
Heim >Technologie-Peripheriegeräte >KI >Quantifizierung, Beschneidung, Destillation, was genau sagen diese großen Modell-Slangs aus?
Quantifizierung, Beschneidung, Destillation, was genau sagen diese großen Modell-Slangs aus?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-04-26 09:28:181033Durchsuche
Quantifizierung, Beschneidung, Destillation: Wenn Sie häufig auf große Sprachmodelle achten, werden Sie diese Wörter auf jeden Fall sehen. Es ist für uns schwierig zu verstehen, was sie bewirken, aber diese Wörter sind besonders wichtig für die Entwicklung großer Sprachmodelle in dieser Phase. Dieser Artikel wird Ihnen helfen, sie kennenzulernen und ihre Prinzipien zu verstehen.
Modellkomprimierung
Quantifizierung, Bereinigung und Destillation sind eigentlich allgemeine Komprimierungstechnologien für neuronale Netzwerkmodelle, die nicht nur für große Sprachmodelle gelten.
Die Bedeutung der Modellkomprimierung
Nach der Komprimierung wird die Modelldatei kleiner, der verwendete Festplattenspeicher wird ebenfalls kleiner, der Cache-Speicherplatz, der beim Laden in den Speicher oder bei der Anzeige verwendet wird, wird ebenfalls kleiner Die Laufzeit des Modells wird ebenfalls kleiner. Es kann auch zu Geschwindigkeitsverbesserungen kommen.
Durch die Komprimierung verbraucht die Verwendung des Modells weniger Rechenressourcen, was die Anwendungsszenarien des Modells erheblich erweitern kann, insbesondere an Orten, an denen Modellgröße und Recheneffizienz wichtiger sind, wie z. B. Mobiltelefone, eingebettete Geräte usw.
Was ist komprimiert?
Was komprimiert ist, sind die Parameter des Modells. Was sind die Parameter des Modells?
Sie haben vielleicht gehört, dass aktuelles maschinelles Lernen neuronale Netzwerkmodelle verwendet. Das neuronale Netzwerkmodell simuliert das neuronale Netzwerk im menschlichen Gehirn.
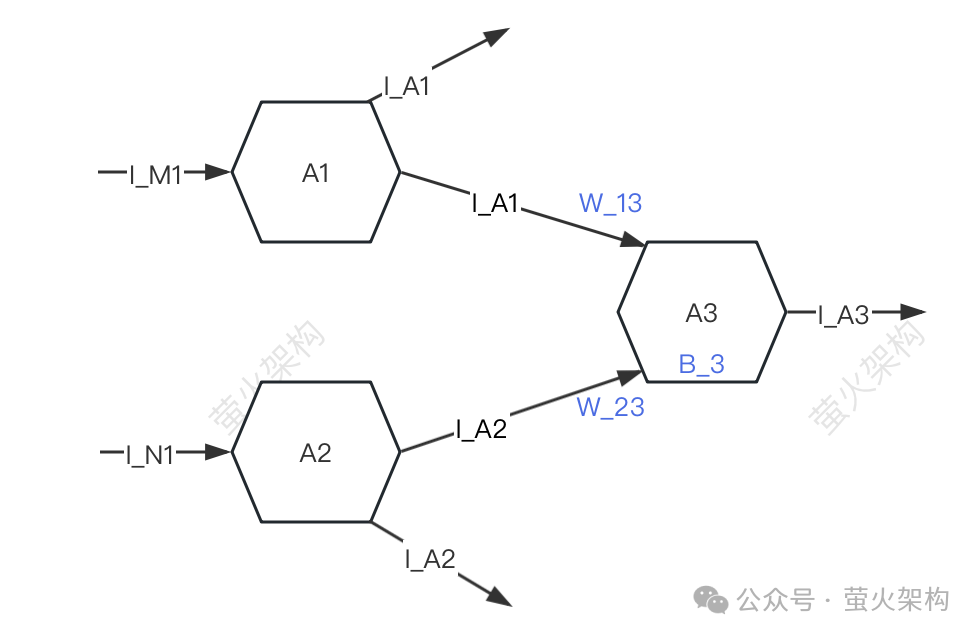
Hier habe ich ein einfaches Diagramm gezeichnet, Sie können es sich ansehen.
 Bilder
Bilder
Der Einfachheit halber werden nur drei Neuronen beschrieben: A1, A2, A3. Jedes Neuron empfängt Signale von anderen Neuronen und überträgt Signale an andere Neuronen.
