
Heim >Technologie-Peripheriegeräte >KI >Ant Group und die Zhejiang-Universität veröffentlichen gemeinsam OneKE, ein Open-Source-Framework zur Wissensextraktion großer Modelle
Ant Group und die Zhejiang-Universität veröffentlichen gemeinsam OneKE, ein Open-Source-Framework zur Wissensextraktion großer Modelle

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-04-19 21:20:011517Durchsuche
Kürzlich wurde OneKE, ein großes Modell-Wissensextraktions-Framework, das gemeinsam von der Ant Group und der Zhejiang-Universität entwickelt wurde, als Open Source angekündigt und an die OpenKG-Community für offene Wissensgraphen gespendet.
Knowledge Graph ist eine der Schlüsseltechnologien, um Vertrauenswürdigkeit und Kontrollierbarkeit großer Modelle zu erreichen. Die Wissensextraktion kann beim Aufbau von Domänenwissensgraphen helfen. OneKE setzt sich dafür ein, Forschern und Entwicklern dabei zu helfen, Probleme wie Informationsextraktion, Textdatenstrukturierung und Wissensgraphenerstellung besser zu bewältigen.
Das Extrahieren von Risikoereignissen, Personenentitäten, institutionellen Entitäten usw. über OneKE kann den Ereigniskontext, Ereignisentwicklungstrends und Beziehungen zwischen Entitäten klar darstellen. Das erstellte Diagramm kann großen Modellen dabei helfen, komplexe Überlegungen über Entitäten und Dokumente hinweg zu realisieren. OneKE ist zweisprachig in Chinesisch und Englisch, unterstützt die Open-Source-Frameworks OpenSPG und DeepKE und kann sofort verwendet werden.
Große Sprachmodelle haben die Fähigkeit künstlicher Intelligenzsysteme, Weltwissen zu verarbeiten, erheblich verbessert. Allerdings sind reale Informationen stark fragmentiert und unstrukturiert. Wenn also große Sprachmodelle Informationsextraktionsaufgaben übernehmen, erzielen sie aufgrund des großen Unterschieds zwischen den extrahierten Inhalten und Ausdrücken in natürlicher Sprache immer noch schlechte Ergebnisse Es gibt viele Mehrdeutigkeiten, Polysemie, Metaphern usw., die die Aufgabe der Wissensextraktion vor größere Herausforderungen stellen. Dies führt auch dazu, dass die durch große Sprachmodelle dargestellte generative künstliche Intelligenz immer noch Probleme wie unzureichende Argumentationsfähigkeit, mangelndes Sachwissen und instabile Generierungsergebnisse aufweist, was die Industrialisierung großer Sprachmodelle erheblich behindert.
Das einheitliche Framework zur Wissensextraktion kann die Kosten für die Erstellung von Domänenwissensdiagrammen erheblich senken und verfügt über ein breites Spektrum an Anwendungsszenarien. Dies bedeutet, dass durch die Extraktion strukturierten Wissens aus massiven Daten, die Erstellung hochwertiger Wissensgraphen und die Herstellung logischer Verbindungen zwischen Wissenselementen erklärbare Argumentationsentscheidungen getroffen werden können, und es kann auch zur Verbesserung großer Modelle verwendet werden, um Illusionen zu lindern und die Stabilität zu verbessern. Beschleunigung der Anwendung großer Modelle in vertikalen Feldern.
Im medizinischen Bereich wird das Wissensmanagement der Erfahrung von Ärzten durch Wissensextraktion erreicht und kontrollierbare Hilfsdiagnosen und -behandlungen sowie medizinische Fragen und Antworten erstellt. Im Finanzbereich wird die Wissensextraktionsabteilung für Finanzindikatoren, Risikoereignisse, kausale Zusammenhänge, Industrieketten usw. verwendet, um eine automatische Erstellung von Finanzforschungsberichten, Risikovorhersagen, Industriekettenanalysen usw. zu erreichen. In Szenarien für Regierungsangelegenheiten kann die Kenntnis der Vorschriften für Regierungsangelegenheiten genutzt werden, um die Effizienz und genaue Entscheidungsfindung der Dienste für Regierungsangelegenheiten zu verbessern.
Um die industrielle Implementierung produktionsbasierter künstlicher Intelligenz zu beschleunigen, haben Ant Group und die Zhejiang-Universität ein gemeinsames Wissensgraphenlabor eingerichtet, das sich auf Themen wie die Konstruktion von Wissensgraphen mit großem Modell, wissensgestützte vertrauenswürdige und kontrollierbare Generierungsfunktionen usw. konzentriert Führen Sie eine umfassende Zusammenarbeit durch, um durch gemeinsame technische Forschung ein kontrollierbares Generierungs-Funktionsparadigma mit wechselseitiger Verbesserung großer Sprachmodelle und Wissensgraphen zu etablieren.
