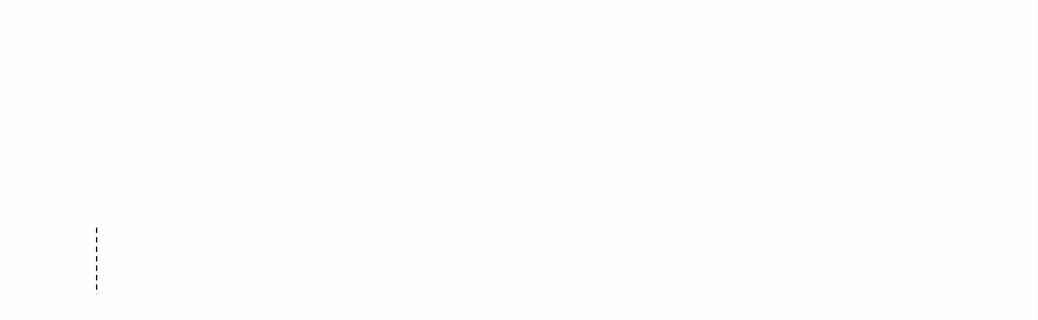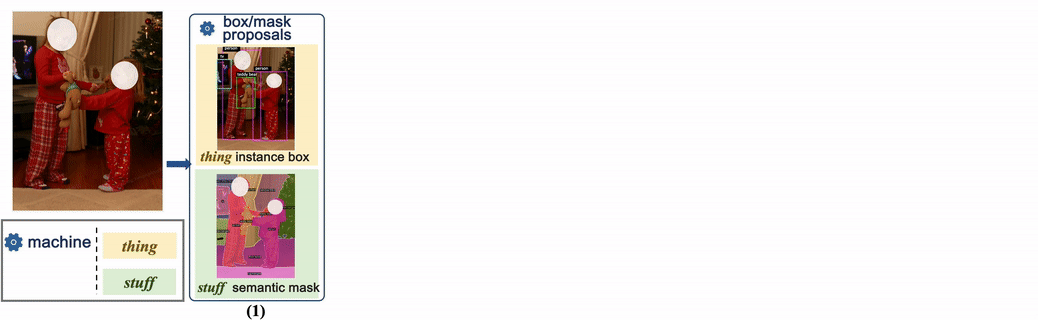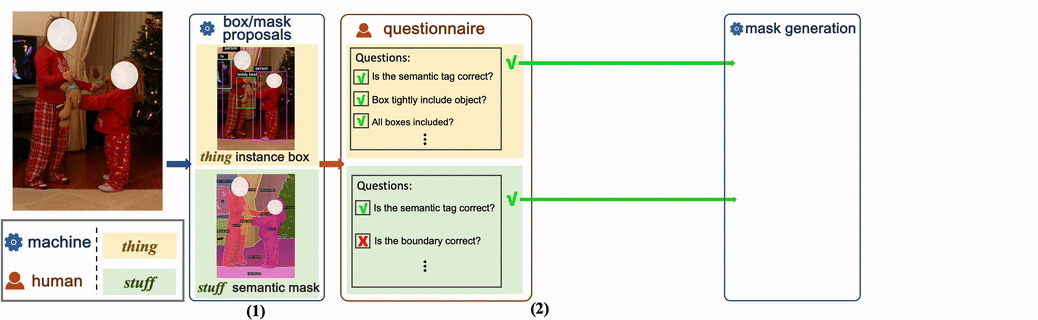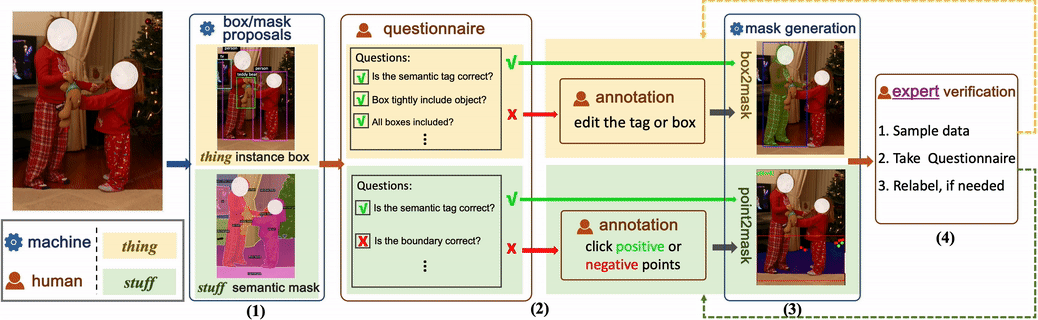Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail-Adresse: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.
