
Heim >Technologie-Peripheriegeräte >KI >CVPR 2024 |. LiDAR-Diffusionsmodell für die fotorealistische Szenengenerierung
CVPR 2024 |. LiDAR-Diffusionsmodell für die fotorealistische Szenengenerierung

- PHPznach vorne
- 2024-04-24 16:28:01956Durchsuche
Originaltitel: Towards Realistic Scene Generation with LiDAR Diffusion Models
Papierlink: https://hancyran.github.io/assets/paper/lidar_diffusion.pdf
Codelink: https://lidar-diffusion.github. io
Autorenzugehörigkeit: CMU Toyota Research Institute University of Southern California

Thesisidee:
Diffusionsmodelle (DMs) zeichnen sich durch fotorealistische Bildsynthese aus, passen sie jedoch an die Lidar-Szenengenerierung an. Die Existenz steht vor großen Herausforderungen. Dies liegt vor allem daran, dass DMs, die im Punktraum arbeiten, Schwierigkeiten haben, das Kurvenmuster und die dreidimensionalen Eigenschaften von Lidar-Szenen beizubehalten, was den größten Teil ihrer Darstellungsfähigkeiten beansprucht. In diesem Artikel werden LiDAR-Diffusionsmodelle (LiDMs) vorgeschlagen, die reale LiDAR-Szenarien simulieren, indem sie geometrische Komprimierung in den Lernprozess integrieren. In diesem Artikel wird die Kurvenkomprimierung zur Simulation realer LIDAR-Muster und die patchweise Codierung vorgestellt, um einen vollständigen 3D-Objektkontext zu erhalten. Mit diesen drei Kerndesigns etabliert dieses Papier einen neuen SOTA in bedingungslosen Lidar-Generierungsszenarien und behält gleichzeitig eine hohe Effizienz (bis zu 107-mal schneller) im Vergleich zu punktbasierten DMs bei. Durch die Komprimierung von Lidar-Szenen in den latenten Raum ermöglicht dieses Papier DMs außerdem die Steuerung unter verschiedenen Bedingungen, wie z. B. semantischen Karten, Kameraansichten und Texthinweisen.
Hauptbeiträge:
In diesem Artikel wird ein neuartiges Laser Dart Diffusion Model (LiDM) vorgeschlagen, ein generatives Modell, das realistische Lidar-Szenen basierend auf beliebigen Eingabebedingungen erzeugen kann. Nach unserem besten Wissen ist dies die erste Methode, die in der Lage ist, Lidar-Szenen aus multimodalen Bedingungen zu generieren.
In diesem Artikel wird die Komprimierung auf Kurvenebene vorgestellt, um realistische Lasermuster beizubehalten, die Koordinatenüberwachung auf Punktebene, um das Modell der Geometrie auf Szenenebene zu standardisieren, und die Codierung auf Blockebene eingeführt, um den Kontext von 3D-Objekten vollständig zu erfassen.
Dieses Papier stellt drei Indikatoren vor, um die Qualität der erzeugten Laserszene im Wahrnehmungsraum umfassend und quantitativ zu bewerten, indem verschiedene Darstellungen verglichen werden, darunter Entfernungsbilder, spärliche Volumina und Punktwolken.
Die Methode in diesem Artikel erreicht den neuesten Stand der bedingungslosen Szenensynthese unter Verwendung von 64-Zeilen-Lidar-Szenen und erreicht eine bis zu 107-fache Geschwindigkeitssteigerung im Vergleich zum punktbasierten Diffusionsmodell.
Webdesign:
In den letzten Jahren gab es eine rasante Entwicklung bedingter generativer Modelle, die in der Lage sind, optisch ansprechende und äußerst realistische Bilder zu erzeugen. Unter diesen Modellen sind Diffusionsmodelle (DMs) aufgrund ihrer einwandfreien Leistung zu einer der beliebtesten Methoden geworden. Um eine Erzeugung unter beliebigen Bedingungen zu erreichen, kombinieren latente Diffusionsmodelle (LDMs) [51] Kreuzaufmerksamkeitsmechanismen und Faltungsautoencoder, um hochauflösende Bilder zu erzeugen. Seine nachfolgenden Erweiterungen (z. B. Stable Diffusion [2], Midjourney [1], ControlNet [72]) steigerten sein Potenzial für die bedingte Bildsynthese weiter.
