
Heim >Technologie-Peripheriegeräte >KI >Nach 750.000 Runden Einzelkampf zwischen großen Modellen gewann GPT-4 die Meisterschaft und Llama 3 belegte den fünften Platz
Nach 750.000 Runden Einzelkampf zwischen großen Modellen gewann GPT-4 die Meisterschaft und Llama 3 belegte den fünften Platz

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-04-23 15:28:01815Durchsuche
Zu Llama 3 gibt es neue Testergebnisse -
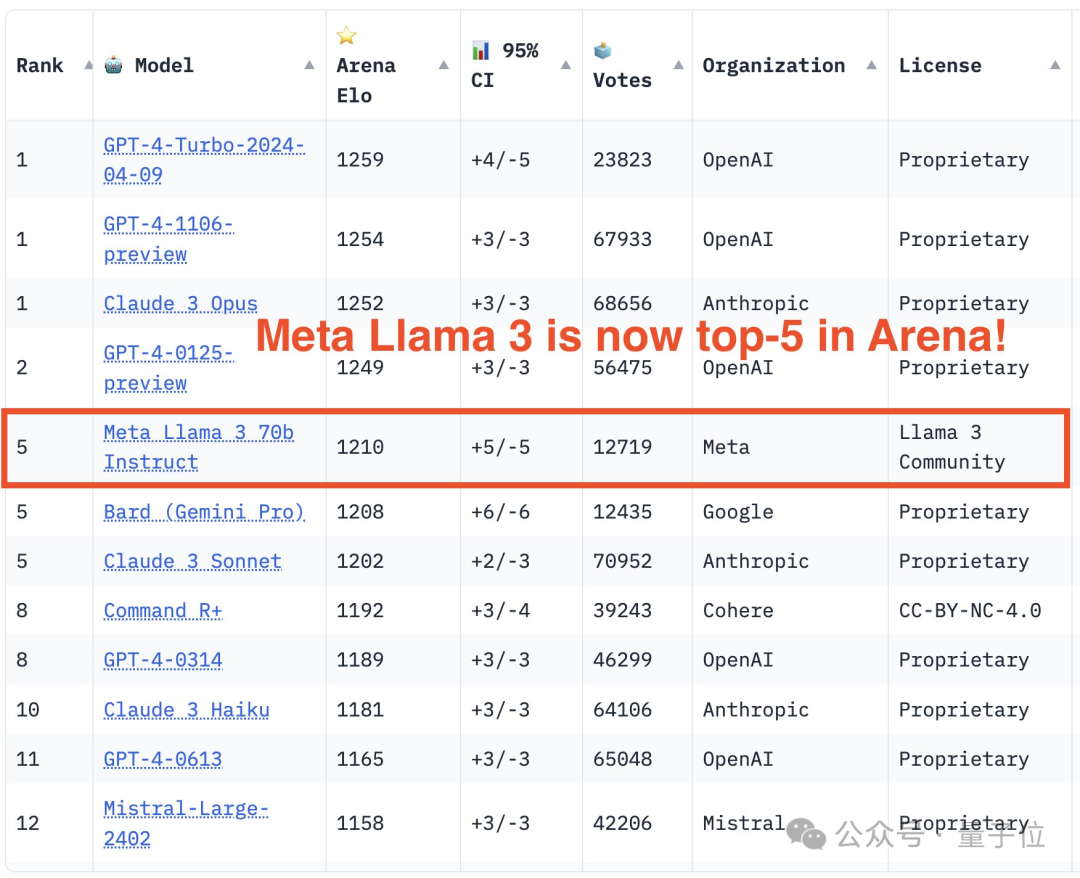
Die große Modellbewertungs-Community LMSYS hat eine große Modell-Rangliste veröffentlicht, Llama 3 belegte den fünften Platz und belegte mit GPT-4 den ersten Platz in der englischen Kategorie.
 Bilder
Bilder
Im Gegensatz zu anderen Benchmarks basiert diese Liste auf Modell-Eins-gegen-Eins-Kämpfen, und die Bewerter aus dem gesamten Netzwerk machen ihre eigenen Vorschläge und Bewertungen.
