
Heim >Technologie-Peripheriegeräte >KI >Wer sagt, dass Elefanten nicht tanzen können? Große Sprachmodelle neu programmieren, um eine zeitliche Vorhersage modalübergreifender Interaktionen zu erreichen
Wer sagt, dass Elefanten nicht tanzen können? Große Sprachmodelle neu programmieren, um eine zeitliche Vorhersage modalübergreifender Interaktionen zu erreichen

- 王林nach vorne
- 2024-04-15 15:20:02857Durchsuche
Kürzlich haben Forscher der australischen Monash University, der Ant Group, IBM Research und anderer Institutionen die Anwendung der Modellreprogrammierung auf große Sprachmodelle (LLMs) untersucht und eine neue Perspektive vorgeschlagen: effiziente Neuprogrammierung großer Sprachmodelle für allgemeine Zeitreihenprognosen Systeme, das Time-LLM-Framework. Dieses Framework kann hochpräzise und effiziente Vorhersagen erzielen, ohne das Sprachmodell zu ändern. Es kann herkömmliche Zeitreihenmodelle in mehreren Datensätzen und Vorhersageaufgaben übertreffen, sodass LLMs eine hervorragende Leistung bei der Verarbeitung modalübergreifender Zeitreihendaten zeigen können .

Vor kurzem hat die Entwicklung großer Sprachmodelle im Bereich der allgemeinen Intelligenz, die neue Richtung „Große Modelle + Zeitreihen/Zeitdaten“, viele damit verbundene Fortschritte gezeigt. Aktuelle LLMs haben das Potenzial, Zeitreihen-/zeitliche Data-Mining-Methoden zu revolutionieren und dadurch eine effiziente Entscheidungsfindung in klassischen komplexen Systemen wie Städten, Energie, Verkehr, Gesundheit usw. zu fördern und sich in Richtung universellerer intelligenter Formen der Zeit-/Raumanalyse zu bewegen .
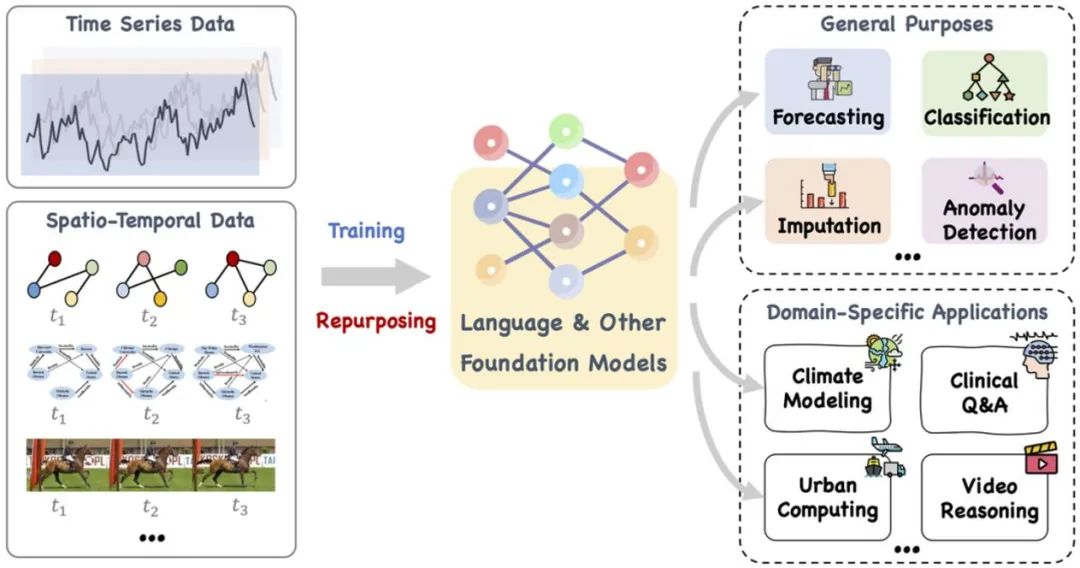
In diesem Artikel wird ein großes Basismodell wie Sprache und andere verwandte Modelle vorgeschlagen, das trainiert und geschickt umfunktioniert werden kann, um eine Reihe allgemeiner Aufgaben und zeitspezifische Domänenanwendungen zu bewältigen. Sequentielle und zeitliche räumliche Daten . Referenz: https://arxiv.org/pdf/2310.10196.pdf.
