das „Gehirn“, das in der Cloud eingesetzt wird und verschiedene Edge-Smart-Geräte beobachtet, steuert und steuert, um verschiedene Aufgaben auszuführen. Das erhaltene Feedback, wenn das Edge-Smart-Gerät verschiedene Aufgaben ausführt, wird kontinuierlich an Awaker 1.0 zurückgesendet, sodass es kontinuierlich Trainingsdaten abrufen und sich kontinuierlich aktualisieren kann.
Dies ist nicht nur ein Gerede auf dem Papier. Der technische Weg von Awaker 1.0 und der Cloud-Edge-Zusammenarbeit mit intelligenten Geräten wurde in Anwendungsszenarien wie Smart-Grid-Inspektionen und Smart Cities angewendet und hat weitaus bessere Erkennungsergebnisse erzielt traditioneller kleiner Modelle.
Das multimodale große Modell kann hören, sehen und sprechen. Es hat in vielen Bereichen wie Spracherkennung, Bildverarbeitung und natürlichem Sprachverständnis großes Potenzial und Anwendungswert gezeigt. Aber die Probleme liegen auf der Hand: Wie kann man kontinuierlich neues Wissen aufnehmen und sich an neue Veränderungen anpassen? Man kann sagen, dass die Kultivierung der inneren Stärke und die Verbesserung der Kampfkünste zu einem wichtigen Thema geworden sind, mit dem multimodale große Modelle konfrontiert sind.
Man kann sagen, dass die Kultivierung der inneren Stärke und die Verbesserung der Kampfkünste zu einem wichtigen Thema geworden sind, mit dem multimodale große Modelle konfrontiert sind.
Die Einführung der Sophon-Engine Awaker 1.0 bietet einen Schlüssel zur Selbsttranszendenz multimodaler großer Modelle.
Es scheint die Star-Attracting-Methode zu beherrschen, es überwindet den Engpass der Datenknappheit und bietet die Möglichkeit für kontinuierliches Lernen und Selbstentwicklung von multimodalen großen Modellen; Edge-Collaboration-Technologie, um sich mutig in die Welt spezifischer Anwendungsszenarien intelligenter Geräte wie der verkörperten Intelligenz zu wagen.
Dies mag ein kleiner Schritt in Richtung AGI sein, aber es ist auch der Beginn einer Reise der Selbsttranszendenz für multimodale große Modelle.
Der lange und schwierige Weg erfordert, dass ein Team wie Sophon Engine kontinuierlich an die Spitze der Technologie klettert.
Das obige ist der detaillierte Inhalt vonDie Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Detaillierter Code für Schulungsfragen zur Grundanweisung der MySQL-Datenbank
- php „7-Tage-Devil-Trainingslager' – kostenlose Live-Kursanmeldung! ! ! ! ! !
- So löschen Sie eine Tabelle in der Datenbank in MySQL
- So löschen Sie doppelte Daten in Excel, sodass nur noch eine übrig bleibt
- Volcano Engine unterstützt Shenzhen Technology bei der Veröffentlichung des branchenweit ersten molekularen 3D-Vortrainingsmodells Uni-Mol