A3 empfängt die Signale I_A1 und I_A2 von A1 und A2, aber die Stärke der von A3 von A1 und A2 empfangenen Signale ist unterschiedlich (diese Stärke wird als „Gewicht“ bezeichnet). W_23 bzw. A3 verarbeitet die empfangenen Signaldaten.
- Führen Sie zunächst eine gewichtete Summierung der Signale durch, d wird in eine bestimmte Form umgewandelt und das umgewandelte Signal wird an das nächste Neuron gesendet.
- Bei der Verarbeitung dieser Signaldaten sind die verwendeten Gewichte (W_13, W_23) und Offsets (B_3) die Parameter des Modells. Natürlich hat das Modell andere Parameter, aber die Gewichte und Offsets sind im Allgemeinen alle Der Großteil der Parameter sollte bei einer Aufteilung nach dem 80/20-Prinzip über 80 % liegen.
- Wenn Sie ein großes Sprachmodell zum Generieren von Text verwenden, sind diese Parameter bereits vorab trainiert und wir können sie nicht ändern. Es ist wie bei den Koeffizienten von Polynomen in der Mathematik. Wir können nur das unbekannte xyz übergeben und eine Ausgabe erhalten Ergebnisse.
Bei der Modellkomprimierung geht es um die Komprimierung dieser Parameter des Modells. Die wichtigsten Überlegungen sind Quantisierung, Beschneidung und Destillation, die im Mittelpunkt dieses Artikels stehen.
Quantisierung
Quantisierung dient dazu, die numerische Genauigkeit von Modellparametern zu verringern. Beispielsweise handelt es sich bei den anfänglich trainierten Gewichten um 32-Bit-Gleitkommazahlen, bei der tatsächlichen Verwendung stellt sich jedoch heraus, dass nahezu kein Verlust auftritt ausgedrückt in 16 Bit, aber die Modelldatei Die Größe wird um die Hälfte reduziert, die Videospeichernutzung wird um die Hälfte reduziert und die Anforderungen an die Kommunikationsbandbreite zwischen Prozessor und Speicher werden ebenfalls reduziert, was geringere Kosten und höhere Vorteile bedeutet.
Es ist, als würde man einem Rezept folgen, man muss das Gewicht jeder Zutat bestimmen. Sie können eine sehr genaue elektronische Waage verwenden, die auf 0,01 Gramm genau ist, was großartig ist, weil Sie das Gewicht jeder Zutat sehr genau kennen können. Wenn Sie jedoch gerade ein Potluck-Menü zubereiten und keine so hohe Genauigkeit benötigen, können Sie eine einfache und günstige Waage mit einer Mindestskalierung von 1 Gramm verwenden, die nicht so genau ist, aber für die Zubereitung einer köstlichen Mahlzeit ausreicht. Abendessen.
Bilder
Ein weiterer Vorteil der Quantisierung besteht darin, dass sie schneller berechnet wird. Moderne Prozessoren enthalten normalerweise viele Vektorberechnungseinheiten mit geringer Genauigkeit. Das Modell kann diese Hardwarefunktionen voll ausnutzen, um mehr parallele Operationen durchzuführen. Gleichzeitig sind Operationen mit niedriger Präzision normalerweise schneller Der Verbrauch einer einzelnen Multiplikation und Addition ist kürzer. Aufgrund dieser Vorteile kann das Modell auch auf Geräten mit niedrigerer Konfiguration ausgeführt werden, beispielsweise auf normalen Büro- oder Heimcomputern, Mobiltelefonen und anderen mobilen Endgeräten, die nicht über leistungsstarke GPUs verfügen.
Dieser Idee folgend werden weiterhin 8-Bit-, 4-Bit- und 2-Bit-Modelle komprimiert, die kleiner sind und weniger Rechenressourcen verbrauchen. Wenn jedoch die Genauigkeit der Gewichte abnimmt, werden die Werte verschiedener Gewichte näher oder sogar gleich, was die Genauigkeit und Präzision der Modellausgabe verringert und die Leistung des Modells in unterschiedlichem Maße verringert.
Die Quantisierungstechnologie verfügt über viele verschiedene Strategien und technische Details, wie z. B. dynamische Quantisierung, statische Quantisierung, symmetrische Quantisierung, asymmetrische Quantisierung usw. Bei großen Sprachmodellen werden normalerweise statische Quantisierungsstrategien verwendet Die Parameter werden einmal quantifiziert und quantitative Berechnungen sind bei der Ausführung des Modells nicht mehr erforderlich, was die Verteilung und Bereitstellung erleichtert.
