
Heim >Technologie-Peripheriegeräte >KI >Die 10 wichtigsten Algorithmen für künstliche Intelligenz
Die 10 wichtigsten Algorithmen für künstliche Intelligenz

- PHPznach vorne
- 2024-03-06 09:37:13752Durchsuche
Angesichts der anhaltenden Beliebtheit der Technologie der künstlichen Intelligenz (KI) spielen verschiedene Algorithmen eine wichtige Rolle bei der Förderung der Entwicklung dieses Bereichs. Von linearen Regressionsalgorithmen, die zur Vorhersage von Immobilienpreisen verwendet werden, bis hin zu neuronalen Netzen, die selbstfahrende Autos antreiben – diese Algorithmen versorgen und betreiben im Stillen unzählige Anwendungen. Da die Datenmenge zunimmt und die Rechenleistung zunimmt, verbessern sich auch die Leistung und Effizienz der Algorithmen der künstlichen Intelligenz ständig. Der Anwendungsbereich dieser Algorithmen wird immer größer und umfasst medizinische Diagnose, finanzielle Risikobewertung, Verarbeitung natürlicher Sprache usw.

Heute nehmen wir Sie mit auf einen Blick auf diese beliebten Algorithmen für künstliche Intelligenz ( lineare Regression, logistische Regression, Entscheidungsbaum, Naive Bayes, Support Vector Machine (SVM), Ensemble-Lernen, K-Algorithmus für den nächsten Nachbarn, K-Means-Algorithmus, neuronales Netzwerk, Reinforcement Learning (Deep Q-Networks), erkunden Sie ihre Arbeitsprinzipien und Anwendungsszenarien und ihre Anwendung in der realen Welt beeinflusst in.
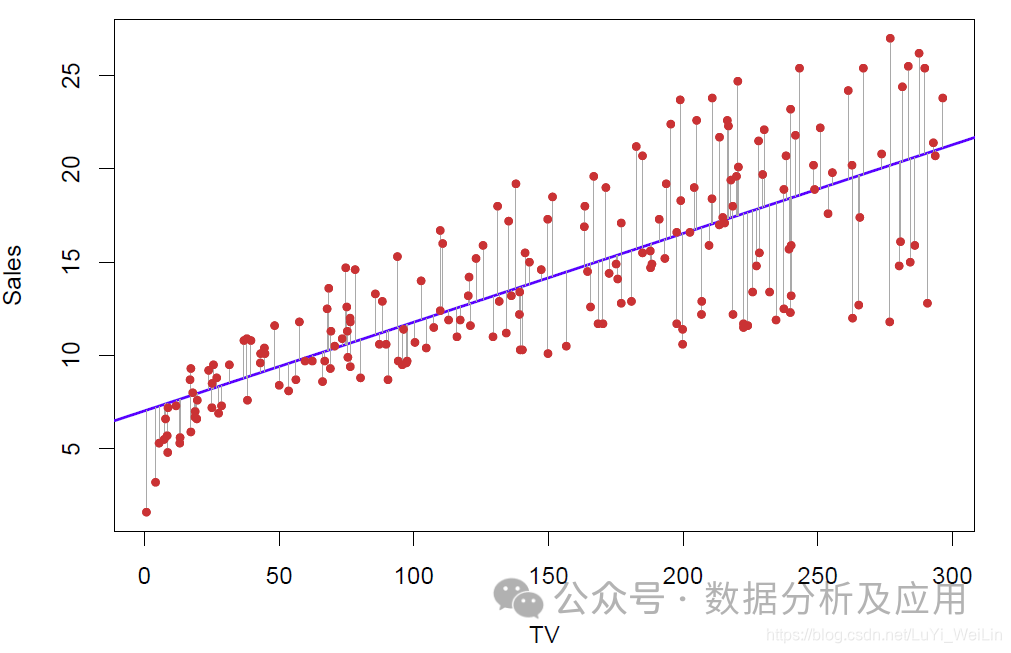
1. Lineare Regression:
Das Prinzip der linearen Regression besteht darin, eine optimale Gerade zu finden, die möglichst gut zur Verteilung der Datenpunkte passt.
