
Heim >Technologie-Peripheriegeräte >KI >Wie kann ein Transformator verwendet werden, um die visuellen Merkmale des Lidar-Millimeterwellenradars effektiv zu korrelieren?
Wie kann ein Transformator verwendet werden, um die visuellen Merkmale des Lidar-Millimeterwellenradars effektiv zu korrelieren?

- PHPznach vorne
- 2024-04-19 16:01:24533Durchsuche
Der Autor persönlich versteht
Eine der Grundaufgaben des autonomen Fahrens ist die dreidimensionale Zielerkennung, und viele Methoden werden mittlerweile auf Basis von Multisensor-Fusionsmethoden implementiert. Warum ist also eine Multisensorfusion erforderlich? Ob Lidar- und Kamerafusion oder Millimeterwellenradar- und Kamerafusion, der Hauptzweck besteht darin, die komplementäre Verbindung zwischen Punktwolken und Bildern zu nutzen, um die Genauigkeit der Zielerkennung zu verbessern. Mit der kontinuierlichen Anwendung der Transformer-Architektur im Bereich Computer Vision haben auf Aufmerksamkeitsmechanismen basierende Methoden die Genauigkeit der Fusion zwischen mehreren Sensoren verbessert. Die beiden gemeinsamen Arbeiten basieren auf dieser Architektur und schlagen neuartige Fusionsmethoden vor, um die nützlichen Informationen ihrer jeweiligen Modalitäten besser zu nutzen und eine bessere Fusion zu erreichen.
TransFusion:
Hauptbeitrag
Lidar und Kamera sind zwei wichtige dreidimensionale Zielerkennungssensoren beim autonomen Fahren. Bei der Sensorfusion stehen sie jedoch hauptsächlich vor dem Problem der geringen Erkennungsgenauigkeit, die durch schlechte Bildstreifen verursacht wird Bedingungen. . Die punktbasierte Fusionsmethode besteht darin, Lidar und Kameras durch harte Assoziation zu verschmelzen, was zu einigen Problemen führt: a) Durch einfaches Zusammenfügen von Punktwolken- und Bildmerkmalen wird die Erkennungsleistung bei Vorhandensein von Bildmerkmalen geringer Qualität erheblich beeinträchtigt ;b) Das Finden harter Korrelationen zwischen spärlichen Punktwolken und Bildern verschwendet hochwertige Bildmerkmale und ist schwer auszurichten. Um dieses Problem zu lösen, wird eine Soft-Assoziationsmethode vorgeschlagen. Bei dieser Methode werden Lidar und Kamera als zwei unabhängige Detektoren behandelt, die miteinander kooperieren und die Vorteile der beiden Detektoren voll ausnutzen. Zunächst wird ein herkömmlicher Objektdetektor verwendet, um Objekte zu erkennen und Begrenzungsrahmen zu generieren. Anschließend werden die Begrenzungsrahmen und Punktwolken abgeglichen, um eine Bewertung dafür zu erhalten, welchem Begrenzungsrahmen jeder Punkt zugeordnet ist. Abschließend werden die den Randkästen entsprechenden Bildmerkmale mit den durch die Punktwolke generierten Merkmalen verschmolzen. Mit dieser Methode kann der durch schlechte Bildstreifenbedingungen verursachte Rückgang der Erkennungsgenauigkeit wirksam vermieden werden. Gleichzeitig wird in diesem Artikel TransFusion vorgestellt, ein Fusionsframework für Lidar und Kameras, um das Korrelationsproblem zwischen den beiden Sensoren zu lösen. Die Hauptbeiträge sind wie folgt:
Schlagen Sie ein transformatorbasiertes 3D-Erkennungsfusionsmodell von Lidar und Kamera vor, das eine hervorragende Robustheit gegenüber schlechter Bildqualität und Sensorfehlausrichtung zeigt;- Führt mehrere Methoden zur Objektabfrage ein. Einfache, aber effektive Anpassungen zur Verbesserung die Qualität der anfänglichen Begrenzungsrahmenvorhersagen für die Bildfusion und ein bildgesteuertes Abfrageinitialisierungsmodul, das für den Umgang mit Objekten entwickelt wurde, die in Punktwolken schwer zu erkennen sind
- implementiert nicht nur eine erweiterte 3D-Erkennung in der Leistung von nuScenes und erweitert das Modell auch um dreidimensionale Trackingaufgaben erfolgreich gelöst und gute Ergebnisse erzielt.
