
Heim >Technologie-Peripheriegeräte >KI >Ein Artikel, der die Anwendung des Diffusionsmodells in Zeitreihen zusammenfasst
Ein Artikel, der die Anwendung des Diffusionsmodells in Zeitreihen zusammenfasst

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-03-07 10:30:041149Durchsuche
Das Diffusionsmodell ist derzeit das Kernmodul der generativen KI und wird häufig in großen generativen KI-Modellen wie Sora, DALL-E und Imagen verwendet. Gleichzeitig werden Diffusionsmodelle zunehmend auf Zeitreihen angewendet. Dieser Artikel führt Sie in die Grundideen des Diffusionsmodells sowie in mehrere typische Arbeiten des in Zeitreihen verwendeten Diffusionsmodells ein, um Ihnen das Verständnis der Anwendungsprinzipien des Diffusionsmodells in Zeitreihen zu erleichtern.

1.Diffusionsmodell-Modellierungsidee
Der Kern des generativen Modells besteht darin, einen Punkt aus einer zufälligen einfachen Verteilung abzutasten und diesen Punkt einem Bild des Zielraums zuzuordnen eine Reihe von Transformationen oder an einer Probe. Das Diffusionsmodell entfernt kontinuierlich Rauschen an den abgetasteten Abtastpunkten und generiert die endgültigen Daten durch mehrere Rauschentfernungsschritte. Dieser Prozess ist dem Skulpturprozess sehr ähnlich. Das aus der Gaußschen Verteilung entnommene Rauschen ist der Prozess, bei dem die überschüssigen Teile dieses Materials ständig abgetragen werden.
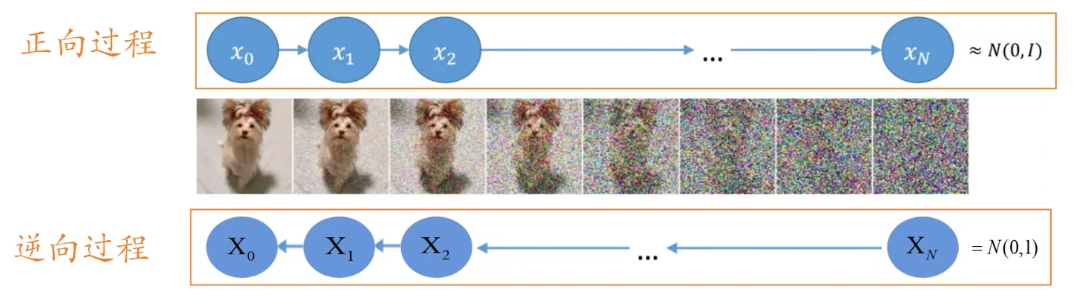
Was oben erwähnt wurde, ist der umgekehrte Prozess, das heißt, das Rauschen wird schrittweise aus einem Rauschen entfernt, um ein Bild zu erhalten. Bei diesem Prozess handelt es sich um einen iterativen Prozess, der T-fache Entrauschung erfordert, um das Rauschen Stück für Stück von den ursprünglichen Abtastpunkten zu entfernen. In jedem Schritt wird das im vorherigen Schritt generierte Ergebnis eingegeben, und das Rauschen muss vorhergesagt werden. Anschließend wird das Rauschen von der Eingabe subtrahiert, um die Ausgabe des aktuellen Zeitschritts zu erhalten.
Hier müssen Sie ein Modul (Entrauschungsmodul) trainieren, das das Rauschen des aktuellen Schritts vorhersagt. Dieses Modul gibt den aktuellen Schritt t sowie die Eingabe des aktuellen Schritts ein und sagt voraus, was das Rauschen ist. Dieses Modul zur Geräuschvorhersage wird durch einen Vorwärtsprozess ausgeführt, der dem Encoder-Teil in VAE ähnelt. Im Vorwärtsprozess wird ein Bild eingegeben, bei jedem Schritt ein Rauschen abgetastet und das Rauschen zum Originalbild hinzugefügt, um das generierte Ergebnis zu erhalten. Anschließend werden die generierten Ergebnisse und die Einbettung des aktuellen Schritts t als Eingabe zur Vorhersage des erzeugten Rauschens verwendet, wodurch die Rolle des Trainings des Rauschunterdrückungsmoduls erfüllt wird. 2.
