
Heim >Technologie-Peripheriegeräte >KI >Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-04-23 13:20:21990Durchsuche
Im Vordergrund geschrieben
Projektlink: https://nianticlabs.github.io/mickey/
Anhand zweier Bilder kann die Kameraposition zwischen ihnen geschätzt werden, indem die Korrespondenz zwischen den Bildern hergestellt wird. Normalerweise handelt es sich bei diesen Entsprechungen um 2D-zu-2D-Entsprechungen, und unsere geschätzten Posen sind maßstabsunabhängig. Einige Anwendungen, wie z. B. Augmented Reality jederzeit und überall, erfordern eine Posenschätzung von Skalenmetriken und sind daher auf externe Tiefenschätzer angewiesen, um die Skalierung wiederherzustellen.
In diesem Artikel wird MicKey vorgestellt, ein Schlüsselpunkt-Matching-Prozess, der metrische Korrespondenzen im dreidimensionalen Kameraraum vorhersagen kann. Durch das Erlernen des 3D-Koordinatenabgleichs zwischen Bildern können wir ohne Tiefentest auf die metrische relative Pose schließen. Während des Trainings sind auch keine Tiefentests, Szenenrekonstruktionen oder Bildüberlappungsinformationen erforderlich. MicKey wird nur durch Bildpaare und ihre relativen Posen überwacht. MicKey erreicht Spitzenleistungen bei kartenfreien Relokalisierungs-Benchmarks und erfordert gleichzeitig weniger Überwachung als andere konkurrierende Methoden.
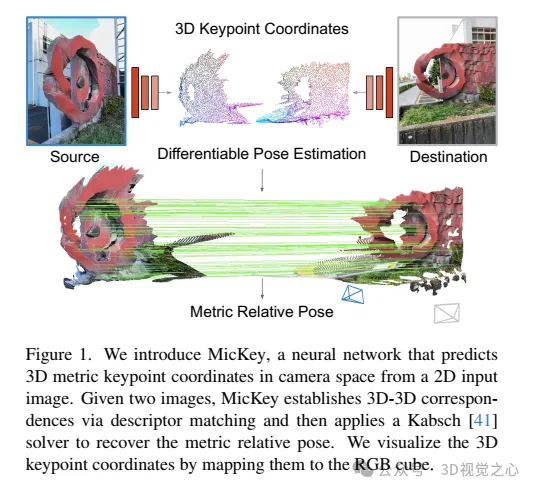
"Metric+Keypoints (MicKey) ist ein Feature-Erkennungsprozess, der zwei Probleme löst. Erstens regressiert MicKey die Schlüsselpunktpositionen im Kameraraum, was die Herstellung metrischer Korrespondenzen durch Deskriptorabgleich ermöglicht. Von Metriken In der Korrespondenz ist die Metrik relativ Die Pose kann wiederhergestellt werden, wie in Abbildung 1 dargestellt. Zweitens lernt MicKey durch die Verwendung der differenzierbaren Posenoptimierung für das End-to-End-Training nur Bildpaare und ihre wahren relativen Posen ohne Aufsicht während des Trainingsprozesses Tiefe der Schlüsselpunkte implizit und nur für die genau gefundenen Merkmalsbereiche. Unser Trainingsprozess ist robust gegenüber Bildpaaren mit unbekannter visueller Überlappung, sodass die durch SFM erhaltenen Informationen (z. B. Bildüberlappung) nicht erforderlich sind. Diese schwache Überwachung macht MicKey sehr zugänglich attraktiv, weil für das Training auf neuen Domänen außer der Pose keine zusätzlichen Informationen erforderlich sind.“ MicKey bietet eine zuverlässige skalenmetrische Posenschätzung selbst bei extremen Betrachtungswinkeländerungen, unterstützt durch Tiefenvorhersage, die speziell auf die Übereinstimmung spärlicher Merkmale ausgerichtet ist. Die durch diese Genauigkeit unterstützte Deformationsanpassung bei extremen Blickwinkeländerungen macht MicKey ideal für die Unterstützung der Tiefenschätzung, die für die Tiefenschätzungsanpassung erforderlich ist, die durch Tiefenvorhersage speziell für die Zuordnung spärlicher Merkmale unterstützt wird.
Die Hauptbeiträge sind wie folgt:
MicKey ist ein neuronales Netzwerk, das Schlüsselpunkte aus einem einzelnen Bild vorhersagen und beschreiben kann. Solche Deskriptoren können die Schätzung metrischer relativer Posen zwischen Bildern ermöglichen.