Modelltraining ist die Verwendung bekannter Eingabe- und Ausgabedaten zur Optimierung des Modells, normalerweise durch Minimierung der Differenz zwischen vorhergesagten Werten und tatsächlichen Werten.
Vorteile: Einfach und leicht verständlich, hohe Berechnungseffizienz.
Nachteile: Begrenzte Fähigkeit, mit nichtlinearen Beziehungen umzugehen.
Verwendungsszenarien: Geeignet für Probleme der Vorhersage kontinuierlicher Werte, wie z. B. die Vorhersage von Immobilienpreisen, Aktienkursen usw.
Beispielcode (verwenden Sie die Scikit-Learn-Bibliothek von Python, um ein einfaches lineares Regressionsmodell zu erstellen):
from sklearn.linear_model import LinearRegressionfrom sklearn.datasets import make_regression# 生成模拟数据集X, y = make_regression(n_samples=100, n_features=1, noise=0.1)# 创建线性回归模型对象lr = LinearRegression()# 训练模型lr.fit(X, y)# 进行预测predictions = lr.predict(X)
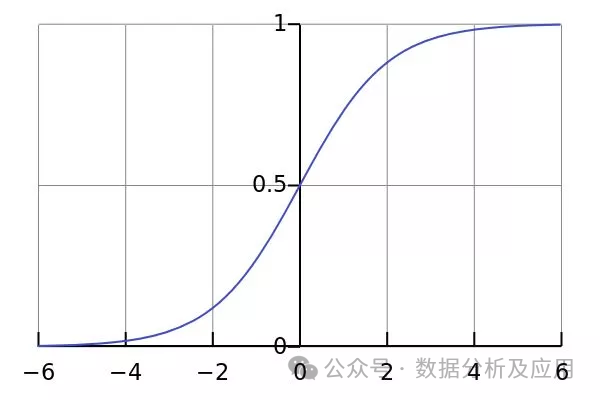
2. Logistische Regression:
Modellprinzip: Die logistische Regression ist eine Methode, die verwendet wird, um A Algorithmus für maschinelles Lernen, der binäre Klassifizierungsprobleme löst, indem er kontinuierliche Eingaben diskreten Ausgaben (normalerweise binär) zuordnet. Es verwendet eine logistische Funktion, um die Ergebnisse der linearen Regression in den Bereich von (0,1) abzubilden, um die Klassifizierungswahrscheinlichkeit zu erhalten.
Modelltraining: Verwenden Sie Beispieldaten bekannter Klassifizierungen, um ein logistisches Regressionsmodell zu trainieren, indem Sie die Parameter des Modells optimieren, um den Kreuzentropieverlust zwischen der vorhergesagten Wahrscheinlichkeit und der tatsächlichen Klassifizierung zu minimieren.
Vorteile: Einfach und leicht zu verstehen, besser für Probleme mit zwei Klassifizierungen.
Nachteile: Begrenzte Fähigkeit, mit nichtlinearen Beziehungen umzugehen.
Verwendungsszenarien: Geeignet für binäre Klassifizierungsprobleme wie Spam-Filterung, Krankheitsvorhersage usw.