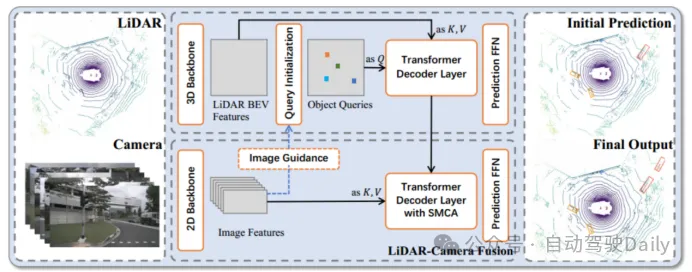 Abbildung 1 Das Gesamtgerüst von TransFusion
Abbildung 1 Das Gesamtgerüst von TransFusion
Um die oben genannten Bildeintragsunterschiede und Korrelationsprobleme zwischen verschiedenen Sensoren zu lösen, wird ein Transformer-basiertes Fusionsgerüst – TransFusion – vorgeschlagen . Das Modell basiert auf standardmäßigen 3D- und 2D-Backbone-Netzwerken, um LiDAR BEV-Funktionen und Bildfunktionen zu extrahieren, und besteht dann aus zwei Schichten von Transformer-Decodern: Der Decoder der ersten Ebene verwendet spärliche Punktwolken, um anfängliche Begrenzungsrahmen zu generieren; Layer Die Objektabfrage wird mit der Bildmerkmalsabfrage kombiniert, um bessere Erkennungsergebnisse zu erzielen. Der räumliche Modulationsaufmerksamkeitsmechanismus (SMCA) und die bildgesteuerte Abfragestrategie werden ebenfalls eingeführt, um die Erkennungsgenauigkeit zu verbessern. Durch die Erkennung dieses Modells können bessere Bildmerkmale und Erkennungsgenauigkeit erzielt werden.
Abfrageinitialisierung
Wenn ein Objekt nur eine kleine Anzahl von LIDAR-Punkten enthält, kann nur die gleiche Anzahl von Bildmerkmalen erhalten werden, wodurch hochwertige Bildsemantikinformationen verschwendet werden . Daher behält dieser Artikel alle Bildmerkmale bei und verwendet den Kreuzaufmerksamkeitsmechanismus und die adaptive Methode in Transformer, um eine Merkmalsfusion durchzuführen, sodass das Netzwerk adaptiv Standort und Informationen aus dem Bild extrahieren kann. Um das Problem der räumlichen Fehlausrichtung von LiDAR-BEV-Merkmalen und Bildmerkmalen, die von verschiedenen Sensoren stammen, zu lindern, wurde ein
Räumlich moduliertes Kreuzaufmerksamkeitsmodul (SMCA)entwickelt, das eine 2D-zirkuläre Gaußsche Kurve um das 2D-Zentrum jeder Abfrageprojektion weiterleitet Maskengewichte erregen Aufmerksamkeit.
Bildgesteuerte Abfrageinitialisierung (Bildgesteuerte Abfrageinitialisierung)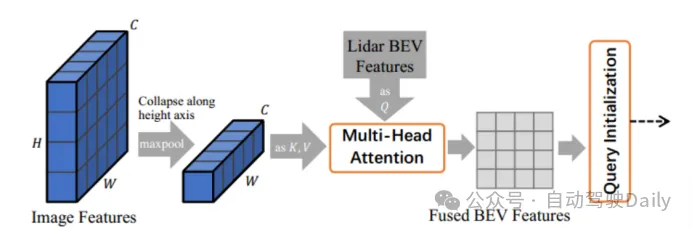 Abbildung 2 Bildgesteuertes Abfragemodul
Abbildung 2 Bildgesteuertes Abfragemodul
Dieses Modul verwendet LIDAR- und Bildinformationen gleichzeitig als Objektabfragen, indem es Bildmerkmale und LIDAR-BEV-Merkmale in das Netzwerk des Cross-Attention-Mechanismus sendet, sie auf die BEV-Ebene projiziert und fusionierte BEV-Merkmale generiert. Wie in Abbildung 2 dargestellt, werden die Multi-View-Bildmerkmale zunächst als Schlüsselwert des Cross-Attention-Mechanismus-Netzwerks entlang der Höhenachse gefaltet, und die Lidar-BEV-Merkmale werden als Abfragen an das Aufmerksamkeitsnetzwerk gesendet, um die fusionierten BEV-Merkmale zu erhalten. Diese werden für die Heatmap-Vorhersage verwendet und mit der reinen LIDAR-Heatmap Ŝ gemittelt, um die endgültige Heatmap Ŝ zur Auswahl und Initialisierung der Zielabfrage zu erhalten. Solche Operationen ermöglichen es dem Modell, Ziele zu erkennen, die in Lidar-Punktwolken schwer zu erkennen sind.
