
Heim >Technologie-Peripheriegeräte >KI >Trajectory Prediction Series | Worüber spricht die weiterentwickelte Version von HiVT QCNet?
Trajectory Prediction Series | Worüber spricht die weiterentwickelte Version von HiVT QCNet?

- WBOYnach vorne
- 2024-04-12 18:28:21834Durchsuche
Die weiterentwickelte Version von HiVT (Sie können diesen Artikel direkt lesen, ohne HiVT zuerst zu lesen) mit deutlich verbesserter Leistung und Effizienz.
Der Artikel ist auch leicht zu lesen.
[Trajectory Prediction Series] [Notizen] HiVT: Hierarchischer Vektortransformator für Multi-Agent-Bewegungsvorhersage – Zhihu (zhihu.com)
Originallink:
https://openaccess.thecvf.com/content/CVPR2023/ papers /Zhou_Query-Centric_Trajectory_Prediction_CVPR_2023_paper.pdf
Abstract
Es gibt ein Problem im Modell, bei dem der Agent als Zentrum für die Vorhersage verwendet wird. Wenn sich das Fenster bewegt, muss es mehrmals wiederholt werden, um es auf das Agentenzentrum zu normalisieren Dann wiederholen Sie den Kodierungsvorgang. Es ist nicht für den Onboard-Einsatz geeignet. Daher verwenden wir ein abfragezentriertes Framework für die Szenenkodierung, das berechnete Ergebnisse wiederverwenden kann und nicht auf das globale Zeitkoordinatensystem angewiesen ist. Da verschiedene Agenten gleichzeitig Szenenmerkmale gemeinsam nutzen, kann der Trajektoriendekodierungsprozess des Agenten paralleler verarbeitet werden.
Die Szene ist komplex kodiert, und mit der aktuellen Dekodierungsmethode ist es immer noch schwierig, Modusinformationen zu erfassen, insbesondere für Langzeitvorhersagen. Um dieses Problem zu lösen, verwenden wir zunächst die ankerfreie Abfrage, um einen Trajektorienvorschlag zu generieren (eine schrittweise Methode zur Merkmalsextraktion), damit das Modell die Szenenmerkmale zu verschiedenen Zeiten besser nutzen kann. Dann gibt es noch das Anpassungsmodul, das den im vorherigen Schritt erhaltenen Vorschlag nutzt, um die Flugbahn zu optimieren (dynamisch ankerbasiert). Durch diese hochwertigen Anker kann unser abfragebasierter Decoder die Eigenschaften des Modus besser verarbeiten.
Erfolgreich gerankt. Dieses Design implementiert auch Szenario-Feature-Codierung und parallele Multi-Agent-Decodierungspipelines.
Einführung
Das aktuelle Papier zur Flugbahnvorhersage weist die folgenden Probleme auf:
- Für eine Vielzahl von heterogenen Szeneninformationen ist die Verarbeitungseffizienz gering. Bei unbemannten Fahraufgaben werden Daten Bild für Bild an das Modell gestreamt, einschließlich vektorisierter hochpräziser Karten und historischer Flugbahnen umgebender Agenten. Die jüngste Methode der faktorisierten Aufmerksamkeit (getrennte Aufmerksamkeit in Raum und Zeit) hat die Verarbeitung dieser Informationen auf eine neue Ebene gehoben. Dies erfordert jedoch Aufmerksamkeit für jedes Szenenelement. Wenn die Szene sehr komplex ist, sind die Kosten immer noch sehr hoch.
- Mit zunehmender Zeit der Prognose explodiert auch die Unsicherheit der Prognose. Beispielsweise kann ein Auto an einer Kreuzung geradeaus fahren oder abbiegen. Um zu vermeiden, dass potenzielle Möglichkeiten verpasst werden, muss das Modell die Verteilung mehrerer Moden ermitteln, anstatt nur die Mode mit der höchsten Häufigkeit vorherzusagen. Es gibt jedoch nur ein GT, und es ist unmöglich, bei mehreren Möglichkeiten ein besseres Lernen durchzuführen. Einige Arbeiten schlagen die Verwendung mehrerer Handanker zur Überwachung vor. Dieser Effekt hängt vollständig von der Qualität der Anker ab. Dieser Ansatz ist sehr schlecht, wenn der Anker GT nicht genau abdecken kann. Es gibt auch andere Ansätze zur direkten Vorhersage mehrerer Modi, wobei die Probleme des Moduskollapses und der Trainingsinstabilität ignoriert werden.
