
Heim >Technologie-Peripheriegeräte >KI >OpenAI hat den Open-Source-Transformer-Debugger offiziell angekündigt! Sie müssen keinen Code schreiben, jeder kann die LLM-Blackbox knacken
OpenAI hat den Open-Source-Transformer-Debugger offiziell angekündigt! Sie müssen keinen Code schreiben, jeder kann die LLM-Blackbox knacken

- PHPznach vorne
- 2024-03-12 15:16:191248Durchsuche
AGI rückt wirklich näher!
Um sicherzustellen, dass Menschen nicht durch KI getötet werden, hat OpenAI nie damit aufgehört, die Blackbox des neuronalen Netzwerks/Transfomers zu entschlüsseln.
Im Mai letzten Jahres veröffentlichte das OpenAI-Team eine schockierende Entdeckung: GPT-4 kann tatsächlich 300.000 Neuronen von GPT-2 erklären!
Internetnutzer riefen aus, dass Weisheit so sei.
 Bilder
Bilder
Gerade hat der Leiter des OpenAI-Super-Alignment-Teams offiziell angekündigt, dass sie den intern verwendeten Transformer Debugger als Open Source veröffentlichen werden.
Kurz gesagt, Forscher können TDB-Tools verwenden, um die interne Struktur von Transformer zu analysieren und das spezifische Verhalten kleiner Modelle zu untersuchen.
 Bilder
Bilder
Mit anderen Worten, mit diesem TDB-Tool kann es uns helfen, AGI in Zukunft zu analysieren und zu analysieren!
 Bilder
Bilder
Der Transformer-Debugger kombiniert spärliche Autoencoder mit der von OpenAI entwickelten „automatischen Interpretierbarkeit“, also der Verwendung großer Modelle, um die Technologie kleiner Modelle automatisch zu erklären.
Link: OpenAI explodiert neues Werk: GPT-4 knackt GPT-2-Gehirn! Alle 300.000 Neuronen wurden gesehen Es ist erwähnenswert, dass Forscher die interne Struktur von LLM schnell erkunden können, ohne Code schreiben zu müssen.
 Es kann beispielsweise Fragen beantworten wie „Warum gibt das Modell Token A anstelle von Token B aus“, „Warum konzentriert sich der Aufmerksamkeitskopf H auf Token T“.
Es kann beispielsweise Fragen beantworten wie „Warum gibt das Modell Token A anstelle von Token B aus“, „Warum konzentriert sich der Aufmerksamkeitskopf H auf Token T“.
Bilder
Da TDB Neuronen und Aufmerksamkeitsköpfe unterstützen kann, ermöglicht es Forschern, durch die Ablation einzelner Neuronen in die Vorwärtsübertragung einzugreifen und die auftretenden spezifischen Veränderungen zu beobachten.
Laut Jan Leike handelt es sich bei diesem Tool jedoch noch um eine frühe Version, die OpenAI in der Hoffnung veröffentlicht hat, dass mehr Forscher es nutzen und auf der bestehenden Basis weiter verbessern können.
 Bilder
Bilder
Projektadresse: https://github.com/openai/transformer-debugger
Funktionsprinzip
 Um zu verstehen, wie dieser Transformer Debugger funktioniert, müssen Sie OpenAI in überprüfen 2023 Eine Studie zur Ausrichtung wurde im Mai veröffentlicht.
Um zu verstehen, wie dieser Transformer Debugger funktioniert, müssen Sie OpenAI in überprüfen 2023 Eine Studie zur Ausrichtung wurde im Mai veröffentlicht.
Das TDB-Tool basiert auf zwei zuvor veröffentlichten Studien und wird keine Artikel veröffentlichen
Einfach ausgedrückt hofft OpenAI, ein Modell (GPT-4) mit größeren Parametern und stärkeren Fähigkeiten zur automatischen Analyse kleiner Parameter zu verwenden Verhalten des Modells (GPT-2) mit Erläuterung seiner Funktionsweise.
Bilder
Die vorläufigen Ergebnisse der damaligen OpenAI-Forschung waren, dass Modelle mit relativ wenigen Parametern leicht zu verstehen waren, aber mit zunehmender Modellparametergröße und zunehmender Anzahl von Schichten nahm der Erklärungseffekt zu Lot.
 Bilder
Bilder
Damals stellte OpenAI in seiner Forschung fest, dass GPT-4 selbst nicht darauf ausgelegt sei, das Verhalten kleiner Modelle zu erklären, sodass die Gesamtinterpretation von GPT-2 noch sehr dürftig sei.
 Bilder
Bilder
In Zukunft müssen Algorithmen und Werkzeuge entwickelt werden, die das Modellverhalten besser erklären können.
Der jetzt Open-Source-Transformer-Debugger ist die schrittweise Errungenschaft von OpenAI im folgenden Jahr.
Und dieses „bessere Tool“ – Transformer Debugger – kombiniert „sparse autoencoder“ in dieser technischen Linie der „Verwendung großer Modelle zur Erklärung kleiner Modelle“.
Dann war der bisherige OpenAI-Prozess zur Verwendung von GPT-4 zur Erklärung kleiner Modelle in der Interpretierbarkeitsforschung nullcodiert, wodurch die Einstiegshürde für Forscher erheblich gesenkt wurde.
