
Heim >Technologie-Peripheriegeräte >KI >Google ergreift Maßnahmen, um die „Amnesie' großer Models zu beheben! Der Feedback-Aufmerksamkeitsmechanismus hilft Ihnen, den Kontext zu „aktualisieren', und die Ära des unbegrenzten Speichers für große Modelle naht.
Google ergreift Maßnahmen, um die „Amnesie' großer Models zu beheben! Der Feedback-Aufmerksamkeitsmechanismus hilft Ihnen, den Kontext zu „aktualisieren', und die Ära des unbegrenzten Speichers für große Modelle naht.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-04-17 15:40:01547Durchsuche
Herausgeber |. Yi Feng
Produziert von 51CTO Technology Stack (WeChat-ID: blog51cto)
Google ergreift endlich Maßnahmen! Wir werden nicht länger unter der „Amnesie“ großer Models leiden.
TransformerFAM wurde geboren und verspricht, großen Modellen unbegrenzten Speicher zu bieten!
Lassen Sie uns ohne weitere Umschweife einen Blick auf die „Wirksamkeit“ von TransformerFAM werfen:
 Bilder
Bilder
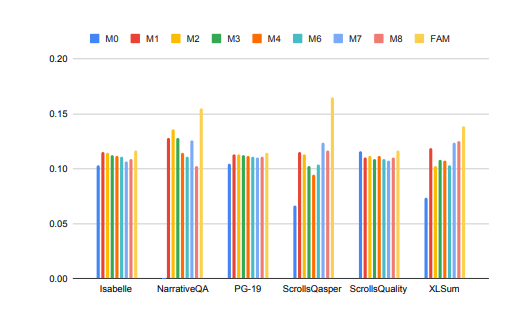
Die Leistung großer Modelle bei der Verarbeitung langer Kontextaufgaben wurde deutlich verbessert!
Im Bild oben erfordern Aufgaben wie Isabelle und NarrativeQA, dass das Modell eine große Menge an Kontextinformationen versteht und verarbeitet und genaue Antworten oder Zusammenfassungen auf bestimmte Fragen gibt. Bei allen Aufgaben übertrifft das mit FAM konfigurierte Modell alle anderen BSWA-Konfigurationen, und es ist ersichtlich, dass ab einem bestimmten Punkt die Erhöhung der Anzahl der BSWA-Speichersegmente seine Speicherkapazitäten nicht weiter verbessern kann.
Es scheint, dass auf dem Weg zu langen Texten und langen Gesprächen das „Unvergessliche“ von FAM, einem großen Modell, durchaus etwas zu bieten hat.
Google-Forscher stellten FAM vor, eine neuartige Transformer-Architektur – Feedback Attention Memory. Mithilfe von Rückkopplungsschleifen kann das Netzwerk auf seine eigene Driftleistung achten, die Entstehung des internen Arbeitsspeichers des Transformers fördern und ihn in die Lage versetzen, unendlich lange Sequenzen zu verarbeiten.
Vereinfacht ausgedrückt ähnelt diese Strategie ein wenig unserer Strategie, die „Amnesie“ großer Models künstlich zu bekämpfen: Geben Sie den Prompt vor jedem Gespräch mit dem großen Model erneut ein. Der Ansatz von FAM ist lediglich fortgeschrittener. Wenn das Modell einen neuen Datenblock verarbeitet, verwendet es die zuvor verarbeiteten Informationen (d. h. FAM) als dynamisch aktualisierten Kontext und integriert sie wieder in den aktuellen Verarbeitungsprozess.
Auf diese Weise können Sie dem Problem des „Dinge vergessen“ gut begegnen. Noch besser: Trotz der Einführung von Feedback-Mechanismen zur Aufrechterhaltung des Langzeitarbeitsgedächtnisses ist FAM darauf ausgelegt, die Kompatibilität mit vorab trainierten Modellen aufrechtzuerhalten, ohne dass zusätzliche Gewichte erforderlich sind. Theoretisch führt der leistungsstarke Speicher eines großen Modells also nicht dazu, dass es langweilig wird oder mehr Rechenressourcen verbraucht.
Also, wie wurde so ein wunderbarer TransformerFAM entdeckt? Was sind die damit verbundenen Technologien?
