
Heim >Technologie-Peripheriegeräte >KI >Yuanxiangs erstes multimodales Großmodell XVERSE-V ist Open Source, aktualisiert die Liste der maßgeblichen Großmodelle und unterstützt die Eingabe aller Seitenverhältnisse
Yuanxiangs erstes multimodales Großmodell XVERSE-V ist Open Source, aktualisiert die Liste der maßgeblichen Großmodelle und unterstützt die Eingabe aller Seitenverhältnisse

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-04-28 16:43:08815Durchsuche
83 % der Informationen, die Menschen erhalten, stammen aus dem Sehen. Große multimodale Grafik- und Textmodelle können umfassendere und genauere Informationen aus der realen Welt wahrnehmen, eine umfassendere kognitive Intelligenz aufbauen und so größere Schritte in Richtung AGI (künstliche allgemeine Intelligenz) unternehmen. .
Yuanxiang hat heute das multimodale Großmodell XVERSE-V veröffentlicht, das die Bildeingabe mit jedem Seitenverhältnis unterstützt und bei Mainstream-Bewertungen führend ist. Dieses Modell ist vollständig Open Source und für die kommerzielle Nutzung bedingungslos kostenlos und fördert weiterhin die Forschung und Entwicklung sowie Anwendungsinnovationen einer großen Anzahl kleiner und mittlerer Unternehmen, Forscher und Entwickler.  XVERSE-V verfügt über eine hervorragende Leistung und übertrifft Open-Source-Modelle wie Yi-VL-34B, den wandorientierten intelligenten OmniLMM-12B und DeepSeek-VL-7B in einer Reihe maßgeblicher multimodaler Bewertungen und in der umfassenden Fähigkeitsbewertung MMBench Es übertrifft bekannte Closed-Source-Modelle wie Google GeminiProVision, Alibaba Qwen-VL-Plus und Claude-3V Sonnet.
XVERSE-V verfügt über eine hervorragende Leistung und übertrifft Open-Source-Modelle wie Yi-VL-34B, den wandorientierten intelligenten OmniLMM-12B und DeepSeek-VL-7B in einer Reihe maßgeblicher multimodaler Bewertungen und in der umfassenden Fähigkeitsbewertung MMBench Es übertrifft bekannte Closed-Source-Modelle wie Google GeminiProVision, Alibaba Qwen-VL-Plus und Claude-3V Sonnet. 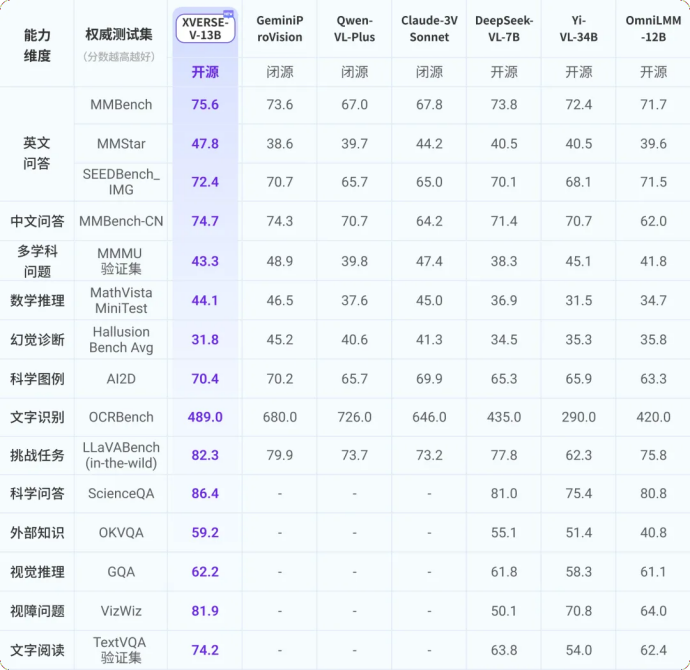 Abbildung. Umfassende Bewertung multimodaler großer Modelle
Abbildung. Umfassende Bewertung multimodaler großer Modelle
Fusion von globaler und lokaler hochauflösender Bilddarstellung
Traditionelle multimodale Modellbilddarstellung hat nur das Ganze, XVERSE-V verfolgt auf innovative Weise eine Strategie der Integration des Ganzen und der Teil unterstützt die Eingabe von Bildern mit jedem Seitenverhältnis. Unter Berücksichtigung sowohl globaler Übersichtsinformationen als auch lokaler Detailinformationen können subtile Merkmale in Bildern identifiziert und analysiert, klarer gesehen und genauer verstanden werden. E Hinweis: Concate* gibt an, dass die Verarbeitungsmethode gemäß der Spalte durchgeführt wird. 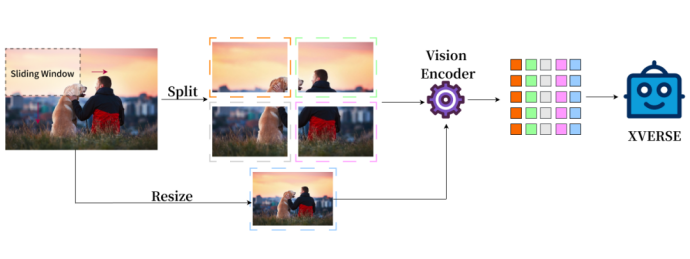
 Modelle können in einer Vielzahl von Bereichen verwendet werden, einschließlich der Erkennung von Panoramakarten, Satellitenbildern und der Analyse antiker kultureller Relikte.