Neuere Forschungen haben groß angelegte Sprachmodelle von der Verarbeitung natürlicher Sprache auf Zeitreihen und räumlich-zeitliche Aufgaben erweitert. Diese neue Forschungsrichtung, nämlich „großes Modell + Zeitreihen/raumzeitliche Daten“, hat viele verwandte Entwicklungen hervorgebracht, wie z. B. LLMTime, das LLMs direkt für die prädiktive Inferenz von Zero-Shot-Zeitreihen nutzt. Obwohl LLMs über leistungsstarke Lern- und Ausdrucksfähigkeiten verfügen und komplexe Muster und langfristige Abhängigkeiten in Textsequenzdaten effektiv erfassen können, ist die Anwendung von LLMs in Zeitreihen und raumzeitlichen Aufgaben als „Black Box“, die sich auf die Verarbeitung natürlicher Sprache konzentriert, immer noch problematisch Herausforderung. Im Vergleich zu herkömmlichen Zeitreihenmodellen wie TimesNet, TimeMixer usw. sind LLMs aufgrund ihrer großen Parameter und ihres Umfangs mit „Elefanten“ vergleichbar.
Was Sie fragen, ist, wie man solche großen Sprachmodelle (LLMs), die im Bereich der natürlichen Sprache trainiert wurden, „zähmen“ kann, damit sie numerische Sequenzdaten über Textmuster hinweg verarbeiten und leistungsstarke Argumente für Zeitreihen und raumzeitliche Aufgaben entwickeln können sind zu einem Schwerpunkt der aktuellen Forschung geworden. Zu diesem Zweck ist eine tiefergehende theoretische Analyse erforderlich, um mögliche Musterähnlichkeiten zwischen sprachlichen und zeitlichen Daten zu untersuchen und diese effektiv auf bestimmte Zeitreihen und raumzeitliche Aufgaben anzuwenden.
LLM-Reprogrammierung ist eine allgemeine Technologie zur Vorhersage von Zeitreihen. Es schlägt zwei Schlüsseltechnologien vor, nämlich (1) zeitliche Eingabe-Neuprogrammierung und (2) sofortige Vorprogrammierung, um die zeitliche Vorhersageaufgabe in eine „Sprach“-Aufgabe umzuwandeln, die von LLMs effektiv gelöst werden kann und große Sprachmodelle erfolgreich aktiviert, um hohe Ergebnisse zu erzielen Leistung. Fähigkeit, präzise Timing-Überlegungen durchzuführen.

Papieradresse: https://openreview.net/pdf?id=Unb5CVPtae
Papiercode: https://github.com/KimMeen/Time-LLM
1. Problemhintergrund
Timing Daten werden in der Realität in großem Umfang gespeichert, wobei die Zeitvorhersage in vielen dynamischen Systemen der realen Welt von großer Bedeutung ist und umfassend untersucht wurde. Im Gegensatz zur Verarbeitung natürlicher Sprache (NLP) und Computer Vision (CV), bei denen ein einzelnes großes Modell mehrere Aufgaben bewältigen kann, müssen Zeitreihenvorhersagemodelle häufig speziell entwickelt werden, um den Anforderungen verschiedener Aufgaben und Anwendungsszenarien gerecht zu werden. Neuere Untersuchungen haben gezeigt, dass große Sprachmodelle (LLMs) auch bei der Verarbeitung komplexer zeitlicher Abläufe zuverlässig sind. Es ist immer noch eine Herausforderung, die Argumentationsfähigkeiten großer Sprachmodelle selbst für die Bewältigung zeitlicher Analyseaufgaben zu nutzen.