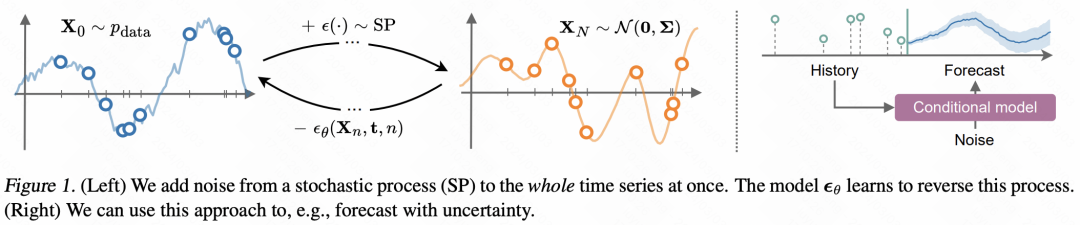
Anwendung des Diffusionsmodells in Zeitreihen Prognose Eine der Methoden. Im Gegensatz zum herkömmlichen Diffusionsmodell führt TimeGrad ein Entrauschungsmodul ein, das auf dem grundlegenden Diffusionsmodell basiert und für jeden Zeitschritt einen zusätzlichen verborgenen Zustand bereitstellt. Dieser verborgene Zustand wird durch die Codierung der historischen Sequenz und externer Variablen durch das RNN-Modell erhalten und als Leitfaden für das Diffusionsmodell zur Generierung der Sequenz verwendet. Die Gesamtlogik ist in der folgenden Abbildung dargestellt.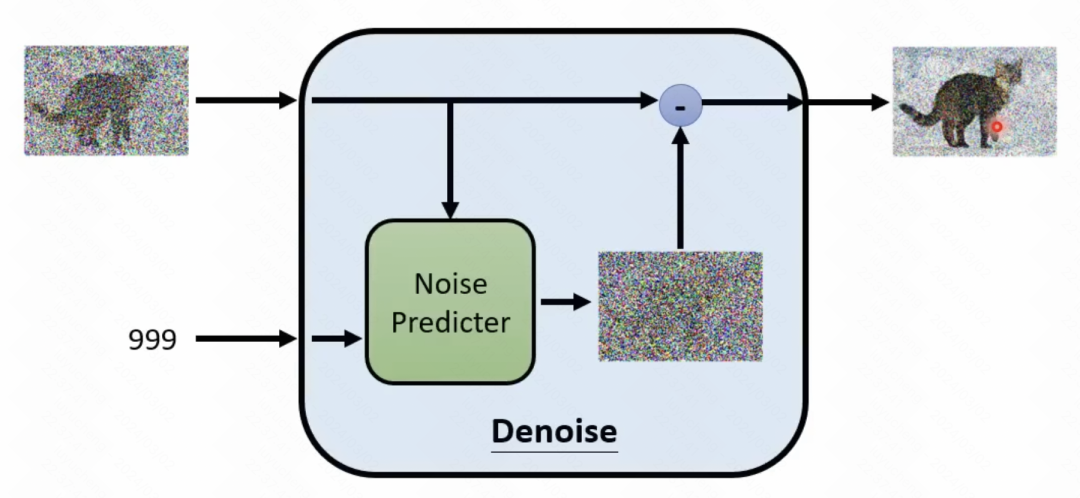
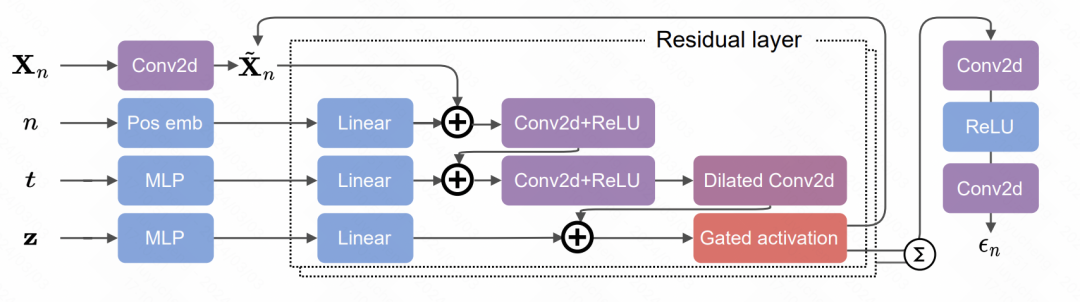
In der Netzwerkstruktur des Entrauschungsmoduls wird hauptsächlich das Faltungs-Neuronale Netzwerk verwendet. Das Eingangssignal ist in zwei Teile unterteilt: Der erste Teil ist die Ausgabesequenz des vorherigen Schritts und der zweite Teil ist der vom RNN ausgegebene verborgene Zustand, das Ergebnis, das nach dem Upsampling erhalten wird. Diese beiden Teile werden gefaltet und dann zur Geräuschvorhersage addiert.