Beispielcode (verwenden Sie die Scikit-Learn-Bibliothek von Python, um ein einfaches logistisches Regressionsmodell zu erstellen):
from sklearn.linear_model import LogisticRegressionfrom sklearn.datasets import make_classification# 生成模拟数据集X, y = make_classification(n_samples=100, n_features=2, n_informative=2, n_redundant=0, random_state=42)# 创建逻辑回归模型对象lr = LogisticRegression()# 训练模型lr.fit(X, y)# 进行预测predictions = lr.predict(X)
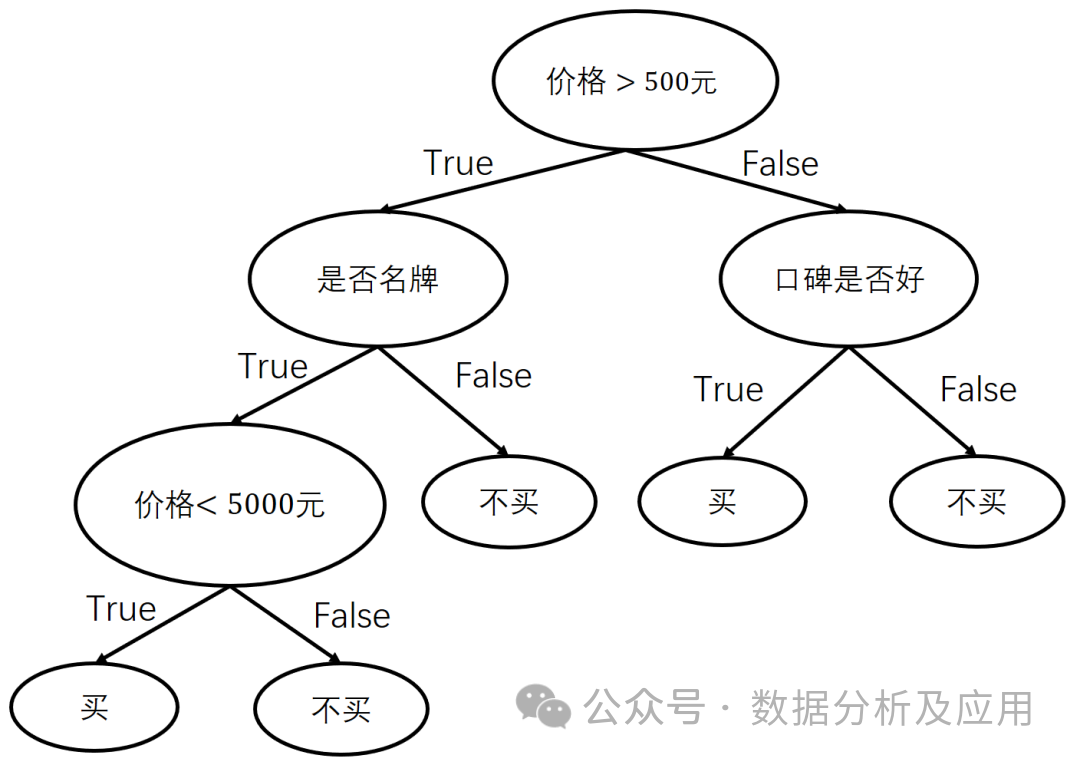
3. Entscheidungsbaum:
Modellprinzip: Der Entscheidungsbaum ist ein überwachtes Lernen Algorithmen, die Entscheidungsgrenzen konstruieren, indem sie einen Datensatz rekursiv in kleinere Teilmengen aufteilen. Jeder interne Knoten repräsentiert eine Beurteilungsbedingung für ein Merkmalsattribut, jeder Zweig repräsentiert einen möglichen Attributwert und jeder Blattknoten repräsentiert eine Kategorie.
Modelltraining: Erstellen Sie einen Entscheidungsbaum, indem Sie die besten Partitionierungsattribute auswählen und Bereinigungstechniken verwenden, um eine Überanpassung zu verhindern.
Vorteile: Leicht zu verstehen und zu erklären, in der Lage, Klassifizierungs- und Regressionsprobleme zu bewältigen.
Nachteile: Leicht zu überpassen, empfindlich gegenüber Rauschen und Ausreißern.
Verwendungsszenarien: Geeignet für Klassifizierungs- und Regressionsprobleme wie Erkennung von Kreditkartenbetrug, Wettervorhersage usw.
Beispielcode (verwenden Sie die Scikit-Learn-Bibliothek von Python, um ein einfaches Entscheidungsbaummodell zu erstellen):
from sklearn.tree import DecisionTreeClassifierfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建决策树模型对象dt = DecisionTreeClassifier()# 训练模型dt.fit(X_train, y_train)# 进行预测predictions = dt.predict(X_test)
4, Naive Baye s:
Modellprinzip: Naive Baye Si ist ein Klassifizierungsmethode basierend auf dem Bayes-Theorem und der Annahme der merkmalsbedingten Unabhängigkeit. Es führt eine probabilistische Modellierung der Attributwerte der Stichproben in jeder Kategorie durch und sagt dann basierend auf diesen Wahrscheinlichkeiten die Kategorie voraus, zu der neue Stichproben gehören.