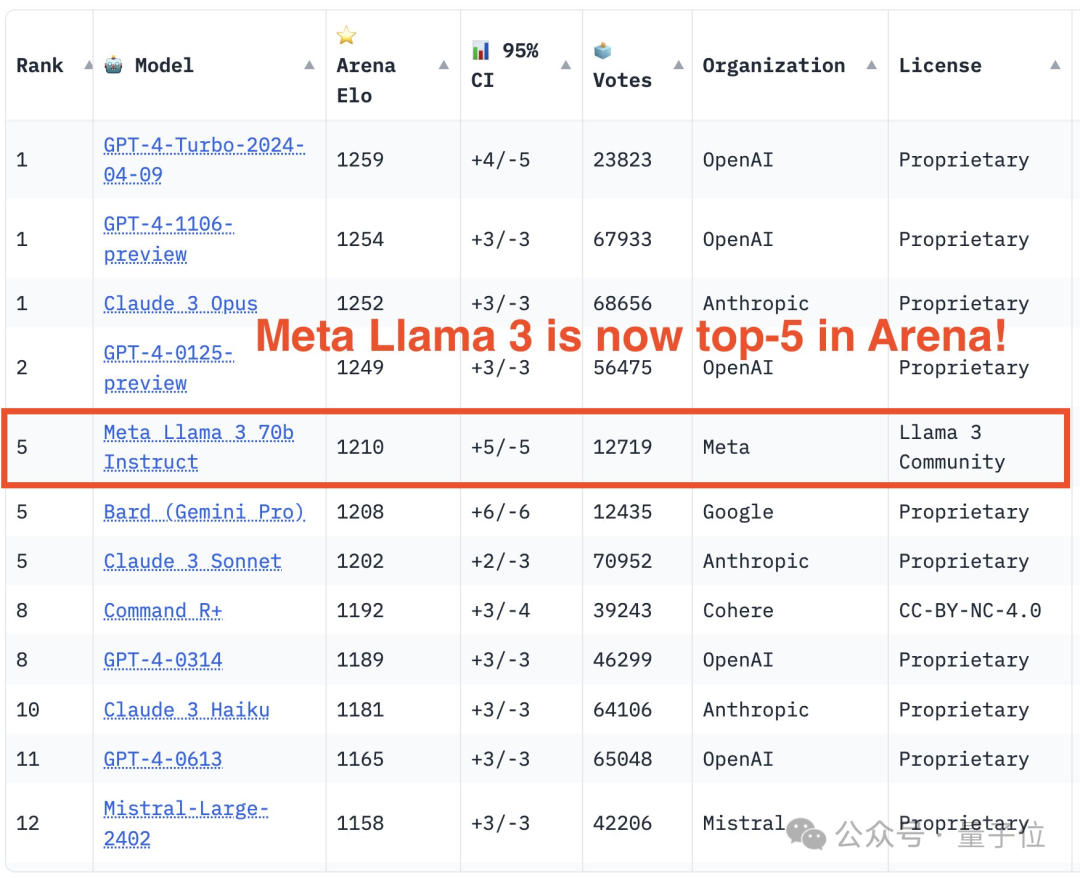
Am Ende belegte Llama 3 den fünften Platz auf der Liste, gefolgt von drei verschiedenen Versionen von GPT-4 und Claude 3 Super Cup Opus.
In der englischen Einzelliste überholte Llama 3 Claude und punktgleich mit GPT-4.
LeCun, Metas leitender Wissenschaftler, freute sich sehr über dieses Ergebnis, twitterte den Tweet erneut und hinterließ ein „Schön“.