Dieser Erfolg hat den Gedanken zu diesem Artikel ausgelöst: Können wir kontrollierbare Diffusionsmodelle (DMs) auf die Generierung von Lidar-Szenen im autonomen Fahren und in der Robotik anwenden? Können diese Modelle beispielsweise anhand einer Reihe von Begrenzungsrahmen entsprechende LIDAR-Szenen synthetisieren und so diese Begrenzungsrahmen in hochwertige und teure Anmerkungsdaten umwandeln? Ist es alternativ möglich, eine 3D-Szene nur aus einer Reihe von Bildern zu generieren? Könnten wir noch ehrgeiziger einen sprachgesteuerten Lidar-Generator für kontrollierte Simulation entwerfen? Um diese miteinander verbundenen Fragen zu beantworten, besteht das Ziel dieser Arbeit darin, ein Diffusionsmodell zu entwerfen, das mehrere Bedingungen (z. B. Layout, Kameraansicht, Text) kombinieren kann, um realistische Lidar-Szenen zu erzeugen.
Zu diesem Zweck zieht dieser Artikel einige Erkenntnisse aus aktuellen Arbeiten zu Diffusionsmodellen (DMs) im Bereich des autonomen Fahrens. In [75] wird ein punktbasiertes Diffusionsmodell (d. h. LiDARGen) für die bedingungslose Generierung von LIDAR-Szenen eingeführt. Allerdings erzeugt dieses Modell häufig verrauschte Hintergründe (z. B. Straßen, Wände) und verschwommene Objekte (z. B. Autos), was zu erzeugten Lidar-Szenen führt, die weit von der Realität entfernt sind (siehe Abbildung 1). Darüber hinaus verlangsamt die Verteilung von Punkten ohne Komprimierung den Inferenzprozess rechentechnisch. Darüber hinaus führt die direkte Anwendung patchbasierter Diffusionsmodelle (d. h. Latent Diffusion [51]) auf die Generierung von Lidar-Szenen weder qualitativ noch quantitativ zu einer zufriedenstellenden Leistung (siehe Abbildung 1).
Um eine bedingt realistische Lidar-Szenengenerierung zu erreichen, schlägt dieser Artikel einen kurvenbasierten Generator namens Lidar-Diffusionsmodelle (LiDMs) vor, um die oben genannten Fragen zu beantworten und die Mängel in der jüngsten Arbeit zu beheben. LiDMs sind in der Lage, beliebige Bedingungen wie Begrenzungsrahmen, Kamerabilder und semantische Karten zu verarbeiten. LiDMs nutzen Entfernungsbilder als LiDAR-Szenendarstellungen, die bei verschiedenen nachgelagerten Aufgaben wie Erkennung [34, 43], semantischer Segmentierung [44, 66] und Generierung [75] sehr häufig vorkommen. Diese Wahl basiert auf der reversiblen und verlustfreien Konvertierung zwischen Entfernungsbildern und Punktwolken sowie den erheblichen Vorteilen, die sich aus hochoptimierten 2D-Faltungsoperationen ergeben. Um die semantische und konzeptionelle Essenz der Lidar-Szene während des Diffusionsprozesses zu erfassen, wandelt unsere Methode die Kodierungspunkte der Lidar-Szene vor dem Diffusionsprozess in einen wahrnehmungsmäßig äquivalenten latenten Raum um.