Mit der Entwicklung künstlicher Intelligenz haben Sprachmodelle und generative Modelle große Erfolge erzielt, und im Prozess des Modellentwurfs nimmt auch die Anzahl der Parameter des Modells zu. Für feinkörnige Verständnisaufgaben nimmt auch die Anzahl der Modellparameter zu. Es besteht jedoch ein Widerspruch zwischen Skalierung und Genauigkeit in vorhandenen Datensätzen. Beispielsweise sind 99,1 % der Masken im SA-1B-Datensatz maschinengeneriert, es gibt jedoch keine semantischen Bezeichnungen Probleme, und diese Die Größe des Datensatzes ist im Allgemeinen relativ klein. Kürzlich hat ByteDance eine neue Generation feinkörniger Verständnisdatensätze vorgeschlagen. Als Reaktion auf die Designanforderungen moderner Deep-Learning-Modelle wurden insgesamt 383.000 Bilder für die Panoramasegmentierung manuell mit Anmerkungen versehen und schließlich 5,18 Millionen erreicht. Zhang Mask ist der bislang größte Datensatz zum Verständnis der Panoramasegmentierung mit künstlichen Etiketten und heißt COCONut. Dieses Ergebnis wurde für CVPR2024 ausgewählt. 
- Papierlink: https://arxiv.org/abs/2404.08639
- Code- und Datensatzlink: https://xdeng7.github.io/coconut.github.io/
Das Video zeigt die Maskendichte und die semantischen Kategoriestatistiken eines einzelnen Bildes von COCONut. Es ist ersichtlich, dass die Semantik des Datensatzes reichhaltig und die Granularität der Maskensegmentierung gut ist. Der Datensatz unterstützt auch eine Vielzahl von Verständnisaufgaben, wie z. B. Panoramasegmentierung, Instanzsegmentierung, semantische Segmentierung, Objekterkennung, semantisch kontrollierte Generierung und Segmentierung des offenen Vokabulars, wodurch allein durch das Ersetzen des Datensatzes erhebliche Leistungsverbesserungen bei mehreren Aufgaben erzielt werden.
Normalerweise ist nur die manuelle Annotation sehr teuer, was auch ein wichtiger Grund dafür ist, dass die meisten vorhandenen öffentlichen Datensätze nicht skaliert werden können. Es gibt auch einige Datensätze, die vom Modell generierte Beschriftungen direkt verwenden, aber oft verbessern solche generierten Beschriftungen das Training des Modells nicht wesentlich. Dieser Artikel bestätigt dies auch. Daher schlägt dieser Artikel eine neuartige Anmerkungsmethode vor, kombiniert mit einer manuellen halbautomatischen Etikettengenerierung. Dies kann nicht nur die Genauigkeit der Datenanmerkung gewährleisten, sondern auch die Kosten für manuelle Arbeit einsparen und gleichzeitig den Annotationsprozess beschleunigen.
Vergleich der AnmerkungsgenauigkeitDie Forscher verglichen die Anmerkungen von COCONut und COCO auf demselben Bild. Aus dem Vergleich in der folgenden Abbildung können wir erkennen, dass die in diesem Artikel vorgeschlagene Anmerkungsmethode fast die gleiche Genauigkeit wie die rein manuelle Anmerkung mit Photoshop erreicht, die Anmerkungsgeschwindigkeit jedoch um mehr als das Zehnfache erhöht wird.