CSDI: Conditional Score-based Diffusion Models for Probabilistic Time Series Imputation (2021)
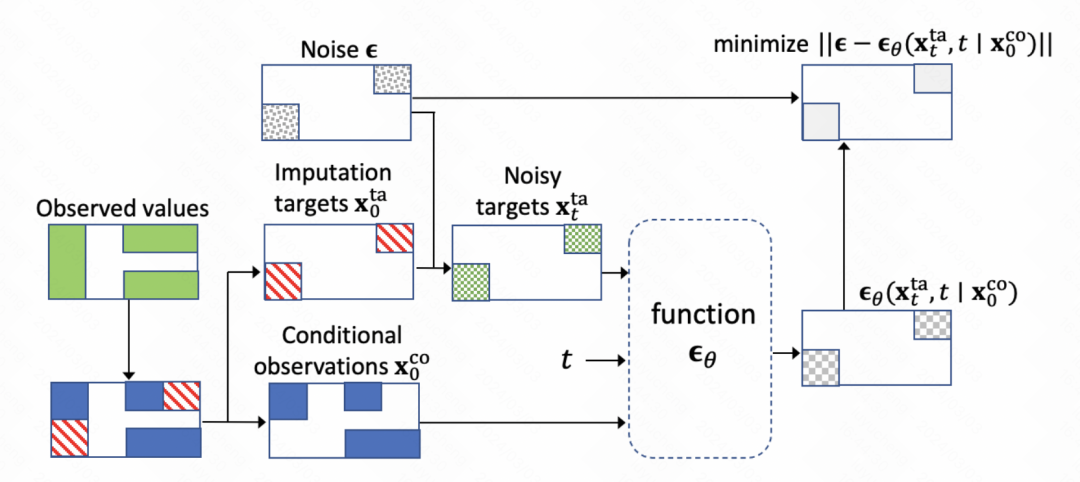
In diesem Artikel wird das Diffusionsmodell zur Modellierung der Zeitreihenfüllaufgabe verwendet. Die allgemeine Modellierungsmethode ähnelt TimeGrad. Wie in der Abbildung unten gezeigt, fehlen in der anfänglichen Zeitreihe Werte. Anschließend wird das Diffusionsmodell verwendet, um das Rauschen schrittweise vorherzusagen und eine Entrauschung zu erreichen. 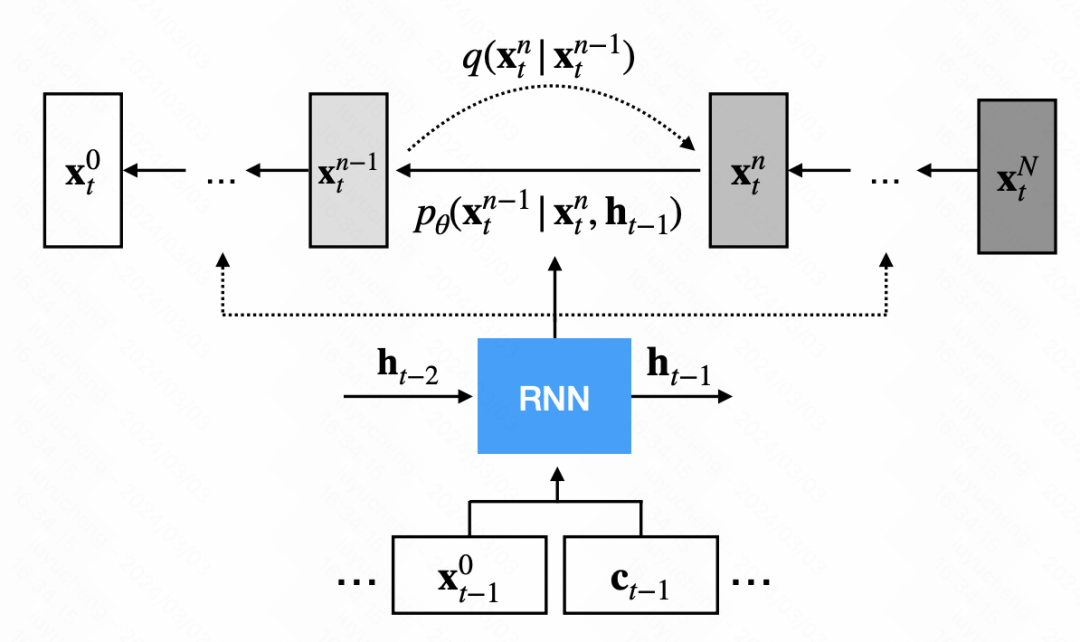
Der Kern des gesamten Modells ist auch das Diffusionsmodell-Trainingsmodul zur Rauschunterdrückung. Der Kern besteht darin, das Rauschvorhersagenetzwerk zu trainieren, um die Rauschergebnisse vorherzusagen.
