
Heim >Technologie-Peripheriegeräte >KI >APISR, ein zweidimensionales dediziertes hochauflösendes KI-Modell: online verfügbar, ausgewählt von CVPR
APISR, ein zweidimensionales dediziertes hochauflösendes KI-Modell: online verfügbar, ausgewählt von CVPR

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-04-07 17:07:091286Durchsuche
Animationswerke wie „Dragon Ball“, „Pokémon“, „Neon Genesis Evangelion“ und andere Animationen, die im letzten Jahrhundert ausgestrahlt wurden, sind Teil der Kindheitserinnerungen vieler Menschen. Sie haben uns Visionen voller Leidenschaft, Freundschaft und Träume beschert. Reise von. Irgendwann werden wir plötzlich den Drang verspüren, diese Kindheitserinnerungen noch einmal Revue passieren zu lassen, müssen aber leider feststellen, dass die Erkennungsrate dieser Kindheitserinnerungen sehr niedrig ist und es unmöglich ist, auf einem Breitbildfernseher ein gutes visuelles Erlebnis zu schaffen Es hindert uns daran, diese Kindheitserinnerungen mit Kindern zu teilen, die in einer digitalen Welt mit HD-Auflösung aufwachsen.
Für diese Art harter Konkurrenz (und potenziellen Markt) besteht eine Möglichkeit darin, eine Animationsfirma ein Remake produzieren zu lassen. Diese Aufgabe wird sowohl personell als auch finanziell kostspielig sein, kann aber mehr wert sein, als das Problem zu ignorieren und Marktanteile zu verlieren.
Die Leistung multimodaler künstlicher Intelligenz wird immer leistungsfähiger, und der Einsatz KI-basierter Super-Resolution-Technologie zur Verbesserung der Animationsauflösung ist zu einer Richtung geworden, die es wert ist, erkundet zu werden. Diese Technologie kann hochauflösende Bilder aus einer kleinen Anzahl von Bildern mit niedriger Auflösung rekonstruieren, wodurch Animationsbilder klarer und detaillierter werden. Diese Methode nutzt die Tiefe, indem sie eine große Anzahl von Beispieldaten trainiert.
Kürzlich hat ein gemeinsames Team der University of Michigan, der Yale University und der Zhejiang University eine Reihe recht praktischer neuer Methoden für Animationsaufgaben mit Superauflösung entwickelt, indem es den Animationsproduktionsprozess analysiert hat . Methode. Dazu gehören Datensätze, Modelle und einige Verbesserungen. Diese Forschung wurde in die CVPR 2024-Konferenz aufgenommen. Das Team stellte außerdem den relevanten Code als Open-Source-Lösung zur Verfügung und startete ein Testmodell auf Huggingface.

Papiertitel: APISR: Anime Production Inspired Real-World Anime Super-Resolution
Papieradresse: https://arxiv.org/pdf/2403.01598.pdf
Codeadresse: https ://github.com/Kiteretsu77/APISR
Testmodell: https://huggingface.co/spaces/HikariDawn/APISR
Das Bild unten zeigt, was diese Seite anhand des Screenshots der ersten Folge von versucht hat „Dragon Ball“ Dadurch ist der Effekt mit bloßem Auge sichtbar.

Darüber hinaus haben einige Leute versucht, diese Technologie zu verwenden, um die Videoauflösung zu verbessern, und die Ergebnisse sind großartig:
Animationsproduktionsprozess
Um die Innovation dieser neuen Methode zu verstehen, Werfen wir zunächst einen Blick darauf, wie Anime im Allgemeinen gemacht wird.
Zuerst skizziert ein Mensch auf Papier, das dann durch computergenerierte Bildverarbeitung (CGI) koloriert und verbessert wird. Diese bearbeiteten Skizzen werden dann zu einem Video verbunden.
Da der Zeichenprozess jedoch sehr arbeitsintensiv ist und das menschliche Auge nicht bewegungsempfindlich ist, besteht die branchenübliche Praxis beim Zusammenstellen von Videos darin, ein einzelnes Bild für mehrere aufeinanderfolgende Bilder wiederzuverwenden.
Bei der Analyse dieses Prozesses kam das gemeinsame Team nicht umhin, sich zu fragen, ob es notwendig ist, Videomodelle und Videodatensätze zu verwenden, um Animationsmodelle mit Superauflösung zu trainieren: Es ist durchaus möglich, Bilder mit Superauflösung zu bearbeiten und dann eine Verbindung herzustellen diese Bilder!