Um die realistische Simulation realer LIDAR-Daten weiter zu verbessern, konzentriert sich dieser Artikel auf drei Schlüsselkomponenten: Musterauthentizität, geometrische Authentizität und Objektauthentizität. Erstens nutzt dieser Artikel die Kurvenkomprimierung, um das Kurvenmuster von Punkten während der automatischen Kodierung beizubehalten, was von [59] inspiriert ist. Zweitens wird in diesem Artikel die Koordinatenüberwachung auf Punktebene eingeführt, um geometrische Authentizität zu erreichen, um unserem Autoencoder beizubringen, die geometrische Struktur auf Szenenebene zu verstehen. Schließlich erweitern wir das rezeptive Feld, indem wir zusätzliche Downsampling-Strategien auf Blockebene hinzufügen, um den vollständigen Kontext visuell größerer Objekte zu erfassen. Durch die Erweiterung durch diese vorgeschlagenen Module ermöglicht der resultierende Wahrnehmungsraum dem Diffusionsmodell die effiziente Synthese hochwertiger Lidar-Szenen (siehe Abbildung 1) und bietet gleichzeitig eine gute Geschwindigkeit im Vergleich zu punktbasierten Diffusionsmodellen 107x (evaluiert auf einem NVIDIA). RTX 3090) und unterstützt alle Arten von bildbasierten und tokenbasierten Bedingungen.
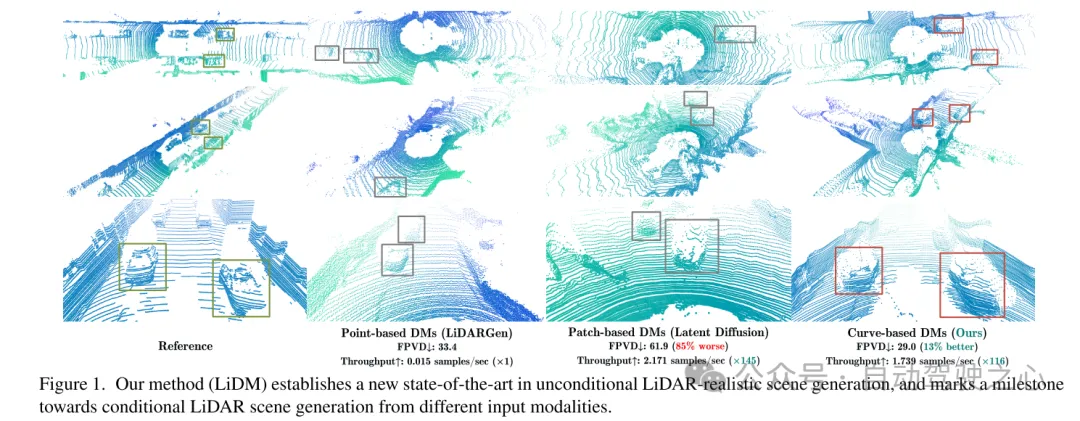
Abbildung 1. Unsere Methode (LiDM) etabliert ein neues SOTA in der bedingungslosen LiDAR-realistischen Szenengenerierung und markiert einen Meilenstein in Richtung der Generierung bedingter LiDAR-Szenen aus verschiedenen Eingabemodalitäten.
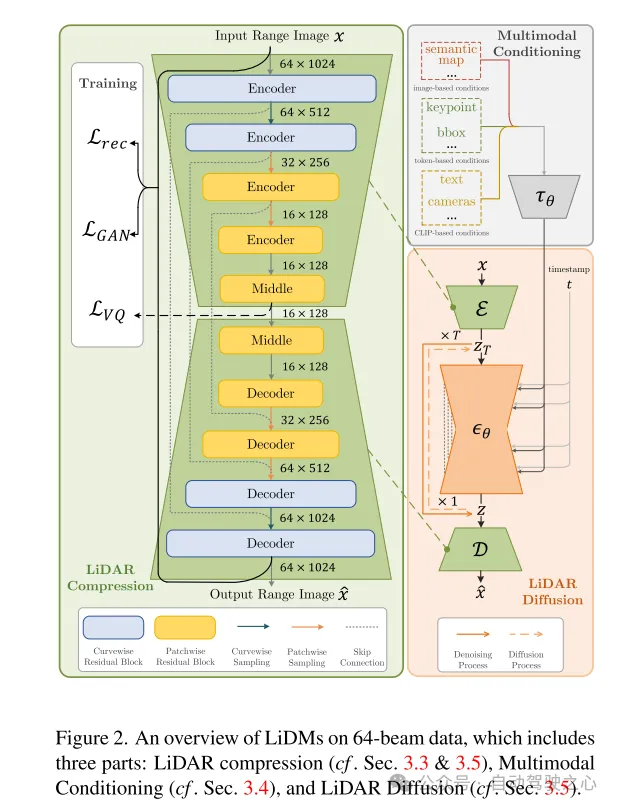
Abbildung 2. Übersicht über LiDMs für 64-Zeilen-Daten, einschließlich drei Teilen: LiDAR-Komprimierung (siehe Abschnitte 3.3 und 3.5), multimodale Konditionalisierung (siehe Abschnitt 3.4) und LiDAR-Diffusion (siehe Abschnitt 3.5).
