
Heim >Technologie-Peripheriegeräte >KI >Über GPT-4 hinaus wurde das große Modell des Stanford-Teams, das auf Mobiltelefonen ausgeführt werden kann, mit über 2.000 Downloads über Nacht populär
Über GPT-4 hinaus wurde das große Modell des Stanford-Teams, das auf Mobiltelefonen ausgeführt werden kann, mit über 2.000 Downloads über Nacht populär

- 王林nach vorne
- 2024-04-07 16:19:011494Durchsuche
Bei der Implementierung großer Modelle ist die endseitige KI eine sehr wichtige Richtung.
Vor kurzem wurde Octopus v2 von Forschern der Stanford University veröffentlicht und erfreut sich großer Beliebtheit in der Entwickler-Community. Das Modell wurde über Nacht über 2.000 Mal heruntergeladen.
Der Octopus v2 mit 2 Milliarden Parametern kann auf Smartphones, Autos, PCs usw. ausgeführt werden, übertrifft GPT-4 in Bezug auf Genauigkeit und Latenz und reduziert die Kontextlänge um 95 %. Darüber hinaus ist Octopus v2 36-mal schneller als das Llama7B + RAG-Schema. 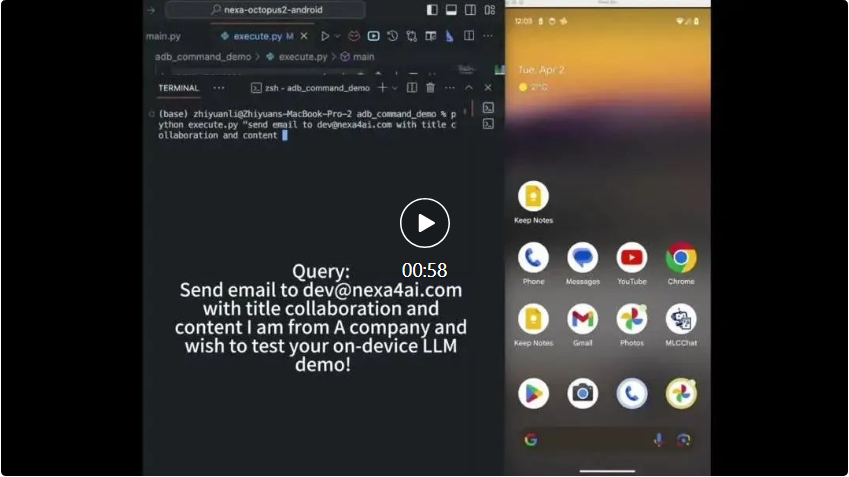

Papier: Octopus v2: On-Device-Sprachmodell für Superagenten
Papieradresse: https://arxiv.org/abs/2404.01744
Homepage des Modells: https://huggingface .co/NexaAIDev/Octopus-v2
Modellübersicht
Octopus-V2-2B+ ist ein Open-Source-Sprachmodell mit 2 Milliarden Parametern, maßgeschneidert für die Android-API. Es läuft nahtlos auf Android-Geräten und erweitert seinen Nutzen auf eine Vielzahl von Anwendungen, die von der Android-Systemverwaltung bis zur Orchestrierung mehrerer Geräte reichen.
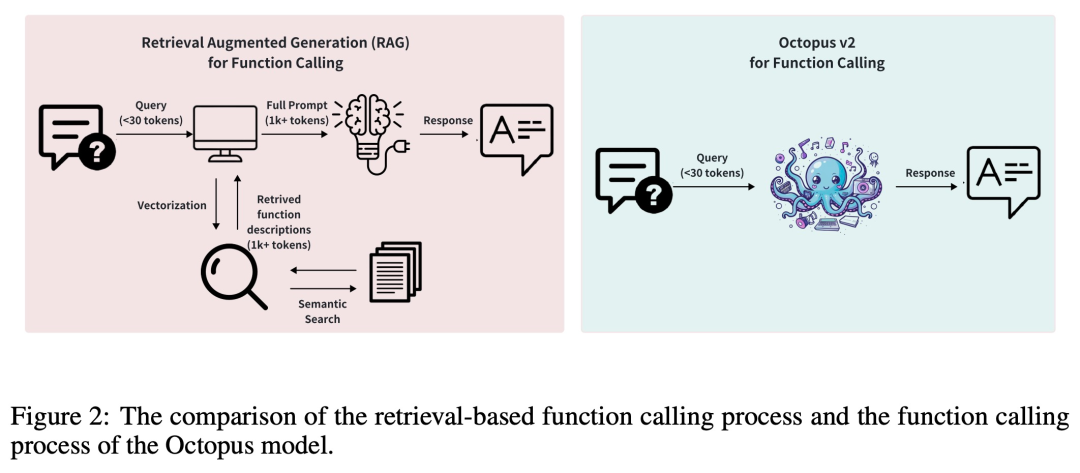
Normalerweise erfordern RAG-Methoden (Retrieval Augmented Generation) detaillierte Beschreibungen potenzieller Funktionsparameter (manchmal sind bis zu Zehntausende Eingabe-Tokens erforderlich). Auf dieser Grundlage führt Octopus-V2-2B eine einzigartige Funktions-Token-Strategie in den Trainings- und Inferenzphasen ein, die es ihm nicht nur ermöglicht, ein mit GPT-4 vergleichbares Leistungsniveau zu erreichen, sondern auch die Inferenzgeschwindigkeit erheblich verbessert und die RAG-basierte übertrifft Dies macht es besonders vorteilhaft für Edge-Computing-Geräte.
