
Heim >Technologie-Peripheriegeräte >KI >Wie man LoRA-Code von Grund auf schreibt, finden Sie hier in einer Anleitung
Wie man LoRA-Code von Grund auf schreibt, finden Sie hier in einer Anleitung

- 王林nach vorne
- 2024-03-20 15:06:45605Durchsuche
LoRA (Low-Rank Adaptation) ist eine beliebte Technik zur Feinabstimmung großer Sprachmodelle (LLM). Diese Technologie wurde ursprünglich von Microsoft-Forschern vorgeschlagen und in das Papier „LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS“ aufgenommen. LoRA unterscheidet sich von anderen Techniken dadurch, dass es sich nicht auf die Anpassung aller Parameter des neuronalen Netzwerks, sondern auf die Aktualisierung einer kleinen Anzahl von Matrizen mit niedrigem Rang konzentriert, wodurch der zum Trainieren des Modells erforderliche Rechenaufwand erheblich reduziert wird.
Da die Feinabstimmungsqualität von LoRA mit der Feinabstimmung eines vollständigen Modells vergleichbar ist, bezeichnen viele Menschen diese Methode als Feinabstimmungsartefakt. Seit ihrer Veröffentlichung waren viele Menschen neugierig auf die Technologie und wollten Code schreiben, um die Forschung besser zu verstehen. In der Vergangenheit war der Mangel an ordnungsgemäßer Dokumentation ein Problem, aber jetzt haben wir Tutorials, die Ihnen helfen.
Der Autor dieses Tutorials ist Sebastian Raschka, ein bekannter Forscher für maschinelles Lernen und KI. Er sagte, dass LoRA unter den verschiedenen effektiven LLM-Feinabstimmungsmethoden immer noch seine erste Wahl sei. Zu diesem Zweck hat Sebastian einen Blog „Code LoRA From Scratch“ geschrieben, um LoRA von Grund auf zu erstellen. Seiner Meinung nach ist dies eine gute Lernmethode.
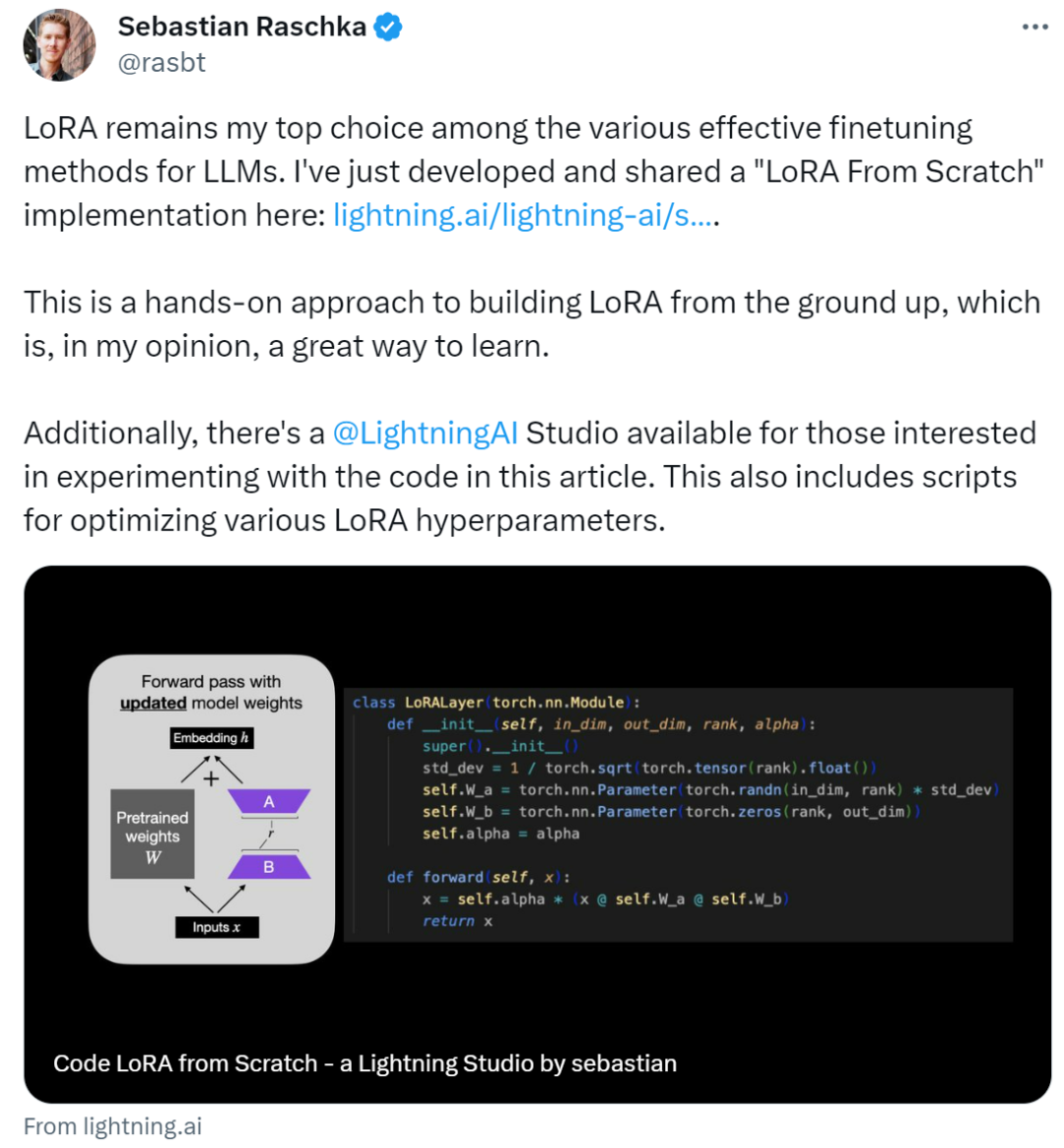