 Bilder
Bilder
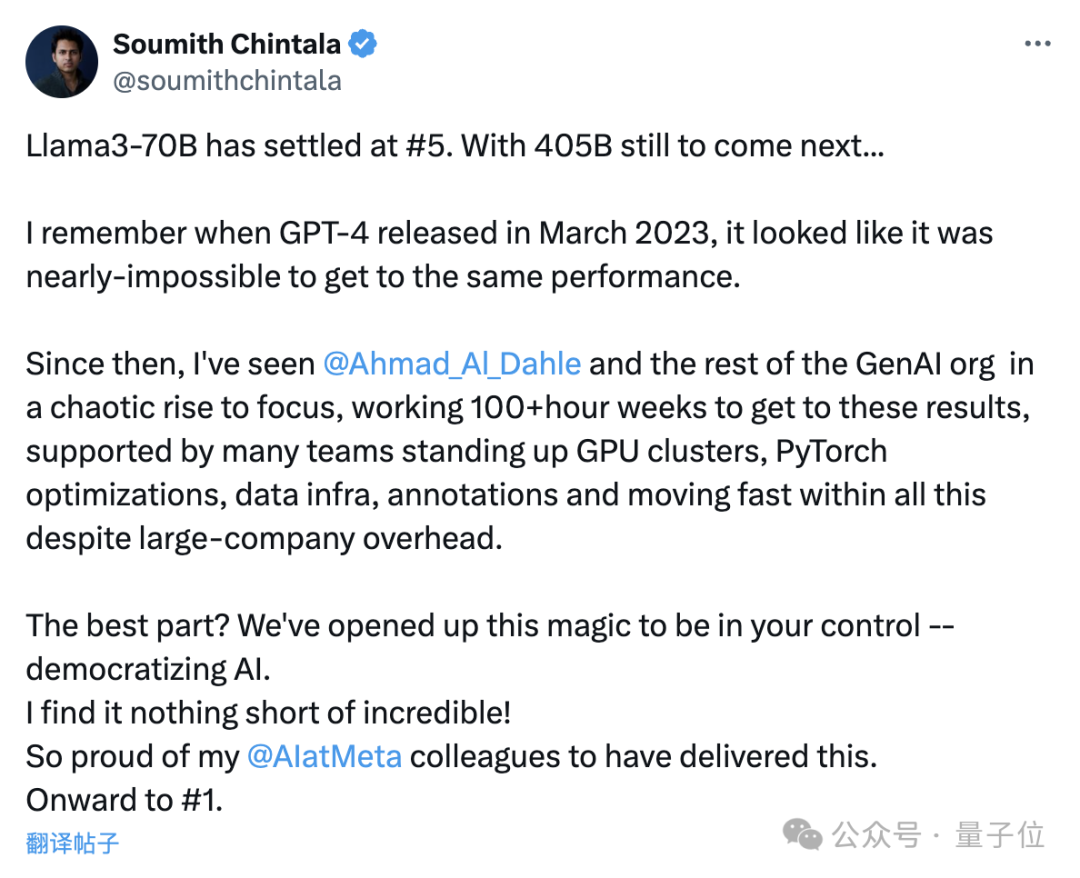
Soumith Chintala, der Vater von PyTorch, äußerte sich ebenfalls begeistert, dass solche Ergebnisse unglaublich seien und er stolz auf Meta sei.
Die 400B-Version von Llama 3 ist noch nicht erschienen und sie hat den fünften Platz erreicht, indem sie sich nur auf 70B-Parameter verlassen hat ...
Ich erinnere mich noch daran, als GPT-4 im März letzten Jahres veröffentlicht wurde, war das fast unmöglich die gleiche Leistung erzielen.
…
Die Popularisierung von KI ist jetzt wirklich unglaublich und ich bin sehr stolz auf meine Kollegen bei Meta AI, die diesen Erfolg erzielt haben.
 Bilder
Bilder
Welche konkreten Ergebnisse zeigt diese Liste?