Diese Trainingsstrategie erfordert nur die Überwachung der relativen Pose, keine Tiefenmessung und keine Kenntnisse über die Überlappung von Bildpaaren.
Einführung in MicKeyMicKey sagt die dreidimensionalen Koordinaten von Schlüsselpunkten im Kameraraum voraus. Das Netzwerk sagt auch Schlüsselpunktauswahlwahrscheinlichkeiten (Schlüsselpunktverteilung) und Deskriptoren voraus, die die Übereinstimmungswahrscheinlichkeit steuern (Übereinstimmungsverteilung). Durch die Kombination dieser beiden Verteilungen erhalten wir die Wahrscheinlichkeit, dass zwei Schlüsselpunkte zu entsprechenden Punkten werden, und optimieren das Netzwerk, um die Wahrscheinlichkeit zu erhöhen, dass entsprechende Punkte angezeigt werden. In einer differenzierbaren RANSAC-Schleife werden mehrere relative Posenhypothesen generiert und ihre Verluste relativ zur wahren Transformation berechnet. Generieren Sie durch REINFORCE Farbverläufe, um entsprechende Wahrscheinlichkeiten zu trainieren. Da unser Posenlöser und unsere Verlustfunktion differenzierbar sind, liefert die Backpropagation auch ein direktes Signal für das Training von 3D-Schlüsselpunktkoordinaten.
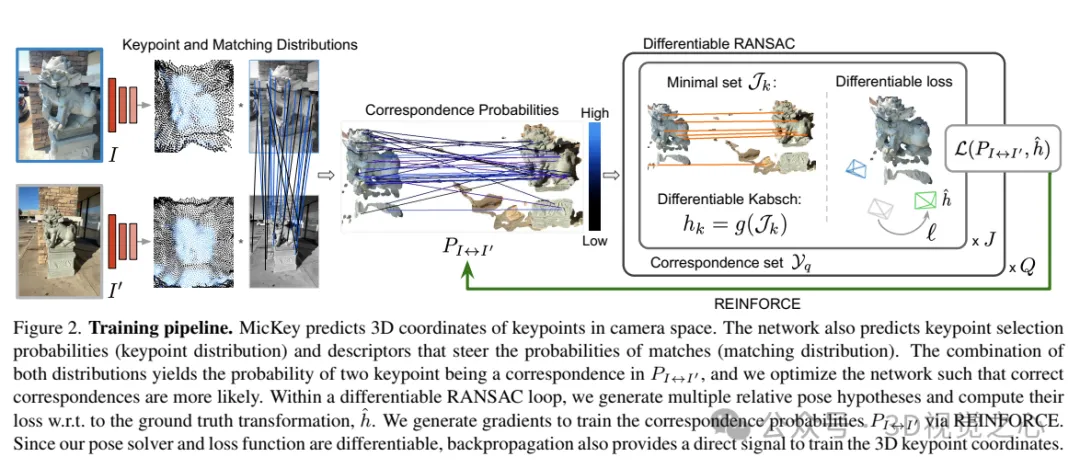
Berechnen Sie anhand zweier Bilder ihre metrischen relativen Posen sowie Schlüsselpunktwerte, Übereinstimmungswahrscheinlichkeiten und Posenkonfidenzen (in Form von Soft-Inlier-Zählungen). Unser Ziel ist es, alle Module zur relativen Posenschätzung durchgängig zu trainieren. Während des Trainingsprozesses gehen wir davon aus, dass es sich bei den Trainingsdaten um die tatsächliche Transformation und K/K' um den kamerainternen Parameter handelt. Das schematische Diagramm des gesamten Systems ist in Abbildung 2 dargestellt.
Um die Koordinaten, Konfidenz und Deskriptoren von 3D-Schlüsselpunkten zu lernen, muss das System vollständig differenzierbar sein. Da jedoch einige Elemente in der Pipeline nicht differenzierbar sind, wie z. B. Keypoint-Sampling oder Inlier-Zählung, wird die Pipeline zur relativen Posenschätzung als probabilistisch neu definiert. Das bedeutet, dass wir die Ausgabe des Netzwerks als Wahrscheinlichkeit einer potenziellen Übereinstimmung behandeln und das Netzwerk während des Trainings seine Ausgabe optimiert, um Wahrscheinlichkeiten zu generieren, sodass die Wahrscheinlichkeit größer ist, dass die richtige Übereinstimmung ausgewählt wird.
