
Heim >Technologie-Peripheriegeräte >KI >Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |

- PHPznach vorne
- 2024-04-29 16:55:121580Durchsuche
FP8 und die geringere Gleitkomma-Quantifizierungsgenauigkeit sind nicht mehr das „Patent“ von H100!
Lao Huang wollte, dass jeder INT8/INT4 nutzt erzwungenermaßen mit der Ausführung von FP6 auf A100 ohne offizielle Unterstützung von NVIDIA.
Die Testergebnisse zeigen, dass die FP6-Quantisierung der neuen Methode TC-FPx auf A100 eine Geschwindigkeit aufweist, die nahe an INT4 liegt oder diese sogar gelegentlich übertrifft, und eine höhere Genauigkeit als letzteres aufweist .
Auf dieser Basis gibt es auch End-to-End-Unterstützung für große Modelle, die als Open Source bereitgestellt und in Deep-Learning-Inferenz-Frameworks wie DeepSpeed integriert wurde.
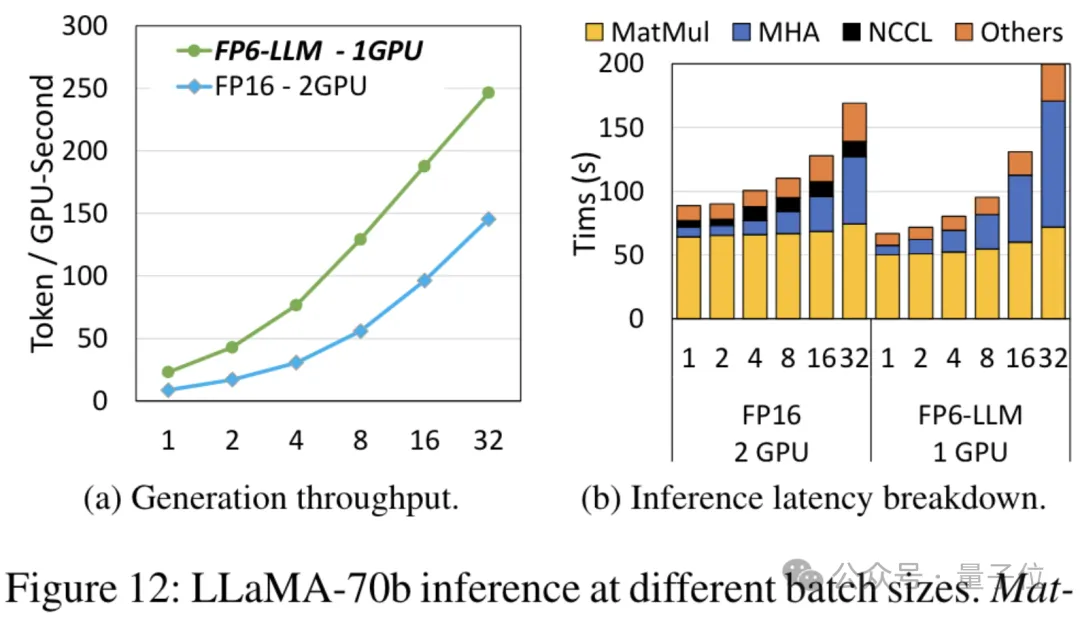
Dieses Ergebnis wirkt sich auch unmittelbar auf die Beschleunigung großer Modelle aus – unter diesem Rahmen ist der Durchsatz bei Verwendung einer einzelnen Karte zum Ausführen von Llama 2,65-mal höher als der von Doppelkarten.
Nachdem er es gelesen hatte, sagte ein Forscher für maschinelles Lernen, dass die Forschung von Microsoft als verrückt bezeichnet werden könne.
Emoticon-Pakete sind ebenfalls ab sofort online, seien Sie so:
NVIDIA: Nur H100 unterstützt FP8.
Microsoft: Gut, ich mache es selbst.

Welche Effekte kann dieses Framework also erzielen und welche Technologie steckt dahinter?
Bei Verwendung von FP6 zum Ausführen von Llama ist eine einzelne Karte schneller als zwei Karten.