Fast 90 Modelle traten in 750.000 Runden gegeneinander an
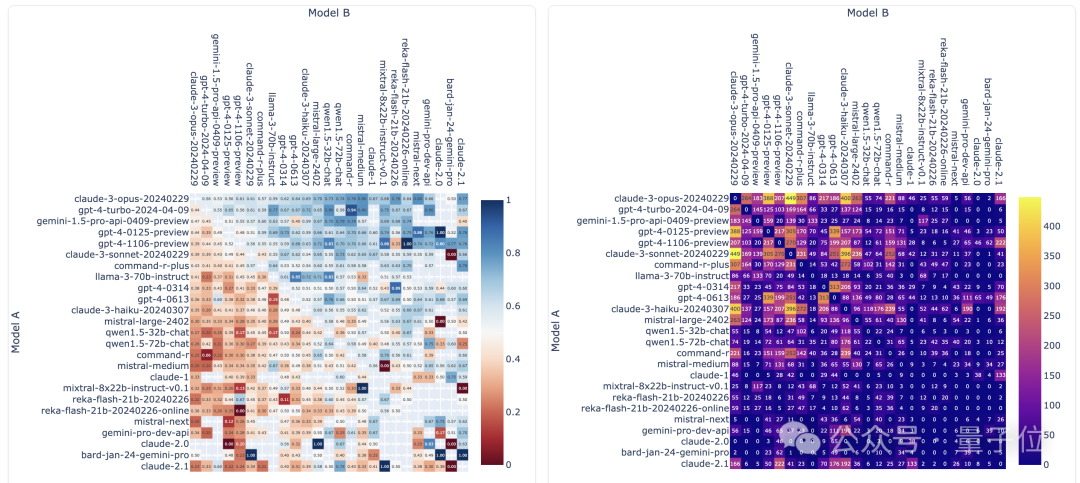
Seit der Veröffentlichung der neuesten Liste hat LMSYS fast 750.000 Einzelkampfergebnisse großer Modelle gesammelt, an denen 89 Modelle beteiligt waren.
Davon hat Llama 3 12.700 Mal teilgenommen, und GPT-4 hat mehrere verschiedene Versionen, wobei die meisten 68.000 Mal teilgenommen haben.
 Bild
Bild
Das Bild unten zeigt die Anzahl der Wettbewerbe und Gewinnquoten einiger beliebter Modelle. Keiner der beiden Indikatoren im Bild zählt die Anzahl der Ziehungen.
 Bilder
Bilder
In Bezug auf die Liste ist LMSYS in eine allgemeine Liste und mehrere Unterlisten unterteilt, die an erster Stelle stehen, gleichauf mit der früheren 1106-Version, und Claude 3 Super Large Cup Opus.
Eine andere Version (0125) von GPT-4 belegt den zweiten Platz, dicht gefolgt von Llama 3.
Aber was noch interessanter ist, ist, dass die neuere Version 0125 nicht so gut funktioniert wie die ältere Version 1106.
 Bilder
Bilder
In der englischen Single-Liste lagen die Ergebnisse von Llama 3 direkt mit den beiden GPT-4 zusammen und übertrafen sogar die 0125-Version.