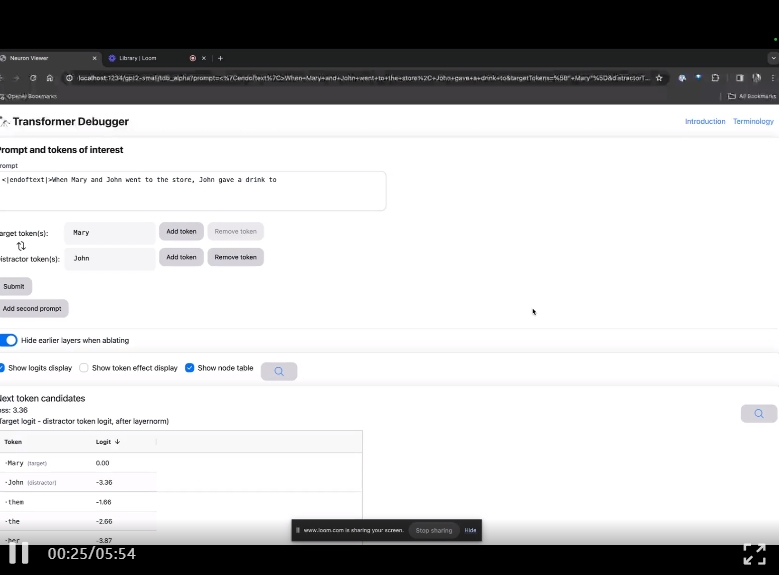
GPT-2 Small wurde durchschaut
Auf der GitHub-Projekthomepage stellten OpenAI-Teammitglieder das neueste Transformer-Debugger-Tool in einem Video vor.
Ähnlich wie der Python-Debugger können Sie mit TDB die Ausgabe des Sprachmodells schrittweise durchgehen, wichtige Aktivierungen verfolgen und Upstream-Aktivierungen analysieren.