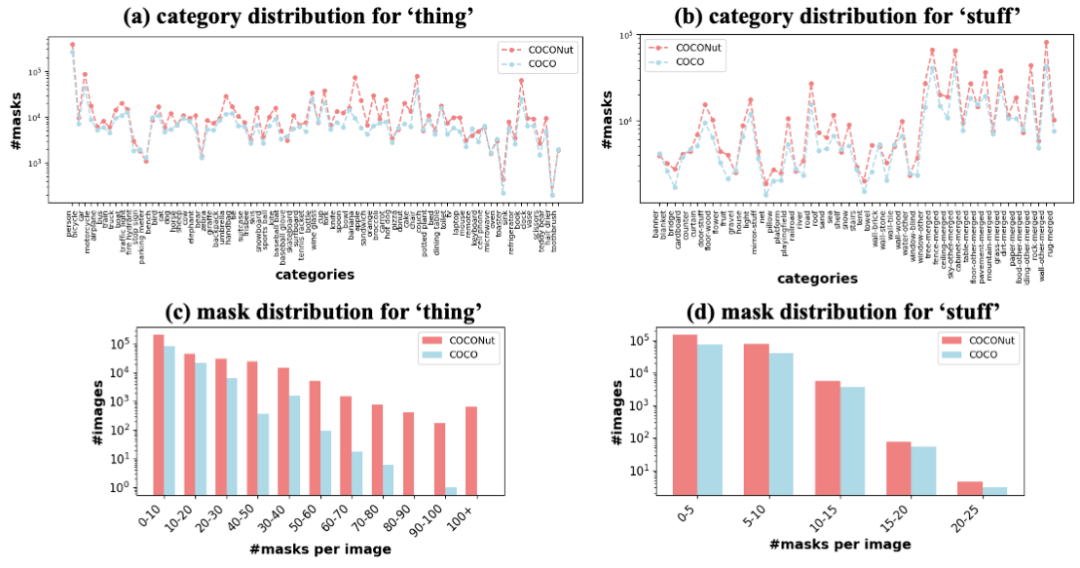
Im Vergleich zum vorhandenen COCO-Datensatz ist die Verteilung jeder Kategorie des Datensatzes relativ ähnlich, aber die Gesamtzahl der Masken in jedem Bild ist größer als COCO Datensatz, insbesondere wenn es eine große Anzahl von Einzelbildern mit mehr als 100 Masken gibt, was zeigt, dass die Annotation von COCONut verfeinert und die granulare Segmentierung dichter ist.
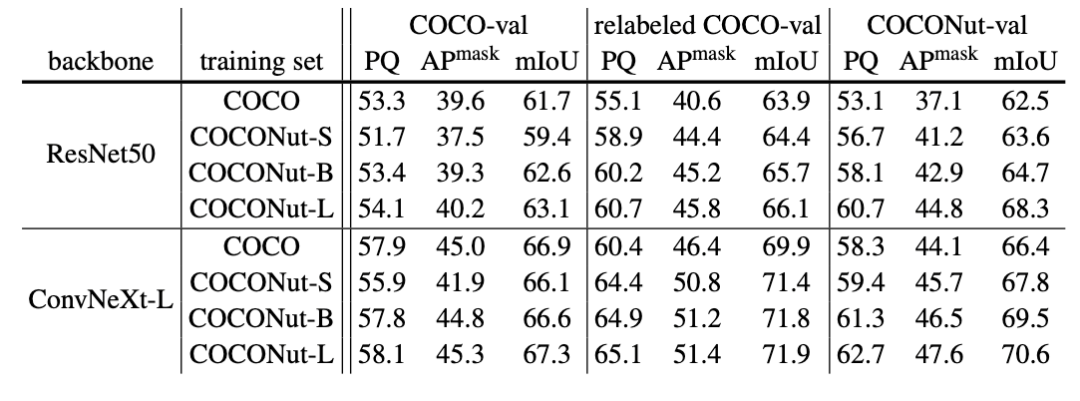
Experimentelle VerifizierungZusätzlich zum Vorschlag eines besseren Trainingssatzes stellten die Forscher auch fest, dass der vorhandene Verifizierungssatz die Verbesserung der Modellleistung nicht gut widerspiegeln kann. Daher schlägt dieser Artikel auch einen anspruchsvolleren Testsatz vor Kann die Verbesserung des Modells widerspiegeln und heißt COCONut-val. Wie aus der folgenden Tabelle ersichtlich ist, kann nur das Ersetzen des Datensatzes und eines Trainingssatzes mit höherer Präzision zu großen Verbesserungen im Modell führen, z. B. zum Erreichen von mehr als 4 Zoll Panorama-Segmentierung. Wenn jedoch die Größe des Trainingssatzes zunimmt, kann festgestellt werden, dass das Testen mit dem vorhandenen Testsatz nicht die Verbesserung des Modells widerspiegelt, während COCONut-val widerspiegeln kann, dass das Modell nach einer Erhöhung des Trainingsumfangs immer noch offensichtliche Verbesserungen aufweist Daten festlegen.