Octopus-V2-2B ist in der Lage, einzelne, verschachtelte und parallele Funktionsaufrufe in einer Vielzahl komplexer Szenarien zu generieren.
Datensatz
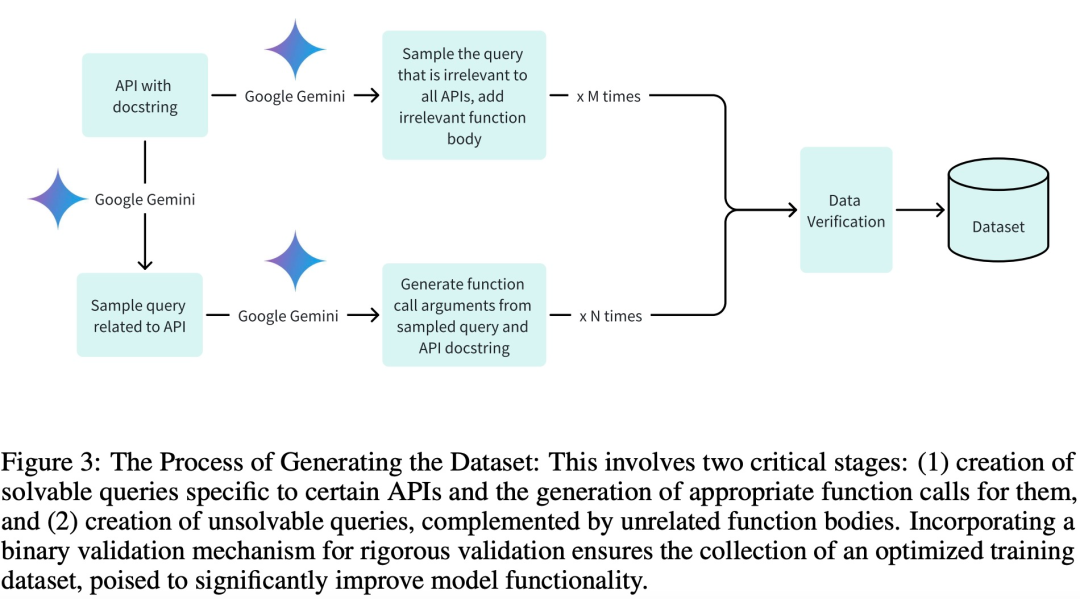
Um qualitativ hochwertige Datensätze für die Trainings-, Validierungs- und Testphasen zu übernehmen und insbesondere ein effizientes Training zu erreichen, erstellte das Forschungsteam den Datensatz mit drei Schlüsselphasen:
Generieren relevanter Abfragen und ihre zugehörigen Funktionsaufrufargumente;
Irrelevante Abfragegenerierung durch entsprechende Funktionskomponenten;
Binäre Verifizierungsunterstützung über Google Gemini.
Das Forschungsteam hat 20 Android-API-Beschreibungen für Trainingsmodelle geschrieben. Hier ist ein Beispiel für eine Android-API-Beschreibung:
def get_trending_news (category=None, region='US', language='en', max_results=5):"""Fetches trending news articles based on category, region, and language.Parameters:- category (str, optional): News category to filter by, by default use None for all categories. Optional to provide.- region (str, optional): ISO 3166-1 alpha-2 country code for region-specific news, by default, uses 'US'. Optional to provide.- language (str, optional): ISO 639-1 language code for article language, by default uses 'en'. Optional to provide.- max_results (int, optional): Maximum number of articles to return, by default, uses 5. Optional to provide.Returns:- list [str]: A list of strings, each representing an article. Each string contains the article's heading and URL. """
Modellentwicklung und -training
Diese Studie verwendet das Google Gemma-2B-Modell als vorab trainiertes Modell im Framework und wendet zwei verschiedene Trainingsmethoden an: das vollständige Modelltraining und LoRA-Modelltraining.
Im vollständigen Modelltraining verwendet diese Studie den AdamW-Optimierer, die Lernrate ist auf 5e-5 eingestellt, die Anzahl der Aufwärmschritte ist auf 10 eingestellt und es wird ein linearer Lernratenplaner verwendet.
Das LoRA-Modelltraining verwendet denselben Optimierer und dieselbe Lernratenkonfiguration wie das vollständige Modelltraining, der LoRA-Rang ist auf 16 eingestellt und LoRA wird auf die folgenden Module angewendet: q_proj, k_proj, v_proj, o_proj, up_proj, down_proj. Unter diesen ist der LoRA-Alpha-Parameter auf 32 eingestellt.
Bei beiden Trainingsmethoden ist die Anzahl der Epochen auf 3 eingestellt.