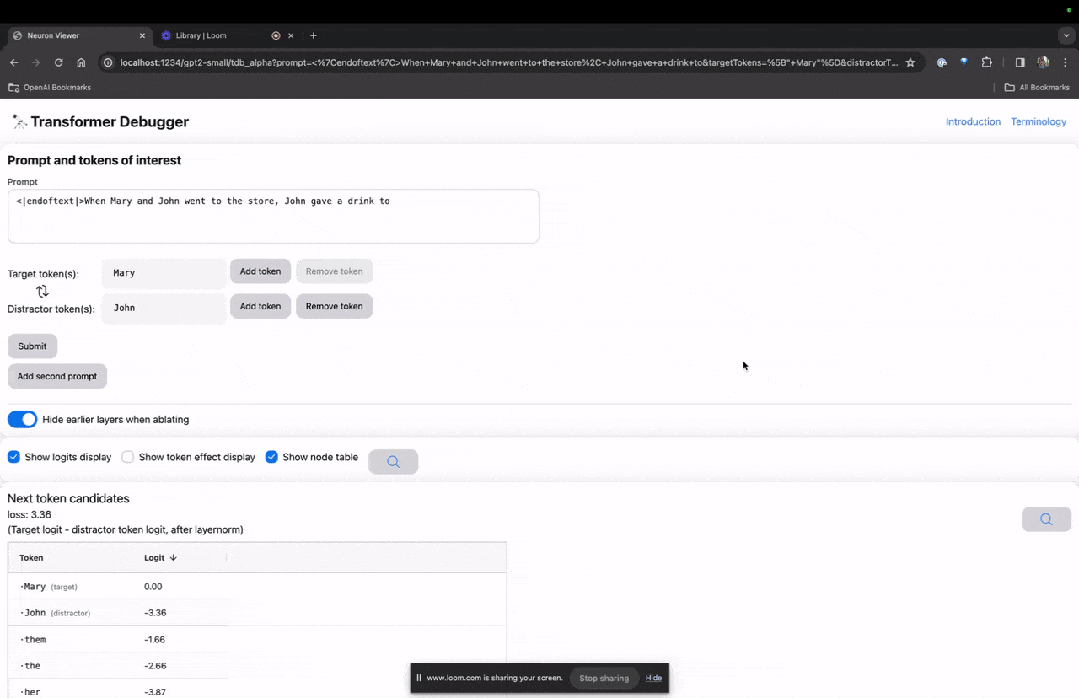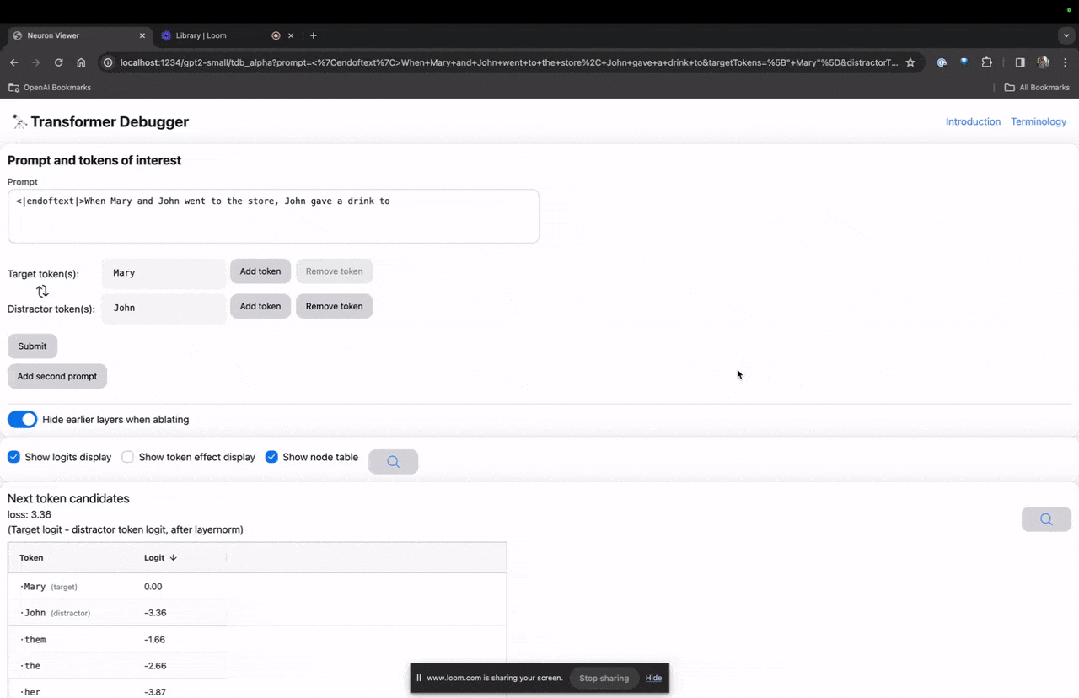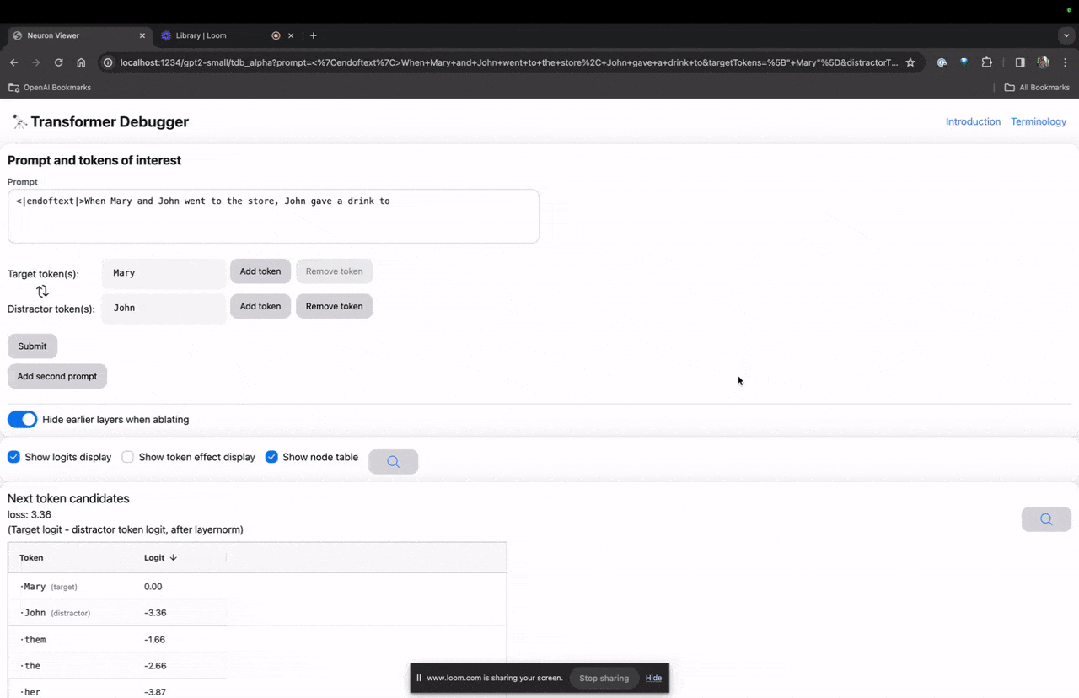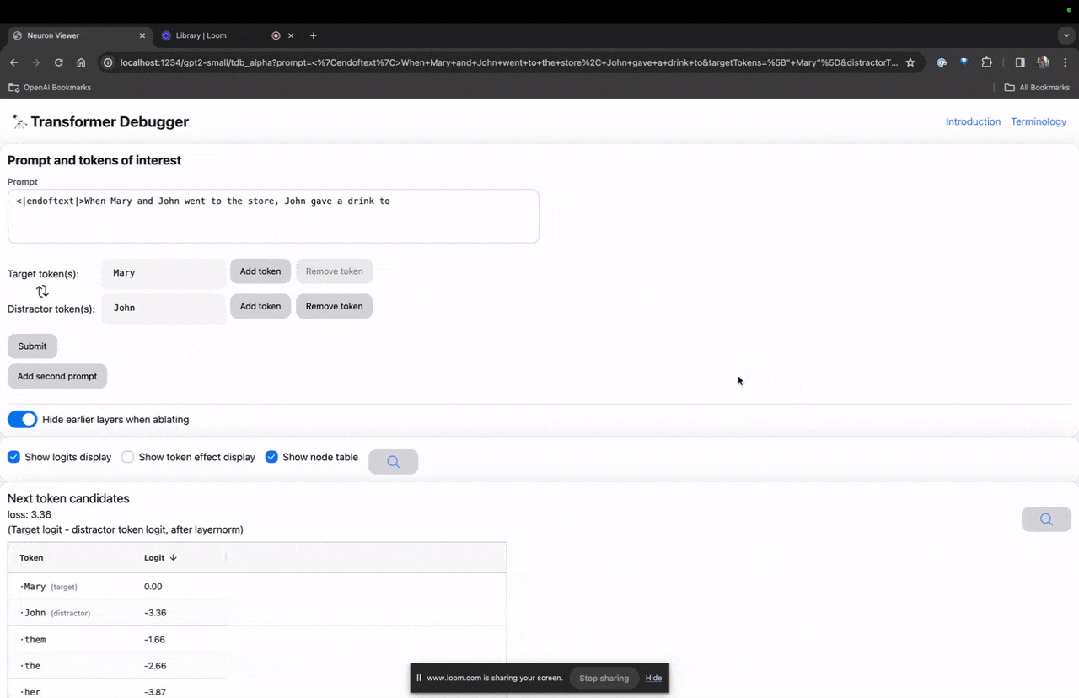
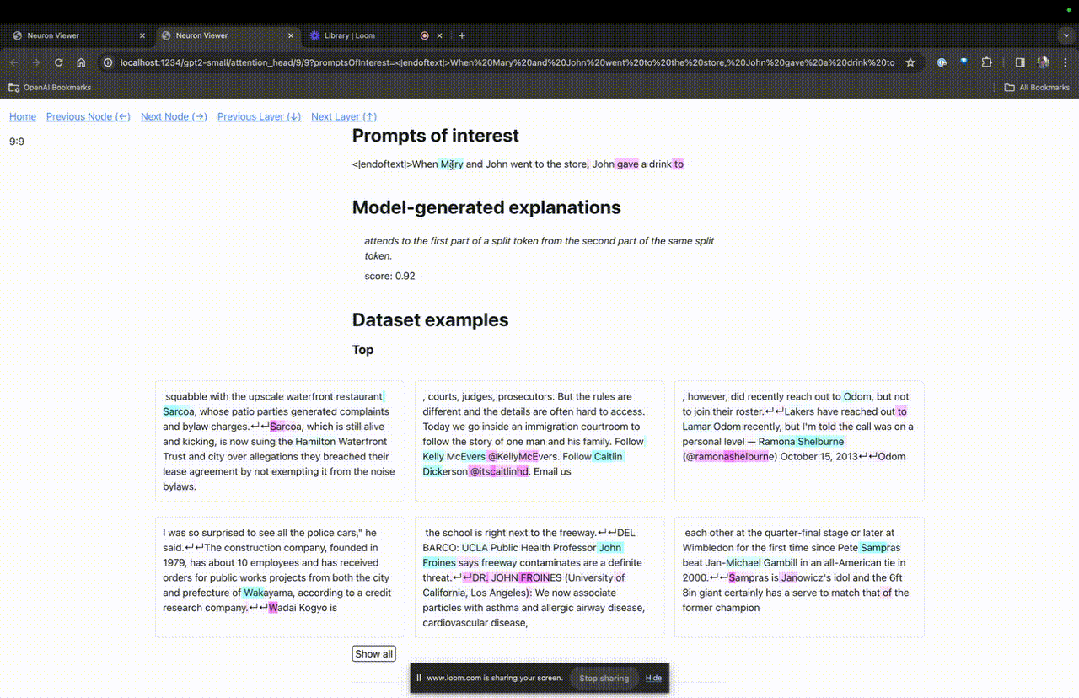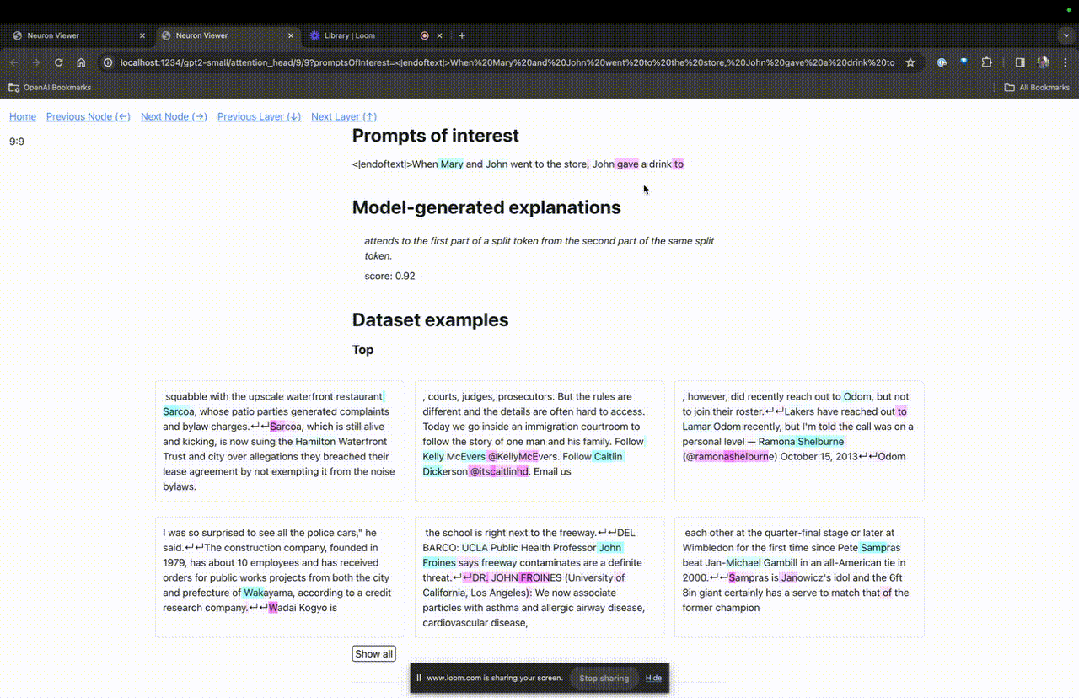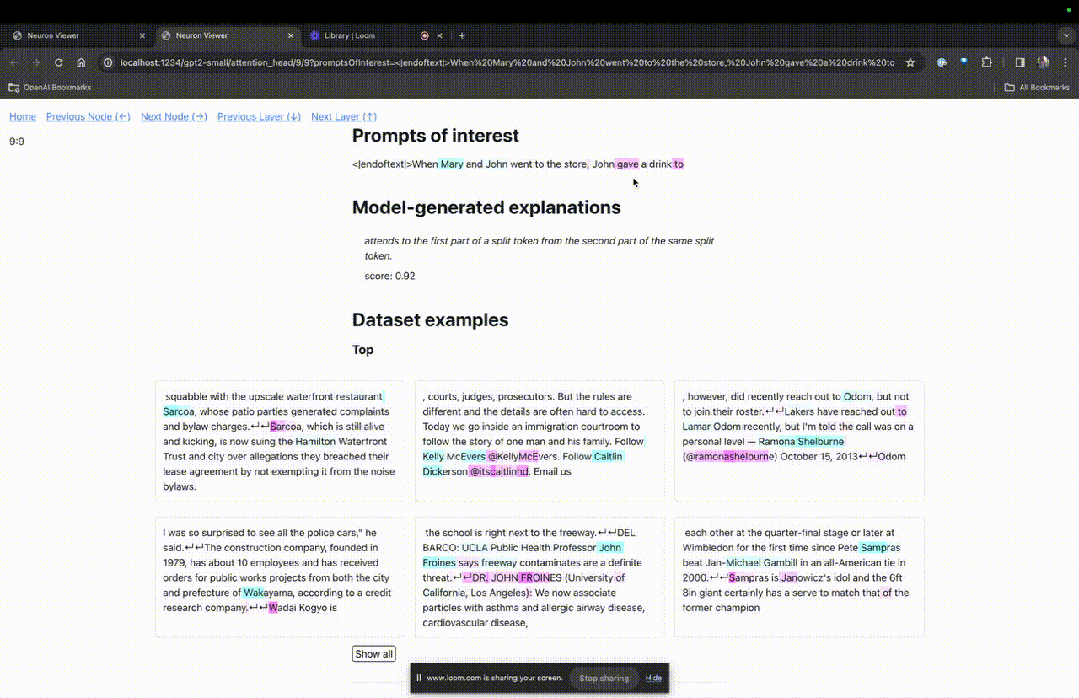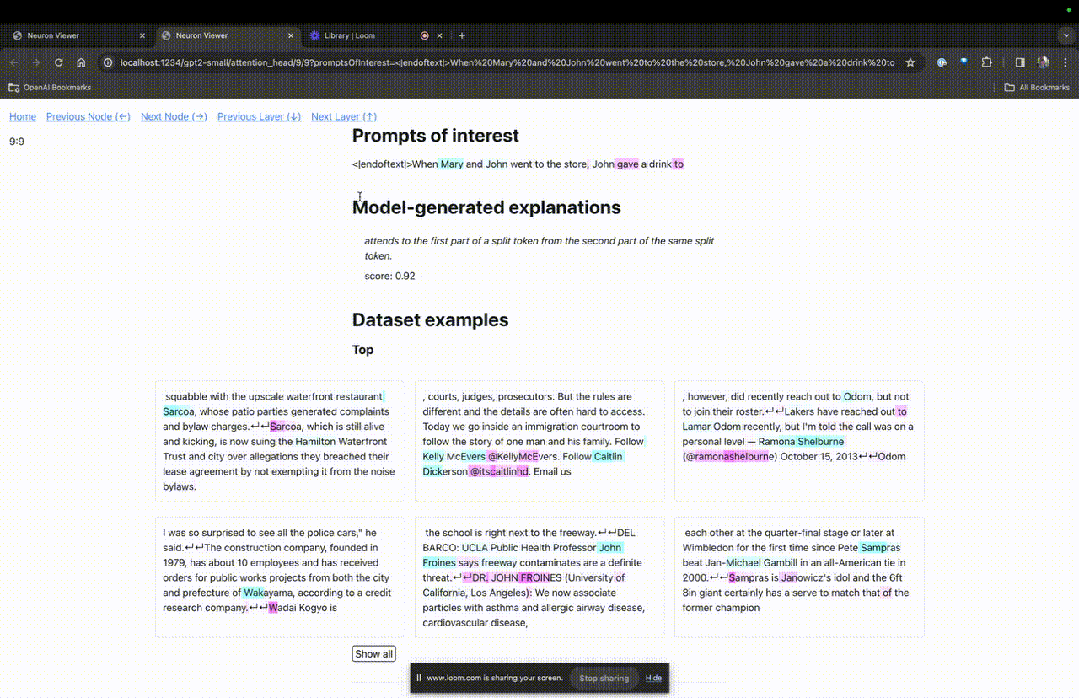