Daher beschlossen sie, bildbasierte Methoden und Datensätze zu verwenden, um ein einheitliches Superauflösungs- und Wiederherstellungs-Framework zu schaffen, das für Bilder und Videos geeignet ist.
Neue vorgeschlagene Methode
Bild-Superauflösungsdatensatz (API SR) für die Animationsproduktion
Das Team hat den API SR-Datensatz vorgeschlagen. Hier finden Sie eine kurze Einführung in seine Erfassungs- und Organisationsmethode. Diese Methode nutzt die Eigenschaften von Animationsvideos (siehe Abbildung 2) und kann die am wenigsten komprimierten und informativsten Frames aus dem Video auswählen.

I-Frame-basierte Bildsammlung: Bei der Videokomprimierung muss ein Kompromiss zwischen Videoqualität und Datengröße getroffen werden. Mittlerweile gibt es viele Videokomprimierungsstandards, von denen jeder sein eigenes komplexes technisches System hat, aber alle haben ein ähnliches Backbone-Design.
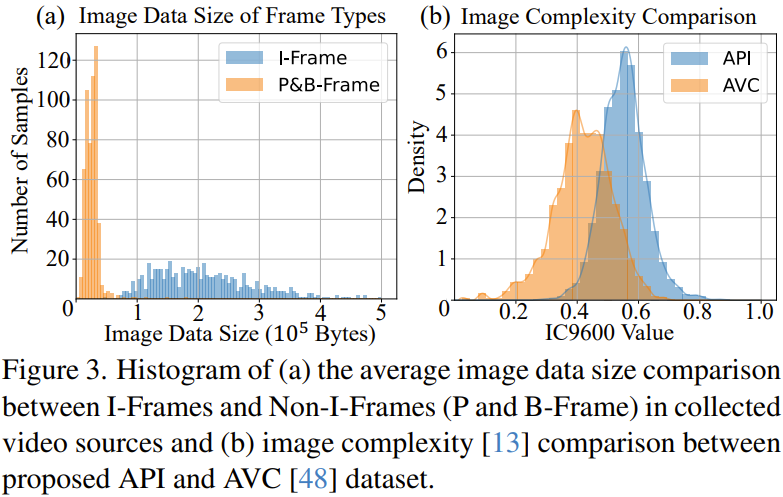
Diese Eigenschaften führen dazu, dass die Komprimierungsqualität jedes Frames unterschiedlich ist. Der Videokomprimierungsprozess bezeichnet eine Reihe von Schlüsselbildern (d. h. I-Frames) als einzelne Komprimierungseinheiten. In der Praxis ist das I-Frame das erste Bild, wenn sich die Szene ändert. Diese I-Frames können eine große Datenmenge belegen. Nicht-I-Frames (d. h. P-Frames und B-Frames) weisen höhere Komprimierungsraten auf. Sie müssen den I-Frame während des Komprimierungsprozesses als Referenz verwenden, um im Laufe der Zeit Änderungen vorzunehmen. Wie in Abbildung 3a dargestellt, ist in den vom Team gesammelten Animationsvideos die Datengröße von I-Frames im Allgemeinen höher als die von Nicht-I-Frames, und die Qualität von I-Frames ist tatsächlich höher. Daher nutzte das Team das Videoverarbeitungstool ffmpeg, um alle I-Frames aus der Videoquelle zu extrahieren und sie als ersten Datenpool zu verwenden.
Auswahl basierend auf der Bildkomplexität: Das Team überprüfte den anfänglichen I-Frame-Pool basierend auf Image Complexity Assessment (ICA), einer für Animationen besser geeigneten Metrik, siehe Abbildung 4.

API-Datensatz: Das Team hat manuell 562 hochwertige Anime-Videos gesammelt. Anschließend wurden die 10 Frames mit der höchsten Punktzahl aus jedem Video auf der Grundlage der beiden oben genannten Schritte gesammelt. Anschließend wurde eine Filterung durchgeführt, um ungeeignete Bilder zu entfernen, und schließlich wurde ein Datensatz mit 3740 hochwertigen Bildern erhalten. Abbildung 5 zeigt einige Bildbeispiele. Darüber hinaus können wir in Abbildung 3b auch die Vorteile des API-Datensatzes hinsichtlich der Bildkomplexität erkennen.

Zurück zur ursprünglichen 720P-Auflösung: Durch die Untersuchung des Animationsproduktionsprozesses können wir erkennen, dass die meisten Animationsproduktionen das 720P-Format verwenden (d. h. das Bild ist 720 Pixel hoch). In realen Szenarien werden Animes jedoch häufig fälschlicherweise auf 1080P oder andere Formate hochskaliert, um Multimediaformate zu standardisieren. Das Team stellte experimentell fest, dass die Größenänderung aller Anime-Bilder auf natives 720P die von den Machern gewünschte Funktionsdichte sowie engere handgezeichnete Anime-Linien und CGI-Informationen lieferte.
