Die AIxiv-Kolumne ist eine Kolumne, in der akademische und technische Inhalte auf dieser Website veröffentlicht werden. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail-Adresse: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.
In letzter Zeit haben sich groß angelegte KI-Modelle wie große Sprachmodelle und vinzentinische Graphenmodelle rasant entwickelt. In dieser Situation ist die Anpassung an sich schnell ändernde Anforderungen und die schnelle Anpassung großer Modelle an verschiedene nachgelagerte Aufgaben zu einer wichtigen Herausforderung geworden. Aufgrund der begrenzten Rechenressourcen sind herkömmliche Feinabstimmungsmethoden für vollständige Parameter möglicherweise unzureichend. Daher müssen effizientere Feinabstimmungsstrategien erforscht werden. Die oben genannten Herausforderungen haben zu der jüngsten rasanten Entwicklung der Parameter-effizienten Feinabstimmungstechnologie (PEFT) geführt. Um die Entwicklungsgeschichte der PEFT-Technologie umfassend zusammenzufassen und mit den neuesten Forschungsfortschritten Schritt zu halten, haben Forscher der Northeastern University, der University of California Riverside, der Arizona State University und der New York University kürzlich die Parameter untersucht, organisiert und zusammengefasst Die Anwendung der effizienten Feinabstimmungstechnologie (PEFT) auf große Modelle und ihre Entwicklungsaussichten werden in einem umfassenden und hochmodernen Bericht zusammengefasst.
Link zum Papier: https://arxiv.org/pdf/2403.14608.pdfPEFT bietet ein effizientes Mittel zur nachgelagerten Aufgabenanpassung für vorab trainierte Modelle, indem es die meisten Parameter und Parameter vor dem Training festlegt Die Feinabstimmung einer sehr kleinen Anzahl von Parametern ermöglicht es großen Modellen, sich leicht zu bewegen und sich schnell an verschiedene nachgelagerte Aufgaben anzupassen, sodass große Modelle nicht mehr „Big Mac“ sind. Der vollständige Text ist 24 Seiten lang und umfasst fast 250 aktuelle Dokumente. Er wurde sofort nach seiner Veröffentlichung von der Stanford University, der Peking University und anderen Institutionen zitiert und erfreute sich auf verschiedenen Plattformen großer Beliebtheit.
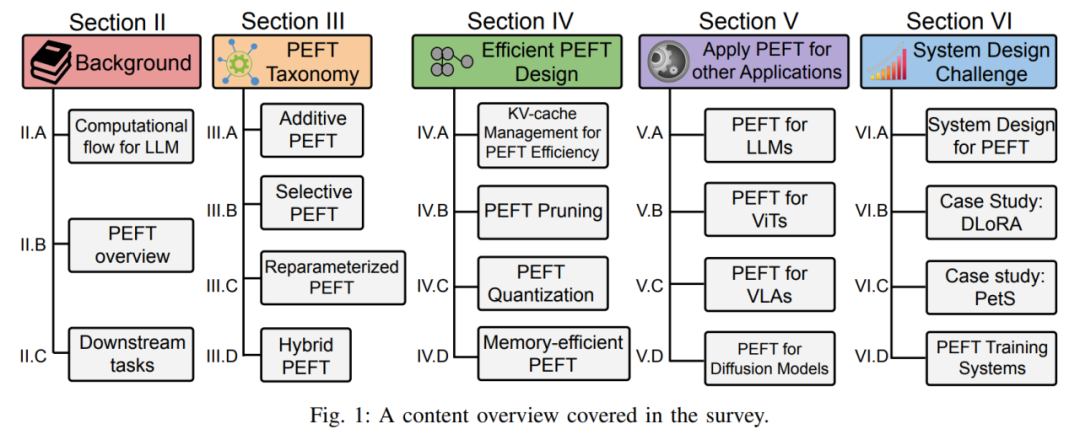
In dieser Rezension werden insbesondere die Entwicklungsgeschichte und die neuesten Fortschritte von PEFT unter vier Aspekten umfassend analysiert: PEFT-Algorithmusklassifizierung, effizientes PEFT-Design, feldübergreifende PEFT-Anwendung sowie PEFT-Systemdesign und -bereitstellung sowie detaillierte Erläuterungen . Unabhängig davon, ob Sie ein Praktiker in verwandten Branchen oder ein Anfänger auf dem Gebiet der Feinabstimmung großer Modelle sind, kann dieser Testbericht als umfassender Lernleitfaden dienen. 1. Hintergrundeinführung in PEFT basierte Modelle und definiert die erforderliche symbolische Darstellung, um die spätere Analyse verschiedener PEFT-Technologien zu erleichtern.