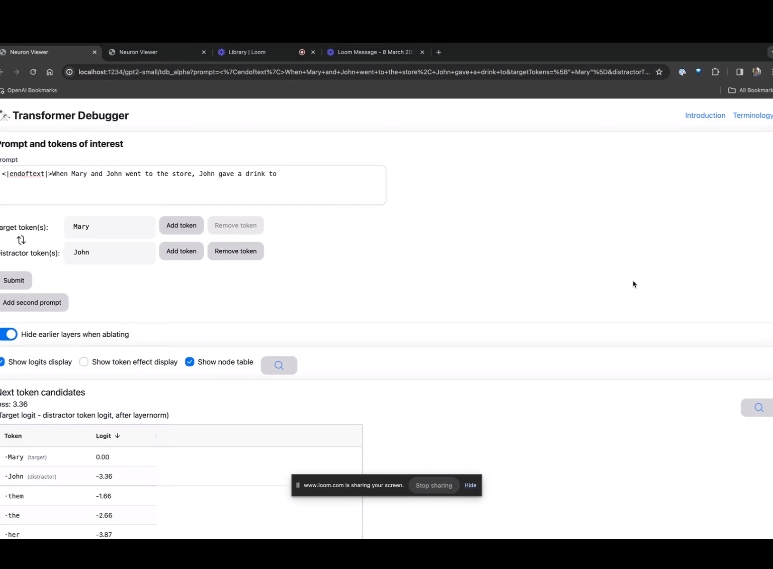
Betreten Sie die TDB-Homepage, geben Sie zunächst die Spalte „Eingabeaufforderung“ ein – Eingabeaufforderung und Zeichen des Interesses:
Mary und Johon gingen in den Laden, Johon gab ...
Der nächste Schritt besteht darin, eine „Nächstes Wort“-Vorhersage zu treffen, was die Eingabe des Ziel-Tokens und störender Token erfordert.
Nach der endgültigen Einreichung können Sie den Logarithmus der vom System vorhergesagten Kandidaten für das nächste Wort sehen.
Die „Knotentabelle“ unten ist der Kernteil von TDB. Jede Zeile entspricht hier einem Knoten, der eine Modellkomponente aktiviert.