2. Papierübersicht
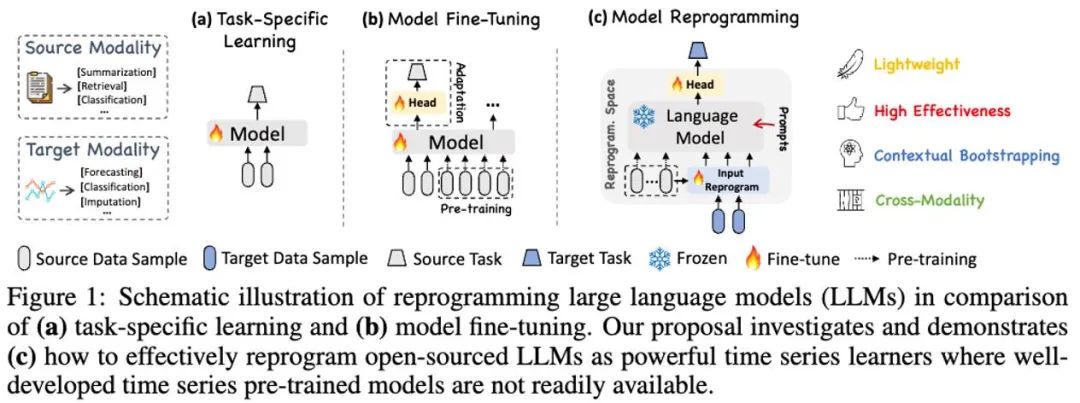
In dieser Arbeit schlägt der Autor Time-LLM vor, ein allgemeines Framework zur Neuprogrammierung großer Sprachmodelle (LLM-Reprogrammierung), das LLM problemlos für allgemeine Zeitreihenvorhersagen verwendet, ohne dass eine Schulung erforderlich ist auf dem großen Sprachmodell selbst. Time-LLM verwendet zunächst Textprototypen (Textprototypen), um die eingegebenen Zeitreihendaten neu zu programmieren, und verwendet die Darstellung in natürlicher Sprache, um die semantischen Informationen der Zeitreihendaten darzustellen, wodurch zwei unterschiedliche Datenmodalitäten ausgerichtet werden, sodass dies beim großen Sprachmodell nicht der Fall ist eine Änderung erfordern. Sie können die Informationen hinter einer anderen Datenmodalität verstehen.
Um das Verständnis von LLM für Eingabezeitreihendaten und entsprechende Aufgaben weiter zu verbessern, schlug der Autor das Prompt-as-Prefix (PaP)-Paradigma vor, das das Prompt-as-Prefix (PaP)-Paradigma durch Hinzufügen zusätzlicher kontextbezogener Eingabeaufforderungen vollständig aktiviert Aufgabenanweisungen vor der Darstellung der Zeitreihendaten von LLM für sequentielle Aufgaben. In dieser Arbeit führte der Autor ausreichend Experimente mit gängigen Zeitreihen-Benchmark-Datensätzen durch, und die Ergebnisse zeigten, dass Time-LLM in den meisten Fällen das traditionelle Zeitreihenmodell übertreffen und bei Stichproben mit wenigen und null Aufnahmen eine bessere Leistung erzielen kann Die Beispiel-Lernaufgabe (Zero-Shot) wurde erheblich verbessert.
Die Hauptbeiträge dieser Arbeit lassen sich wie folgt zusammenfassen:
1 Diese Arbeit schlägt ein neues Konzept zur Neuprogrammierung großer Sprachmodelle für die Zeitanalyse vor, ohne dass das Backbone-Sprachmodell geändert werden muss. Die Autoren zeigen, dass die Vorhersage von Zeitreihen als eine weitere „linguistische“ Aufgabe betrachtet werden kann, die durch handelsübliche LLMs effektiv gelöst werden kann.
2. Diese Arbeit schlägt ein allgemeines Sprachmodell-Reprogrammierungs-Framework vor, nämlich Time-LLM, das darin besteht, eingegebene Zeitdaten in eine natürlichere textliche Prototypendarstellung umzuprogrammieren und diese zur Verbesserung mit deklarativen Hinweisen wie Domänenexpertenwissen und Aufgabenbeschreibung zu integrieren den Eingabekontext, um LLM für eine effektive domänenübergreifende Argumentation zu leiten. Diese Technologie bietet eine solide Grundlage für die Entwicklung multimodaler Timing-Grundmodelle.