Um die oben genannten Probleme zu lösen, haben wir QCNet vorgeschlagen.
Zunächst wollen wir die Inferenzgeschwindigkeit von Onboard verbessern und gleichzeitig die leistungsstarke faktorisierte Aufmerksamkeit sinnvoll nutzen. Die agentenzentrierte Kodierungsmethode der Vergangenheit funktioniert offensichtlich nicht. Wenn der nächste Datenrahmen eintrifft, verschiebt sich das Fenster, aber es wird immer noch eine große Überlappung mit dem vorherigen Rahmen geben, sodass wir die Möglichkeit haben, „diese Funktionen wiederzuverwenden“. Allerdings muss die agentenzentrierte Methode auf das Agentenkoordinatensystem übertragen werden, sodass die Szene neu kodiert werden muss. Um dieses Problem zu lösen, haben wir die „abfragezentrierte“ Methode verwendet: Szenenelemente extrahieren Merkmale innerhalb ihres eigenen räumlich-zeitlichen Koordinatensystems, unabhängig vom globalen Koordinatensystem (es spielt keine Rolle, wo sich das Ego befindet). (Hochpräzise Karten können verwendet werden, da Kartenelemente Langzeit-IDs haben. Nicht hochpräzise Karten sollten schwierig zu verwenden sein. Kartenelemente müssen im vorderen und hinteren Rahmen verfolgt werden.)
Dies ermöglicht uns Um die zuvor verarbeiteten Ergebnisse zu kodieren, werden sie wiederverwendet, und der Agent nutzt direkt die Funktionen dieser Caches, wodurch Latenz gespart wird.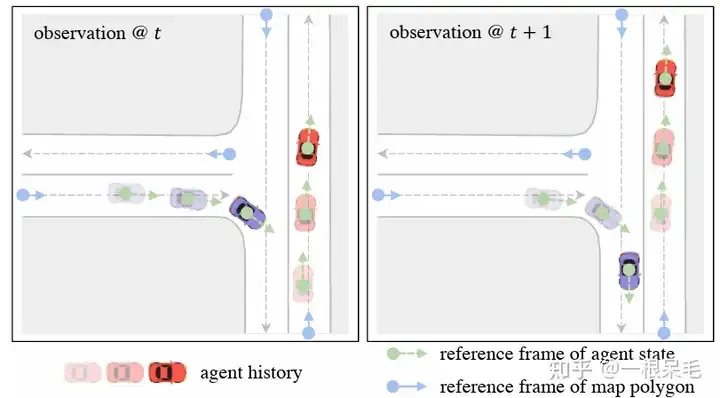 Zweitens verwenden wir eine ankerfreie Abfrage, um die Szenenmerkmale Schritt für Schritt (an der vorherigen Position) zu extrahieren, um diese Szenenkodierungsergebnisse besser für die Multi-Mode-Langzeitvorhersage nutzen zu können, sodass jede Dekodierung erfolgt sehr kurzer Schritt. Dieser Ansatz ermöglicht es, die Merkmalsextraktion der Szene auf einen bestimmten Standort des Agenten in der Zukunft zu konzentrieren, anstatt entfernte Merkmale zu extrahieren, um den Standort mehrerer Momente in der Zukunft zu berücksichtigen. Der so erhaltene hochwertige Anker wird im nächsten Refine-Modul feinjustiert. Diese
Zweitens verwenden wir eine ankerfreie Abfrage, um die Szenenmerkmale Schritt für Schritt (an der vorherigen Position) zu extrahieren, um diese Szenenkodierungsergebnisse besser für die Multi-Mode-Langzeitvorhersage nutzen zu können, sodass jede Dekodierung erfolgt sehr kurzer Schritt. Dieser Ansatz ermöglicht es, die Merkmalsextraktion der Szene auf einen bestimmten Standort des Agenten in der Zukunft zu konzentrieren, anstatt entfernte Merkmale zu extrahieren, um den Standort mehrerer Momente in der Zukunft zu berücksichtigen. Der so erhaltene hochwertige Anker wird im nächsten Refine-Modul feinjustiert. Diese
nutzt die Vorteile der beiden Methoden voll aus, um Multimode- und Langzeitvorhersagen zu erzielen.