 Bilder
Bilder
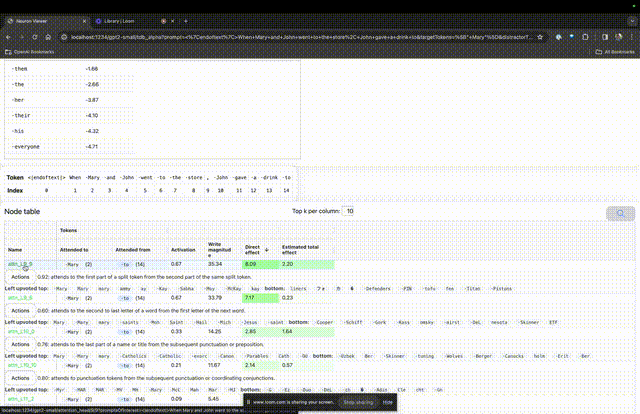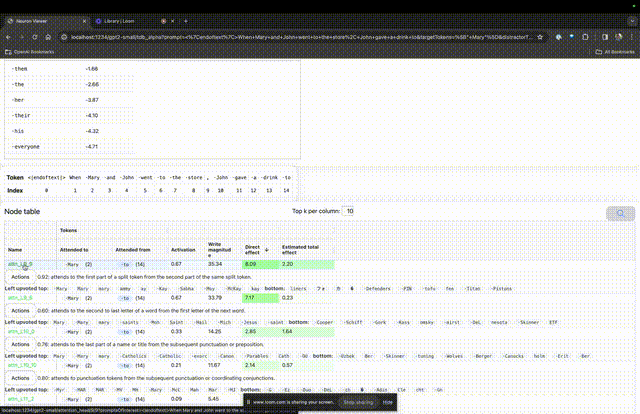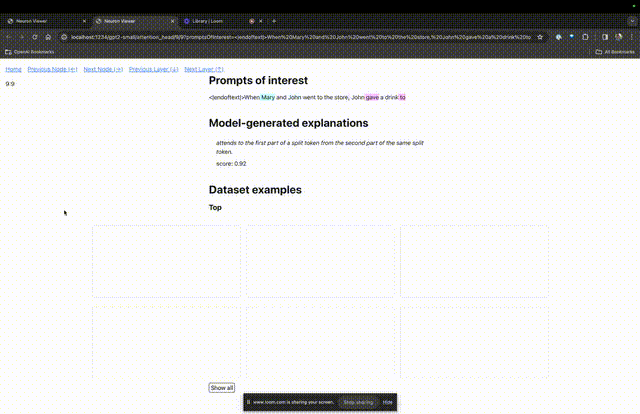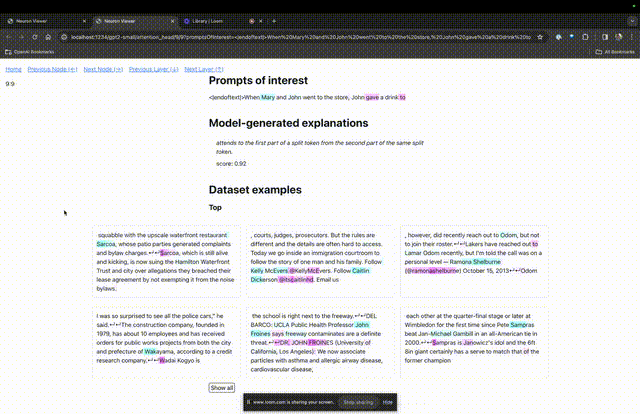
Wenn Sie wissen möchten, welche Funktion der Aufmerksamkeitskopf für eine bestimmte Aufforderung sehr wichtig ist, klicken Sie einfach auf den Namen der Komponente.
Dann öffnet TDB die Seite „Neuron Browser“ und die vorherigen Eingabeaufforderungswörter werden oben angezeigt.
 Bild
Bild
Die hellblauen und rosafarbenen Spielsteine könnt ihr hier sehen. Unter jedem Token der entsprechenden Farbe führt die Aufmerksamkeit von nachfolgenden Tags zu diesem Token dazu, dass ein großer Normvektor in den nachfolgenden Token geschrieben wird.
 Bilder
Bilder
In zwei weiteren Videos stellen die Forscher das Konzept von TDB und seine Anwendung zum Verständnis von Schleifen vor. Gleichzeitig zeigte er auch, wie TDB eine der Erkenntnisse der Arbeit qualitativ reproduzieren kann.
OpenAI Automatic Interpretability Research
Einfach ausgedrückt besteht die Idee von OpenAI Automatic Interpretability Research darin, GPT-4 das Verhalten von Neuronen in natürlicher Sprache interpretieren zu lassen und diesen Prozess dann auf GPT anzuwenden -2.
Wie ist das möglich? Zuerst müssen wir LLM „sezieren“.
Wie Gehirne bestehen sie aus „Neuronen“, die bestimmte Muster im Text beobachten, die bestimmen, was das gesamte Modell als nächstes sagen wird.
Wenn Sie beispielsweise eine Frage wie „Welche Marvel-Superhelden haben die nützlichsten Superkräfte?“ erhalten, kann „Marvel-Superhelden-Neuronen“ die Wahrscheinlichkeit erhöhen, dass das Modell bestimmte Superhelden in Marvel-Filmen benennt.
Das Tool von OpenAI verwendet diese Einstellung, um das Modell in einzelne Teile zu zerlegen.
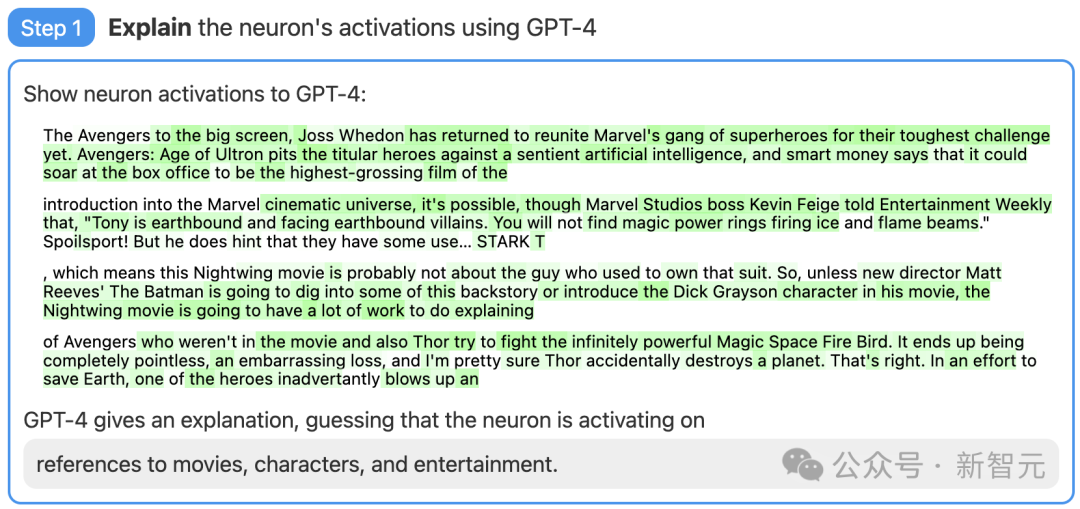
Schritt 1: Verwenden Sie GPT-4, um Erklärungen zu generieren
Suchen Sie zunächst ein Neuron von GPT-2 und zeigen Sie die relevante Textsequenz und Aktivierung für GPT-4 an.