3. Time-LLM übertrifft durchweg die beste Leistung bestehender Modelle bei Mainstream-Vorhersageaufgaben, insbesondere in Szenarien mit wenigen Stichproben und Nullstichproben. Darüber hinaus ist Time-LLM in der Lage, eine höhere Leistung zu erzielen und gleichzeitig eine hervorragende Effizienz bei der Neuprogrammierung des Modells beizubehalten. Erschließen Sie das ungenutzte Potenzial von LLM für Zeitreihen und andere sequentielle Daten drastisch.
3. Modellrahmen
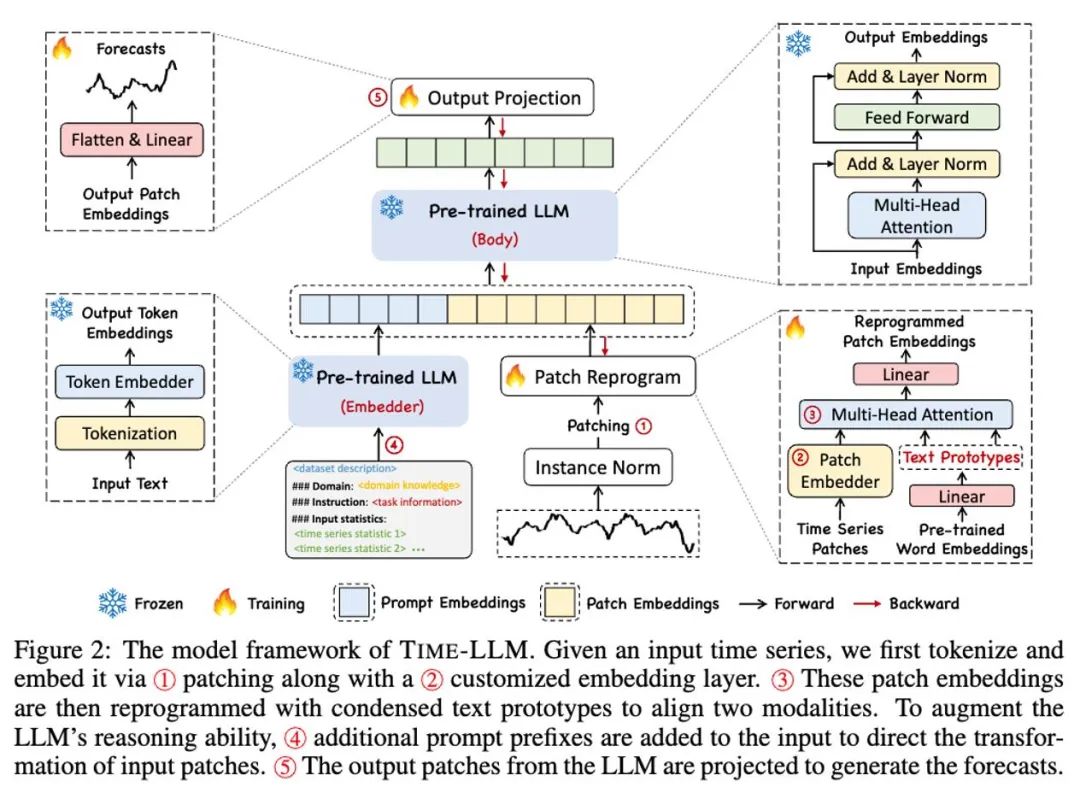
Wie in ① und ② im obigen Modellrahmendiagramm gezeigt, werden die Eingabezeitreihendaten zunächst von RevIN normalisiert und dann in verschiedene Patches unterteilt und dem latenten Raum zugeordnet.
Es gibt erhebliche Unterschiede in den Ausdrucksmethoden zwischen Zeitreihendaten und Textdaten und sie gehören zu unterschiedlichen Modalitäten. Zeitreihen können weder direkt bearbeitet noch verlustfrei in natürlicher Sprache beschrieben werden, was eine erhebliche Herausforderung darstellt, LLM direkt zum Verständnis von Zeitreihen zu bewegen. Daher müssen wir zeitliche Eingabemerkmale an der Textdomäne natürlicher Sprache ausrichten.