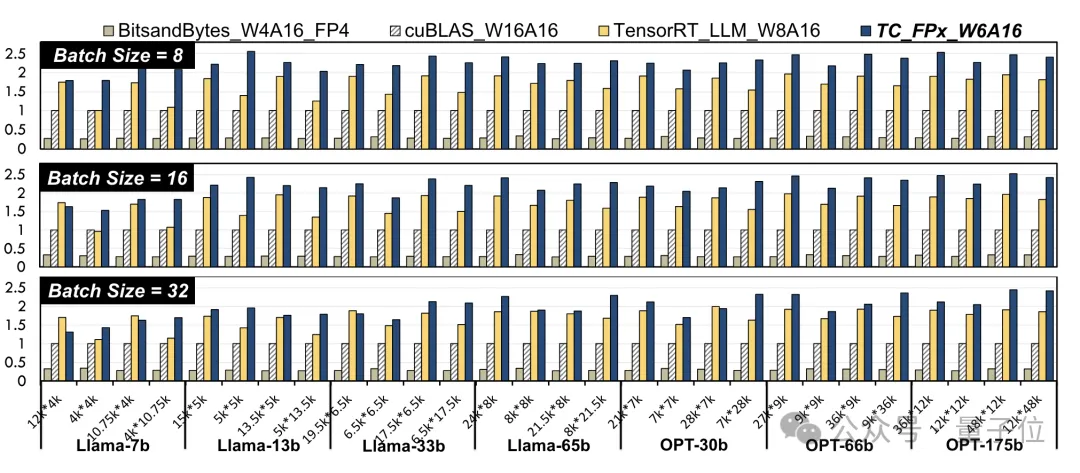
Die Verwendung von FP6-Genauigkeit auf A100 führt zu einer Leistungsverbesserung auf Kernel-Ebene. Die Forscher wählten lineare Schichten in Llama-Modellen und OPT-Modellen unterschiedlicher Größe aus und testeten sie mit CUDA 11.8 auf der NVIDIA A100-40GB GPU-Plattform. Die Ergebnisse sind im Vergleich zu NVIDIAs offizieller Geschwindigkeit cuBLAS
(W16A16)und TensorRT-LLM
(W8A16), TC-FPx(W6A16)Die maximale Geschwindigkeitsverbesserung beträgt das 2,6-fache bzw. das 1,9-fache. Im Vergleich zur 4-Bit-BitsandBytes-Methode (W4A16) beträgt die maximale Geschwindigkeitsverbesserung von TC-FPx das 8,9-fache. (W und A stellen die Bitbreite der Gewichtsquantisierung bzw. die Bitbreite der Aktivierungsquantisierung dar)
△Normalisierte Daten, wobei das cuBLAS-Ergebnis 1 istGleichzeitig wird auch der TC-FPx-Kern reduziert die Notwendigkeit eines DRAM-Speicherzugriffs und verbessert die DRAM-Bandbreitennutzung und Tensor-Core-Auslastung sowie die Auslastung von ALU- und FMA-Einheiten.