Modelltraining: Erstellen Sie einen Naive-Bayes-Klassifikator, indem Sie Beispieldaten mit bekannten Kategorien und Attributen verwenden, um die A-priori-Wahrscheinlichkeit jeder Kategorie und die bedingte Wahrscheinlichkeit jedes Attributs abzuschätzen.
Vorteile: Einfach, effizient, besonders effektiv für große Kategorien und kleine Datensätze.
Nachteile: Schlechte Modellierung von Abhängigkeiten zwischen Features.
Nutzungsszenarien: Geeignet für Textklassifizierung, Spam-Filterung und andere Szenarien.

Beispielcode (Erstellen eines einfachen naiven Bayes-Klassifikators mithilfe der Scikit-Learn-Bibliothek von Python):
from sklearn.naive_bayes import GaussianNBfrom sklearn.datasets import load_iris# 加载数据集iris = load_iris()X = iris.datay = iris.target# 创建朴素贝叶斯分类器对象gnb = GaussianNB()# 训练模型gnb.fit(X, y)# 进行预测predictions = gnb.predict(X)
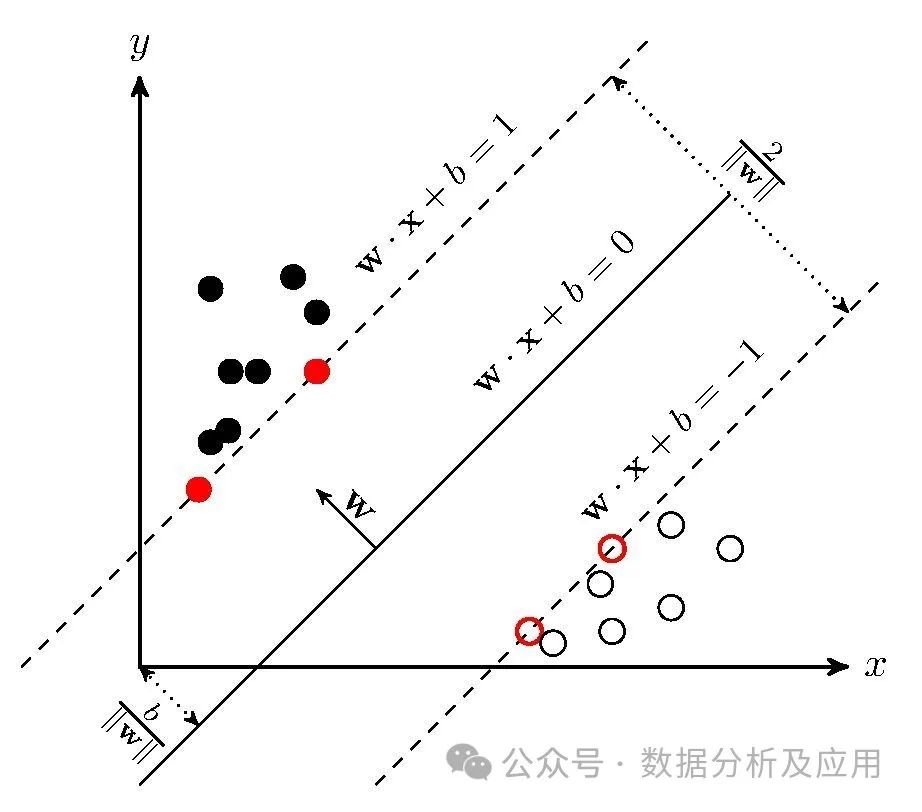
5、支持向量机(SVM):
模型原理:支持向量机是一种监督学习算法,用于分类和回归问题。它试图找到一个超平面,使得该超平面能够将不同类别的样本分隔开。SVM使用核函数来处理非线性问题。
模型训练:通过优化一个约束条件下的二次损失函数来训练SVM,以找到最佳的超平面。
优点:对高维数据和非线性问题表现良好,能够处理多分类问题。
缺点:对于大规模数据集计算复杂度高,对参数和核函数的选择敏感。