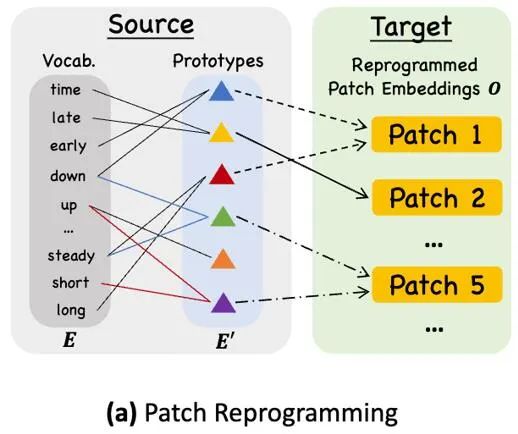
Eine gängige Methode zum Ausrichten verschiedener Modalitäten ist die Kreuzaufmerksamkeit. Wie in ③ im Modellrahmendiagramm gezeigt, müssen Sie nur eine Kreuzaufmerksamkeit für die Einbettungs- und Timing-Eingabemerkmale aller Wörter erstellen (wobei das Timing Die Eingabefunktion ist Abfrage, die Einbettung aller Wörter ist Schlüssel und Wert. Allerdings ist das inhärente Vokabular von LLM sehr groß, sodass zeitliche Merkmale nicht effektiv allen Wörtern direkt zugeordnet werden können und nicht alle Wörter über semantische Beziehungen zu Zeitreihen verfügen. Um dieses Problem zu lösen, führt diese Arbeit eine lineare Kombination von Vokabeln durch, um Textprototypen zu erhalten. Die Anzahl der Textprototypen ist viel kleiner als die des ursprünglichen Vokabulars. Die Kombination kann verwendet werden, um die sich ändernden Eigenschaften von Zeitreihendaten darzustellen „ein kurzer Anstieg oder ein langsamer Rückgang.“
Um die Fähigkeit von LLM bei bestimmten Timing-Aufgaben vollständig zu aktivieren, schlägt diese Arbeit das Prompt-Prefixing-Paradigma vor, eine einfache und effektive Methode, wie in ④ im Modellrahmendiagramm dargestellt. Jüngste Fortschritte haben gezeigt, dass andere Datenmuster wie Bilder nahtlos in das Präfix von Hinweisen integriert werden können, was eine effiziente Schlussfolgerung auf der Grundlage dieser Eingaben ermöglicht. Inspiriert von diesen Erkenntnissen stellen die Autoren eine alternative Frage, um ihre Methode direkt auf reale Zeitreihen anwendbar zu machen: Können Hinweise als Präfixinformationen dienen, um den Eingabekontext zu bereichern und die Transformation neu programmierter Zeitreihen-Patches zu steuern? Dieses Konzept wird Prompt-as-Prefix (PaP) genannt und darüber hinaus stellten die Autoren fest, dass es die Anpassungsfähigkeit von LLM an nachgelagerte Aufgaben erheblich verbessert und gleichzeitig die Patch-Neuprogrammierung ergänzt. Laienhaft ausgedrückt bedeutet dies, einige Vorinformationen des Zeitreihendatensatzes in Form natürlicher Sprache als Präfix-Eingabeaufforderung einzugeben und sie mit den ausgerichteten Zeitreihenfunktionen in LLM zu verbinden. Kann es den Vorhersageeffekt verbessern?