Das auf Basis von TC-FPx entwickelte
End-to-End-Inferenz-Framework FP6-LLM
bringt auch bei großen Modellen erhebliche Leistungsverbesserungen. 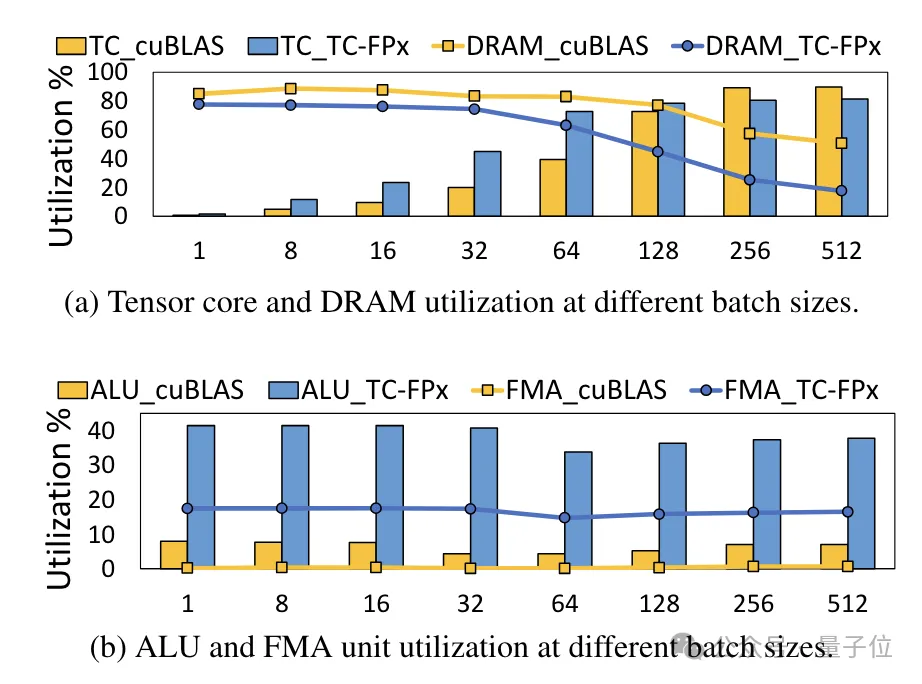
Für das Modell OPT-30B mit einer geringeren Anzahl von Parametern (FP16 verwendet auch eine einzelne Karte) bringt FP6-LLM auch eine deutliche Durchsatzverbesserung und Latenzreduzierung.
Und die maximale Stapelgröße, die von einer einzelnen Karte FP16 unter dieser Bedingung unterstützt wird, beträgt nur 4, aber FP6-LLM kann normal mit einer Stapelgröße von 16 arbeiten.
Wie hat das Microsoft-Team also die FP16-Quantisierung auf dem A100 erreicht?
Neu gestaltete Kernel-Lösung
Um Präzision einschließlich 6 Bit zu unterstützen, hat das TC-FPx-Team eine einheitliche Kernel-Lösung entwickelt, die Quantisierungsgewichte unterschiedlicher Bitbreiten unterstützen kann. 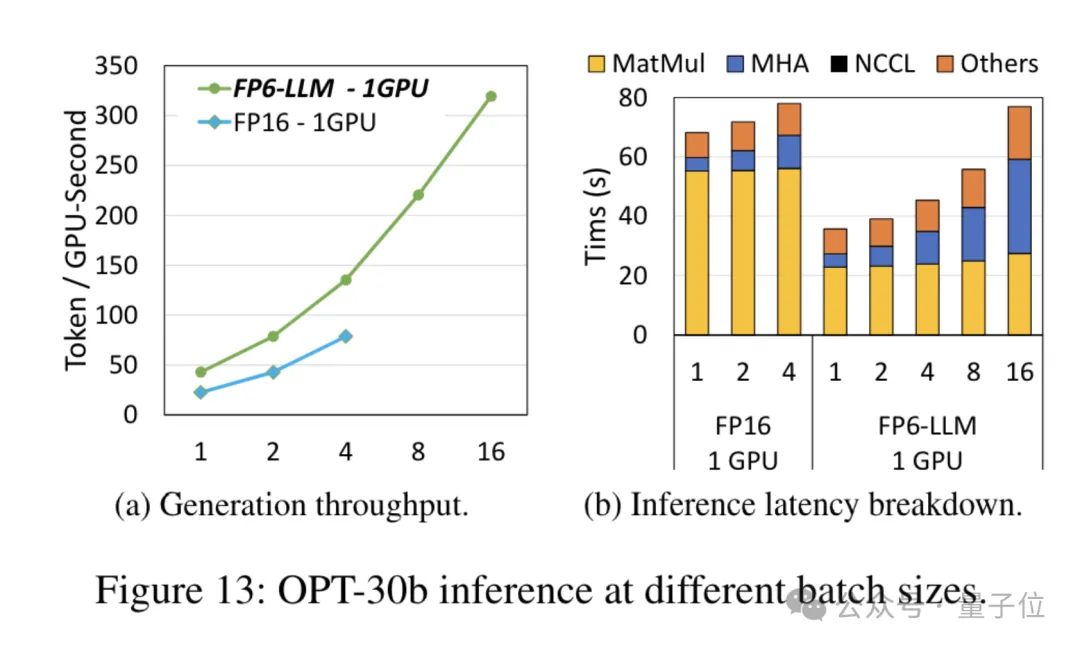
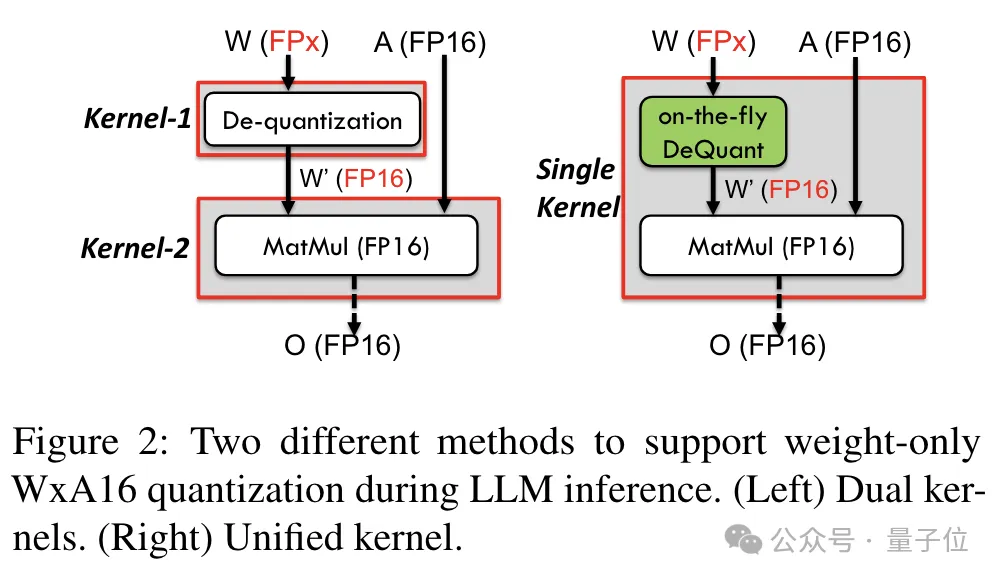
Gleichzeitig nutzte das Team auch die Bit-Level-Pre-Packaging-Technologie, um das Problem zu lösen, dass das GPU-Speichersystem nicht für Bitbreiten ohne Zweierpotenz geeignet ist (z. B. 6). -bisschen).