Ein praktisches Degradationsmodell für Animationen
Bei realen Superauflösungsaufgaben ist das Design des Degradationsmodells sehr wichtig. Basierend auf Degradationsmodellen höherer Ordnung und einem aktuellen bildbasierten Videokomprimierungs-Wiederherstellungsmodell schlug das Team zwei Verbesserungen vor, die verzerrte handgezeichnete Linien und verschiedene Komprimierungsartefakte wiederherstellen und außerdem die Darstellung des Degradationsmodells verbessern können. Abbildung 6a veranschaulicht dieses Degradationsmodell.
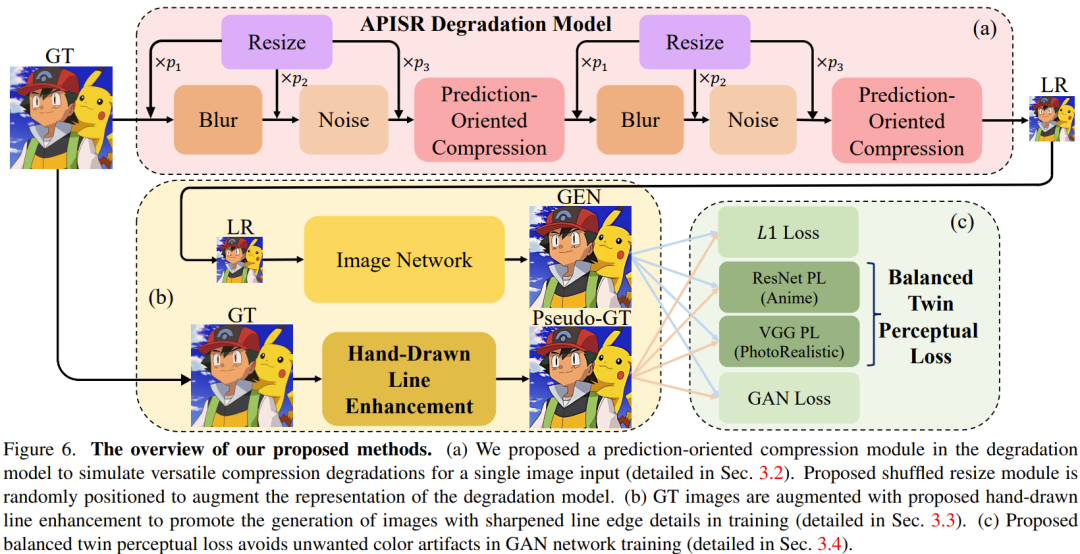
Vorhersageorientierte Komprimierung: Für die Aufgabe der Animationswiederherstellung von Videokomprimierungsartefakten stellt die Verwendung von Bildverschlechterungsmodellen ein schwieriges Problem dar. Dies liegt daran, dass die Komprimierungsmethode des JPEG-Bildformats und das Prinzip der Videokomprimierung unterschiedlich sind.
Um solche Schwierigkeiten zu bewältigen, entwarf das Team ein vorhersageorientiertes Komprimierungsmodell, das im Bildverschlechterungsmodell verwendet wird. Dieses Modul erfordert einen Videokomprimierungsalgorithmus, um einen einzelnen Eingaberahmen zu komprimieren.
Mit diesem Ansatz ist das Bildverschlechterungsmodell in der Lage, Komprimierungsartefakte zu synthetisieren, die denen ähneln, die bei der typischen Multi-Frame-Videokomprimierung beobachtet werden, wie in Abbildung 7 dargestellt. Durch die Einspeisung dieser synthetisierten Bilder in ein hochauflösendes Bildnetzwerk kann das System dann effektiv die Muster verschiedener Komprimierungsartefakte lernen und diese wiederherstellen.

Mischen Sie die Reihenfolge der Größenänderungsmodule: Entartete Modelle im Bereich der realen Superauflösung müssen Unschärfe-, Größenänderungs-, Rausch- und Komprimierungsmodule berücksichtigen. Unschärfe, Rauschen und Komprimierung sind reale Artefakte, die durch klare mathematische Modelle oder Algorithmen synthetisiert werden können. Die Logik des Größenänderungsmoduls ist jedoch völlig anders. Die Größenänderung ist kein Teil der natürlichen Bilderzeugung, sondern wird speziell für die Superauflösung paarweiser Datensätze eingeführt. Daher war das bisherige Modul zur Größenänderung mit fester Größe nicht sehr geeignet. Das Team schlug eine robustere und effizientere Lösung vor, bei der Größenänderungsvorgänge zufällig in verschiedenen Reihenfolgen innerhalb des degenerierten Modells platziert werden.