1. Warum kann TransformerFAM großen Modellen helfen, sich „mehr zu merken“?
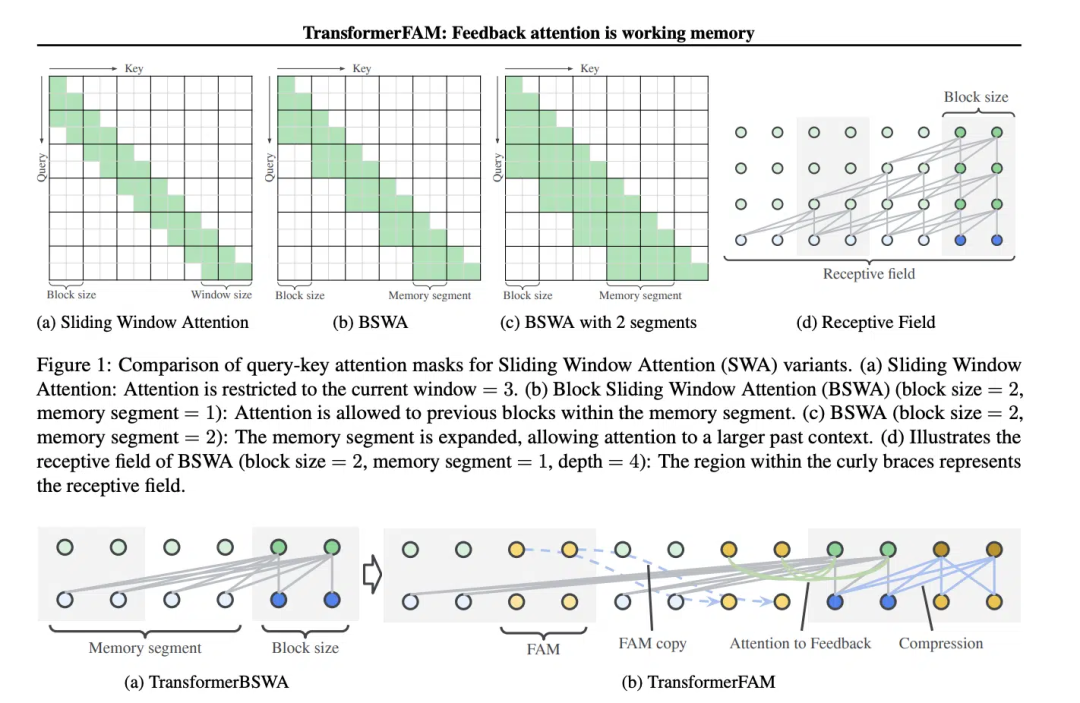
Das Konzept der Sliding Window Attention (SWA) ist entscheidend für das Design von TransformerFAM.
Im traditionellen Transformer-Modell nimmt die Komplexität der Selbstaufmerksamkeit quadratisch mit zunehmender Sequenzlänge zu, was die Fähigkeit des Modells, lange Sequenzen zu verarbeiten, einschränkt.
„Im Film Memento (2000) leidet die Hauptfigur an anterograder Amnesie, was bedeutet, dass sie sich nicht erinnern kann, was in den letzten 10 Minuten passiert ist, aber ihr Langzeitgedächtnis ist intakt und sie muss wichtige Informationen auf den Körper tätowieren.“ „sich an sie zu erinnern ähnelt dem aktuellen Stand großer Sprachmodelle (LLMs)“, heißt es in dem Artikel.
 Screenshots aus dem Film „Memento“, die Bilder stammen aus dem Internet
Screenshots aus dem Film „Memento“, die Bilder stammen aus dem Internet
Sliding Window Attention (Sliding Window Attention), es handelt sich um einen verbesserten Aufmerksamkeitsmechanismus zur Verarbeitung langer Sequenzdaten. Es ist von der Schiebefenstertechnik in der Informatik inspiriert. Bei NLP-Aufgaben (Natural Language Processing) ermöglicht SWA dem Modell, sich bei jedem Zeitschritt nur auf ein Fenster fester Größe der Eingabesequenz zu konzentrieren und nicht auf die gesamte Sequenz. Der Vorteil von SWA besteht daher darin, dass der Rechenaufwand erheblich reduziert werden kann.