Experimente
Datensätze und Metriken
Der Datensatz nuScenes ist ein umfangreicher Datensatz für autonomes Fahren zur 3D-Erkennung und -Verfolgung, der 700, 150 und 150 Szenen für Training, Validierung und Tests enthält. Jeder Frame enthält eine Lidar-Punktwolke und sechs Kalibrierungsbilder, die ein horizontales 360-Grad-Sichtfeld abdecken. Für die 3D-Erkennung sind die Hauptmetriken die mittlere durchschnittliche Präzision (mAP) und der nuScenes-Erkennungsscore (NDS). mAP wird durch den BEV-Mittelabstand und nicht durch 3D-IoU definiert, und der endgültige mAP wird durch Mittelung der Entfernungsschwellenwerte von 0,5 m, 1 m, 2 m, 4 m für 10 Kategorien berechnet. NDS ist ein umfassendes Maß für mAP und andere Attributmaße, einschließlich Übersetzung, Skalierung, Ausrichtung, Geschwindigkeit und anderer Boxattribute. .
Der Waymo-Datensatz umfasst 798 Szenen für das Training und 202 Szenen für die Validierung. Die offiziellen Indikatoren sind mAP und mAPH (mAP gewichtet nach Kursgenauigkeit). mAP und mAPH werden auf der Grundlage von 3D-IoU-Schwellenwerten definiert, die 0,7 für Fahrzeuge und 0,5 für Fußgänger und Radfahrer betragen. Diese Metriken sind weiter in zwei Schwierigkeitsstufen unterteilt: STUFE 1 für Begrenzungsrahmen mit mehr als 5 LIDAR-Punkten und STUFE 2 für Begrenzungsrahmen mit mindestens einem LIDAR-Punkt. Im Gegensatz zu den 360-Grad-Kameras von nuScenes decken die Kameras von Waymo nur etwa 250 Grad horizontal ab.
Training Verwenden Sie im nuScenes-Datensatz DLA34 als 2D-Backbone-Netzwerk des Bildes und frieren Sie seine Gewichte ein. Stellen Sie die Bildgröße auf 448 × 800 ein. Wählen Sie VoxelNet als 3D-Backbone-Netzwerk des Lidar aus. Der Trainingsprozess ist in zwei Phasen unterteilt: Die erste Phase verwendet nur LiDAR-Daten als Eingabe und trainiert das 3D-Backbone 20 Mal mit dem First-Layer-Decoder und dem FFN-Feedforward-Netzwerk, um anfängliche 3D-Bounding-Box-Vorhersagen zu generieren -Kamera Die Fusions- und bildgeführten Abfrageinitialisierungsmodule werden sechsmal trainiert. Das linke Bild ist die Transformator-Decoder-Schichtarchitektur, die für die anfängliche Bounding-Box-Vorhersage verwendet wird; das rechte Bild ist die Transformator-Decoder-Schichtarchitektur, die für die LiDAR-Kamera-Fusion verwendet wird.