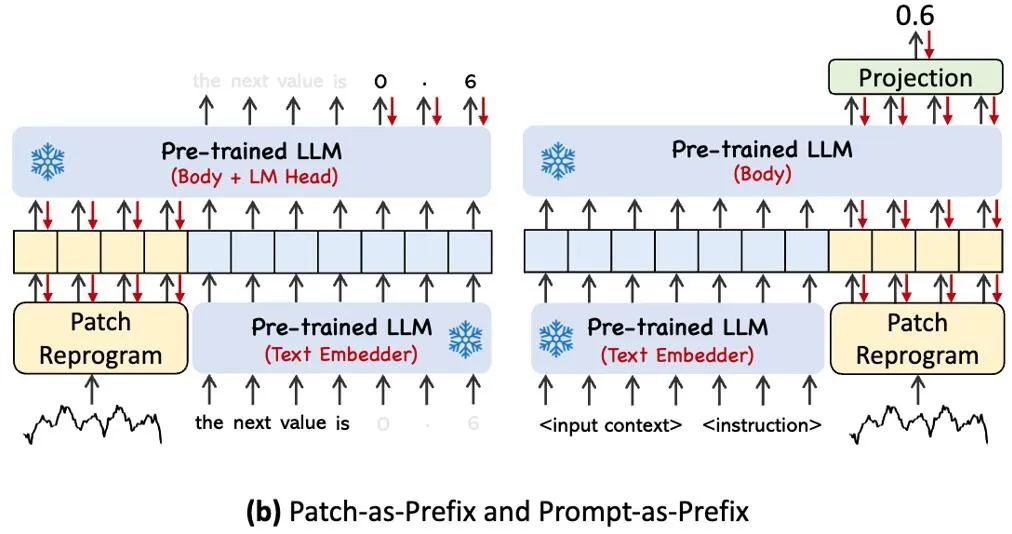
Das Bild oben zeigt zwei Eingabeaufforderungsmethoden. Bei Patch-as-Prefix wird ein Sprachmodell aufgefordert, nachfolgende Werte in einer Zeitreihe vorherzusagen, ausgedrückt in natürlicher Sprache. Dieser Ansatz stößt auf einige Einschränkungen: (1) Sprachmodelle weisen häufig eine geringe Empfindlichkeit auf, wenn sie hochpräzise Zahlen ohne die Unterstützung externer Tools verarbeiten, was erhebliche Herausforderungen für die genaue Verarbeitung langfristiger Vorhersageaufgaben mit sich bringt. (2) Komplexe kundenspezifische Nachbearbeitung ist für unterschiedliche Sprachmodelle erforderlich, da sie auf unterschiedlichen Korpora vorab trainiert sind und bei der Generierung hochpräziser Zahlen möglicherweise unterschiedliche Wortsegmentierungstypen verwenden. Dies führt dazu, dass Vorhersagen in verschiedenen natürlichen Sprachformaten dargestellt werden, z. B. [‚0‘, ‚.‘, ‚6‘, ‚1‘] und [‚0‘, ‚.‘, ‚61‘], was 0,61 darstellt.
In der Praxis hat der Autor drei Schlüsselkomponenten für die Erstellung effektiver Eingabeaufforderungen identifiziert: (1) Datensatzkontext (2) Aufgabenanweisungen zur Anpassung von LLM an verschiedene nachgelagerte Aufgaben (3) statistische Beschreibung, wie Trends, Zeitverzögerung und Wartezeit; ermöglichen es LLM, die Eigenschaften von Zeitreihendaten besser zu verstehen. Das Bild unten zeigt ein Beispiel für eine Eingabeaufforderung.

4. Experimentelle Ergebnisse
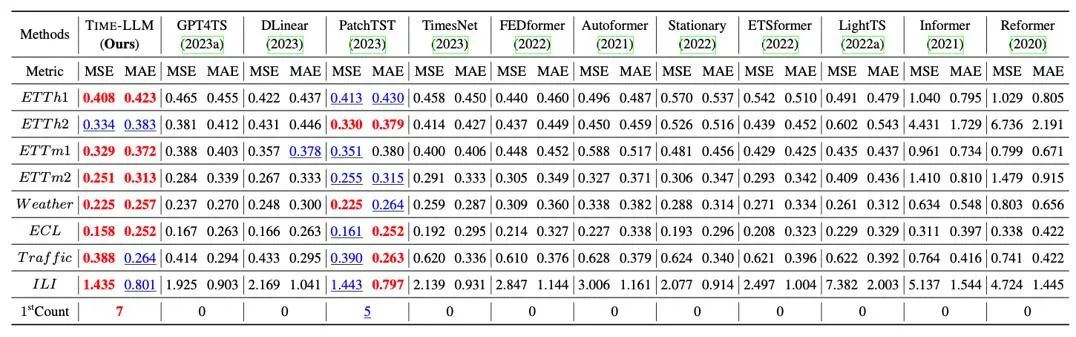
Wir haben umfassende Tests an 8 klassischen öffentlichen Datensätzen zur Langzeitvorhersage durchgeführt. Wie in der Tabelle unten gezeigt, übertraf Time-LLM die bisherigen Besten auf diesem Gebiet im Benchmark Darüber hinaus wurde im Vergleich zu GPT4TS, das GPT-2 direkt verwendet, auch Time-LLM, das Umprogrammierungsideen und Prompt-as-Prefix verwendet, erheblich verbessert, was auf die Wirksamkeit dieser Methode hinweist.