Experimentelle Ergebnisse:

Abbildung 3. Beispiele für LiDMs aus LiDARGen [75], Latent Diffusion [51] und diesem Artikel im 64-Linien-Szenario.

Abbildung 4. Beispiel für LiDMs aus diesem Artikel im 32-Zeilen-Szenario.
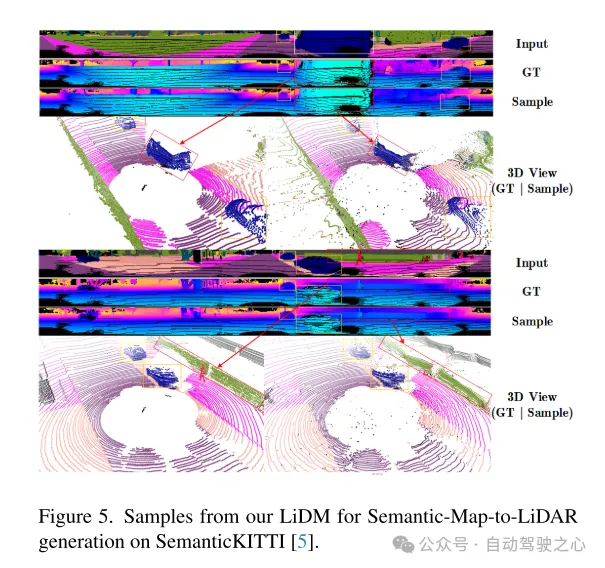
Abbildung 5. Beispiel des LiDM dieses Artikels für die semantische Map-to-Lidar-Generierung im SemanticKITTI-Datensatz [5].
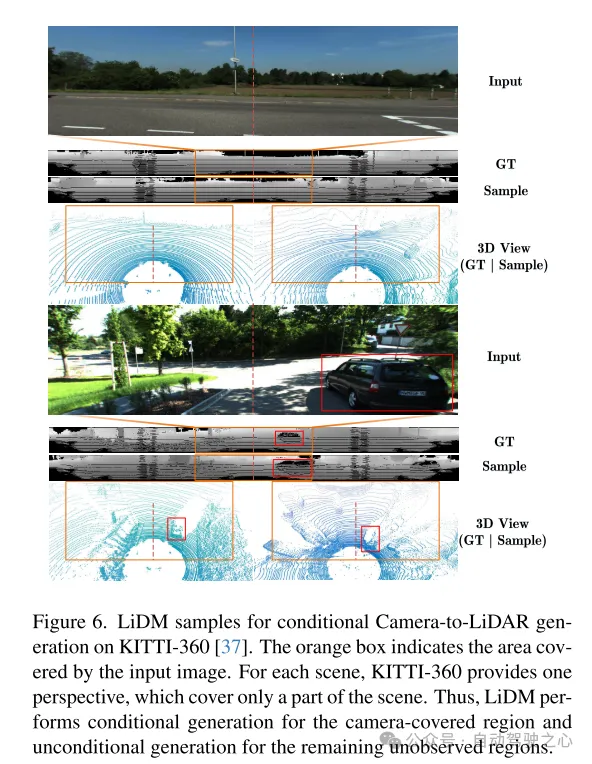
Abbildung 6. Beispiel von LiDM für die bedingte Kamera-zu-Lidar-Generierung im KITTI-360-Datensatz [37]. Das orangefarbene Kästchen zeigt den vom Eingabebild abgedeckten Bereich an. Für jede Szene bietet KITTI-360 eine Perspektive, die nur einen Teil der Szene abdeckt. Daher führt LiDM eine bedingte Generierung für die von der Kamera abgedeckten Bereiche und eine bedingungslose Generierung für die verbleibenden unbeobachteten Bereiche durch.