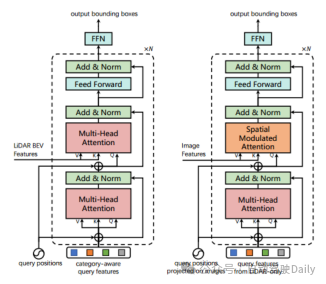
Abbildung 3 Decoder-Layer-Design
Vergleich mit modernsten Methoden
Vergleichen Sie zunächst die Leistung von TransFusion und anderen SOTA-Methoden bei 3D-Objekterkennungsaufgaben. Tabelle 1 unten zeigt die Ergebnisse in der nuScenes-Testsatz Es ist ersichtlich, dass diese Methode zu diesem Zeitpunkt die beste Leistung erzielt hat (mAP beträgt 68,9 %, NDS beträgt 71,7 %). TransFusion-L verwendet zur Erkennung nur Lidar und seine Erkennungsleistung ist deutlich besser als bei früheren Single-Modal-Erkennungsmethoden und übertrifft sogar einige Multi-Modal-Methoden. Dies ist hauptsächlich auf den neuen Assoziationsmechanismus und die Abfrageinitialisierung zurückzuführen. Tabelle 2 zeigt die Ergebnisse von LEVEL 2 MAPH auf dem Waymo-Validierungssatz. Tabelle 1: Vergleich mit der SOTA-Methode im nuScenes-Test Entwickelt, um die Robustheit zu überprüfen. Die drei Fusionsframeworks sind Punkt-für-Punkt-Spleißen und Fusion von Lidar- und Bildmerkmalen (CC), Point Enhancement Fusion Strategy (PA) und TransFusion. Wie in Tabelle 3 gezeigt, führt die TransFusion-Methode durch die Aufteilung des nuScenes-Datensatzes in Tag und Nacht zu einer größeren Leistungsverbesserung bei Nacht. Während des Inferenzprozesses werden die Merkmale des Bildes auf Null gesetzt, um den Effekt zu erzielen, dass mehrere Bilder in jedem Frame zufällig verworfen werden. Wie in Tabelle 4 zu sehen ist, nimmt die Erkennungsleistung ab, wenn einige Bilder während des Inferenzprozesses nicht verfügbar sind deutlich, wobei der mAP von CC und PA um 23,8 % bzw. 17,2 % sank, während TransFusion bei 61,7 % blieb. Der unkalibrierte Sensor wirkt sich auch stark auf die Leistung der 3D-Zielerkennung aus. Die experimentelle Einstellung fügt der Transformationsmatrix von der Kamera zum Lidar zufällig einen Verschiebungsversatz hinzu, wie in Abbildung 4 dargestellt. Wenn die beiden Sensoren um 1 m versetzt sind, beträgt der mAP von TransFusion Es verringerte sich nur um 0,49 %, während der mAP von PA und CC um 2,33 % bzw. 2,85 % abnahm.
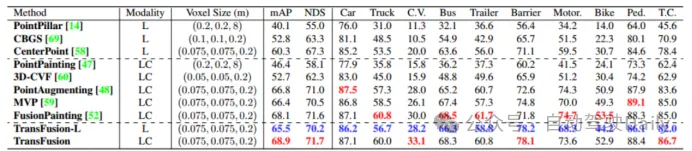
Tabelle 3 Karte bei Tag und Nacht

Tabelle 4 Karte bei unterschiedlicher Anzahl von Bildern
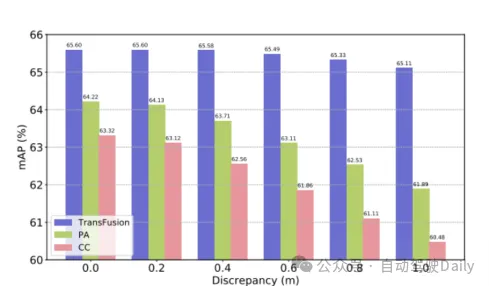
Abbildung 4 Karte bei Sensorfehlausrichtung
Ablationsexperiment
nach Tabelle 5 d )-f) Es kann Aus den Ergebnissen geht hervor, dass die Erkennungsleistung ohne Abfrageinitialisierung stark abnimmt. Obwohl eine Erhöhung der Anzahl der Trainingsrunden und der Decoderschichten die Leistung verbessern kann, kann dennoch nicht der ideale Effekt erzielt werden, was auch bedeutet, dass dies bewiesen ist Von der Seite aus kann die vorgeschlagene Initialisierungsabfragestrategie die Anzahl der Netzwerkschichten reduzieren. Wie in Tabelle 6 gezeigt, bringen Bildmerkmalsfusion und bildgesteuerte Abfrageinitialisierung mAP-Gewinne von 4,8 % bzw. 1,6 %. In Tabelle 7 wurde durch den Vergleich der Genauigkeit in verschiedenen Bereichen die Erkennungsleistung von TransFusion bei schwer zu erkennenden Objekten oder abgelegenen Gebieten im Vergleich zur reinen Lidar-Erkennung verbessert.