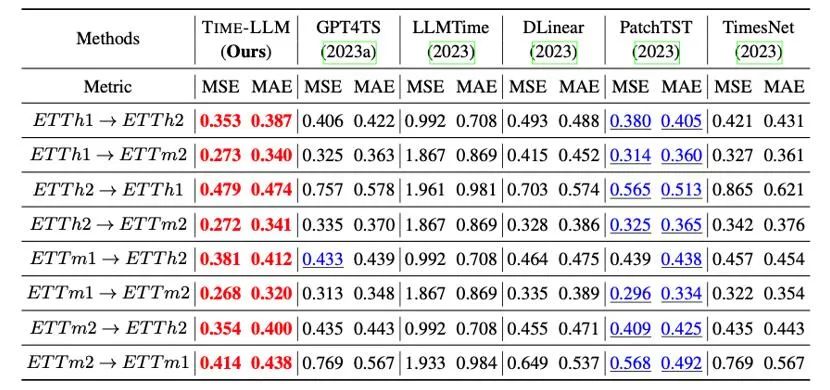
Darüber hinaus bewerten wir die Zero-Shot-Zero-Shot-Lernfähigkeit von neu programmiertem LLM im Rahmen der domänenübergreifenden Anpassung. Dank der Fähigkeit zur Neuprogrammierung aktivieren wir die Vorhersagefähigkeit von LLM domänenübergreifend Wie in der Tabelle unten gezeigt, zeigt Time-LLM auch in Zero-Shot-Szenarien außergewöhnliche Vorhersageergebnisse.
5. Zusammenfassung
Die rasante Entwicklung großer Sprachmodelle (LLMs) hat den Fortschritt der künstlichen Intelligenz in modalübergreifenden Szenarien erheblich vorangetrieben und ihre weit verbreitete Anwendung in mehreren Bereichen gefördert. Allerdings haben die große Parameterskala von LLMs und ihr Design hauptsächlich für Szenarien der Verarbeitung natürlicher Sprache (NLP) viele Herausforderungen für ihre modal- und domänenübergreifenden Anwendungen mit sich gebracht. Vor diesem Hintergrund schlagen wir eine neue Idee zur Neuprogrammierung großer Modelle vor, die darauf abzielt, eine modalübergreifende Interaktion zwischen Text- und Sequenzdaten zu erreichen, und wenden diese Methode umfassend auf die Verarbeitung großer Zeitreihen und raumzeitlicher Daten an. Auf diese Weise hoffen wir, LLMs zu flexiblen tanzenden Elefanten zu machen, die ihre leistungsstarken Fähigkeiten in einem breiteren Spektrum von Anwendungsszenarien unter Beweis stellen können.
Interessierte Freunde sind herzlich eingeladen, den Artikel (https://arxiv.org/abs/2310.01728) zu lesen oder die Projektseite (https://github.com/KimMeen/Time-LLM) zu besuchen, um mehr zu erfahren.
Dieses Projekt erhielt volle Unterstützung von NextEvo, der Forschungs- und Entwicklungsabteilung für KI-Innovationen der Intelligent Engine Division der Ant Group, insbesondere dank der engen Zusammenarbeit zwischen dem Team für Sprach- und Maschinenintelligenz und dem Team für Optimierungsintelligenz. Unter der Führung und Anleitung von Zhou Jun, Vizepräsident der Intelligent Engine Division, und Lu Xingyu, Leiter des Optimization Intelligence Teams, haben wir gemeinsam daran gearbeitet, diesen wichtigen Erfolg erfolgreich abzuschließen.
Das obige ist der detaillierte Inhalt vonWer sagt, dass Elefanten nicht tanzen können? Große Sprachmodelle neu programmieren, um eine zeitliche Vorhersage modalübergreifender Interaktionen zu erreichen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!