Handgezeichnete Linien für Animationen verbessern
Das Team hat die Wahl, die geschärften handgezeichneten Linieninformationen direkt zu extrahieren und sie mit der Grundwahrheit (GT/Ground-Truth) zu verschmelzen, um Pseudo-GT zu bilden. Durch die Einführung dieser gezielten, verbesserten Pseudo-GT in den Super-Resolution-Trainingsprozess kann das Netzwerk scharfe handgezeichnete Linien erzeugen, ohne zusätzliche neuronale Netzwerkmodule oder separate Nachbearbeitungsnetzwerke einzuführen.
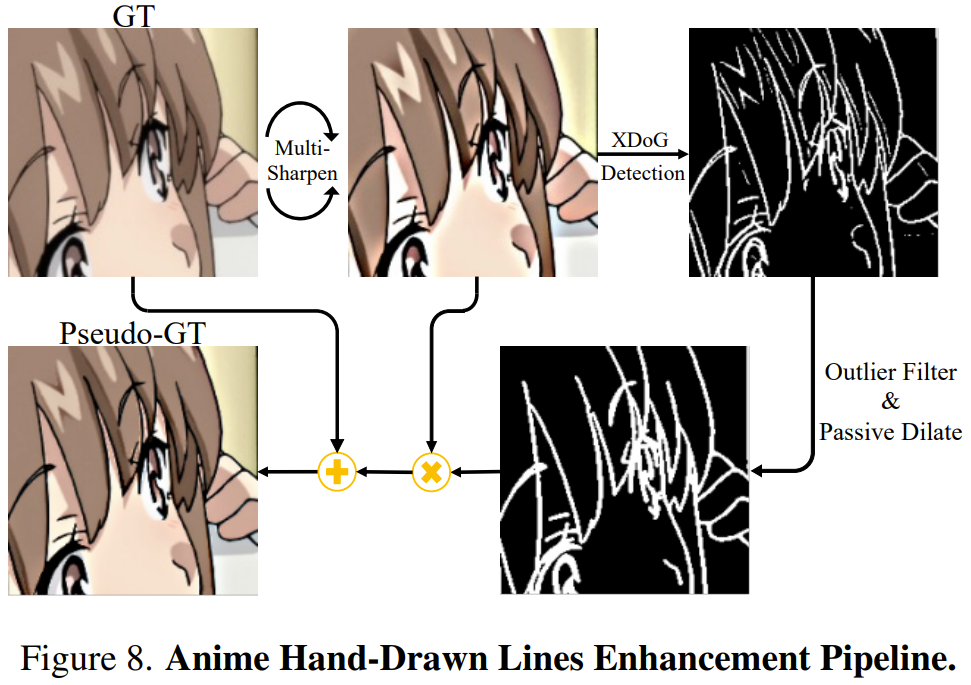
Um handgezeichnete Linien besser zu extrahieren, verwendete das Team XDoG, einen Skizzenextraktionsalgorithmus, der auf dem Pixel-für-Pixel-Gaußschen Kernel basiert und scharfe Kantenkarten von GT extrahieren kann.
Allerdings leiden XDoG-Kantenkarten unter übermäßigem Rauschen, da sie Ausreißerpixel und unterbrochene Liniendarstellungen enthalten. Um dieses Problem zu lösen, schlug das Team eine Ausreißerfiltertechnik gepaart mit einer maßgeschneiderten passiven Dilatationsmethode vor. Auf diese Weise erhält man eine kohärentere und ungestörtere Darstellung der handgezeichneten Linien.
Das Team hat experimentell herausgefunden, dass eine übermäßige Schärfung vorverarbeiteter GT dazu führen kann, dass handgezeichnete Linienkanten besser sichtbar sind als andere irrelevante Schattenkantendetails, sodass der Ausreißerfilter ihre Unterschiede leichter erkennen kann. Zu diesem Zweck schlug das Team vor, zunächst drei Runden Entschärfungs- und Maskierungsvorgänge am GT durchzuführen. Abbildung 8 zeigt eine einfache Darstellung dieses Prozesses.
Ausgewogener dualer Wahrnehmungsverlust für Animationen
Es besteht auch das Problem unerwünschter Farbartefakte, die hauptsächlich auf Inkonsistenzen zwischen dem Generator und dem Wahrnehmungsverlust im Datenbereich während des Trainings zurückzuführen sind.