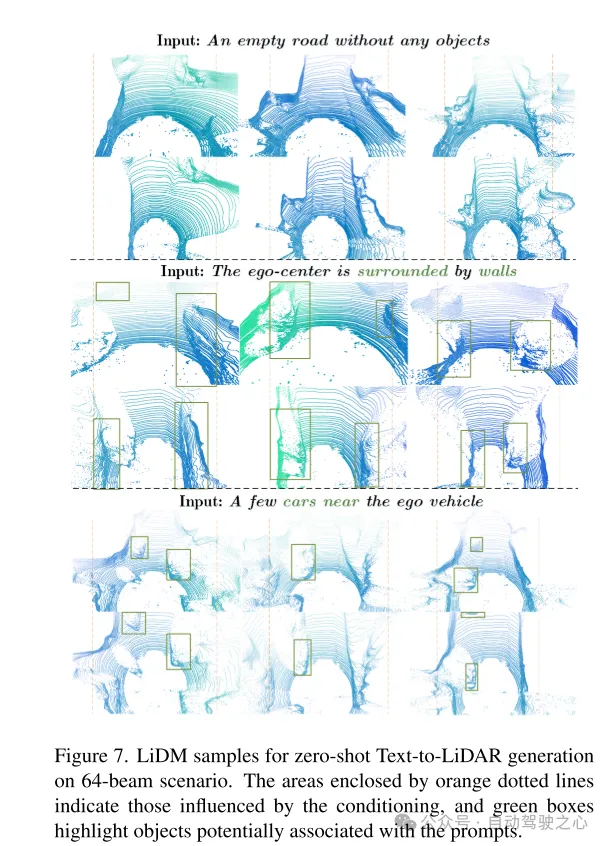
Abbildung 7. Beispiel von LiDM für die Zero-Shot-Text-zu-Lidar-Generierung in einem 64-Zeilen-Szenario. Der von der orangefarbenen gestrichelten Linie umrahmte Bereich stellt den von der Bedingung betroffenen Bereich dar, und der grüne Rahmen hebt Objekte hervor, die möglicherweise mit dem Stichwort verknüpft sind.
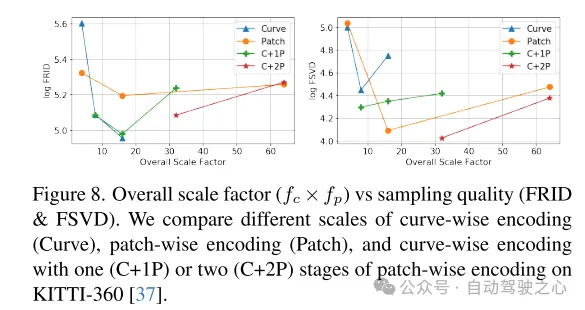
Abbildung 8. Gesamtskalierungsfaktor ( ) im Vergleich zur Stichprobenqualität (FRID und FSVD). In diesem Artikel werden die Codierung auf Kurvenebene (Curve), die Codierung auf Blockebene (Patch) und Kurven mit einer (C+1P) oder zwei (C+2P) Stufen der Codierung auf Blockebene auf verschiedenen Maßstäben auf dem KITTI-360 verglichen [ 37] Codierung auf Datensatzebene.