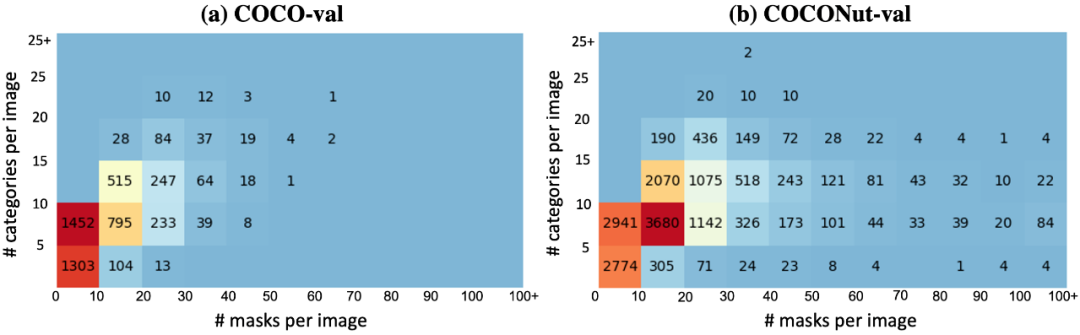
Die folgende Abbildung zeigt einen Vergleich der semantischen Kategorien und der Maskendichte des Verifizierungssatzes. Es ist ersichtlich, dass der neu vorgeschlagene Verifizierungssatz anspruchsvoller ist und die Verbesserung des Modells besser widerspiegeln kann.
Weitere experimentelle Ergebnisse finden Sie im Originalpapier. Das Team stellt den Datensatz und das entsprechende Modell auf der GitHub-Homepage zum öffentlichen Download bereit. ByteDance Intelligent Creation TeamDas Intelligent Creation Team ist das KI- und Multimedia-Technologieteam von ByteDance, das mit Hilfe Computer Vision, Audio- und Videobearbeitung, Spezialeffektverarbeitung und andere technische Bereiche abdeckt des Unternehmens Umfangreiche Geschäftsszenarien, Infrastrukturressourcen und eine Atmosphäre der technischen Zusammenarbeit realisieren einen geschlossenen Kreislauf modernster Algorithmen – technischer Systeme – Produkte mit dem Ziel, branchenführendes Inhaltsverständnis, Inhaltserstellung und Interaktion für verschiedene Unternehmen innerhalb des Unternehmens in verschiedenen Formen bereitzustellen . Erfahrungs- und Verbrauchsmöglichkeiten und Branchenlösungen. Derzeit hat das Team für intelligente Kreation seine technischen Fähigkeiten und Dienste über Volcano Engine, eine Cloud-Service-Plattform von ByteDance, für Unternehmen geöffnet. Weitere Stellen im Zusammenhang mit großen Modellalgorithmen werden eröffnet. Das obige ist der detaillierte Inhalt vonCVPR 2024 |. Byte schlägt eine neue Generation von COCONut-Datensätzen vor, die dichter als die granulare COCO-Segmentierung sind. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!