Verwenden Sie den folgenden Code, um das Octopus-V2-2B-Modell auf einer einzelnen GPU auszuführen.
from transformers import AutoTokenizer, GemmaForCausalLMimport torchimport timedef inference (input_text):start_time = time.time ()input_ids = tokenizer (input_text, return_tensors="pt").to (model.device)input_length = input_ids ["input_ids"].shape [1]outputs = model.generate (input_ids=input_ids ["input_ids"], max_length=1024,do_sample=False)generated_sequence = outputs [:, input_length:].tolist ()res = tokenizer.decode (generated_sequence [0])end_time = time.time ()return {"output": res, "latency": end_time - start_time}model_id = "NexaAIDev/Octopus-v2"tokenizer = AutoTokenizer.from_pretrained (model_id)model = GemmaForCausalLM.from_pretrained (model_id, torch_dtype=torch.bfloat16, device_map="auto")input_text = "Take a selfie for me with front camera"nexa_query = f"Below is the query from the users, please call the correct function and generate the parameters to call the function.\n\nQuery: {input_text} \n\nResponse:"start_time = time.time () print ("nexa model result:\n", inference (nexa_query)) print ("latency:", time.time () - start_time,"s")Bewertung
Octopus-V2-2B zeigte in Benchmark-Tests eine überlegene Inferenzgeschwindigkeit und war 36-mal schneller als die „Llama7B + RAG-Lösung“ auf einer einzelnen A100-GPU. Darüber hinaus ist Octopus-V2-2B 168 % schneller im Vergleich zu GPT-4-turbo, das auf geclusterten A100/H100-GPUs basiert. Dieser Effizienzdurchbruch ist auf das funktionale Token-Design von Octopus-V2-2B zurückzuführen.
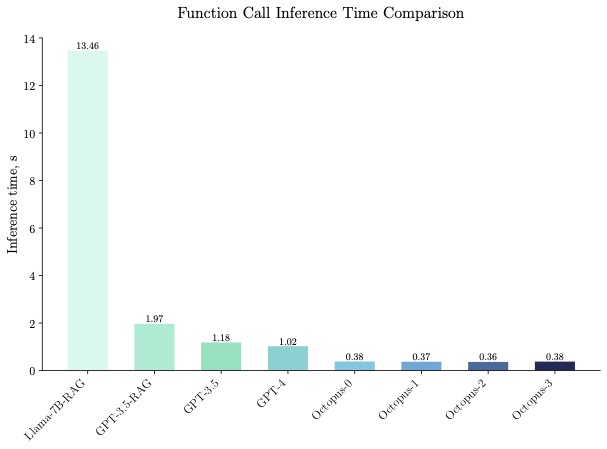
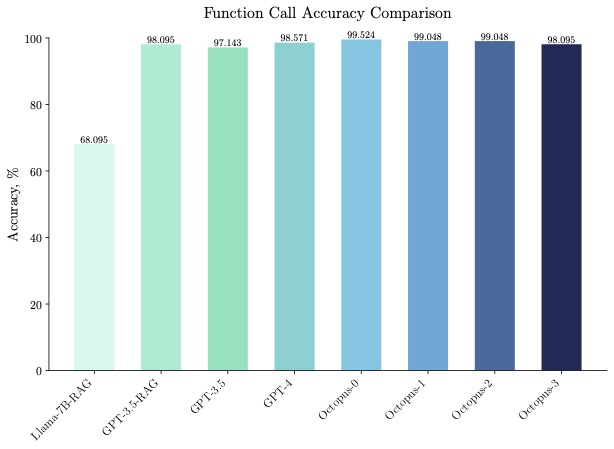
Octopus-V2-2B schneidet nicht nur in puncto Geschwindigkeit, sondern auch in puncto Genauigkeit gut ab und übertrifft die „Llama7B + RAG-Lösung“ in puncto Funktionsaufrufgenauigkeit um 31 %. Octopus-V2-2B erreicht eine Funktionsaufrufgenauigkeit, die mit GPT-4 und RAG + GPT-3.5 vergleichbar ist.
Interessierte Leser können den Originaltext des Artikels lesen, um mehr über den Forschungsinhalt zu erfahren.
Das obige ist der detaillierte Inhalt vonÜber GPT-4 hinaus wurde das große Modell des Stanford-Teams, das auf Mobiltelefonen ausgeführt werden kann, mit über 2.000 Downloads über Nacht populär. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Neue Regeln für Oktober sind da! Einbeziehung neuer Verkehrszeichen, Industrie der künstlichen Intelligenz usw.
- Roboter können auch fühlen: Die Stanford University baut elektronische Haut, die mit dem Gehirn kommunizieren kann
- Lujiazui Digital Intelligence World konzentriert sich auf das digitale Geschäftsökosystem und die Metaverse-Branche und ist bestrebt, einen Branchencluster für Datenelemente zu schaffen
- [Trend Weekly] Globaler Entwicklungstrend der Künstliche-Intelligenz-Branche: OpenAI reichte beim US-Patentamt eine „GPT-5'-Markenanmeldung ein
- Xiaoyu Yilian trat auf der China International Intelligent Industry Expo auf