Dieser Ansatz ist der erste, der die Kontinuität der Flugbahnvorhersage untersucht, um eine Hochgeschwindigkeitsinferenz zu erreichen. Gleichzeitig berücksichtigt der Decoderteil auch Multimode- und Langzeitvorhersageaufgaben.
AnsatzInput und Output
Gleichzeitig kann das Vorhersagemodul auch M Polygone aus der hochpräzisen Karte abrufen. Jedes Polygon verfügt über mehrere Punkte und semantische Informationen (Zebrastreifen, Fahrspur usw.).
Das Vorhersagemodul verwendet den oben genannten Agentenstatus und die Karteninformationen zu T-Momenten, um K vorhergesagte Trajektorien mit einer Gesamtlänge von T' sowie deren Wahrscheinlichkeitsverteilung zu liefern.
Abfragezentrierte Szenenkontextkodierung
Der erste Schritt ist natürlich die Kodierung der Szene. Die derzeit beliebte faktorisierte Aufmerksamkeit (Aufmerksamkeit in Zeit- bzw. Raumdimensionen) erfolgt auf diese Weise. Konkret gibt es drei Schritte:
- Zeitdimension Aufmerksamkeit, Zeitkomplexität O(A), die Multiplikation der Zeitdimensionsmatrix jedes Agenten
- Queraufmerksamkeit zwischen Agent und Karte, zeitliche Komplexität O(ATM), in jedem Moment, Matrixmultiplikation von Agent und Kartenelementen
- Aufmerksamkeit zwischen Agent und Agent, zeitliche Komplexität O(T), in jedem Moment der Agent und die Agentenmatrix werden multipliziert
Im Vergleich zur vorherigen Methode, bei der das Feature in der Zeitdimension auf den aktuellen Moment komprimiert und dann zwischen dem Agenten und dem Agenten, dem Agenten und der Karte interagiert wird, gilt diese Methode für jeden Moment In der Vergangenheit können Sie weitere Informationen abrufen, z. B. die Entwicklung der Interaktion zwischen dem Agenten und der Karte zu jedem Zeitpunkt.
Aber der Nachteil ist, dass die kubische Komplexität sehr groß wird, wenn die Szene komplexer wird und die Anzahl der Elemente zunimmt. Unser Ziel ist es, diese faktorisierte Aufmerksamkeit sinnvoll zu nutzen, ohne dass die Zeitkomplexität so schnell explodiert.
Eine einfache Möglichkeit besteht darin, die Ergebnisse des vorherigen Frames zu verwenden, da es in der Zeitdimension tatsächlich T-1-Frames gibt, die vollständig wiederholt werden. Da wir diese Features jedoch drehen und verschieben müssen, um sie an die Position und Ausrichtung des aktuellen Frames des Agenten anzupassen, können wir nicht einfach die Ergebnisse der vorherigen Frame-Operation verwenden.
Um das Problem des Koordinatensystems zu lösen, wird ein abfragezentrierter Ansatz gewählt, um die Eigenschaften von Szenenelementen zu lernen, ohne sich auf ihre globalen Koordinaten zu verlassen. Dieser Ansatz erstellt ein lokales räumlich-zeitliches Koordinatensystem für jedes Szenenelement und extrahiert Merkmale innerhalb dieses Koordinatensystems. Selbst wenn das Ego woanders hingeht, bleiben die lokal extrahierten Merkmale unverändert. Dieses lokale räumlich-zeitliche Koordinatensystem hat natürlich eine Ursprungsposition und -richtung. Diese Positionsinformationen werden als Schlüssel verwendet, und die extrahierten Merkmale werden als Wert verwendet, um nachfolgende Aufmerksamkeitsoperationen zu erleichtern. Der gesamte Ansatz ist in die folgenden Schritte unterteilt:
Lokales Raumzeit-Koordinatensystem
Wählen Sie für die Funktion des Agenten i zum Zeitpunkt t die Position und Ausrichtung zu diesem Zeitpunkt als Referenzsystem aus. Bei Kartenelementen wird der Startpunkt dieses Elements als Referenzrahmen verwendet. Eine solche Referenzsystem-Auswahlmethode kann die extrahierten Merkmale unverändert lassen, nachdem sich das Ego bewegt hat.