Dann lassen Sie GPT-4 eine mögliche Erklärung basierend auf diesen Verhaltensweisen generieren.
Im Beispiel unten geht GPT-4 beispielsweise davon aus, dass dieses Neuron mit Filmen, Charakteren und Unterhaltung zusammenhängt.
 Bilder
Bilder
Schritt 2: Verwenden Sie GPT-4, um zu simulieren
Als nächstes lassen Sie GPT-4 simulieren, was die dadurch aktivierten Neuronen basierend auf der generierten Erklärung tun werden.
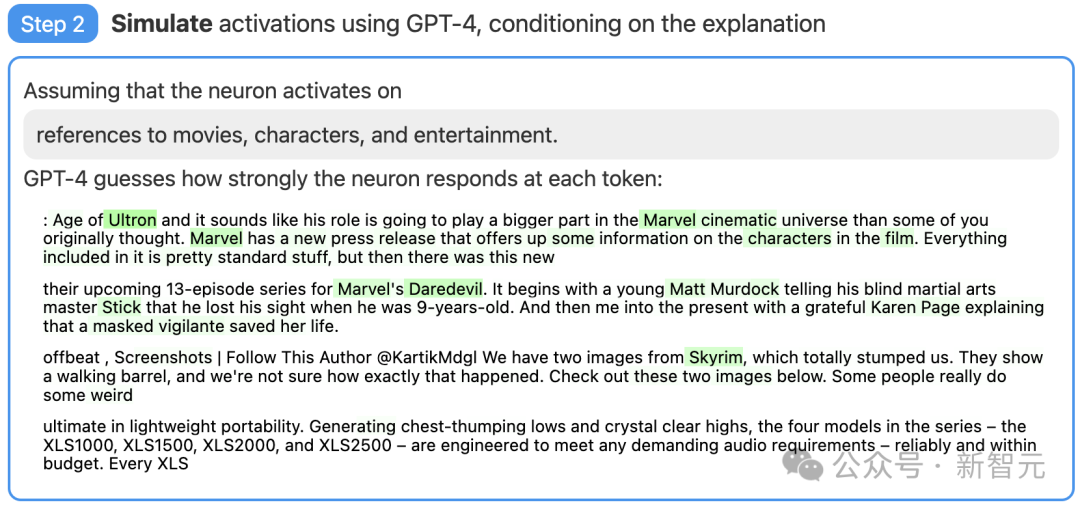 Bilder
Bilder
Schritt drei: Vergleichsergebnis
Vergleichen Sie abschließend das Verhalten des simulierten Neurons (GPT-4) mit dem Verhalten des tatsächlichen Neurons (GPT-2), siehe Let's Sehen Sie, wie genau die Schätzung von GPT-4 ist.
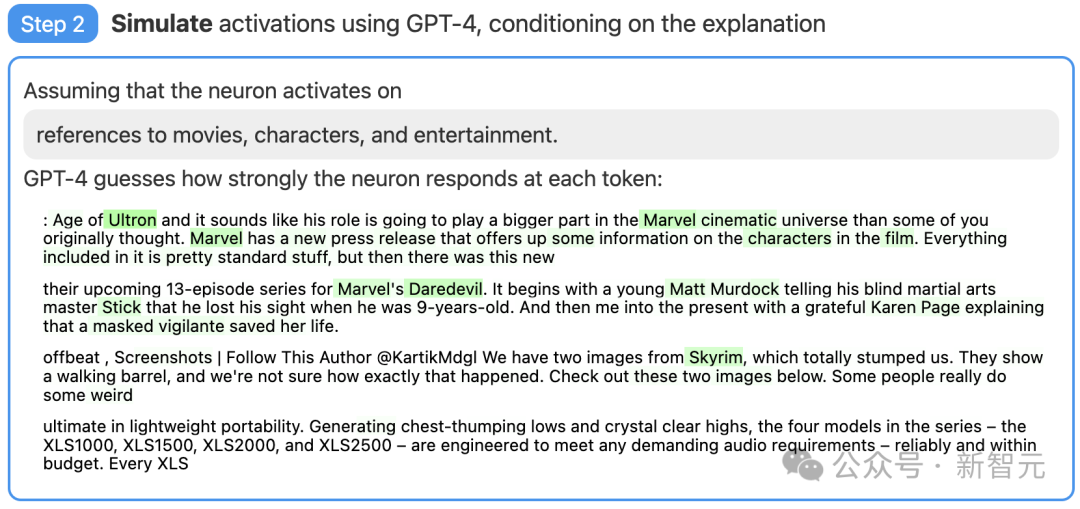 Bilder
Bilder
Auch Einschränkungen
Durch Scoring haben OpenAI-Forscher gemessen, wie effektiv diese Technologie in verschiedenen Teilen des neuronalen Netzwerks war. Diese Technik lässt sich bei größeren Modellen nicht so gut erklären, wahrscheinlich weil spätere Schichten schwieriger zu erklären sind.
 Bilder
Bilder
Derzeit ist die überwiegende Mehrheit der Erklärungswerte sehr niedrig, aber Forscher haben auch herausgefunden, dass sie durch Iteration von Erklärungen, Verwendung größerer Modelle und Änderung der Architektur der erklärten Modelle verbessert werden können .
Jetzt stellt OpenAI den Datensatz und die Visualisierungstools für die Ergebnisse von „Verwendung von GPT-4 zur Erklärung aller 307.200 Neuronen in GPT-2“ als Open-Source-Lösung zur Verfügung und führt auch die Interpretation und Bewertung bestehender Modelle auf dem Markt durch Öffentlichkeit durch den OpenAI-API-Code und fordert die akademische Gemeinschaft auf, bessere Techniken zu entwickeln, die besser bewertete Erklärungen liefern.