Modelle können in einer Vielzahl von Bereichen verwendet werden, einschließlich der Erkennung von Panoramakarten, Satellitenbildern und der Analyse antiker kultureller Relikte.

 Kostenloser Download eines großen Modells
Kostenloser Download eines großen Modells
•Hugging Face: https://huggingface.co/xverse/XVERSE-V-13B
•ModelScope:https ://modelscope.cn/models/xverse/XVERSE-V-13B•Github: https://github.com/xverse-ai/XVERSE-V-13B•Für Anfragen senden Sie bitte: opensource@xverse .cnYuanxiang erstellt weiterhin inländische Open-Source-Benchmarks, darunter den frühesten Open Source des Landes mit einem maximalen Parameter von 65B, den weltweit frühesten Open Source mit dem längsten Kontext von 256K
und das international hochmoderne MoE-Modellund führt das Land in der SuperCLUE-Bewertung an. Die Einführung des MoE-Modells füllt dieses Mal die Lücke im inländischen Open Source und bringt es auf das international führende Niveau. In Bezug auf die kommerzielle Anwendung ist das Yuanxiang-Großmodell eines der ersten Modelle in Guangdong, das eine nationale Registrierung erhielt und kann Dienstleistungen für die gesamte Gesellschaft erbringen. Yuanxiang Large Model führt seit letztem Jahr eine intensive Zusammenarbeit und Anwendungserkundung mit einer Reihe von Tencent-Produkten durch, darunter QQ Music, Huya Live, National Karaoke, Tencent Cloud usw., um innovative und führende Produkte für diese Bereiche zu entwickeln aus Kultur, Unterhaltung, Tourismus und Finanzen.
Hervorragende Leistung in multidirektionalen praktischen Anwendungen Das Modell schneidet nicht nur in den Grundfunktionen gut ab, sondern schneidet auch in tatsächlichen Anwendungsszenarien gut ab. Sie verfügen über die Fähigkeit, verschiedene Szenarien zu verstehen und mit unterschiedlichen Anforderungen wie Informationsgrafiken, Dokumenten, realen Szenarien, mathematischen Fragen, wissenschaftlichen Dokumenten, Codekonvertierung usw. umzugehen.
Das Modell schneidet nicht nur in den Grundfunktionen gut ab, sondern schneidet auch in tatsächlichen Anwendungsszenarien gut ab. Sie verfügen über die Fähigkeit, verschiedene Szenarien zu verstehen und mit unterschiedlichen Anforderungen wie Informationsgrafiken, Dokumenten, realen Szenarien, mathematischen Fragen, wissenschaftlichen Dokumenten, Codekonvertierung usw. umzugehen.
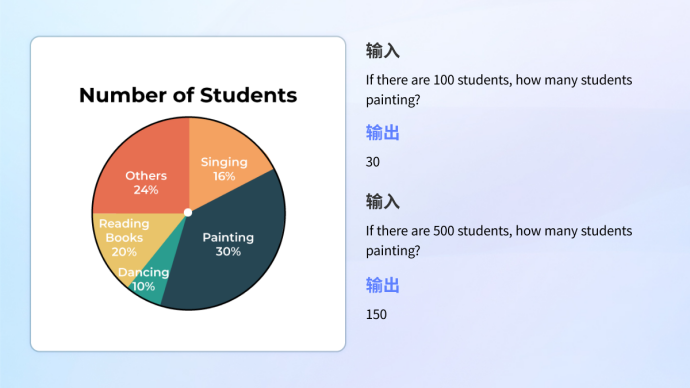
•Diagrammverständnis
Ob es sich um das Verständnis von Informationsgrafiken handelt, die komplexe Grafiken und Texte kombinieren, oder um die Analyse und Berechnung eines einzelnen Diagramms, das Modell kann damit problemlos umgehen. 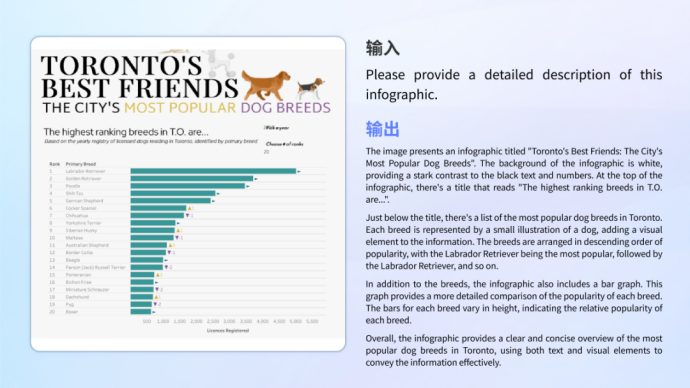
•Echte Szenen mit Sehbehinderung
Im Testset für echte Sehbehinderungsszenen VizWiz schnitt XVERSE-V gut ab und übertraf fast alle Mainstream-Open-Source-Anwendungen wie InternVL-Chat-V1.5 und DeepSeek-VL- 7B Multimodale Großmodelle. Dieses Testset enthält mehr als 31.000 visuelle Fragen und Antworten von echten sehbehinderten Benutzern, die die tatsächlichen Bedürfnisse und trivialen Probleme der Benutzer genau widerspiegeln und sehbehinderten Menschen helfen können, ihre täglichen echten visuellen Herausforderungen zu meistern.测试 Vizwiz-Testbeispiel 
• •
Xverse-V verfügt über eine multimodale Fähigkeit und behält gleichzeitig eine starke Fähigkeit zur Textgenerierung bei.