Transformer wird in der Netzwerkstruktur verwendet und besteht aus zwei Teilen: Transformer in der Zeitdimension und Transformer in der variablen Dimension.

Die in diesem Artikel vorgeschlagene Methode ist im Vergleich zu TimeGrad eine höhere Ebene geworden. Sie modelliert direkt die Funktion selbst, die die Zeit generiert Reihe durch das Diffusionsmodell. Hier wird davon ausgegangen, dass jeder Beobachtungspunkt aus einer Funktion generiert wird und dann die Verteilung dieser Funktion direkt modelliert wird, anstatt die Verteilung der Datenpunkte in der Zeitreihe zu modellieren. Daher ändert dieser Artikel das im Diffusionsmodell hinzugefügte unabhängige Rauschen in Rauschen, das sich mit der Zeit ändert, und trainiert das Entrauschungsmodul im Diffusionsmodell, um die Funktion zu entrauschen.
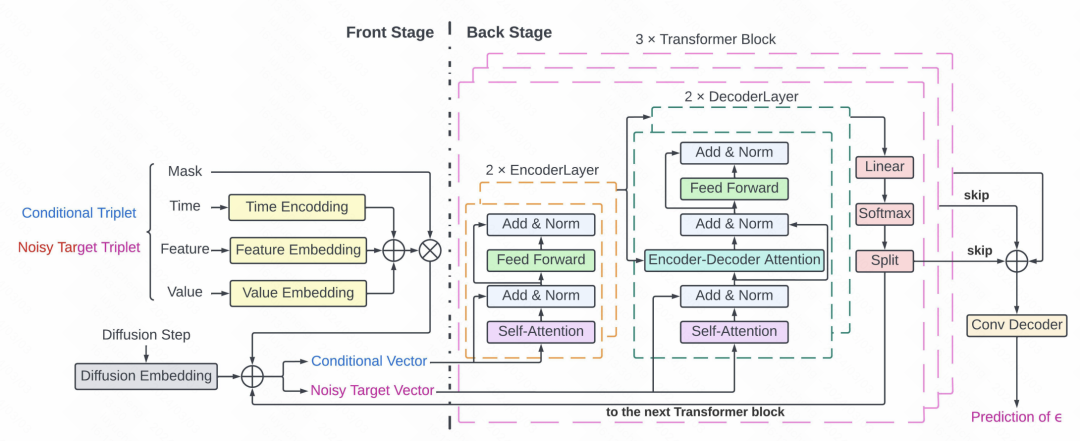
Dieser Artikel wendet das Diffusionsmodell auf die Schlüsselsignalextraktion auf der Intensivstation an. Der Kern dieses Artikels ist einerseits die Verarbeitung spärlicher und unregelmäßiger medizinischer Zeitreihendaten, wobei Wert-, Merkmals- und Zeittripel verwendet werden, um jeden Punkt in der Sequenz darzustellen, und eine Maske für den tatsächlichen Wertteil verwendet wird. Auf der anderen Seite stehen Vorhersagemethoden, die auf Transformer- und Diffusionsmodellen basieren. Der gesamte Diffusionsmodellprozess ist in der Abbildung dargestellt. Das Prinzip des Bilderzeugungsmodells ist ähnlich. Das Entrauschungsmodell wird auf der Grundlage der historischen Zeitreihe trainiert, und dann wird das Rauschen schrittweise von der anfänglichen Rauschsequenz in der Vorwärtsausbreitung subtrahiert.

Der spezifische Rauschvorhersageteil des Diffusionsmodells verwendet die Transformer-Struktur. Jeder Zeitpunkt besteht aus einer Maske und einem Triplett, die in den Transformer eingegeben und als Rauschunterdrückungsmodul zur Vorhersage von Rauschen verwendet werden. Die detaillierte Struktur umfasst 3 Schichten von Transformatoren und 2 Schichten von Decoder-Netzwerken. Der Ausgang des Decoders wird über das Restnetzwerk und den Eingang mit dem Faltungsdecoder verbunden, um Rauschvorhersageergebnisse zu generieren.
Das obige ist der detaillierte Inhalt vonEin Artikel, der die Anwendung des Diffusionsmodells in Zeitreihen zusammenfasst. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was sind die Klassifizierungen künstlicher Intelligenz?
- Was ist das Grundkonzept der künstlichen Intelligenz?
- Zum ersten Mal verlassen Sie sich nicht auf ein generatives Modell und lassen die KI Bilder in nur einem Satz bearbeiten!
- Nicht so gut wie GAN! Google, DeepMind und andere haben Artikel veröffentlicht: Diffusionsmodelle werden direkt aus dem Trainingssatz „kopiert'.
- Methoden zur Analyse der Rauschdiffusion in generierten Modellen