2) NetzwerkstrukturMicKey folgt einer Multi-Head-Netzwerkarchitektur mit einem gemeinsamen Encoder, der 3D-Metrikschlüsselpunkte sowie Deskriptoren aus dem Eingabebild ableitet, wie in Abbildung 3 dargestellt.
Encoder. Übernehmen Sie ein vorab trainiertes DINOv2-Modell als Feature-Extraktor und nutzen Sie seine Features direkt ohne weiteres Training oder Feinabstimmung. DINOv2 unterteilt das Eingabebild in Blöcke der Größe 14×14 und stellt für jeden Block einen Merkmalsvektor bereit. Die endgültige Feature-Map F hat eine Auflösung von (1024, w, h), wobei w = W/14 und h = H/14.
Der entscheidende Punkt ist Kopf. Hier werden vier parallele Köpfe definiert, die die Merkmalskarte F verarbeiten und die xy-Offset- (U), Tiefen- (Z), Konfidenz- (C) und Deskriptorkarten (D) berechnen, wobei jeder Eintrag der Karte der Eingabe A 14 entspricht ×14-Block im Bild. MicKey hat die seltene Eigenschaft, Schlüsselpunkte als relative Offsets von einem dünn besetzten regelmäßigen Gitter vorherzusagen. Die absoluten 2D-Koordinaten werden wie folgt ermittelt:
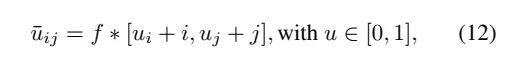
Experimenteller Vergleich
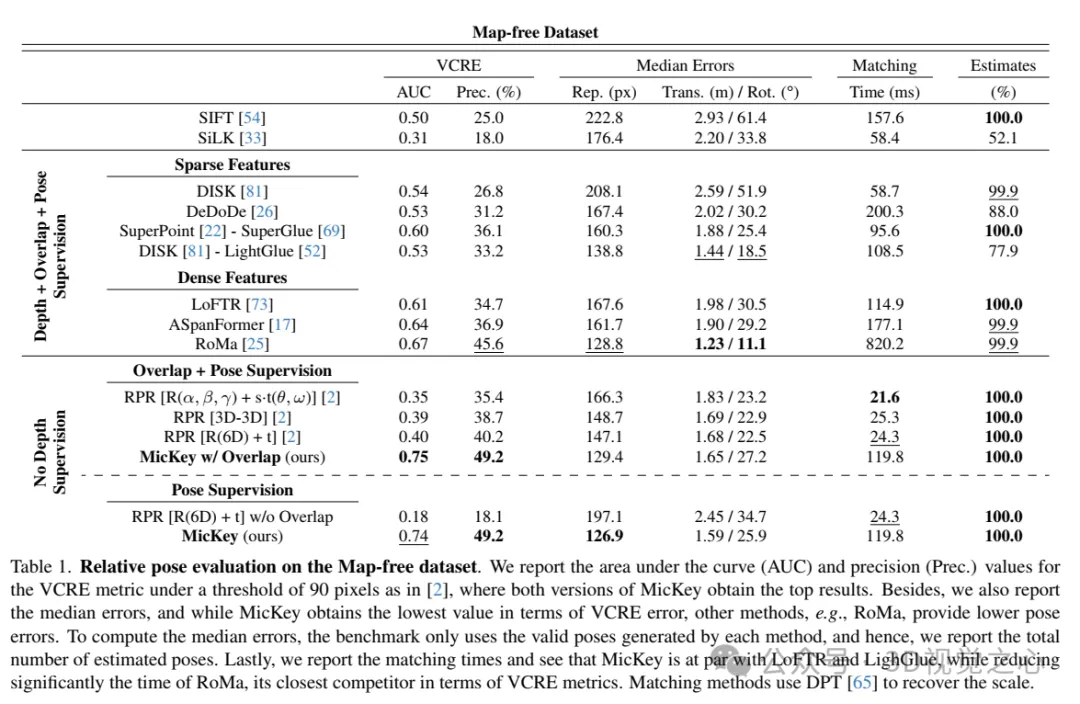
Relative Posenbewertung auf kartenfreien Datensätzen. Es werden Werte für die Fläche unter der Kurve (AUC) und die Präzision (Prec.) für die VCRE-Metrik bei einem 90-Pixel-Schwellenwert angegeben, wobei beide Versionen von MicKey die höchsten Ergebnisse erzielen. Darüber hinaus wird auch der mittlere Fehler gemeldet, und während MicKey den niedrigsten Wert in Bezug auf den VCRE-Fehler erhält, liefern andere Methoden, wie z. B. RoMa, geringere Posenfehler. Zur Berechnung des Medianfehlers verwendet die Basislinie nur gültige Posen, die von jeder Methode generiert wurden. Daher geben wir die geschätzte Gesamtzahl der Posen an. Abschließend werden die Matching-Zeiten gemeldet und festgestellt, dass MicKey mit LoFTR und LighGlue vergleichbar ist, während die Zeiten von RoMa, dem engsten Konkurrenten von MicKey in Bezug auf VCRE-Metriken, deutlich verkürzt werden. Die Matching-Methode verwendet DPT, um den Maßstab wiederherzustellen.