Konkret handelt es sich beim Vorpacken auf Bitebene um die Neuorganisation von Gewichtsdaten vor der Modellinferenz, einschließlich der Neuanordnung quantisierter 6-Bit-Gewichte, sodass auf sie auf eine GPU-speichersystemfreundliche Weise zugegriffen werden kann.
Da GPU-Speichersysteme außerdem normalerweise auf Daten in 32-Bit- oder 64-Bit-Blöcken zugreifen, packt die Pre-Packing-Technologie auf Bitebene auch 6-Bit-Gewichte, sodass sie in dieser ausgerichteten Form gespeichert und abgerufen werden können Blöcke.

Nach Abschluss der Vorverpackung nutzt das Forschungsteam die Parallelverarbeitungsfähigkeiten des SIMT-Kerns, um eine parallele Dequantisierung der FP6-Gewichte im Register durchzuführen und Gewichte im FP16-Format zu generieren.
Die dequantisierten FP16-Gewichte werden im Register rekonstruiert und dann an den Tensorkern gesendet. Die rekonstruierten FP16-Gewichte werden zur Durchführung von Matrixmultiplikationsoperationen verwendet, um die Berechnung der linearen Schicht abzuschließen.
In diesem Prozess nutzte das Team die Bit-Level-Parallelität des SMIT-Kerns, um die Effizienz des gesamten Dequantisierungsprozesses zu verbessern.