Einbettung von Szenenelementen
Für andere Vektormerkmale innerhalb jedes Elements werden Polarkoordinatendarstellungen im obigen Referenzsystem erhalten. Anschließend werden sie in Fourier-Merkmale umgewandelt, um Hochfrequenzsignale zu erhalten. Nach der Verkettung der semantischen Merkmale erhält MLP die Merkmale. Um bei Kartenelementen sicherzustellen, dass die Reihenfolge der internen Punkte nicht relevant ist, wird zunächst Aufmerksamkeit und dann ein Pooling durchgeführt. Schließlich sind die Agentenmerkmale [A, T, D] und die Kartenmerkmale sind [M, D]. Nur durch die Beibehaltung dieser Konsistenz kann die Matrixmultiplikation der Aufmerksamkeit erleichtert werden. Die so extrahierten Merkmale können Ego überall nutzbar machen.
Fourier-Einbettung: Erstellen Sie eine normalverteilte Einbettung, die den Gewichten verschiedener Frequenzen entspricht, multiplizieren Sie die Eingabesumme mit 2Π und nehmen Sie schließlich cos und sin als Merkmale. Ein intuitives Verständnis sollte darin bestehen, den Eingang als Signal zu behandeln und das Signal in mehrere Grundsignale (Signale mit mehreren Frequenzen) zu dekodieren. Dadurch können Hochfrequenzsignale besser erfasst werden. Bei allgemeinen Methoden können feine Hochfrequenzsignale leicht verloren gehen. Es ist erwähnenswert, dass die Verwendung verrauschter Daten nicht empfohlen wird, da dadurch fälschlicherweise das falsche Hochfrequenzsignal erfasst wird. (Es fühlt sich ein bisschen wie Überanpassung an, nicht zu allgemein, aber nicht zu präzise)
Relative räumlich-zeitliche Positionseinbettung

Selbstaufmerksamkeit für die Kartenkodierung

Faktorisierte Aufmerksamkeit für die Agentenkodierung



Nähe ist als Umkreis von 50 m um den Agenten definiert. Insgesamt werden Zeiten durchgeführt.
Es ist erwähnenswert, dass die durch die obige Methode erhaltenen Merkmale eine räumlich-zeitliche Invarianz aufweisen, d. Da es im Vergleich zum vorherigen Frame nur einen neuen Datenrahmen gibt, besteht keine Notwendigkeit, die Merkmale des vorherigen Moments zu berechnen, sodass die gesamte Rechenkomplexität durch T geteilt wird.

Abfragebasierte Trajektoriendekodierung
Ähnlich wie die ankerfreie Abfragemethode von DETR, bei der auf bestimmte Schlüsselwerte geachtet wird, führt dies zu instabilem Training, Problemen mit dem Zusammenbruch des Modus und auch die langfristige Vorhersage ist schwierig. Unzuverlässig, weil die Unsicherheit zu einem späteren Zeitpunkt explodieren wird. Daher verwendet dieses Modell zunächst eine grobe ankerfreie Abfragemethode und verfeinert dann die ankerbasierte Methode für diese Ausgabe.
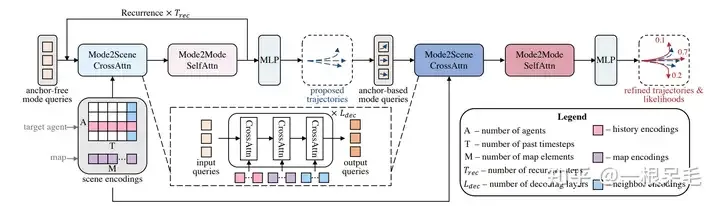 Die gesamte Netzwerkstruktur
Die gesamte Netzwerkstruktur
Mode2Scene und Mode2Mode Attention
Mode2Scene übernimmt in beiden Schritten die DETR-Struktur: Die Abfrage erfolgt im K-Trajektorienmodus (der grobe Vorschlagsschritt wird direkt zufällig generiert und der Verfeinerungsschritt wird aus dem Vorschlag erhalten Schrittmerkmale als Eingabe) und führen Sie dann mehrere Queraufmerksamkeiten auf die Szenenmerkmale aus (Agentenverlauf, Karte, umgebende Agenten).