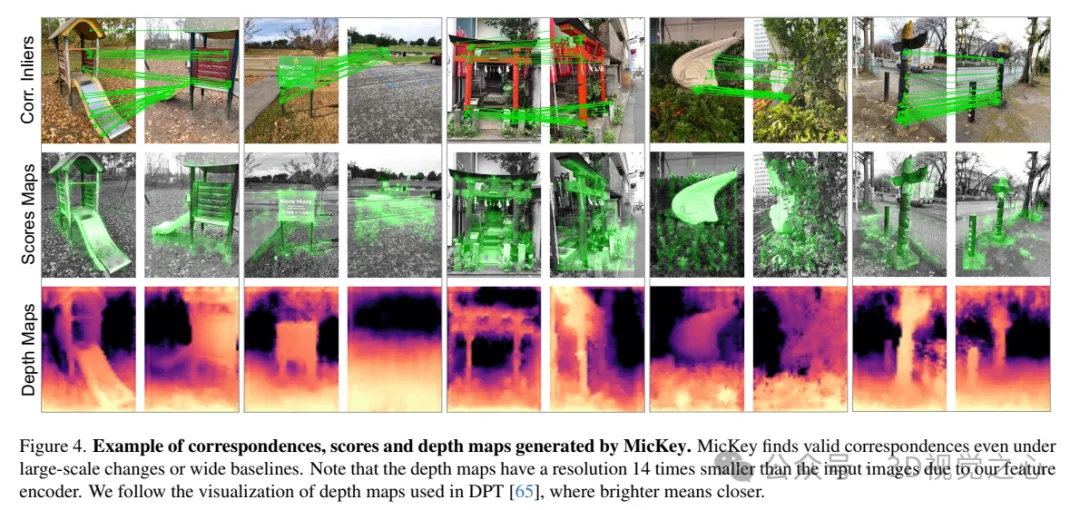
Beispiel für von MicKey generierte Korrespondenzpunkte, Punktestände und Tiefenkarten. MicKey findet effektive Korrespondenzpunkte auch bei großen Änderungen oder breiten Basislinien. Beachten Sie, dass aufgrund unseres Feature-Encoders die Auflösung der Tiefenkarte 14-mal kleiner ist als die des Eingabebildes. Wir folgen der in DPT verwendeten Tiefenkarten-Visualisierungsmethode, bei der hellere Farben geringere Entfernungen darstellen.
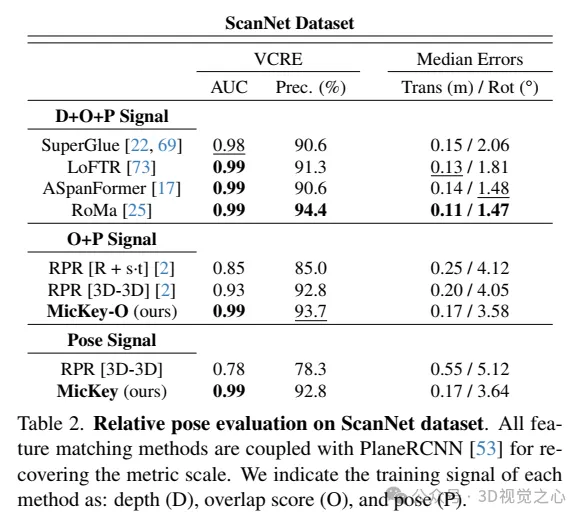
Relative Posenbewertung im ScanNet-Datensatz. Alle Feature-Matching-Methoden werden in Verbindung mit PlaneRCNN verwendet, um metrische Skalen wiederherzustellen. Wir geben die Trainingssignale für jede Methode an: Tiefe (D), Überlappungspunktzahl (O) und Pose (P).


Das obige ist der detaillierte Inhalt vonDas Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!