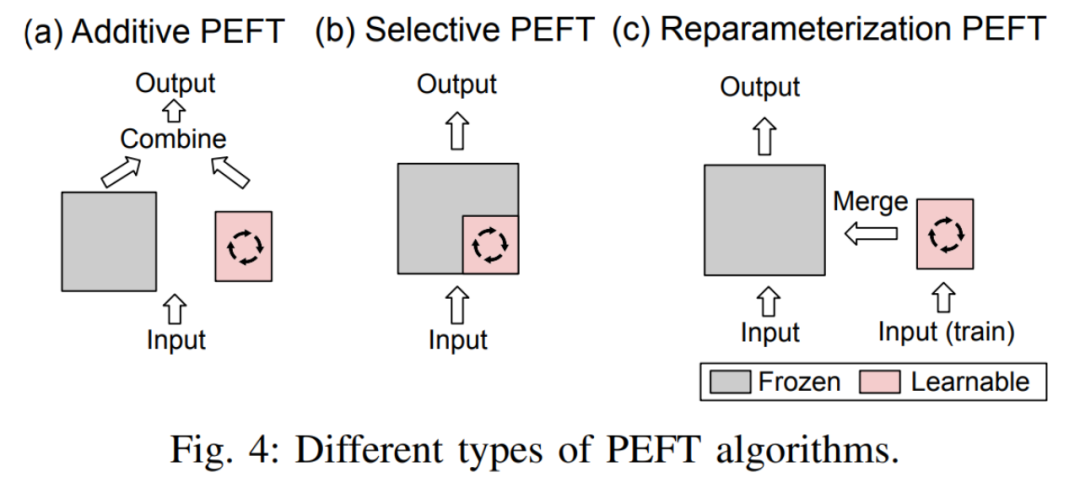
Darüber hinaus skizziert der Autor auch die Klassifizierungsmethode des PEFT-Algorithmus. Der Autor unterteilt den PEFT-Algorithmus in additive Feinabstimmung, selektive Feinabstimmung, stark parametrisierte Feinabstimmung und hybride Feinabstimmung entsprechend verschiedenen Operationen. Abbildung 3 zeigt die Klassifizierung von PEFT-Algorithmen und die spezifischen Algorithmusnamen, die in jeder Kategorie enthalten sind. Die spezifischen Definitionen jeder Kategorie werden später im Detail erläutert.
Im Hintergrundabschnitt stellt der Autor außerdem gängige Downstream-Benchmarks und Datensätze vor, die zur Überprüfung der Leistung der PEFT-Methode verwendet werden, um es den Lesern zu erleichtern, sich mit allgemeinen Aufgabeneinstellungen vertraut zu machen. 2. Klassifizierung der PEFT-Methode Additive Feinabstimmung
Durch Hinzufügen lernbarer Module oder Parameter an bestimmten Stellen im vorab trainierten Modell, um die Anzahl der trainierbaren Parameter des Modells bei der Anpassung an nachgelagerte Aufgaben zu minimieren. Selektive FeinabstimmungBeim Feinabstimmungsprozess wird nur ein Teil der Parameter im Modell aktualisiert, während die übrigen Parameter unverändert bleiben. Im Vergleich zur additiven Feinabstimmung erfordert die selektive Feinabstimmung keine Änderung der Architektur des vorab trainierten Modells.