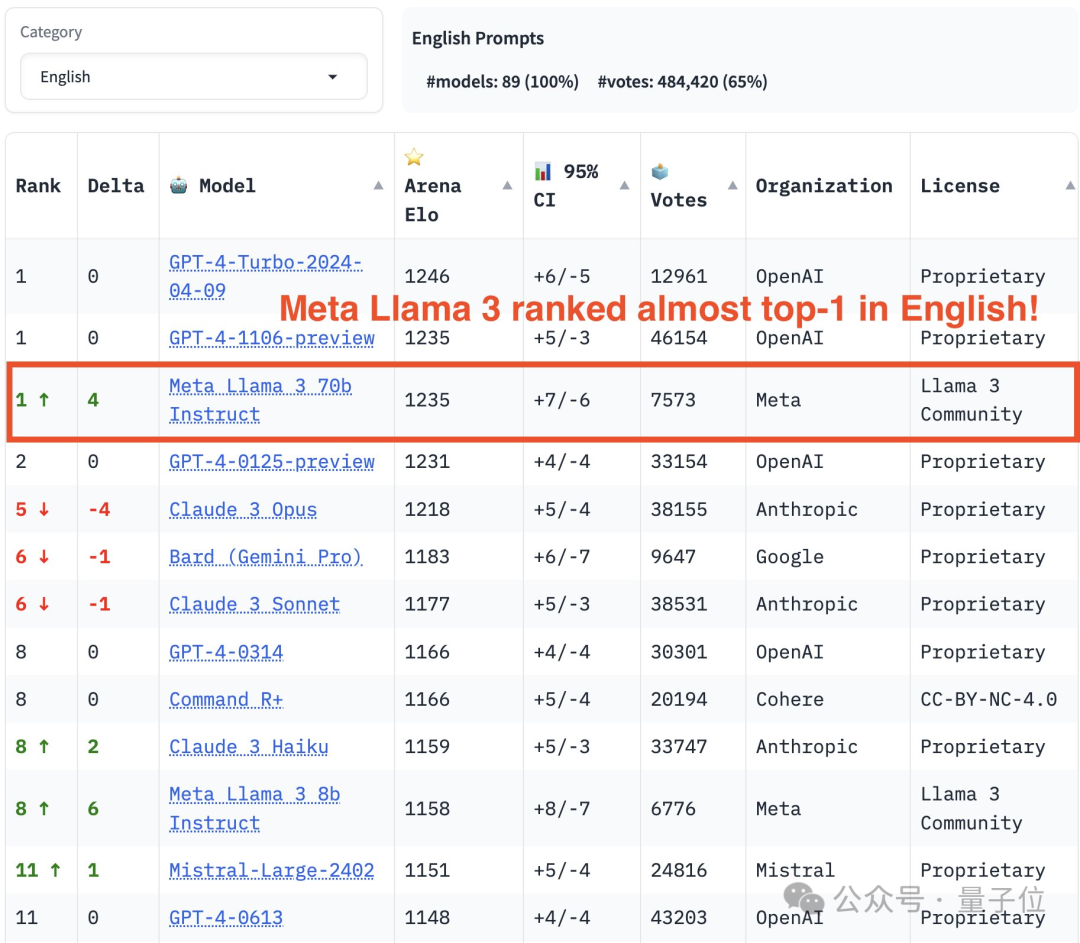 Bilder
Bilder
Der erste Platz in der Rangliste der Chinesischkenntnisse teilen sich Claude 3 Opus und GPT-4-1106, während Llama 3 außerhalb des 20. Platzes liegt.
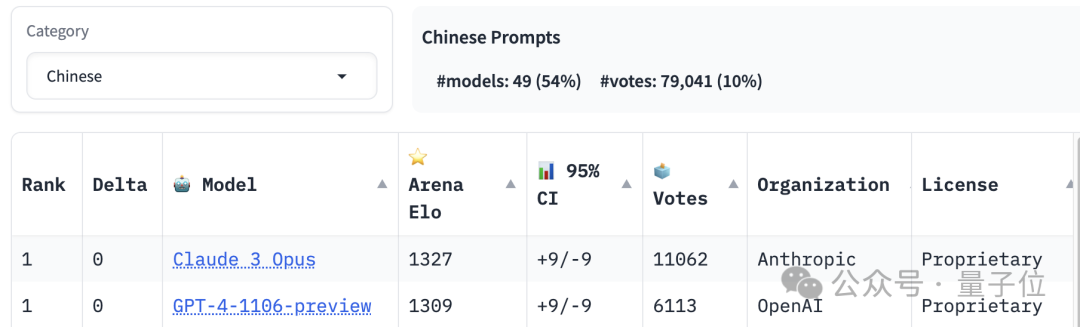 Bilder
Bilder
Zusätzlich zu den Sprachkenntnissen legt die Liste auch Ranglisten für Langtext- und Programmierfähigkeiten fest, und auch Llama 3 gehört zu den Besten.
Aber was sind die spezifischen „Spielregeln“ von LMSYS?
Ein großer Modelltest, an dem jeder teilnehmen kann
Dies ist ein großer Modelltest, an dem jeder teilnehmen kann. Über die Fragen und Bewertungskriterien entscheiden die Teilnehmer selbst.
Der spezifische „Wettkampf“-Prozess ist in zwei Modi unterteilt: Kampf und Seite an Seite.
 Bilder
Bilder
Im Kampfmodus ruft das System nach Eingabe der Frage auf der Testoberfläche zufällig zwei Modelle in der Bibliothek auf, und der Tester weiß nicht, wen das System ausgewählt hat, sondern nur „Modell“. angezeigt in der Schnittstelle A“ und „Modell B“.