使用场景:适用于分类和回归问题,如图像识别、文本分类等。
示例代码(使用Python的Scikit-learn库构建一个简单的SVM分类器):
from sklearn import svmfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建SVM分类器对象,使用径向基核函数(RBF)clf = svm.SVC(kernel='rbf')# 训练模型clf.fit(X_train, y_train)# 进行预测predictions = clf.predict(X_test)
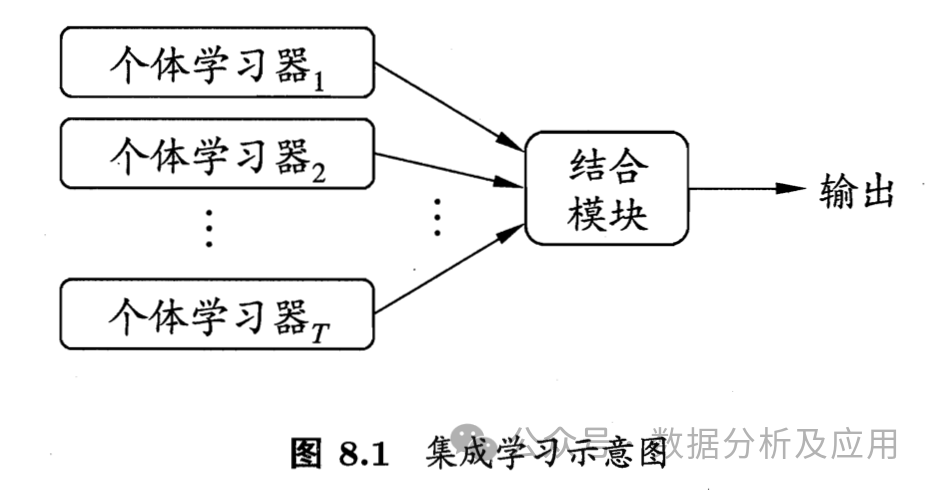
6、集成学习:
模型原理:集成学习是一种通过构建多个基本模型并将它们的预测结果组合起来以提高预测性能的方法。集成学习策略有投票法、平均法、堆叠法和梯度提升等。常见集成学习模型有XGBoost、随机森林、Adaboost等
模型训练:首先使用训练数据集训练多个基本模型,然后通过某种方式将它们的预测结果组合起来,形成最终的预测结果。
优点:可以提高模型的泛化能力,降低过拟合的风险。
缺点:计算复杂度高,需要更多的存储空间和计算资源。
使用场景:适用于解决分类和回归问题,尤其适用于大数据集和复杂的任务。
示例代码(使用Python的Scikit-learn库构建一个简单的投票集成分类器):
from sklearn.ensemble import VotingClassifierfrom sklearn.linear_model import LogisticRegressionfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建基本模型对象和集成分类器对象lr = LogisticRegression()dt = DecisionTreeClassifier()vc = VotingClassifier(estimators=[('lr', lr), ('dt', dt)], voting='hard')# 训练集成分类器vc.fit(X_train, y_train)# 进行预测predictions = vc.predict(X_test)7、K近邻算法:
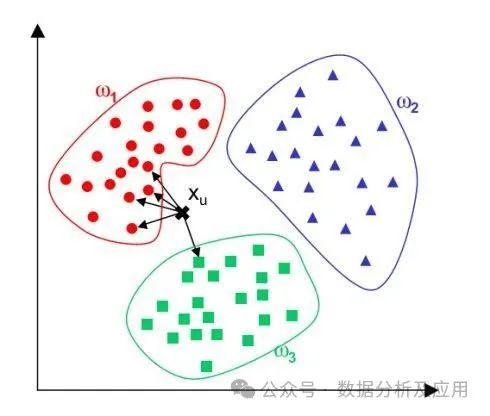
模型原理:K近邻算法是一种基于实例的学习,通过将新的样本与已知样本进行比较,找到与新样本最接近的K个样本,并根据这些样本的类别进行投票来预测新样本的类别。