Reparametrisierte Feinabstimmung funktioniert durch die Konstruktion (niedrigrangiger) Darstellungen vorab trainierter Modellparameter für das Training. Während der Inferenz werden die Parameter äquivalent in die vorab trainierte Modellparameterstruktur konvertiert, um zusätzliche Inferenzverzögerungen zu vermeiden.
- Der Unterschied zwischen den drei ist in Abbildung 4 dargestellt:
- Hybrid-Feinabstimmung kombiniert die Vorteile verschiedener PEFT-Methoden und erstellt ein einheitliches PEFT, indem die Ähnlichkeiten verschiedener Methodenarchitekturen analysiert werden. oder optimale PEFT-Hyperparameter finden.
Als nächstes unterteilt der Autor jede PEFT-Kategorie weiter: A. Additive Feinabstimmung:
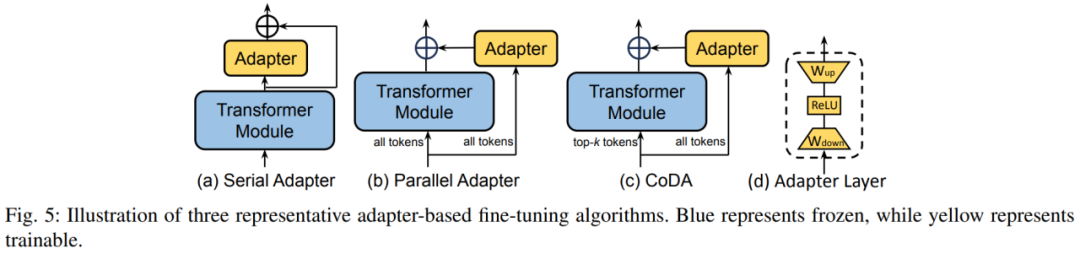
Adapter durch Hinzufügen eines kleinen Transformators im Transformatorblock Die Adapterschicht implementiert eine effiziente Feinabstimmung von Parametern. Jede Adapterschicht enthält eine Abwärtsprojektionsmatrix, eine Aktivierungsfunktion und eine Aufwärtsprojektionsmatrix. Die Abwärtsprojektionsmatrix ordnet die Eingabemerkmale der Engpassdimension r zu, und die Aufwärtsprojektionsmatrix ordnet die Engpassmerkmale wieder der ursprünglichen Dimension d zu. Abbildung 5 zeigt drei typische Einfügungsstrategien der Adapterschicht im Modell. Der serielle Adapter wird nacheinander nach dem Transformer-Modul eingefügt, und der parallele Adapter wird parallel neben dem Transformer-Modul eingefügt. CoDA ist eine Sparse-Adapter-Methode. CoDA verwendet sowohl das vorab trainierte Transformer-Modul als auch den Adapter-Zweig für die Argumentation. Für unwichtige Token verwendet CoDA nur den Adapter-Zweig für die Argumentation, um Rechenaufwand zu sparen. 2) Soft PromptSoft Prompt erreicht eine effiziente Feinabstimmung von Parametern durch das Hinzufügen lernbarer Vektoren am Kopf der Eingabesequenz. Repräsentative Methoden umfassen Präfix-Tuning und Prompt-Tuning. Die Präfixoptimierung ermöglicht die Feinabstimmung der Modelldarstellung durch das Hinzufügen lernbarer Vektoren vor den Schlüssel-, Wert- und Abfragematrizen jeder Transformer-Ebene. Prompt Tuning fügt nur lernbare Vektoren in die erste Wortvektorebene ein, um die Trainingsparameter weiter zu reduzieren.