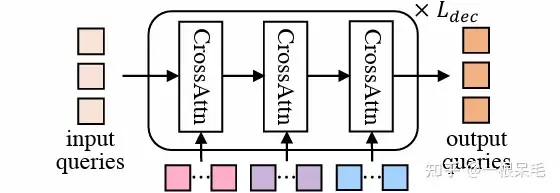 DETR-Struktur
DETR-Struktur
Mode2Mode führt Selbstaufmerksamkeit zwischen den K-Modi durch, um die Vielfalt zwischen den Modi zu erkennen und zu vermeiden, dass sie alle zusammenkommen.
Referenzrahmen von Modusabfragen
Um die Flugbahnen mehrerer Agenten parallel vorherzusagen, wird die Kodierung der Szene von mehreren Agenten gemeinsam genutzt. Da es sich bei den Szenenfeatures immer um Features relativ zu sich selbst handelt, müssen Sie dennoch in die Agentenperspektive wechseln, wenn Sie sie verwenden möchten. Für die Modusabfrage werden die Standort- und Orientierungsinformationen des Agenten angehängt. Ähnlich wie beim vorherigen Vorgang zum Codieren der relativen Position werden auch die relativen Positionsinformationen des Szenenelements und des Agenten als Schlüssel und Wert eingebettet. (Intuitiv ausgedrückt ist es eine gewichtete Aufmerksamkeit jedes Agentenmodus auf die Verwendung nahegelegener Informationen.)
Ankerfreier Trajektorienvorschlag
Das erste Mal ist die ankerfreie Methode, bei der eine lernbare Abfrage verwendet wird, um relativ wenig zu erstellen Qualität Der Trajektorienvorschlag generiert insgesamt K Vorschläge. Da Queraufmerksamkeit zum Extrahieren von Merkmalen aus Szeneninformationen verwendet wird, können relativ kleine und effektive Anker effizient für die Verwendung in der zweiten Verfeinerung generiert werden. Selbstaufmerksamkeit macht jeden Vorschlag insgesamt vielfältiger.

Ankerbasierte Trajektorienverfeinerung
Obwohl die ankerfreie Methode relativ einfach ist, weist sie auch das Problem eines instabilen Trainings und eines möglichen Moduskollapses auf. Gleichzeitig muss der zufällig generierte Modus auch für verschiedene Agenten in der gesamten Szene gut funktionieren. Dies ist relativ schwierig und es ist leicht, Flugbahnvorschläge zu generieren, die nicht mit der Kinematik oder dem Verkehr übereinstimmen. Deshalb dachten wir darüber nach, eine weitere ankerbasierte Korrektur vorzunehmen. Basierend auf dem Vorschlag wird ein Versatz vorhergesagt (zum ursprünglichen Vorschlag hinzugefügt, um die überarbeitete Flugbahn zu erhalten) und die Wahrscheinlichkeit jeder neuen Flugbahn wird vorhergesagt.
Dieses Modul verwendet auch die Form von DETR. Die Abfrage jedes Modus wird mithilfe des Vorschlags des vorherigen Schritts extrahiert. Insbesondere wird eine kleine GRU verwendet, um jeden Anker einzubetten (Schritt nach vorne) und bis zum Ende zu verwenden. Eine Funktion dient zu einem bestimmten Zeitpunkt als Abfrage. Diese ankerbasierten Abfragen können bestimmte räumliche Informationen bereitstellen und so die Erfassung nützlicher Informationen während der Aufmerksamkeit erleichtern.
Trainingsziele
Das Gleiche wie HiVT (siehe HiVT-Analyse), unter Verwendung der Laplace-Verteilung. Um es ganz klar auszudrücken: Jeder Moment in jedem Modus wird als Laplace-Verteilung modelliert (siehe die allgemeine Gaußsche Verteilung, wobei Mittelwert und Var die Position dieses Punktes und seine Unsicherheit darstellen). Und die Momente gelten als unabhängig (direkt multipliziert). Π stellt die Wahrscheinlichkeit des entsprechenden Modus dar.
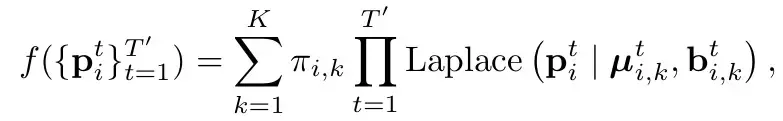
Verlust besteht aus 3 Teilen
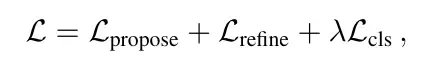
ist hauptsächlich in zwei Teile unterteilt: Klassifizierungsverlust und Regressionsverlust.