Um dieses Problem zu lösen und die Mängel früherer Methoden auszugleichen, bestand der Ansatz des Teams darin, ein vorab trainiertes ResNet zu verwenden, das auf die Klassifizierungsaufgabe für Animationsziele im Danbooru-Datensatz trainiert wurde. Der Danbooru-Datensatz ist eine Anime-Illustrationsdatenbank mit umfangreichen und umfangreichen Anmerkungen. Da es sich bei diesem vorab trainierten Netzwerk um ResNet50 und nicht um VGG handelt, schlug das Team auch einen ähnlichen Mid-Layer-Vergleich vor.
Wenn Sie jedoch nur ResNet-basierte Verluste verwenden, kann es zu schlechten visuellen Ergebnissen kommen. Dies ist auf die inhärente Verzerrung im Danbooru-Datensatz zurückzuführen – die meisten Bilder in diesem Datensatz sind menschliche Gesichter oder relativ einfache Illustrationen. Daher überlegte das Team und beschloss, reale Funktionen als Hilfsmittel zu nutzen, um den ResNet-basierten Wahrnehmungsverlust während des Trainings zu steuern. Diese Methode führt zu einem optisch ansprechenden Bild und löst gleichzeitig das Problem unerwünschter Farben.
Experiment
Implementierungsdetails
Im Experiment verwendete das Team den neu vorgeschlagenen API-Datensatz als Trainingsdatensatz für das Bildnetzwerk. Für das Bildnetzwerk wird eine winzige Version von GRL mit einem nächstgelegenen Faltungs-Upsampling-Modul verwendet.
Weitere Details und Parameter finden Sie im Originalpapier.
Vergleich mit den derzeit besten Methoden
Das Team verglich die neu vorgeschlagene APISR quantitativ und qualitativ mit einigen anderen fortschrittlichen Methoden, darunter Real-ESRGAN, BSRGAN, RealBasicVSR, AnimeSR und VQD-SR.
Quantitativer Vergleich
Wie in Tabelle 1 gezeigt, hat das neue Modell mit nur 1,03 Millionen Parametern die kleinste Netzwerkgröße, aber seine Leistung bei allen Indikatoren übertrifft alle anderen Methoden.
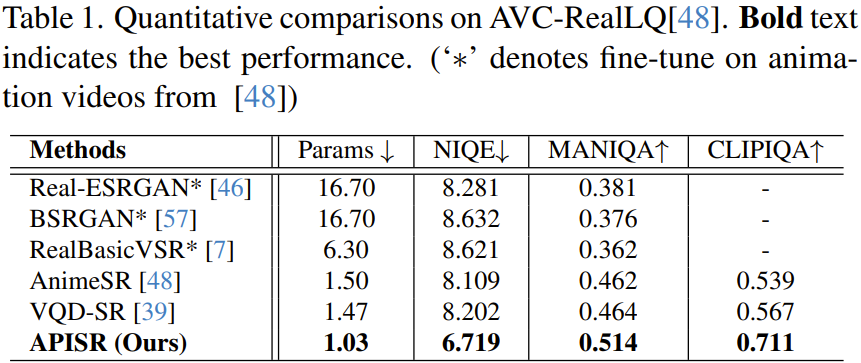
Das Team betonte insbesondere die Rolle vorhersageorientierter Kompressionsmodelle.
Darüber hinaus ist darauf hinzuweisen, dass die neue Methode solche Ergebnisse nur mit der Trainingsmusterkomplexität von 13,3 % bzw. 25 % für AnimeSR und VQDSR erzielte. Dies ist hauptsächlich auf die Einführung der Bewertung der Bildkomplexität im Sortierprozess des Datensatzes zurückzuführen, die den Effekt des Erlernens der Animationsbilddarstellung durch Auswahl informationsreicher Bilder verbessern kann. Darüber hinaus ist dank des neu entwickelten expliziten Degradationsmodells kein Training auf der Seite des Degradationsmodells erforderlich.
Qualitativer Vergleich
Wie in Abbildung 10 dargestellt, ist die mit APISR erzielte visuelle Qualität weitaus besser als bei anderen Methoden.

Das Team führte außerdem eine Ablationsstudie durch, um die Wirksamkeit des neuen Datensatzes, des Degradationsmodells und des Verlustdesigns zu überprüfen. Einzelheiten finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonAPISR, ein zweidimensionales dediziertes hochauflösendes KI-Modell: online verfügbar, ausgewählt von CVPR. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!