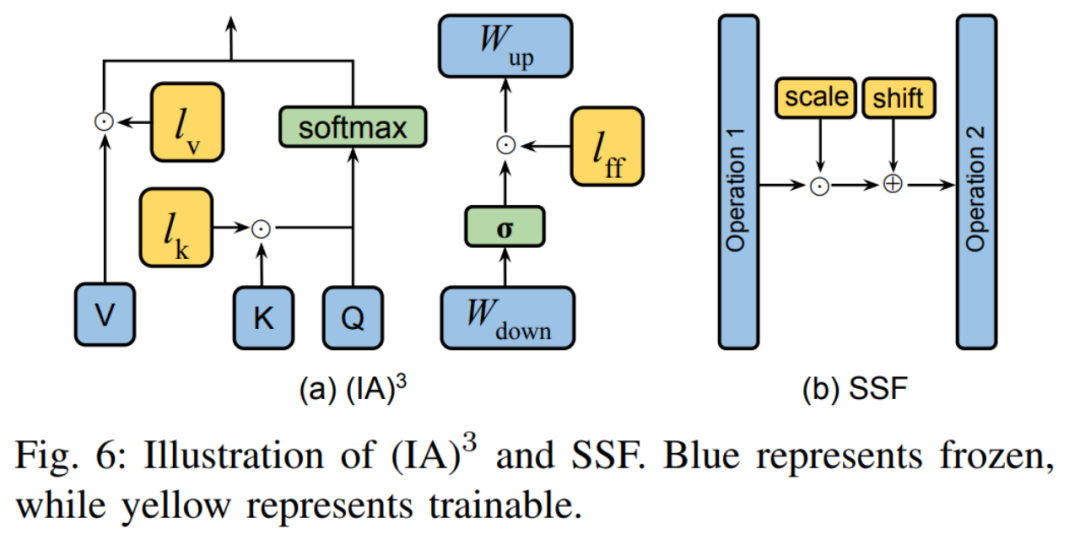
3) AndereZusätzlich zu den beiden oben genannten Klassifizierungen gibt es auch einige PEFT-Methoden, die auch neue Parameter in den Trainingsprozess einführen. Die beiden typischen Methoden sind in Abbildung 6 dargestellt. (IA) 3 führt drei Skalierungsvektoren zum Anpassen von Schlüsseln, Werten und Aktivierungen von Feedforward-Netzwerken ein. SSF passt den Aktivierungswert des Modells durch lineare Transformation an. Nach jedem Schritt fügt SSF eine SSF-ADA-Schicht hinzu, um die Skalierung und Übersetzung von Aktivierungswerten zu ermöglichen. B. Selektive Feinabstimmung: 1) Unstrukturierte Maske
Diese Art von Methode bestimmt die Parameter, die durch Hinzufügen einer lernbaren Binärmaske zu den Modellparametern feinabgestimmt werden können. . Viele Arbeiten wie Diff Pruning, FishMask und LT-SFT usw. konzentrieren sich auf die Berechnung der Position der Maske. 2) Strukturierte Maske Unstrukturierte Maske unterliegt keinen Einschränkungen hinsichtlich der Form der Maske, dies führt jedoch zu einer Ineffizienz in ihrer Wirkung. Daher legen einige Werke wie FAR, S-Bitfit, Xattn Tuning usw. strukturierte Einschränkungen für die Form der Maske fest. Der Unterschied zwischen den beiden ist im Bild unten dargestellt:
C. Neuparametrisierte Feinabstimmung:
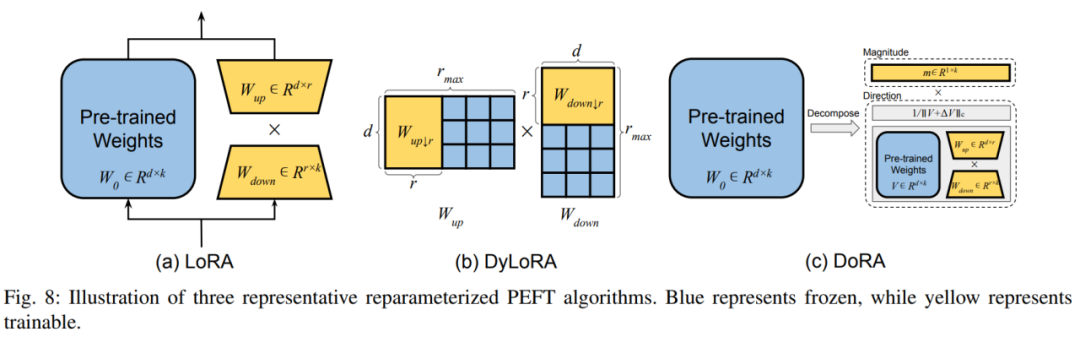
Diese Art von Methode funktioniert, indem sie verschiedene niedrigdimensionale, neuparametrisierte Formen der vorab trainierten Gewichtsmatrix findet, die dargestellt werden sollen den gesamten Parameterraum zur Feinabstimmung. Die typischste Methode ist LoRA, die eine Low-Rank-Darstellung der ursprünglichen Modellparameter für das Training erstellt, indem sie zwei zusätzliche Auf- und Abwärtsprojektionsmatrizen hinzufügt. Nach dem Training können zusätzliche Parameter nahtlos in vorab trainierte Gewichte integriert werden, um zusätzlichen Inferenzaufwand zu vermeiden. DoRA entkoppelt die Gewichtsmatrix in modulare Länge und Richtung und nutzt LoRA zur Feinabstimmung der Richtungsmatrix. 2) LoRA-Ableitungsmethode Der Autor unterteilt die LoRA-Ableitungsmethode in die dynamische Auswahl des LoRA-Rangs und die Verbesserung von LoRA in verschiedenen Aspekten. Im dynamischen LoRA-Rang ist die typische Methode DyLoRA, die eine Reihe von Rängen für gleichzeitiges Training während des Trainingsprozesses erstellt und so den Ressourcenaufwand für die Suche nach dem optimalen Rang reduziert. Bei der Verbesserung von LoRA listet der Autor die Mängel des traditionellen LoRA in verschiedenen Aspekten und die entsprechenden Lösungen auf. D. Hybrid-Feinabstimmung: In diesem Teil wird untersucht, wie man verschiedene PEFT-Technologien in ein einheitliches Modell integriert und ein optimales Designmuster findet. Darüber hinaus werden auch einige Lösungen vorgestellt, die die neuronale Architektursuche (NAS) verwenden, um optimale PEFT-Trainingshyperparameter zu erhalten. 3. Effizientes PEFT-Design