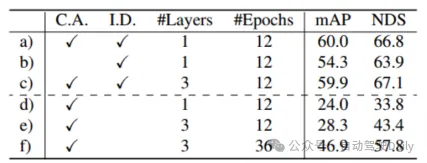
Tabelle 5 Ablationsexperiment des Abfrageinitialisierungsmoduls
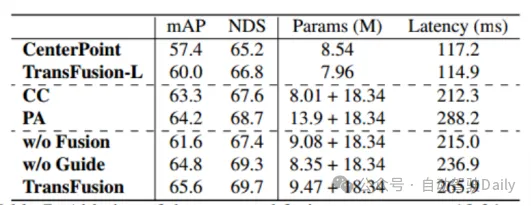
Tabelle 6 Ablationsexperiment des Fusionsteils

Tabelle 7 Abstand zwischen dem Objektzentrum und dem Ego-Fahrzeug (in Metern)
Fazit
Ein effektives und robustes Transformer-basiertes Lidar-Kamera-3D-Erkennungs-Framework ist mit einem weichen Korrelationsmechanismus ausgestattet, der den Standort und die Informationen, die aus dem Bild gewonnen werden sollen, adaptiv bestimmen kann. TransFusion erzielt hochmoderne Ergebnisse in den nuScenes-Erkennungs- und Tracking-Bestenlisten und zeigt konkurrenzfähige Ergebnisse im Waymo-Erkennungs-Benchmark. Umfangreiche Ablationsexperimente belegen die Robustheit dieser Methode gegenüber schlechten Bildbedingungen.
DeepInteraction:
Hauptbeitrag:
Das Hauptproblem besteht darin, dass bestehende multimodale Fusionsstrategien modalitätsspezifische nützliche Informationen ignorieren, was letztendlich die Leistung des Modells beeinträchtigt. Punktwolken liefern notwendige Positionierungs- und geometrische Informationen bei niedrigen Auflösungen, und Bilder liefern umfassende Erscheinungsbildinformationen bei hohen Auflösungen. Daher ist die modalübergreifende Informationsfusion besonders wichtig, um die Leistung der 3D-Zielerkennung zu verbessern. Das vorhandene Fusionsmodul, wie in Abbildung 1(a) dargestellt, integriert die Informationen der beiden Modalitäten in einen einheitlichen Netzwerkraum. Dadurch wird jedoch verhindert, dass einige Informationen in eine einheitliche Darstellung integriert werden, wodurch einige der spezifischen Informationen reduziert werden . Repräsentative Vorteile der Modalität. Um die oben genannten Einschränkungen zu überwinden, schlägt der Artikel ein neues modales Interaktionsmodul vor (Abbildung 1(b)). Die Schlüsselidee besteht darin, zwei modalitätsspezifische Darstellungen zu lernen und aufrechtzuerhalten, um eine Interaktion zwischen Modalitäten zu erreichen. Die Hauptbeiträge sind wie folgt:
- schlägt eine neue modale Interaktionsstrategie für die multimodale 3D-Zielerkennung vor, die darauf abzielt, die grundlegende Einschränkung früherer modaler Fusionsstrategien zu lösen, die in jeder Modalität nützliche Informationen verlieren;
- entwarf eine DeepInteraction-Architektur mit ein interaktiver Encoder mit multimodalen Merkmalen und ein interaktiver Decoder mit multimodaler Merkmalsvorhersage.