Darüber hinaus stellte das Team fest, dass die Konsistenzrate der Erklärung umso höher ist, je größer das Modell ist. Unter ihnen ist GPT-4 dem Menschen am nächsten, aber es gibt immer noch eine große Lücke.
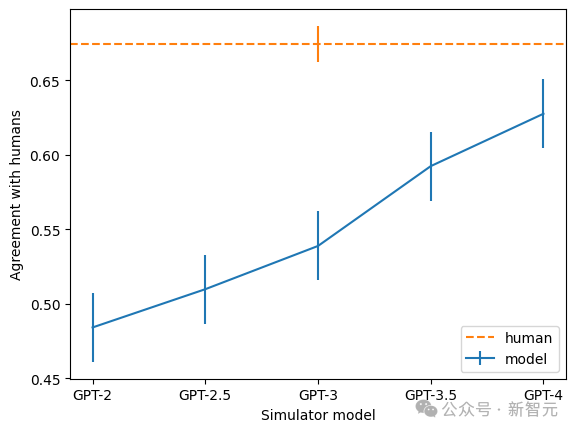 Bilder
Bilder
Das Folgende sind Beispiele für die Aktivierung von Neuronen in verschiedenen Schichten. Sie können sehen, dass die Ebene umso abstrakter ist, je höher sie ist.
 Bilder
Bilder
 Bilder
Bilder
 Bilder
Bilder
 Bilder
Bilder
Sparse Autoencoder-Setup
Der von OpenAI verwendete Sparse-Autoencoder ist ein Modell mit einer Vorspannung für den Eingang und enthält außerdem eine lineare Schicht mit Vorspannung und ReLU für den Encoder sowie eine weitere lineare Schicht und Vorspannung für den Decoder.
Die Forscher fanden heraus, dass der Bias-Term für die Leistung des Autoencoders sehr wichtig ist. Sie setzen die in der Eingabe und Ausgabe angewendete Bias in Beziehung, und das Ergebnis entspricht dem Subtrahieren der festen Bias von allen Aktivierungen.
Die Forscher nutzten den Adam-Optimierer, um einen Autoencoder zu trainieren, um die MLP-Aktivierung des Transformers mithilfe von MSE zu rekonstruieren. Durch die Verwendung des MSE-Verlusts kann die Herausforderung der Polysemantik umgangen und der Verlust plus eine L1-Strafe genutzt werden, um die Sparsity zu fördern.
Es gibt mehrere Prinzipien, die beim Training von Autoencodern sehr wichtig sind.
Das erste ist der Maßstab. Durch das Training eines Autoencoders mit mehr Daten werden Funktionen subjektiv „schärfer“ und besser interpretierbar. OpenAI verwendet also 8 Milliarden Trainingspunkte für den Autoencoder.
Zweitens hören einige Neuronen während des Trainings auf zu feuern, selbst bei einer großen Anzahl von Datenpunkten.
Die Forscher haben diese toten Neuronen dann während des Trainings „neu abgetastet“, wodurch das Modell mehr Merkmale für eine bestimmte Dimension der verborgenen Ebene des Autoencoders darstellen und so bessere Ergebnisse erzielen konnte.
Beurteilungsindikatoren
Wie beurteilen Sie, ob Ihre Methode wirksam ist? Beim maschinellen Lernen kann man Verluste einfach als Standard verwenden, es ist jedoch nicht einfach, hier eine ähnliche Referenz zu finden.
Suchen Sie beispielsweise nach einer informationsbasierten Metrik, sodass in gewisser Weise die beste Zerlegung diejenige ist, die die Gesamtinformationen des Autoencoders und der Daten minimiert.
– Tatsächlich hat die Gesamtinformation jedoch oft nichts mit der subjektiven Interpretierbarkeit von Merkmalen oder der Aktivierungsparsität zu tun.
Letztendlich verwendeten die Forscher eine Kombination aus mehreren zusätzlichen Metriken:
- Manuelle Inspektion: Sehen die Merkmale erklärbar aus?
- Funktionsdichte: Die Anzahl der Funktionen in Echtzeit und der Prozentsatz der Token, die sie auslösen, sind ein sehr nützlicher Leitfaden.
- Rekonstruktionsverlust: misst, wie gut der Autoencoder die MLP-Aktivierungen rekonstruiert. Das ultimative Ziel besteht darin, die Funktionalität der MLP-Schicht zu berücksichtigen, sodass der MSE-Verlust gering sein sollte.
- Spielzeugmodell: Die Verwendung eines bereits gut verstandenen Modells ermöglicht eine klare Beurteilung der Leistung des Autoencoders.
Die Forscher äußerten jedoch auch die Hoffnung, anhand der auf Transformer trainierten spärlichen Autoencoder bessere Indikatoren für Wörterbuch-Lernlösungen zu ermitteln.
Referenz:
Das obige ist der detaillierte Inhalt vonOpenAI hat den Open-Source-Transformer-Debugger offiziell angekündigt! Sie müssen keinen Code schreiben, jeder kann die LLM-Blackbox knacken. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- OpenAI veröffentlicht ein neues Konsistenzmodell, die GAN-Geschwindigkeit erreicht 18 FPS und kann in Echtzeit qualitativ hochwertige Bilder erzeugen.
- ChatGPT konzentriert sich auf den Chatbot-Wettbewerb zwischen Google, Meta und OpenAI und stellt die Unzufriedenheit von LeCun in den Mittelpunkt des Themas
- Copilot debütiert, ChatGPT verwendet standardmäßig die Bing-Suche, das große Universum von Microsoft und OpenAI ist da
- Wie modelliere ich Entscheidungsbäume und neuronale Netzwerke in PHP?
- „Elektronische Fruchtfliegen'-Alarm Musk! Dahinter steckt eine Karte des gesamten Gehirns mit 130.000 Neuronen, die auf einem Computer ausgeführt werden kann