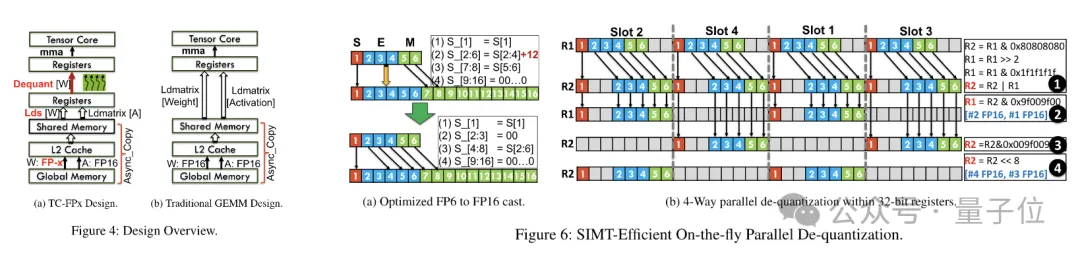
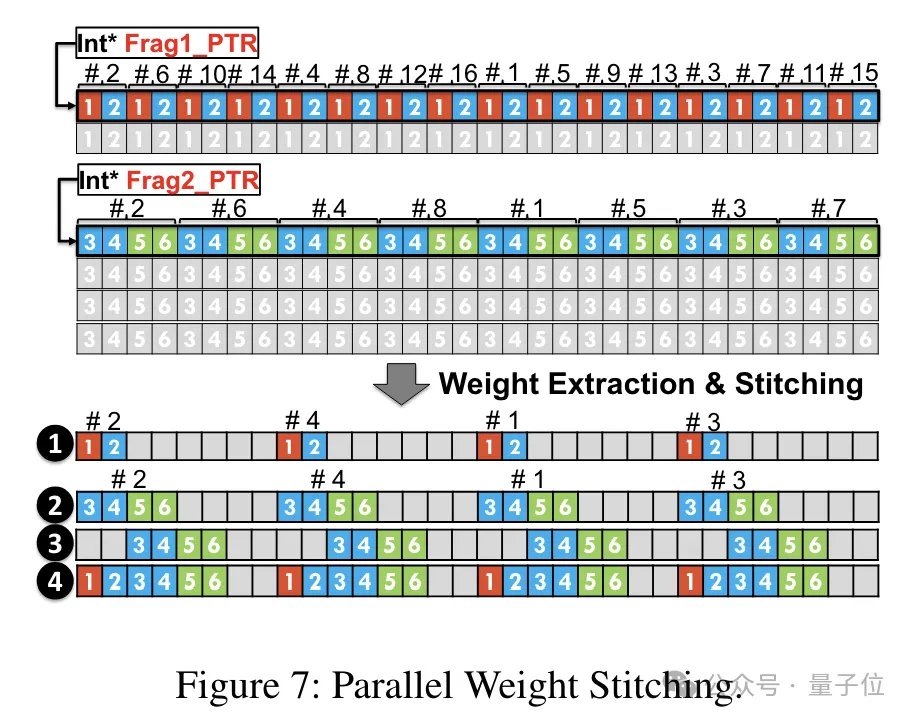
Um den parallelen Ablauf der Gewichtsrekonstruktionsaufgabe zu ermöglichen, verwendete das Team außerdem eine parallele Gewichtsspleißtechnologie.
Konkret ist jedes Gewicht in mehrere Teile unterteilt, und die Bitbreite jedes Teils ist eine Potenz von 2 (z. B. Division von 6 in 2+4 oder 4+2).
Vor der Dequantisierung werden die Gewichte zunächst aus dem gemeinsamen Speicher in Register geladen. Da jedes Gewicht in mehrere Teile aufgeteilt ist, muss das vollständige Gewicht zur Laufzeit auf Registerebene rekonstruiert werden.
Um den Laufzeitaufwand zu reduzieren, schlägt TC-FPx eine Methode zum parallelen Extrahieren und Spleißen von Gewichten vor. Dieser Ansatz verwendet zwei Registersätze, um Segmente von 32 FP6-Gewichten zu speichern und diese Gewichte parallel zu rekonstruieren.
Gleichzeitig muss zum parallelen Extrahieren und Zusammenfügen von Gewichten sichergestellt werden, dass das anfängliche Datenlayout bestimmte Reihenfolgeanforderungen erfüllt, sodass TC-FPx die Gewichtsfragmente vor der Ausführung neu anordnet.