Nachdem das Modell die Antwort ausgegeben hat, muss der Bewerter entscheiden, welches besser oder unentschieden ist. Wenn die Leistung des Modells nicht den Erwartungen entspricht, gibt es natürlich entsprechende Optionen.
Erst nachdem eine Auswahl getroffen wurde, wird die Identität des Models bekannt gegeben.
Side-by-Side ist, wo der Benutzer das angegebene Modell für PK auswählt. Der Rest des Testvorgangs ist der gleiche wie im Kampfmodus.
Allerdings werden nur die Abstimmungsergebnisse im anonymen Modus des Kampfes gezählt. und das Model ist während des Gesprächs möglicherweise nicht vorsichtig. Wenn Sie Ihre Identität preisgeben, werden die Ergebnisse ungültig.
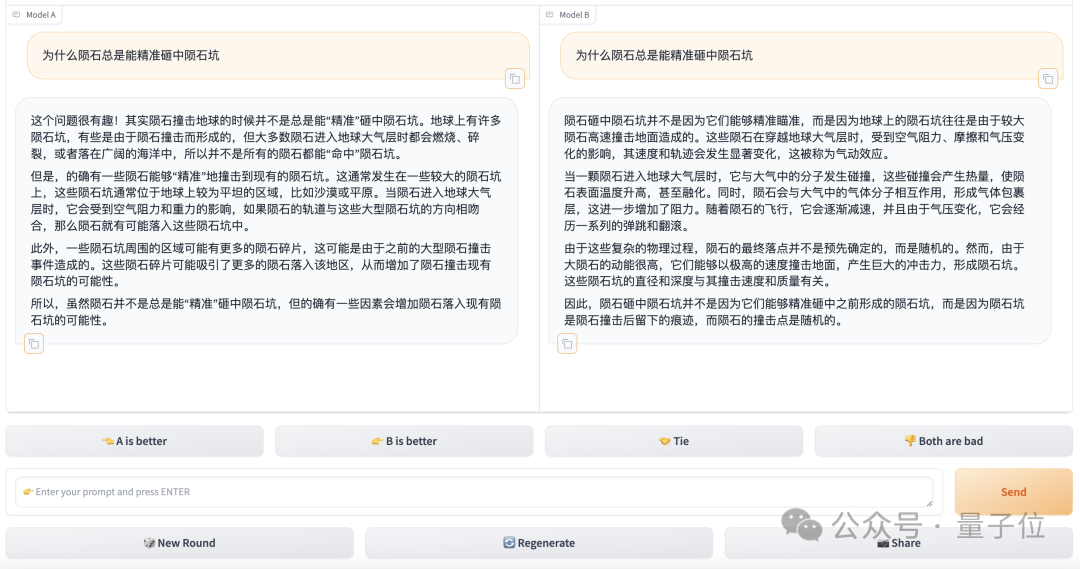 Bilder
Bilder
Entsprechend der Win-Rate jedes Modells gegenüber anderen Modellen kann ein solches Bild gezeichnet werden:
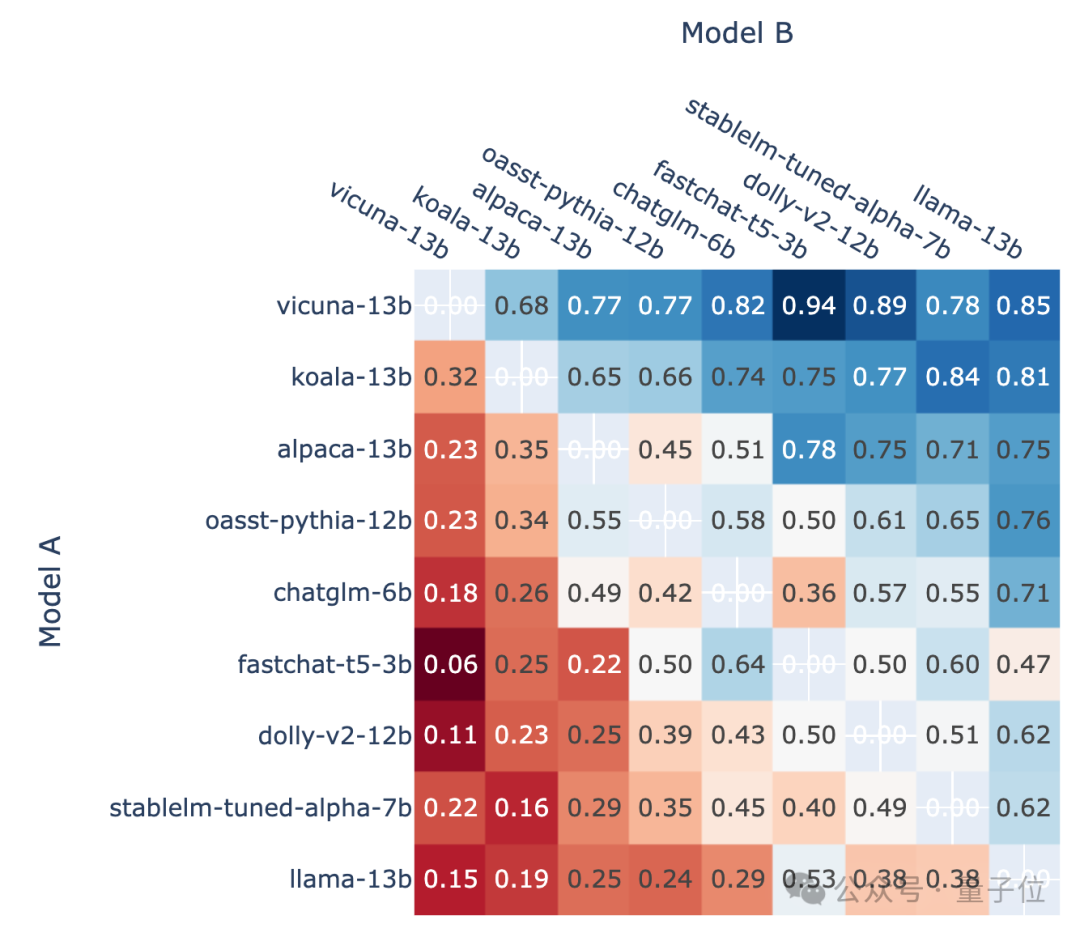 Bilder
Bilder
△Schematisches Diagramm, frühere Version
Und die endgültige Rangliste verwendet Win Die Bewertungsdaten werden über das Elo-Bewertungssystem in Punkte umgewandelt.
Das Elo-Bewertungssystem ist eine Methode zur Berechnung des relativen Fähigkeitsniveaus von Spielern, die vom amerikanischen Physikprofessor Arpad Elo entwickelt wurde.
Speziell für LMSYS werden unter den Anfangsbedingungen die Bewertungen (R) aller Modelle auf 1000 gesetzt und dann die erwartete Gewinnquote (E) basierend auf einer solchen Formel berechnet.
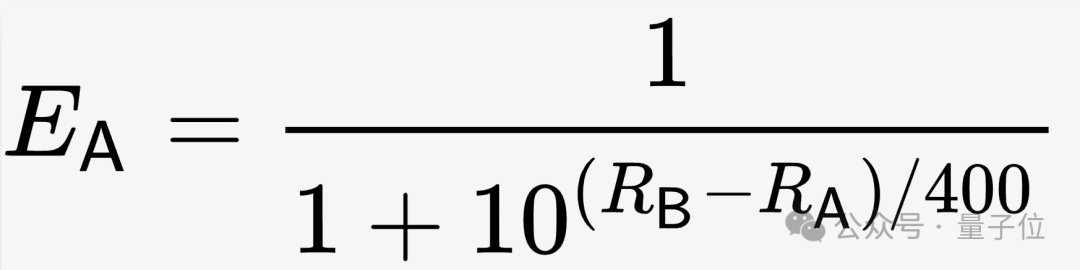 Bilder
Bilder
Im weiteren Verlauf des Tests wird die Punktzahl entsprechend der tatsächlichen Punktzahl überarbeitet (S hat drei Werte: 1, 0 und 0,5, entsprechend den drei Situationen Gewinnen und Verlieren). bzw. Zeichnen.