Beschneiden
Beim Beschneiden werden unwichtige oder selten verwendete Gewichte im Modell entfernt. Die Werte dieser Gewichte liegen im Allgemeinen nahe bei 0. Bei einigen Modellen kann das Beschneiden zu einem höheren Komprimierungsverhältnis führen, wodurch das Modell kompakter und effizienter wird. Dies ist besonders nützlich für die Bereitstellung von Modellen auf Geräten mit eingeschränkten Ressourcen oder wenn Arbeitsspeicher und Datenspeicher begrenzt sind.
Das Beschneiden verbessert auch die Interpretierbarkeit des Modells. Durch das Entfernen unnötiger Komponenten wird durch das Bereinigen die zugrunde liegende Struktur des Modells transparenter und einfacher zu analysieren. Dies ist wichtig für das Verständnis des Entscheidungsprozesses komplexer Modelle wie neuronaler Netze.
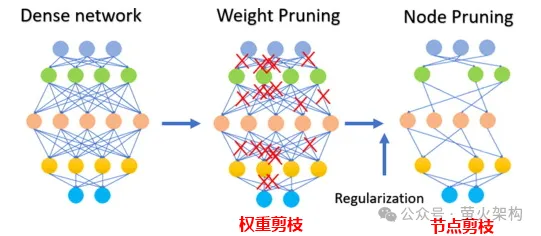
Das Beschneiden umfasst nicht nur das Beschneiden von Gewichtsparametern, sondern auch das Beschneiden bestimmter Neuronenknoten, wie in der folgenden Abbildung dargestellt:
 Bild
Bild
Beachten Sie, dass das Beschneiden nicht für alle Modelle geeignet ist, für einige spärliche Für Modelle (die meisten Parameter liegen bei 0 oder nahe bei 0) haben möglicherweise keine Auswirkungen. Bei einigen kleinen Modellen mit relativ wenigen Parametern kann die Bereinigung zu einer erheblichen Verschlechterung der Modellleistung führen Es eignet sich nicht zum Beschneiden des Modells, beispielsweise für medizinische Diagnosen, bei denen es um Leben und Tod geht.
Bei der tatsächlichen Anwendung der Beschneidungstechnologie ist es normalerweise erforderlich, die Verbesserung der Modelllaufgeschwindigkeit und die negativen Auswirkungen des Beschneidens auf die Modellleistung umfassend zu berücksichtigen und einige Strategien zu übernehmen, z. B. die Bewertung jedes Parameters im Modell, d. h. Bewertung der Parameter. Wie viel trägt es zur Modellleistung bei? Diejenigen mit hohen Werten sind wichtige Parameter, die nicht abgeschnitten werden dürfen; diejenigen mit niedrigen Werten sind Parameter, die möglicherweise nicht so wichtig sind und für eine Kürzung in Betracht gezogen werden können. Dieser Wert kann mithilfe verschiedener Methoden berechnet werden, beispielsweise anhand der Größe des Parameters (der größere Absolutwert ist normalerweise wichtiger) oder mithilfe komplexerer statistischer Analysemethoden ermittelt werden.
Destillation
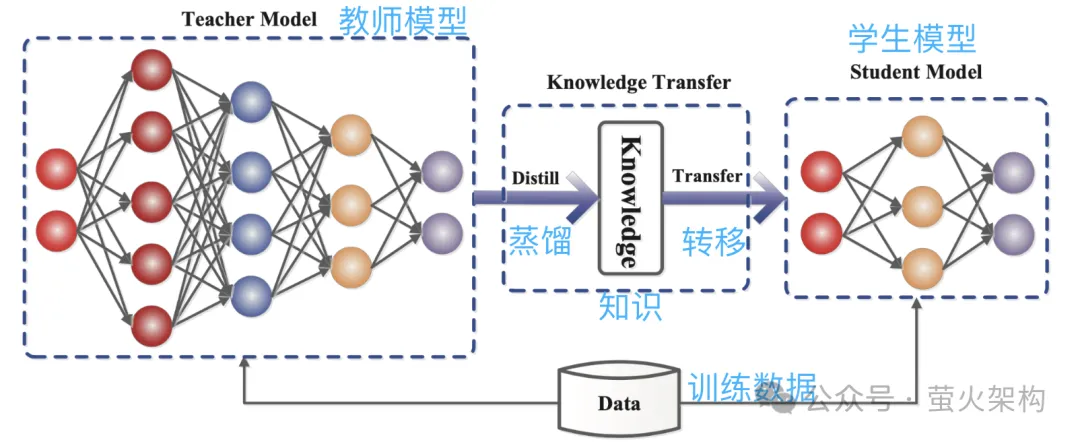
Destillation besteht darin, die vom großen Modell gelernte Wahrscheinlichkeitsverteilung direkt in ein kleines Modell zu kopieren. Das kopierte Modell wird als Lehrermodell bezeichnet und ist im Allgemeinen ein hervorragendes Modell mit einer großen Anzahl von Parametern und einer starken Leistung. Das neue Modell wird als Schülermodell bezeichnet, bei dem es sich im Allgemeinen um ein kleines Modell mit relativ wenigen Parametern handelt.