In diesem Abschnitt bespricht der Autor Forschungsergebnisse zur Verbesserung der Effizienz von PEFT und konzentriert sich dabei auf die Latenz und den Spitzenspeicheraufwand für das Training und die Inferenz. Der Autor beschreibt hauptsächlich aus drei Perspektiven, wie die Effizienz von PEFT verbessert werden kann. Dies sind: PEFT-Beschneidungsstrategie: Kombination der Beschneidungstechnologie für neuronale Netze und der PEFT-Technologie zur weiteren Verbesserung der Effizienz. Zu den repräsentativen Aufgaben gehören AdapterDrop, SparseAdapter usw. PEFT-Quantifizierungsstrategie: Das heißt, die Modellgröße wird reduziert, indem die Modellgenauigkeit verringert wird, wodurch die Recheneffizienz verbessert wird. In Kombination mit PEFT besteht die Hauptschwierigkeit darin, die Gewichte vor dem Training und die Quantisierungsverarbeitung des neuen PEFT-Moduls besser auszubalancieren. Zu den repräsentativen Werken gehören QLoRA, LoftQ usw. Speichereffizientes PEFT-Design: Obwohl PEFT während des Trainings nur eine kleine Anzahl von Parametern aktualisieren kann, ist sein Speicherbedarf aufgrund der Notwendigkeit einer Gradientenberechnung und Backpropagation immer noch groß. Um dieser Herausforderung zu begegnen, versuchen einige Methoden, den Speicheraufwand zu reduzieren, indem sie die Gradientenberechnung innerhalb der vorab trainierten Gewichte umgehen, z. B. Side-Tuning und LST. Gleichzeitig versuchen andere Methoden, eine Rückausbreitung innerhalb des LLM zu vermeiden, um dieses Problem zu lösen, wie z. B. HyperTuning, MeZO usw. 4. Feldübergreifende Anwendungen von PEFT besprochen. Dieser Abschnitt konzentriert sich hauptsächlich auf verschiedene groß angelegte vorab trainierte Modelle, darunter LLM, Visual Transformer (ViT), visuelles Textmodell und Diffusionsmodell, und beschreibt ausführlich die Rolle von PEFT bei der nachgelagerten Aufgabenanpassung dieser vorab trainierten Modelle. In Bezug auf LLM stellte der Autor vor, wie man PEFT zur Feinabstimmung von LLM verwendet, um visuelle Befehlseingaben und repräsentative Arbeiten wie LLaMA-Adapter zu akzeptieren. Darüber hinaus untersucht der Autor auch die Anwendung von PEFT beim kontinuierlichen Lernen von LLM und erwähnt, wie man LLM mit PEFT verfeinern kann, um sein Kontextfenster zu erweitern.