Klassifizierungsverlust bezieht sich auf den Verlust der vorhergesagten Wahrscheinlichkeit. Hierbei ist zu beachten, dass die Gradientenrückkehr unterbrochen werden muss und der durch die Wahrscheinlichkeit verursachte Gradient nicht auf die Vorhersage von Koordinaten übertragen werden kann (das heißt, vorausgesetzt). Die vorhergesagte Position jedes Modus liegt unter vernünftigen Voraussetzungen. Die Beschriftung, die GT am nächsten kommt, ist 1, die anderen sind 0. Es gibt zwei Regressionsverluste: Der eine ist der Verlust des Vorschlags der ersten Stufe und der andere der Verlust der Verfeinerung der zweiten Stufe. Es wird ein Winner-Take-All-Ansatz verwendet, das heißt, es wird nur der Verlust des Modus berechnet, der GT am nächsten kommt, und die Regressionsverluste beider Stufen werden berechnet. Um die Stabilität des Trainings zu gewährleisten, wird die Gradientenrückkehr auch in den beiden Phasen unterbrochen, sodass beim Vorschlagslernen nur Vorschläge gelernt werden und bei der Verfeinerung nur die Verfeinerung gelernt wird. Was die Ensemble-Technik betrifft, halte ich sie für etwas betrügerisch: Sie können sich auf die Einführung in BANet beziehen, die im Folgenden kurz vorgestellt wird. Der letzte Schritt beim Generieren der Trajektorie besteht darin, mehrere Untermodelle (Decoder) gleichzeitig mit derselben Struktur zu verbinden, was mehrere Sätze von Vorhersagen ergibt. Beispielsweise gibt es 7 Untermodelle mit jeweils 6 Vorhersagen, insgesamt 42 . Verwenden Sie dann kmeans, um eine Clusterbildung durchzuführen (unter Verwendung des letzten Koordinatenpunkts als Clusterbildungsstandard). Das Ziel besteht aus 6 Gruppen, 7 Elementen in jeder Gruppe, und führen Sie dann einen gewichteten Durchschnitt in jeder Gruppe durch, um eine neue Flugbahn zu erhalten. Die Gewichtungsmethode ist wie folgt. Es ist die b-minFDE der aktuellen Flugbahn und gt, und c ist die Wahrscheinlichkeit der aktuellen Flugbahn. Das Gewicht wird in jeder Gruppe berechnet und dann werden die Flugbahnkoordinaten gewichtet und summiert eine neue Flugbahn erhalten. (Es fühlt sich etwas schwierig an, da c tatsächlich die Wahrscheinlichkeit dieser Flugbahn in der Ausgabe des Untermodells ist und bei der Verwendung beim Clustering etwas nicht mit den Erwartungen übereinstimmt.) Argoverse1 liegt ebenfalls weit vorne
Argoverse2 Basic SOTA (* zeigt an, dass die Ensemble-Technik verwendet wird)
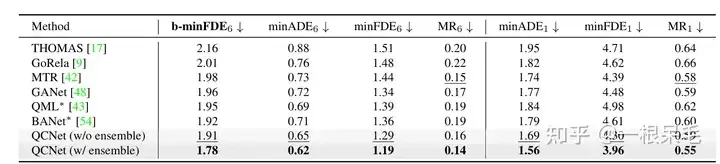 Der Unterschied zwischen b-minFDE und minFDE besteht darin, dass es mit einem zusätzlichen Koeffizienten multipliziert wird, der sich auf seine Wahrscheinlichkeit bezieht Das Ziel möchte, dass die FDE die kleinste ist. Je höher die Wahrscheinlichkeit dieser Flugbahn, desto besser.
Der Unterschied zwischen b-minFDE und minFDE besteht darin, dass es mit einem zusätzlichen Koeffizienten multipliziert wird, der sich auf seine Wahrscheinlichkeit bezieht Das Ziel möchte, dass die FDE die kleinste ist. Je höher die Wahrscheinlichkeit dieser Flugbahn, desto besser. 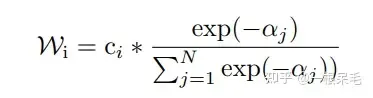 Und die Wahrscheinlichkeit der neuen Flugbahn nach dieser Operation beträgt Auch die genaue Berechnung ist schwierig. Die obige Methode kann nicht verwendet werden, da sonst die Gesamtwahrscheinlichkeitssumme nicht unbedingt 1 beträgt. Es scheint, dass wir die Wahrscheinlichkeiten nur in Clustern mit gleichem Gewicht berechnen können.