Während der Destillation generiert das Lehrermodell Wahrscheinlichkeitsverteilungen mehrerer möglicher Ausgaben basierend auf der Eingabe, und dann lernt das Schülermodell die Wahrscheinlichkeitsverteilung dieser Eingabe und Ausgabe. Nach umfassender Schulung kann das Schülermodell das Verhalten des Lehrermodells nachahmen oder das Wissen des Lehrermodells erlernen.
Zum Beispiel kann das Lehrermodell bei einer Bildklassifizierungsaufgabe bei gegebenem Bild eine Wahrscheinlichkeitsverteilung ähnlich der folgenden ausgeben:
- Katze: 0,7
- Hund: 0,4
- Auto : 0,1
Übermitteln Sie dann dieses Bild und die ausgegebenen Wahrscheinlichkeitsverteilungsinformationen zum Nachahmungslernen an das Schülermodell.
 Bilder
Bilder
Da die Destillation das Wissen des Lehrermodells in ein kleineres und einfacheres Schülermodell komprimiert, kann es sein, dass das neue Modell einige Informationen verliert. Außerdem verlässt sich das Schülermodell möglicherweise zu sehr auf das Lehrermodell. Dies führt dazu, dass das Modell eine schlechte Generalisierungsfähigkeit aufweist.
Um den Lerneffekt des Schülermodells zu verbessern, können wir einige Methoden und Strategien anwenden.
Einführung in den Temperaturparameter: Angenommen, es gibt einen Lehrer, der sehr schnell unterrichtet und die Informationsdichte sehr hoch ist, kann es für die Schüler etwas schwierig sein, ihm zu folgen. Wenn der Lehrer zu diesem Zeitpunkt langsamer vorgeht und die Informationen vereinfacht, ist es für die Schüler einfacher, sie zu verstehen. Bei der Modelldestillation spielt der Temperaturparameter eine ähnliche Rolle wie die „Anpassung der Vorlesungsgeschwindigkeit“, um dem Schülermodell (kleines Modell) zu helfen, das Wissen des Lehrermodells (großes Modell) besser zu verstehen und zu erlernen. Aus professioneller Sicht besteht die Aufgabe darin, die Wahrscheinlichkeitsverteilung der Modellausgabe glatter zu gestalten, sodass das Schülermodell die Ausgabedetails des Lehrermodells leichter erfassen und lernen kann.
Passen Sie die Struktur des Lehrermodells und des Schülermodells an: Es kann für einen Schüler schwierig sein, etwas von einem Experten zu lernen, da die Wissenslücke zwischen ihnen zu groß ist und das direkte Lernen zu diesem Zeitpunkt möglicherweise nicht möglich ist Fügen Sie in der Mitte einen Lehrer hinzu, der sowohl die Worte von Experten verstehen als auch in eine Sprache übersetzen kann, die die Schüler verstehen können. Der in der Mitte hinzugefügte Lehrer kann einige Zwischenschichten oder zusätzliche neuronale Netze hinzufügen, oder der Lehrer kann einige Anpassungen am Schülermodell vornehmen, damit es besser mit der Ausgabe des Lehrermodells übereinstimmt.
Wir haben oben drei Hauptmodellkomprimierungstechnologien vorgestellt. Tatsächlich gibt es hier noch viele Details, aber es reicht fast aus, um die Prinzipien zu verstehen. Es gibt auch andere Modellkomprimierungstechnologien und Parameterfreigabe, spärliche Verbindung usw. Interessierte Schüler können sich weitere verwandte Inhalte ansehen.