Für ViT beschreibt der Autor, wie man die PEFT-Technologie nutzt, um sie an nachgelagerte Bilderkennungsaufgaben anzupassen, und wie man PEFT nutzt, um ViT-Videoerkennungsfunktionen bereitzustellen.
In Bezug auf visuelle Textmodelle stellte der Autor viele Arbeiten vor, in denen PEFT zur Feinabstimmung visueller Textmodelle für offene Bildklassifizierungsaufgaben angewendet wird.
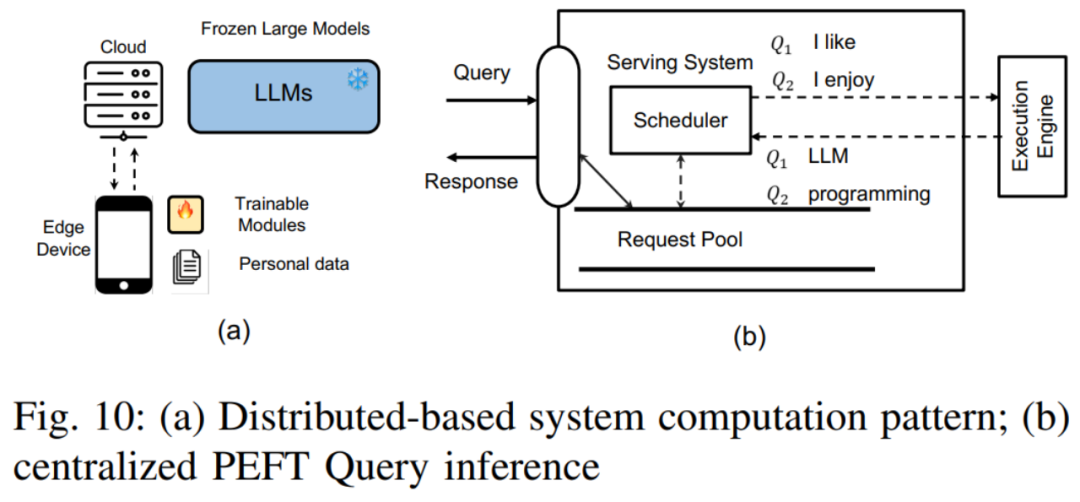
Für das Diffusionsmodell identifiziert der Autor zwei häufige Szenarien: wie man neben Text zusätzliche Eingaben hinzufügt und wie man eine personalisierte Generierung erreicht, und beschreibt jeweils die Anwendung von PEFT bei diesen beiden Arten von Aufgaben. 5. Herausforderungen beim Systemdesign von PEFT Es umfasst hauptsächlich die folgenden Punkte: Zentraler PEFT-Abfragedienst: In diesem Modus speichert der Cloud-Server eine einzelne LLM-Modellkopie und mehrere PEFT-Module. Entsprechend den Aufgabenanforderungen verschiedener PEFT-Abfragen wählt der Cloud-Server das entsprechende PEFT-Modul aus und integriert es in das LLM-Modell. Verteilter PEFT-Abfragedienst: In diesem Modus wird das LLM-Modell auf dem Cloud-Server gespeichert, während die PEFT-Gewichte und Datensätze auf dem Benutzergerät gespeichert werden. Das Benutzergerät verwendet die PEFT-Methode zur Feinabstimmung des LLM-Modells und lädt dann die feinabgestimmten PEFT-Gewichte und den Datensatz auf den Cloud-Server hoch.