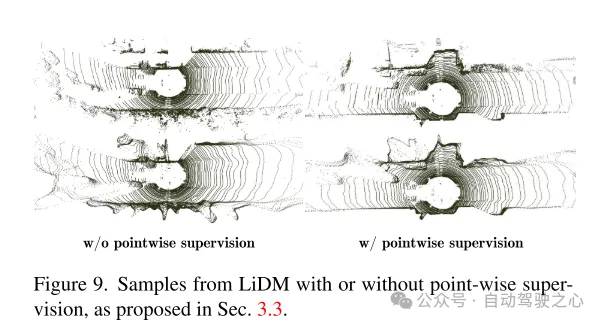
Abbildung 9. Beispiele für LiDM mit und ohne Überwachung auf Punktebene, wie in Abschnitt 3.3 vorgeschlagen.
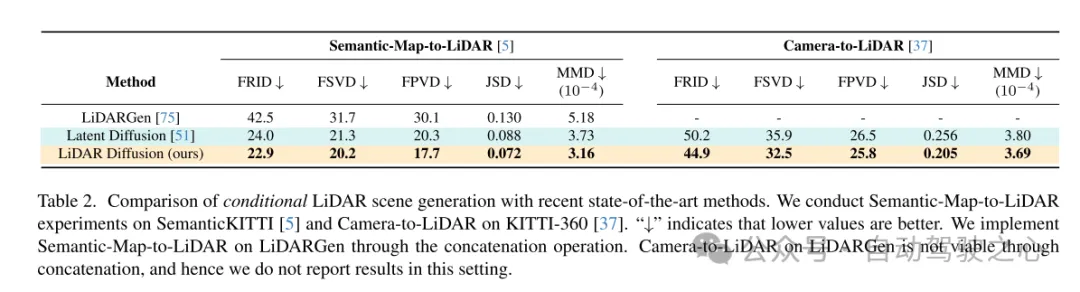

Zusammenfassung:
Dieses Papier schlägt LiDAR-Diffusionsmodelle (LiDMs) vor, ein allgemeines bedingtes Framework für die Generierung von LiDAR-Szenen. Das Design dieses Artikels konzentriert sich auf die Beibehaltung des gekrümmten Musters und der geometrischen Struktur der Szenenebene und der Objektebene und entwirft einen effizienten latenten Raum für das Diffusionsmodell, um eine realistische Lidar-Generierung zu erreichen. Dieses Design ermöglicht es den LiDMs in diesem Artikel, eine wettbewerbsfähige Leistung bei der bedingungslosen Generierung in einem 64-Zeilen-Szenario zu erreichen und das hochmoderne Niveau bei der bedingten Generierung zu erreichen. LiDMs können mithilfe einer Vielzahl von Bedingungen, einschließlich semantischer Karten, gesteuert werden , Kameraansicht und Textansagen. Nach unserem besten Wissen ist unsere Methode die erste, die erfolgreich Bedingungen in die Lidar-Generierung einführt.
Zitat:
@inproceedings{ran2024towards,
title={Auf dem Weg zu einer realistischen Szenengenerierung mit LiDAR-Diffusionsmodellen},
Autor={Ran, Haoxi und Guizilini, Vitor und Wang, Yue},
booktitle={Proceedings der IEEE/CVF-Konferenz zu Computer Vision und Mustererkennung},
Jahr={2024}
}
Das obige ist der detaillierte Inhalt vonCVPR 2024 |. LiDAR-Diffusionsmodell für die fotorealistische Szenengenerierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist der Unterschied zwischen Git und Github?
- Aubizhong Photonics und Stander Robotics arbeiten intensiv zusammen, um gemeinsam die Forschung und Entwicklung einer neuen Lidar-Generation voranzutreiben
- Intelligentes Fahren liegt im Trend, Nezha Automobile entscheidet sich für LiDAR von Hesai Technology
- Wird Radarcoin im Jahr 2024 steigen? Wird es auf 0,5 $ steigen?
- So richten Sie den Radarturm in Submarine 2 aus