Und die Wahrscheinlichkeit der neuen Flugbahn nach dieser Operation beträgt Auch die genaue Berechnung ist schwierig. Die obige Methode kann nicht verwendet werden, da sonst die Gesamtwahrscheinlichkeitssumme nicht unbedingt 1 beträgt. Es scheint, dass wir die Wahrscheinlichkeiten nur in Clustern mit gleichem Gewicht berechnen können. 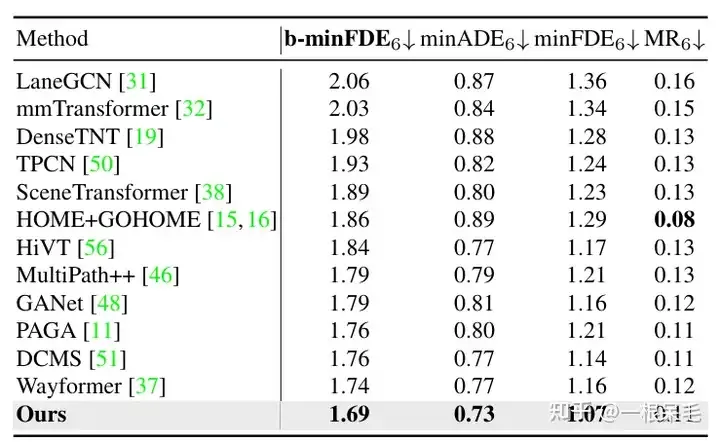 Forschung zur Szenenkodierung: Wenn die Ergebnisse der vorherigen Szenenkodierung wiederverwendet werden, kann die Inferenzzeit erheblich verkürzt werden. Die Anzahl der faktorisierten Aufmerksamkeitsinteraktionen zwischen dem Agenten und den Szeneninformationen nimmt zu und der Vorhersageeffekt wird ebenfalls besser, aber auch die Latenz steigt stark an, was abgewogen werden muss.
Forschung zur Szenenkodierung: Wenn die Ergebnisse der vorherigen Szenenkodierung wiederverwendet werden, kann die Inferenzzeit erheblich verkürzt werden. Die Anzahl der faktorisierten Aufmerksamkeitsinteraktionen zwischen dem Agenten und den Szeneninformationen nimmt zu und der Vorhersageeffekt wird ebenfalls besser, aber auch die Latenz steigt stark an, was abgewogen werden muss.  Forschung zu verschiedenen Vorgängen: Der Nachweis der Bedeutung der Verfeinerung und der Bedeutung der faktorisierten Aufmerksamkeit in verschiedenen Interaktionen ist unverzichtbar.
Forschung zu verschiedenen Vorgängen: Der Nachweis der Bedeutung der Verfeinerung und der Bedeutung der faktorisierten Aufmerksamkeit in verschiedenen Interaktionen ist unverzichtbar. 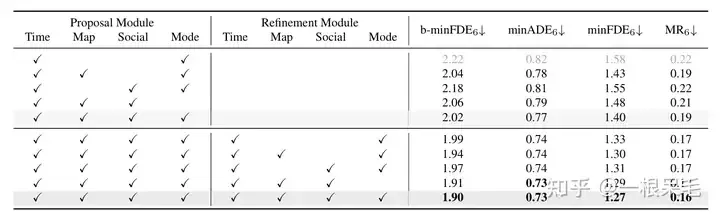
Das obige ist der detaillierte Inhalt vonTrajectory Prediction Series | Worüber spricht die weiterentwickelte Version von HiVT QCNet?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Auf Datentypen zugreifen
- Was wird zur Darstellung von Entitäten in der Access-Datenbank verwendet?
- Welche Software ist Dolby Access?
- Besprechen Sie den aktuellen Status und die Entwicklungstrends der Technologie zur Vorhersage der Flugbahn des autonomen Fahrens
- Mit welcher Methode kann man in Java Code schreiben, um über die Baidu Map API Flugbahnen auf der Karte zu zeichnen?