Mehrfaches PEFT-Training: Zu den Herausforderungen gehören die Verwaltung von Speichergradienten und die Modellgewichtsspeicherung sowie die Entwicklung eines effizienten Kernels zum stapelweisen Training von PEFT usw. Als Reaktion auf die oben genannten Herausforderungen beim Systemdesign listete der Autor drei detaillierte Systemdesignfälle auf, um eine tiefergehende Analyse dieser Herausforderungen und praktikable Lösungsstrategien zu ermöglichen. Offsite-Tuning: Löst hauptsächlich das Datenschutzdilemma und die massiven Ressourcenverbrauchsprobleme, die bei der Feinabstimmung von LLM auftreten. PetS: Bietet ein einheitliches Service-Framework und einen einheitlichen Verwaltungs- und Planungsmechanismus für PEFT-Module. PEFT Parallel Training Framework: Stellt zwei parallele PEFT-Trainingsframeworks vor, darunter S-LoRA und Punica, und wie sie die Trainingseffizienz von PEFT verbessern. 6. Zukünftige Forschungsrichtungen Der Autor ist der Ansicht, dass die PEFT-Technologie zwar bei vielen nachgelagerten Aufgaben erfolgreich war, es jedoch immer noch einige Mängel gibt, die in zukünftigen Arbeiten behoben werden müssen. Etablieren Sie einen einheitlichen Bewertungsmaßstab: Obwohl es einige PEFT-Bibliotheken gibt, fehlt ein umfassender Maßstab, um die Wirksamkeit und Effizienz verschiedener PEFT-Methoden fair zu vergleichen. Durch die Festlegung eines anerkannten Maßstabs werden Innovation und Zusammenarbeit innerhalb der Gemeinschaft gefördert. Verbesserte Trainingseffizienz: PEFTs Menge an trainierbaren Parametern stimmt nicht immer mit den Rechen- und Speichereinsparungen während des Trainings überein. Wie im Abschnitt „Effizientes PEFT-Design“ erläutert, können zukünftige Forschungsarbeiten weitere Möglichkeiten zur Optimierung des Speichers und der Recheneffizienz untersuchen. Erforschung des Skalierungsgesetzes: Viele PEFT-Techniken werden auf kleineren Transformer-Modellen implementiert, und ihre Wirksamkeit ist nicht unbedingt auf die verschiedenen heutigen Modelle mit großen Parametern anwendbar. Zukünftige Forschungen könnten untersuchen, wie die PEFT-Methode an große Modelle angepasst werden kann. Mehr Modelle und Aufgaben bedienen: Mit dem Aufkommen größerer Modelle wie Sora, Mamba usw. kann die PEFT-Technologie neue Anwendungsszenarien erschließen. Zukünftige Forschung könnte sich auf die Entwicklung von PEFT-Methoden für bestimmte Modelle und Aufgaben konzentrieren. Verbesserter Datenschutz: Zentralisierte Systeme können bei der Bereitstellung oder Feinabstimmung personalisierter PEFT-Module mit Datenschutzproblemen konfrontiert sein. Zukünftige Forschungen könnten Verschlüsselungsprotokolle zum Schutz personenbezogener Daten und zwischenzeitlicher Trainings-/Inferenzergebnisse untersuchen. PEFT und Modellkomprimierung: Der Einfluss von Modellkomprimierungstechniken wie Pruning und Quantisierung auf die PEFT-Methode wurde nicht vollständig untersucht. Zukünftige Forschung könnte sich darauf konzentrieren, wie sich das komprimierte Modell an die Leistung der PEFT-Methode anpasst.
Das obige ist der detaillierte Inhalt vonLassen Sie große Modelle nicht länger „Big Mac' sein. Dies ist die neueste Überprüfung der effizienten Feinabstimmung großer Modellparameter.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!