 Bilder
Bilder
Aber SWA hat Einschränkungen, da seine Aufmerksamkeitsspanne durch die Fenstergröße begrenzt ist, was dazu führt, dass das Modell wichtige Informationen außerhalb des Fensters nicht berücksichtigen kann.
TransformerFAM erreicht integrierte Aufmerksamkeit, Aktualisierungen auf Blockebene, Informationskomprimierung und globale Kontextspeicherung, indem es eine Feedback-Aktivierung hinzufügt, um die Kontextdarstellung in jeden Block der Schiebefenster-Aufmerksamkeit erneut einzugeben.
In TransformerFAM werden Verbesserungen durch Feedbackschleifen erreicht. Insbesondere konzentriert sich das Modell bei der Verarbeitung des aktuellen Sequenzblocks nicht nur auf Elemente innerhalb des aktuellen Fensters, sondern führt auch zuvor verarbeitete Kontextinformationen (d. h. vorherige „Feedback-Aktivierung“) als zusätzliche Eingabe in den Aufmerksamkeitsmechanismus wieder ein. Selbst wenn das Aufmerksamkeitsfenster des Modells über die Sequenz gleitet, ist es auf diese Weise in der Lage, das Gedächtnis und das Verständnis früherer Informationen aufrechtzuerhalten.
Nach diesen Verbesserungen gibt TransformerFAM LLMs die Möglichkeit, Sequenzen mit unendlicher Länge zu verarbeiten!
Zweitens: Mit einem großen Modell des Arbeitsgedächtnisses wird die Entwicklung in Richtung AGI fortgesetzt.
TransformerFAM hat in der Forschung positive Aussichten gezeigt, was zweifellos die Leistung der KI beim Verstehen und Generieren langer Textaufgaben wie der Dokumentverarbeitung, Zusammenfassung und Story-Generierung verbessern wird , Fragen und Antworten und andere Arbeiten.
 Bilder
Bilder
Gleichzeitig klingt eine KI mit unbegrenztem Speicher attraktiver, egal ob es sich um einen intelligenten Assistenten oder einen emotionalen Begleiter handelt.
Interessanterweise ist das Design von TransformerFAM vom Gedächtnismechanismus in der Biologie inspiriert, der mit der von AGI verfolgten Simulation natürlicher Intelligenz zusammenfällt. Dieser Artikel ist ein Versuch, ein Konzept aus den Neurowissenschaften – das aufmerksamkeitsbasierte Arbeitsgedächtnis – in den Bereich des Deep Learning zu integrieren.
TransformerFAM führt durch Rückkopplungsschleifen das Arbeitsgedächtnis in große Modelle ein und ermöglicht es dem Modell, sich nicht nur kurzfristige Informationen zu merken, sondern auch das Gedächtnis wichtiger Informationen in langfristigen Sequenzen aufrechtzuerhalten.
Durch kühne Fantasie schaffen Forscher Brücken zwischen der realen Welt und abstrakten Konzepten. Da immer wieder innovative Errungenschaften wie TransformerFAM entstehen, werden technologische Engpässe immer wieder überwunden und eine intelligentere und vernetztere Zukunft rückt langsam auf uns zu.
Um mehr über AIGC zu erfahren, besuchen Sie bitte:
51CTO AI.x Community
https://www.51cto.com/aigc/
Das obige ist der detaillierte Inhalt vonGoogle ergreift Maßnahmen, um die „Amnesie' großer Models zu beheben! Der Feedback-Aufmerksamkeitsmechanismus hilft Ihnen, den Kontext zu „aktualisieren', und die Ära des unbegrenzten Speichers für große Modelle naht.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So stellen Sie sicher, dass Google Chrome eWebEditor unterstützt
- Was sind die drei Datenmodelle der Datenbank?
- Wie lautet die Abkürzung für Google China Developer Community Forum?
- Li Xiang, CEO von Li Auto, gab öffentlich seinen Fehler zu: Er korrigierte das Missverständnis des Aufmerksamkeitswarnsystems von Mercedes-Benz
- Wie kann ich ein Div verwenden, um die Aufmerksamkeit des Benutzers zu erregen, ohne das Fenster zu überlaufen?