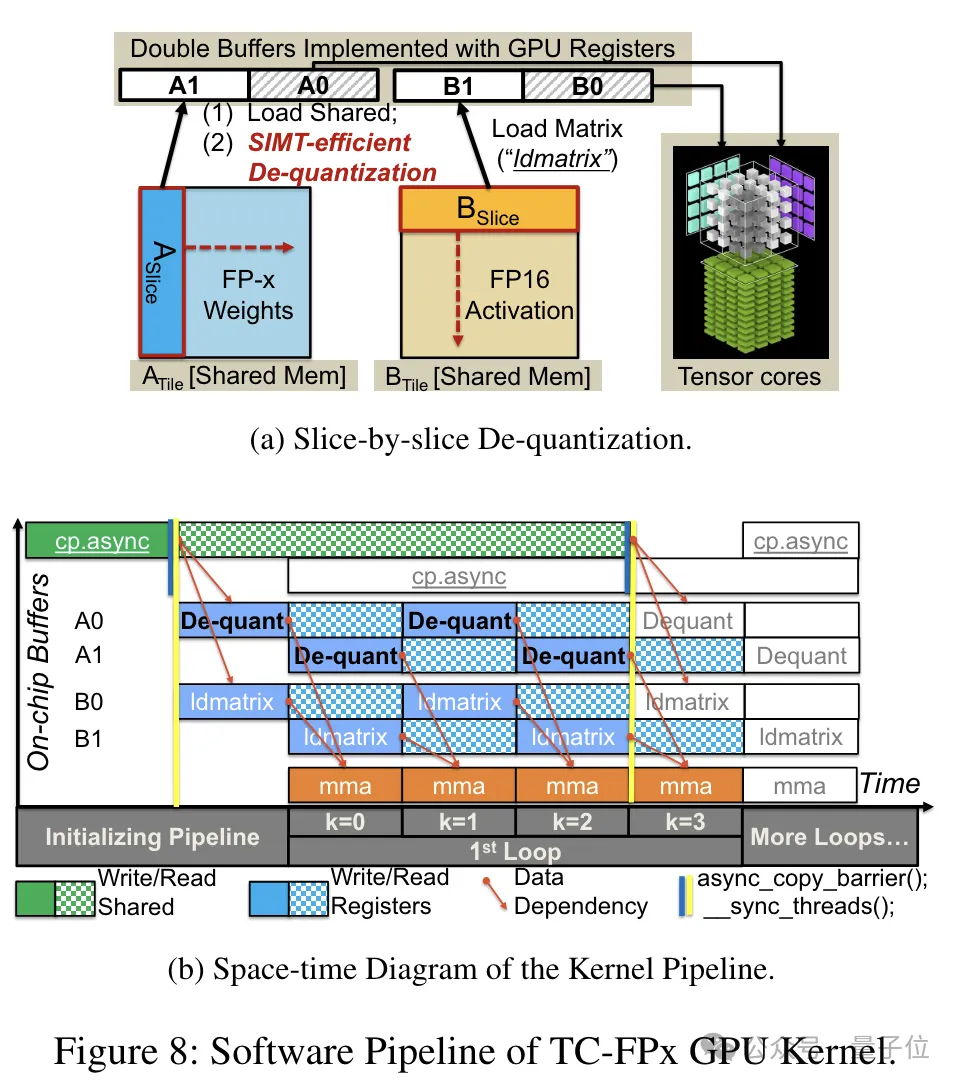
Darüber hinaus hat TC-FPx auch eine Software-Pipeline entwickelt, die den Dequantisierungsschritt mit der Matrixmultiplikationsoperation von Tensor Core integriert und so die Gesamtausführungseffizienz durch Parallelität auf Befehlsebene verbessert.
Papieradresse: https://arxiv.org/abs/2401.14112
Das obige ist der detaillierte Inhalt vonMit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Das li im
- -Tag in HTML ist horizontal angeordnet
- Welche sind die am häufigsten verwendeten relationalen Datenbanken?
- So sortieren Sie Wörter in absteigender Reihenfolge
- Welche Datenmodelle werden am häufigsten verwendet?
- Bekanntes Open-Source-CMS: Dreamweaver CMS wird sich von der kostenlosen Version verabschieden und die Open-Source-Ära geht allmählich zu Ende!