In diesem Artikel wird die Low-Rank-Adaption (LoRA) vorgestellt, indem Sebastian das DistilBERT-Modell im Experiment verfeinert und auf die Klassifizierungsaufgabe angewendet hat.
Die Vergleichsergebnisse zwischen der LoRA-Methode und der herkömmlichen Feinabstimmungsmethode zeigen, dass die LoRA-Methode eine Testgenauigkeit von 92,39 % erreicht, was der Feinabstimmung nur der letzten Schichten des Modells (86,22 % Testgenauigkeit) überlegen ist ) Leistung. Dies zeigt, dass die LoRA-Methode offensichtliche Vorteile bei der Optimierung der Modellleistung bietet und die Generalisierungsfähigkeit und Vorhersagegenauigkeit des Modells besser verbessern kann. Dieses Ergebnis unterstreicht die Bedeutung der Anwendung fortschrittlicher Techniken und Methoden beim Modelltraining und -tuning, um bessere Leistung und Ergebnisse zu erzielen. Werfen wir einen Blick darauf, indem wir vergleichen, wie
Sebastian es erreicht.
Schreiben Sie LoRA von Grund auf
Das Erklären einer LoRA-Ebene im Code sieht folgendermaßen aus:
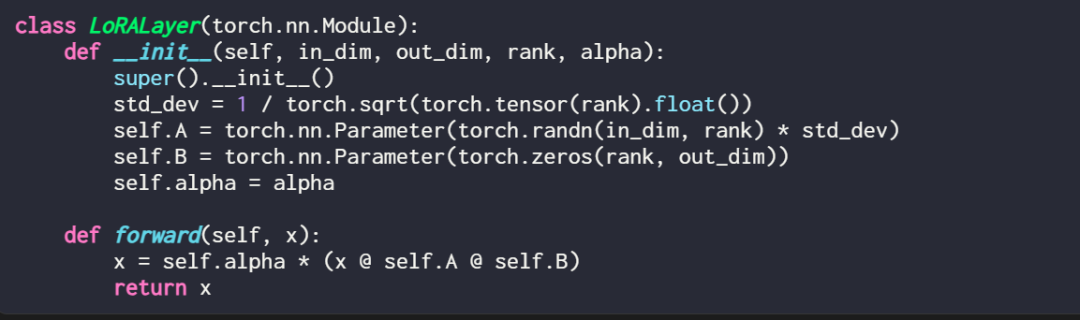
wobei in_dim die Eingabedimension der Ebene ist, die Sie mit LoRA ändern möchten, entsprechend out_dim die Ausgabedimension der Ebene. Dem Code wird außerdem ein Hyperparameter hinzugefügt, der Skalierungsfaktor Alpha. Höhere Alpha-Werte bedeuten größere Anpassungen des Modellverhaltens, niedrigere Werte bedeuten das Gegenteil. Darüber hinaus initialisiert dieser Artikel Matrix A mit kleineren Werten aus einer Zufallsverteilung und Matrix B mit Nullen.
Es ist erwähnenswert, dass LoRA normalerweise in der linearen (Feedforward-)Schicht eines neuronalen Netzwerks ins Spiel kommt. Beispielsweise kann für ein einfaches PyTorch-Modell oder -Modul mit zwei linearen Schichten (dies könnte beispielsweise ein Feedforward-Modul des Transformer-Blocks sein) die Vorwärtsmethode wie folgt ausgedrückt werden:

Bei Verwendung von LoRA ist es Es ist üblich, der Ausgabe dieser linearen Ebenen LoRA-Updates hinzuzufügen. Der resultierende Code lautet wie folgt:

Wenn Sie LoRA durch Ändern eines vorhandenen PyTorch-Modells implementieren möchten, besteht eine einfache Möglichkeit darin, jede lineare Ebene zu aktualisieren wird durch eine LinearWithLoRA-Schicht ersetzt:
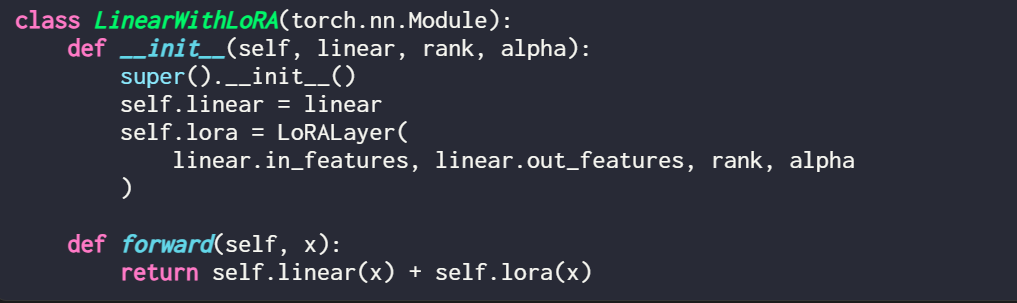
Diese Konzepte sind in der folgenden Abbildung zusammengefasst:
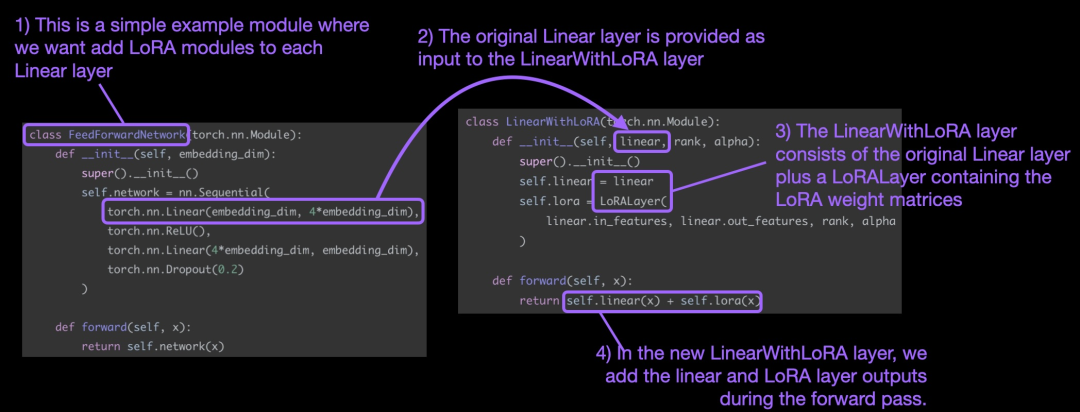
Um LoRA anzuwenden, ersetzt dieser Artikel die vorhandenen linearen Schichten im neuronalen Netzwerk durch eine kombinierte Die ursprüngliche lineare Ebene und die LinearWithLoRA-Ebene des LoRALayers.
So beginnen Sie mit der Verwendung von LoRA zur Feinabstimmung
LoRA kann für Modelle wie GPT oder Bildgenerierung verwendet werden. Zur einfachen Erklärung verwendet dieser Artikel ein kleines BERT-Modell (DistilBERT) zur Textklassifizierung.

Da dieser Artikel nur neue LoRA-Gewichte trainiert, müssen Sie „requires_grad“ aller trainierbaren Parameter auf „False“ setzen, um alle Modellparameter einzufrieren:

Als nächstes verwenden Sie print (model), um das Modell zu überprüfen Struktur von:

Aus der Ausgabe ist ersichtlich, dass das Modell aus 6 Transformatorschichten besteht, einschließlich linearer Schichten:

Darüber hinaus verfügt das Modell über zwei lineare Ausgabeschichten:

LoRA kann optional für diese linearen Schichten aktiviert werden, indem die folgende Zuweisungsfunktion und Schleife definiert wird:
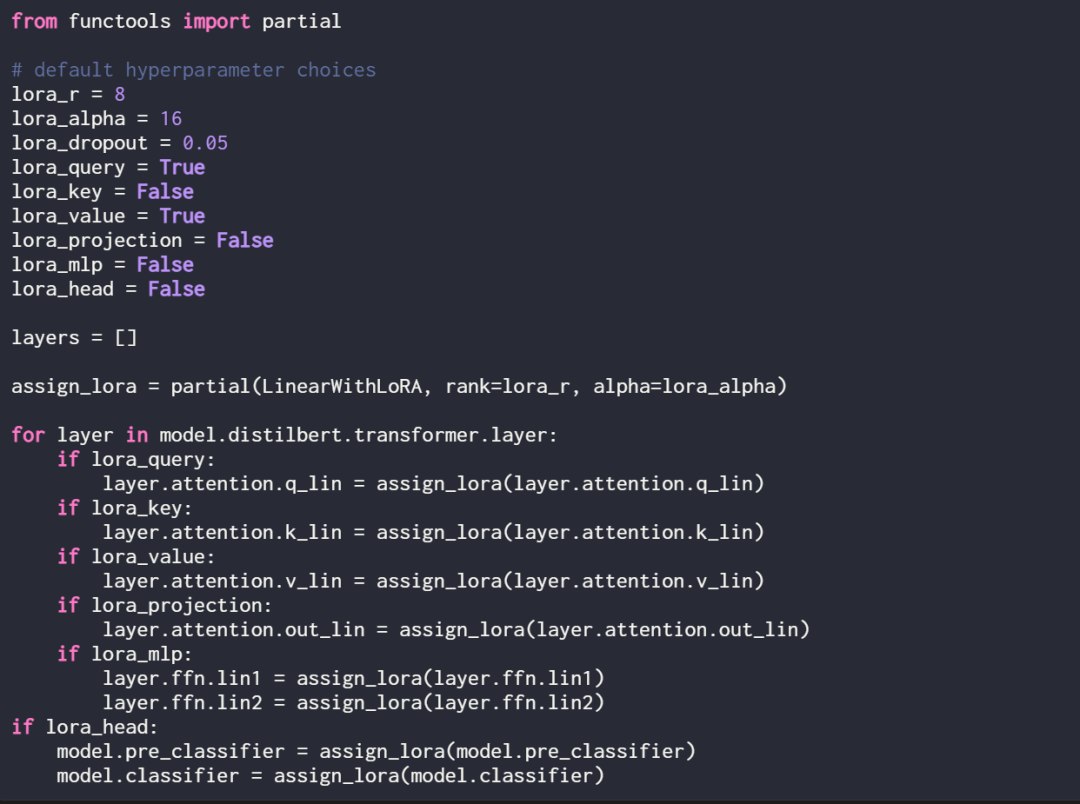
Überprüfen Sie das Modell erneut mit print (model), um seine aktualisierte Struktur zu überprüfen:
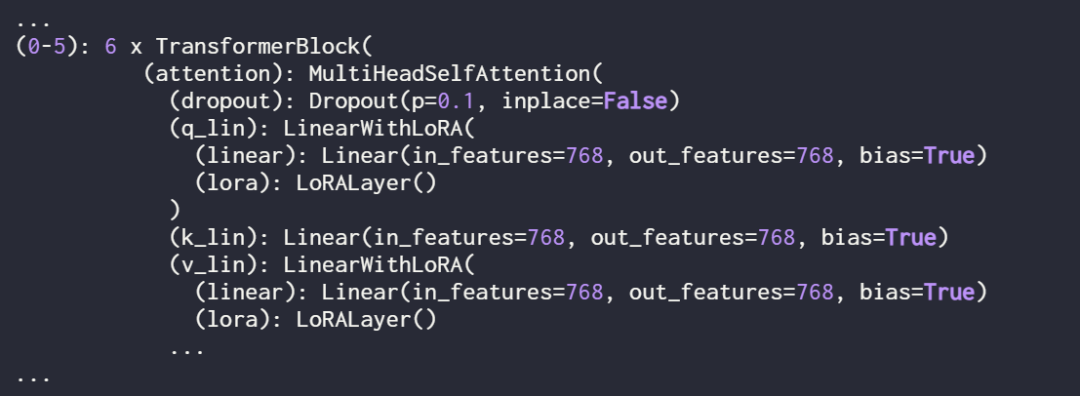
Wie Sie oben sehen können, wurde die Ebene „Linear“ erfolgreich durch die Ebene „LinearWithLoRA“ ersetzt.
Wenn Sie das Modell mit den oben gezeigten Standard-Hyperparametern trainieren, führt dies zu der folgenden Leistung im IMDb-Klassifizierungsdatensatz für Filmrezensionen:
- Trainingsgenauigkeit: 92,15 %
- Validierungsgenauigkeit: 89,98 %
- Testgenauigkeit: 89,44 %
Im nächsten Abschnitt vergleicht dieses Papier diese LoRA-Feinabstimmungsergebnisse mit traditionellen Feinabstimmungsergebnissen.
Vergleich mit herkömmlichen Feinabstimmungsmethoden
Im vorherigen Abschnitt erreichte LoRA unter Standardeinstellungen eine Testgenauigkeit von 89,44 %. Wie schneidet dies im Vergleich zu herkömmlichen Feinabstimmungsmethoden ab?
Zum Vergleich wurde in diesem Artikel ein weiteres Experiment durchgeführt, bei dem das Training des DistilBERT-Modells als Beispiel genommen wurde, aber während des Trainings nur die letzten beiden Schichten aktualisiert wurden. Dies erreichten die Forscher, indem sie alle Modellgewichte einfrierten und dann die beiden linearen Ausgabeschichten entsperrten:
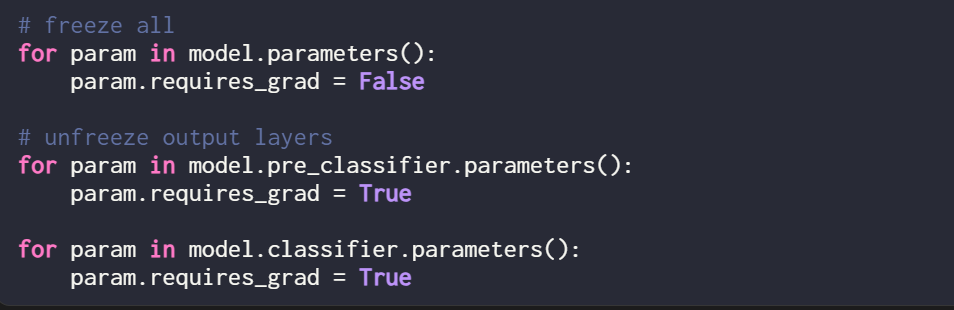
Die Klassifizierungsleistung, die durch das Training nur der letzten beiden Schichten erzielt wurde, ist wie folgt:
- Trainingsgenauigkeit: 86,68 %
- Validierungsgenauigkeit: 87,26 %
- Testgenauigkeit: 86,22 %
Die Ergebnisse zeigen, dass LoRA eine bessere Leistung erbringt als die herkömmliche Methode zur Feinabstimmung der letzten beiden Schichten, aber viermal weniger Parameter verwendet . Die Feinabstimmung aller Ebenen erforderte die Aktualisierung von 450-mal mehr Parametern als beim LoRA-Setup, verbesserte die Testgenauigkeit jedoch nur um 2 %.
LoRA-Konfiguration optimieren
Die oben genannten Ergebnisse werden alle von LoRA unter den Standardeinstellungen durchgeführt. Die Hyperparameter sind wie folgt:

Wenn der Benutzer verschiedene Hyperparameter-Konfigurationen ausprobieren möchte Verwenden Sie den folgenden Befehl:

Die optimale Hyperparameterkonfiguration lautet jedoch wie folgt:

Unter dieser Konfiguration lautet das Ergebnis:
- Validierungsgenauigkeit: 92,96 %
- Testgenauigkeit: 92,39 %
Es ist erwähnenswert, dass, obwohl es in der LoRA-Einstellung nur einen kleinen Satz trainierbarer Parameter gibt (500k VS 66M), die Genauigkeit ist immer noch etwas höher als die Genauigkeit, die mit vollständiger Feinabstimmung erreicht wird.
Originallink: https://lightning.ai/lightning-ai/studios/code-lora-from-scratch?cnotallow=f5fc72b1f6eeeaf74b648b2aa8aaf8b6
Das obige ist der detaillierte Inhalt vonWie man LoRA-Code von Grund auf schreibt, finden Sie hier in einer Anleitung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So konvertieren Sie ai in ps
- So rufen Sie die AI-Attributleiste auf
- Was ist KI?
- Zurück in die Zukunft! Dieser Programmierer nutzte Kindheitstagebücher zum Trainieren der KI und nutzte GPT-3, um einen Dialog mit seinem „vergangenen Ich' zu erreichen.
- Maßgeschneidertes Training von Deep-Learning-Modellen mithilfe von Transfer-Learning-Techniken