Bildungsproblemlösung
Das Modell verfügt über ein breites Spektrum an Wissensreserven und logischen Denkfähigkeiten und kann Bilder erkennen, um Fragen in verschiedenen Disziplinen zu beantworten.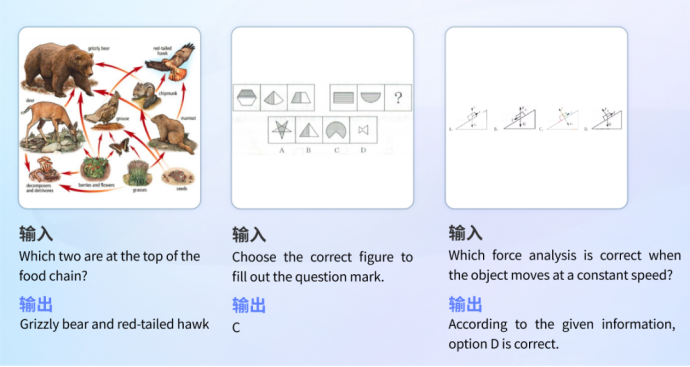
Enzyklopädie-Antworten
Das Modell speichert Wissen zu verschiedenen Themen wie Geschichte, Kultur, Technologie und Sicherheit.
Code schreiben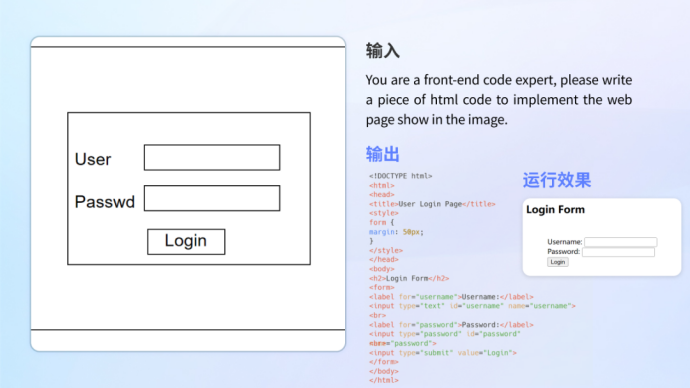
Autonomes Fahren
Emotionsverständnis und -erkennung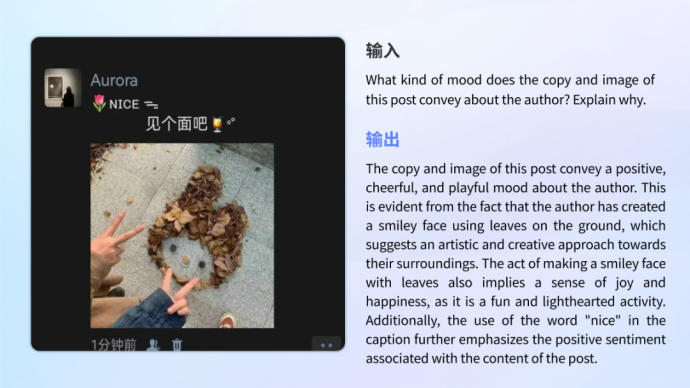
Das obige ist der detaillierte Inhalt vonYuanxiangs erstes multimodales Großmodell XVERSE-V ist Open Source, aktualisiert die Liste der maßgeblichen Großmodelle und unterstützt die Eingabe aller Seitenverhältnisse. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!