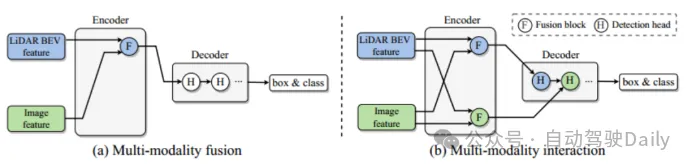
Abbildung 1 Verschiedene Fusionsstrategien
Moduldetails
Interaktiver Encoder mit multimodaler Darstellung Passen Sie den Encoder an eine Multiple-Input-Multiple-Output-Struktur (MIMO) an: Trennen Sie die Lidar- und Kamera-Backbones Die extrahierten zwei modalitätsspezifischen Szeneninformationen werden als Eingabe verwendet und zwei erweiterte Merkmalsinformationen werden generiert. Jede Encoderschicht umfasst: i) multimodale Merkmalsinteraktion (MMRI); ii) intramodales Merkmalslernen iii) Darstellungsintegration;
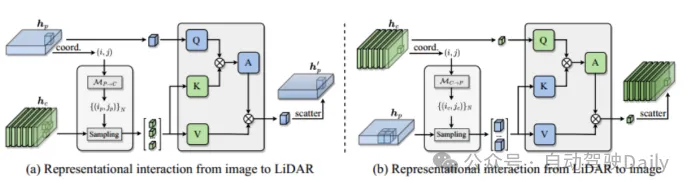
Abbildung 2 Multimodales Darstellungsinteraktionsmodul

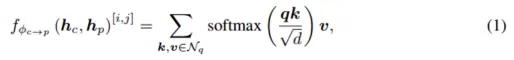
Das Backbone-Netzwerk des Bildes ist ResNet50. Um Rechenkosten zu sparen, wird die Größe des Eingabebildes vor dem Eintritt in das Netzwerk auf die Hälfte der Originalgröße geändert und die Gewichte der Bildzweige werden dabei eingefroren Ausbildung. Die Voxelgröße ist auf (0,075 m, 0,075 m, 0,2 m) eingestellt, der Erkennungsbereich ist auf [-54 m, 54 m] für die X-Achse und Y-Achse und [-5 m, 3 m] für die Z-Achse eingestellt. Entwerfen Sie 2 Schichten Encoderschichten und 5 kaskadierte Decoderschichten. Darüber hinaus werden zwei Online-Übermittlungstestmodelle eingerichtet: Testzeiterhöhung (TTA) und Modellintegration. Die beiden Einstellungen heißen DeepInteraction-large bzw. DeepInteraction-e. Unter anderem verwendet DeepInteraction-large Swin-Tiny als Bild-Backbone-Netzwerk und verdoppelt die Anzahl der Kanäle des Faltungsblocks im Lidar-Backbone-Netzwerk. Die Voxelgröße ist auf [0,5 m, 0,5 m, 0,2 m] eingestellt Bidirektionales Umdrehen und Drehen des Gierwinkels [0°, ±6,25°, ±12,5°], um die Testzeit zu verlängern. DeepInteraction-e integriert mehrere DeepInteraction-große Modelle und die Eingabe-Lidar-BEV-Gittergrößen sind [0,5 m, 0,5 m] und [1,5 m, 1,5 m]. 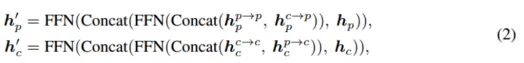

Tabelle 1 Vergleich mit modernsten Methoden auf dem nuScenes-TestsetWie in Tabelle 1 gezeigt, erreicht DeepInteraction State-of-the-Art-Methoden. Spitzenleistung in allen Umgebungen. Tabelle 2 vergleicht die auf NVIDIA V100, A6000 und A100 getesteten Inferenzgeschwindigkeiten. Es ist ersichtlich, dass trotz hoher Leistung immer noch eine hohe Inferenzgeschwindigkeit aufrechterhalten wird, was bestätigt, dass diese Methode einen besseren Kompromiss zwischen Erkennungsleistung und Inferenzgeschwindigkeit erzielt. Tabelle 2: Vergleich der Inferenzgeschwindigkeit ein Hybriddesign: Eine normale DETR-Decoderschicht wird zum Aggregieren von Features in der LIDAR-Darstellung verwendet, und ein multimodaler interaktiver Vorhersagedecoder (MMPI) wird zum Aggregieren von Features in der Bilddarstellung (zweite Zeile) verwendet. MMPI ist deutlich besser als DETR und verbessert 1,3 % mAP und 1,0 % NDS, mit Flexibilität bei der Designkombination. Tabelle 3(c) untersucht weiter den Einfluss verschiedener Decoderschichten auf die Erkennungsleistung. Es zeigt sich, dass sich die Leistung weiter verbessert, wenn 5 Decoderschichten hinzugefügt werden. Schließlich wurden verschiedene Kombinationen von Abfragezahlen, die beim Training und Testen verwendet wurden, verglichen. Bei verschiedenen Auswahlmöglichkeiten war die Leistung stabil, aber 200/300 wurde als optimale Einstellung für Training/Tests verwendet. Tabelle 3: Ablationsexperiment des Decoders die Leistung erheblich verbessern; (2) MMRI und IML können gut zusammenarbeiten, um die Leistung weiter zu verbessern. Wie aus Tabelle 4(b) ersichtlich ist, ist das Stapeln von Encoderschichten für iteratives MMRI von Vorteil.