Außerdem kann die Leistung des Modells nach der Komprimierung erheblich nachlassen. Zu diesem Zeitpunkt können wir eine Feinabstimmung des Modells vornehmen, insbesondere für einige Aufgaben, die eine hohe Modellgenauigkeit erfordern, wie z. B. medizinische Diagnosen oder Finanzen Risikokontrolle, Automatisierung usw. Durch Feinabstimmung kann die Leistung des Modells bis zu einem gewissen Grad wiederhergestellt und seine Genauigkeit und Präzision in bestimmten Aspekten stabilisiert werden.
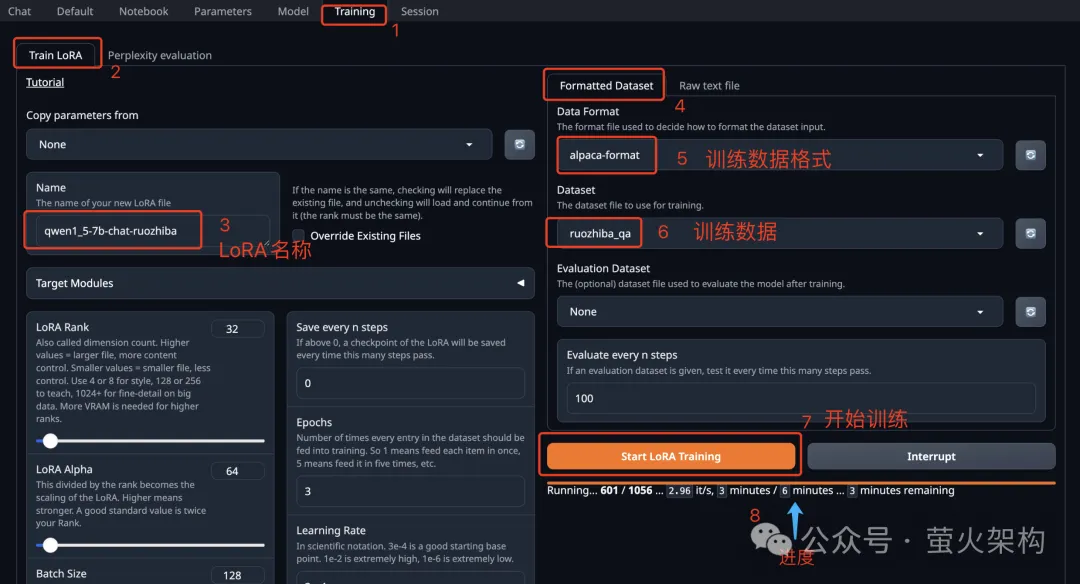
Apropos Modell-Feinabstimmung: Ich habe kürzlich ein Bild von Text Generation WebUI auf AutoDL geteilt. Text Generation WebUI ist ein mit Gradio geschriebenes Webprogramm, das problemlos Rückschlüsse und Feinabstimmungen großer Sprachmodelle durchführen kann und unterstützt Eine Vielzahl von Arten großer Sprachmodelle, darunter Transformers, llama.cpp (GGUF), GPTQ, AWQ, EXL2 und andere Modelle in verschiedenen Formaten. Im neuesten Bild habe ich das große Llama3-Modell integriert, das kürzlich von Meta als Open Source bereitgestellt wurde . Interessierte Schüler können es ausprobieren und sehen, wie man es verwendet: Lernen Sie, ein großes Sprachmodell in zehn Minuten zu verfeinern
 Bilder
Bilder
Referenzartikel:
https: //www.php.cn/link/d7852cd2408d9d3205dc75b59 a6ce22e
https://www.php.cn/link/f204aab71691a8e18c3f6f00872db63b
https://www.php.cn/link/b31f0c758bb498b5d56b5fea80 f313a7
https://www.php.cn/link/129ccfc1c1a82b0b23d4473a72373a0a
Das obige ist der detaillierte Inhalt vonQuantifizierung, Beschneidung, Destillation, was genau sagen diese großen Modell-Slangs aus?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie unterteilt der IEEE802-Standard das hierarchische Modell des lokalen Netzwerks?
- Definition von Interaktionsmethoden: Interaktion zwischen Modellquantifizierung und künstlicher Edge-Intelligenz
- Quantitative Trading-Software für digitale Währungen im Ranking der zehn besten quantitativen Trading-Plattform-Apps im Währungskreis
- ICLR 2024 Spotlight |. Großes Sprachmodellgewicht, Aktivierung, umfassende Low-Bit-Mikronisierung, wurde in die kommerzielle APP integriert