Der Korrekturalgorithmus ist in der folgenden Formel dargestellt, wobei K der Koeffizient ist, der vom Tester entsprechend der tatsächlichen Situation angepasst werden muss.
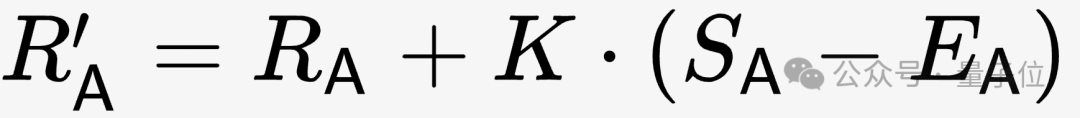 Bilder
Bilder
Nachdem schließlich alle gültigen Daten in die Berechnung einbezogen wurden, wird der Elo-Score des Modells ermittelt.
Während des eigentlichen Betriebs stellte das LMSYS-Team jedoch fest, dass die Stabilität dieses Algorithmus unzureichend war, und verwendete daher statistische Methoden, um ihn zu korrigieren.
Sie verwendeten die Bootstrap-Methode für wiederholte Stichproben, erzielten stabilere Ergebnisse und schätzten das Konfidenzintervall.
Der endgültige überarbeitete Elo-Score ist die Grundlage für die Rangfolge in der Liste geworden.
One More Thing
Llama 3 kann bereits auf der großen Modellinferenzplattform Groq (nicht Musks Grok) ausgeführt werden.
Das größte Highlight dieser Plattform ist ihre „Geschwindigkeit“. Bisher wurde mit dem Mixtral-Modell eine Geschwindigkeit von fast 500 Token pro Sekunde erreicht.
Es ist auch ziemlich schnell, wenn Llama 3 ausgeführt wird. Laut aktuellem Test kann die 70B-Version etwa 300 Token pro Sekunde ausführen, und die 8B-Version liegt bei fast 800.
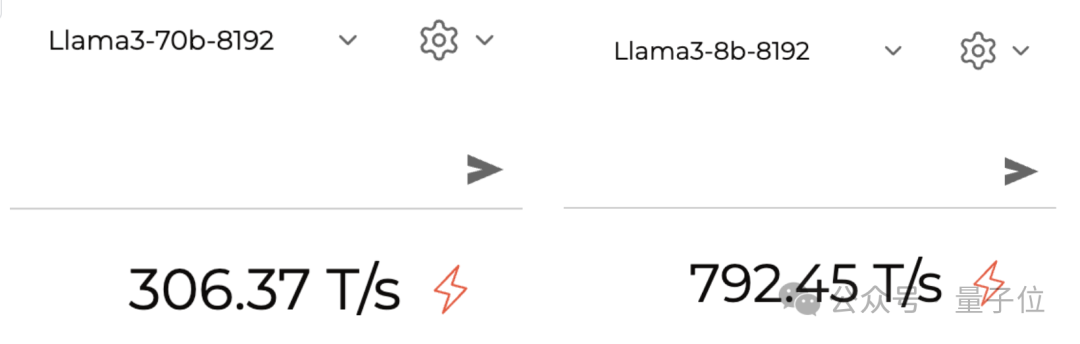 Bilder
Bilder
Referenzlink:
[1]https://lmsys.org/blog/2023-05-03-arena/
[2]https://chat.lmsys.org/?leaderboard
[3]https://twitter.com/lmsysorg/status/1782483699449332144
Das obige ist der detaillierte Inhalt vonNach 750.000 Runden Einzelkampf zwischen großen Modellen gewann GPT-4 die Meisterschaft und Llama 3 belegte den fünften Platz. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Welche zwei Möglichkeiten gibt es, die Blasensortierung zu schreiben? Verwenden Sie die Blasensortierung, um 10 Zahlen anzuordnen.
- Befehl zum Anzeigen der Linux-Version
- So legen Sie die Zeilenhöhe im Bootstrap fest
- 8 Vorlagen für Bootstrap-Unternehmenswebsites (Quellcode kostenloser Download)
- So überprüfen Sie die Version von MySQL