Ant Group und die Zhejiang-Universität haben gemeinsam die Fähigkeiten des Ant Bailing-Großmodells im Bereich der Wissensextraktion etabliert und verbessert und OneKE veröffentlicht, ein zweisprachiges Wissensextraktions-Framework für große Modelle in Chinesisch-Englisch, und eine Open-Source-Version basierend auf LLaMA2 Full veröffentlicht -Parameter-Feinabstimmung. Testindikatoren zeigen, dass OneKE bei mehreren vollständig überwachten Entitäts-/Beziehungs-/Ereignisextraktionsaufgaben ohne Stichprobe relativ gute Ergebnisse erzielt hat.
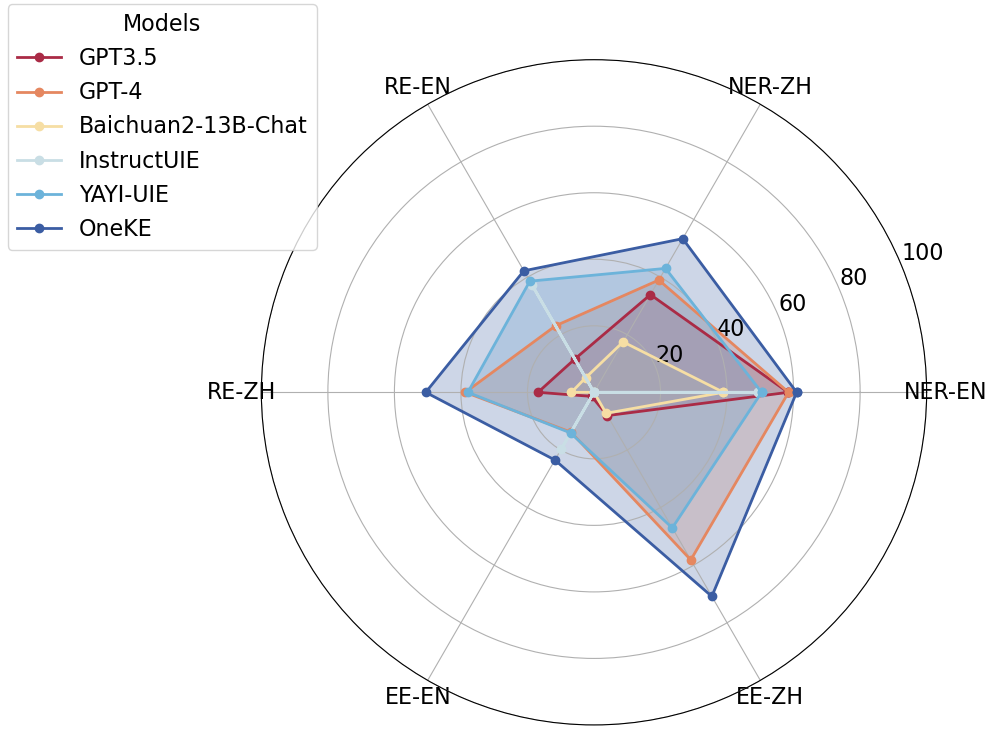
OneKE ist ein hervorragendes zweisprachiges verallgemeinerbares Wissensextraktionstool für Chinesisch. Es hat bei chinesischen NER-Aufgaben zur Erkennung benannter Entitäten, RE-Beziehungsextraktionsaufgaben und EE-Ereignisextraktionsaufgaben relativ gute Ergebnisse erzielt.
Liang Lei, Leiter des Wissensgraphen bei der Ant Group, sagte, dass Ant die Leistung der Wissensextraktion weiterhin optimieren wird, um den kontrollierbaren und vertrauenswürdigen Anforderungen großer Modelle in verschiedenen Szenarien gerecht zu werden. In Zukunft werden wir mit Industriepartnern zusammenarbeiten, um relevante technische Systeme auf verschiedene vertikale Bereiche wie Finanzen, medizinische Versorgung und Regierungsangelegenheiten anzuwenden und die industrielle Umsetzung steuerbarer Erzeugungstechnologie zu fördern, die auf Wissensgraphen und großen Sprachmodellen basiert.
Offizielle OneKE-Homepage: http://oneke.openkg.cn/
OpenSPG GitHub: https://github.com/OpenSPG/openspg
Das obige ist der detaillierte Inhalt vonAnt Group und die Zhejiang-Universität veröffentlichen gemeinsam OneKE, ein Open-Source-Framework zur Wissensextraktion großer Modelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!