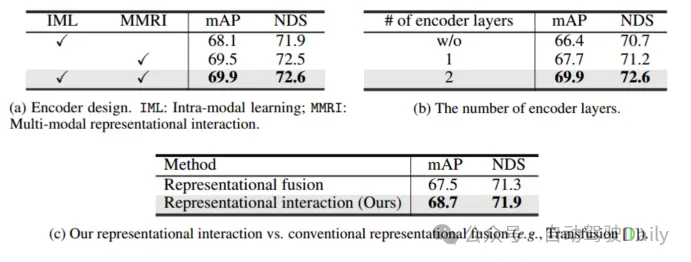
Tabelle 4 Ablationsexperiment des Encoders
Ablationsexperiment des Lidar-Backbone-Netzwerks
Verwendung von zwei verschiedenen Lidar-Backbone-Netzwerken: PointPillar und VoxelNet, um die Allgemeingültigkeit des Frameworks zu überprüfen. Stellen Sie für PointPillars die Voxelgröße auf (0,2 m, 0,2 m) ein, während die restlichen Einstellungen dieselben wie bei DeepInteraction-base bleiben. Aufgrund der vorgeschlagenen multimodalen Interaktionsstrategie zeigt DeepInteraction bei Verwendung eines der beiden Backbones konsistente Verbesserungen gegenüber der reinen Lidar-Basislinie (5,5 % mAP für das voxelbasierte Backbone und 4,4 % mAP für das säulenbasierte Backbone). Dies spiegelt die Vielseitigkeit von DeepInteraction zwischen verschiedenen Punktwolken-Encodern wider.
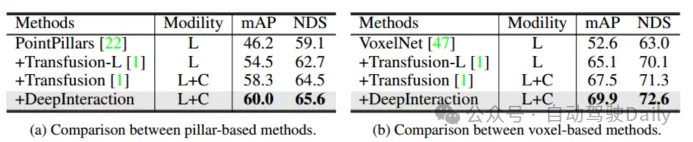
Tabelle 5 Bewertung verschiedener Lidar-Backbones
Schlussfolgerung
In dieser Arbeit wird eine neue 3D-Objekterkennungsmethode DeepInteraction vorgeschlagen, um die inhärenten multimodalen komplementären Eigenschaften zu untersuchen. Die Schlüsselidee besteht darin, zwei modalitätsspezifische Darstellungen beizubehalten und ein Zusammenspiel zwischen ihnen für das Lernen von Darstellungen und die prädiktive Dekodierung herzustellen. Diese Strategie ist speziell darauf ausgelegt, die grundlegende Einschränkung bestehender einseitiger Fusionsmethoden zu beseitigen, nämlich dass die Bilddarstellung aufgrund der zusätzlichen Quellzeichenverarbeitung nicht ausreichend genutzt wird.
Zusammenfassung der beiden Papiere:
Die beiden oben genannten Papiere sind beide dreidimensionale Zielerkennung basierend auf Lidar und Kamerafusion. Aus DeepInteraction ist auch ersichtlich, dass es auf weitere Arbeiten von TransFusion zurückgreift. Aus diesen beiden Arbeiten können wir schließen, dass eine Richtung der Multisensorfusion darin besteht, effizientere dynamische Fusionsmethoden zu erforschen, um sich auf effektivere Informationen verschiedener Modalitäten zu konzentrieren. Selbstverständlich basiert dies alles auf qualitativ hochwertigen Informationen in beiden Modalitäten. Die multimodale Fusion wird in zukünftigen Bereichen wie autonomem Fahren und intelligenten Robotern sehr wichtige Anwendungen haben. Da die aus verschiedenen Modalitäten extrahierten Informationen immer umfangreicher werden, stehen uns auch immer mehr Informationen zur Verfügung eine Frage, über die es sich zu denken lohnt.
Das obige ist der detaillierte Inhalt vonWie kann ein Transformator verwendet werden, um die visuellen Merkmale des Lidar-Millimeterwellenradars effektiv zu korrelieren?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Python zeichnet 3D-Grafiken
- Was ist die Tastenkombination zum Anzeigen des 3D-Desktops in Windows 7?
- Das aktuelle Intrusion-Detection-System kann Hackerangriffe rechtzeitig verhindern, oder?
- So überprüfen Sie, ob nodejs erfolgreich installiert wurde
- Warum wird das Mikrofon auf dem Computer nicht erkannt?