模型训练:不需要训练阶段,通过计算新样本与已知样本之间的距离或相似度来找到最近的邻居。
优点:简单、易于理解,不需要训练阶段。
缺点:对于大规模数据集计算复杂度高,对参数K的选择敏感。
使用场景:适用于解决分类和回归问题,适用于相似度度量和分类任务。
示例代码(使用Python的Scikit-learn库构建一个简单的K近邻分类器):
from sklearn.neighbors import KNeighborsClassifierfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建K近邻分类器对象,K=3knn = KNeighborsClassifier(n_neighbors=3)# 训练模型knn.fit(X_train, y_train)# 进行预测predictions = knn.predict(X_test)
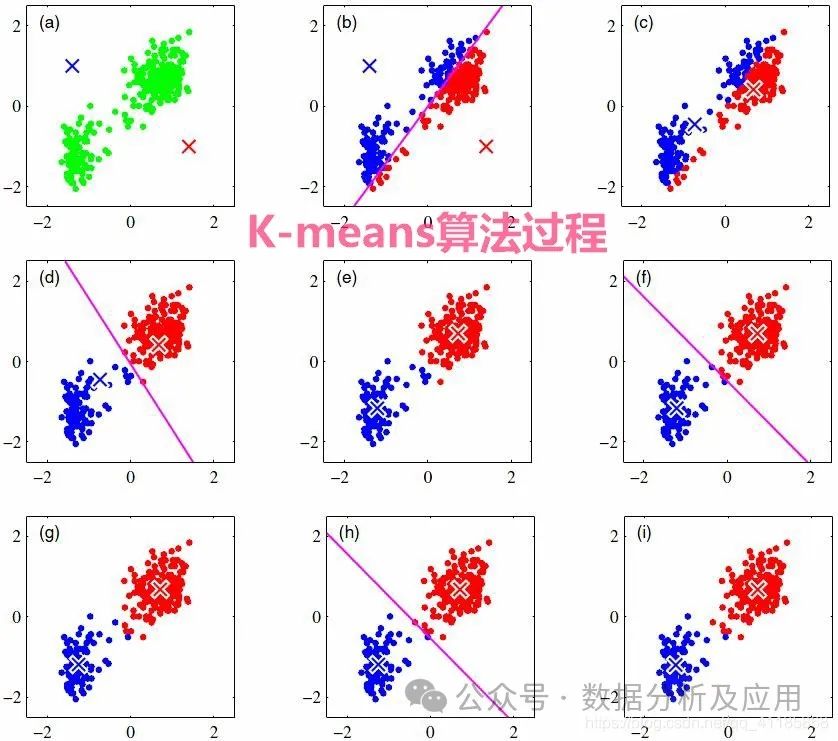
8、K-means算法:
模型原理:K-means算法是一种无监督学习算法,用于聚类问题。它将n个点(可以是样本数据点)划分为k个聚类,使得每个点属于最近的均值(聚类中心)对应的聚类。
模型训练:通过迭代更新聚类中心和分配每个点到最近的聚类中心来实现聚类。
优点:简单、快速,对于大规模数据集也能较好地运行。
缺点:对初始聚类中心敏感,可能会陷入局部最优解。
使用场景:适用于聚类问题,如市场细分、异常值检测等。
示例代码(使用Python的Scikit-learn库构建一个简单的K-means聚类器):
from sklearn.cluster import KMeansfrom sklearn.datasets import make_blobsimport matplotlib.pyplot as plt# 生成模拟数据集X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)# 创建K-means聚类器对象,K=4kmeans = KMeans(n_clusters=4)# 训练模型kmeans.fit(X)# 进行预测并获取聚类标签labels = kmeans.predict(X)# 可视化结果plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')plt.show()
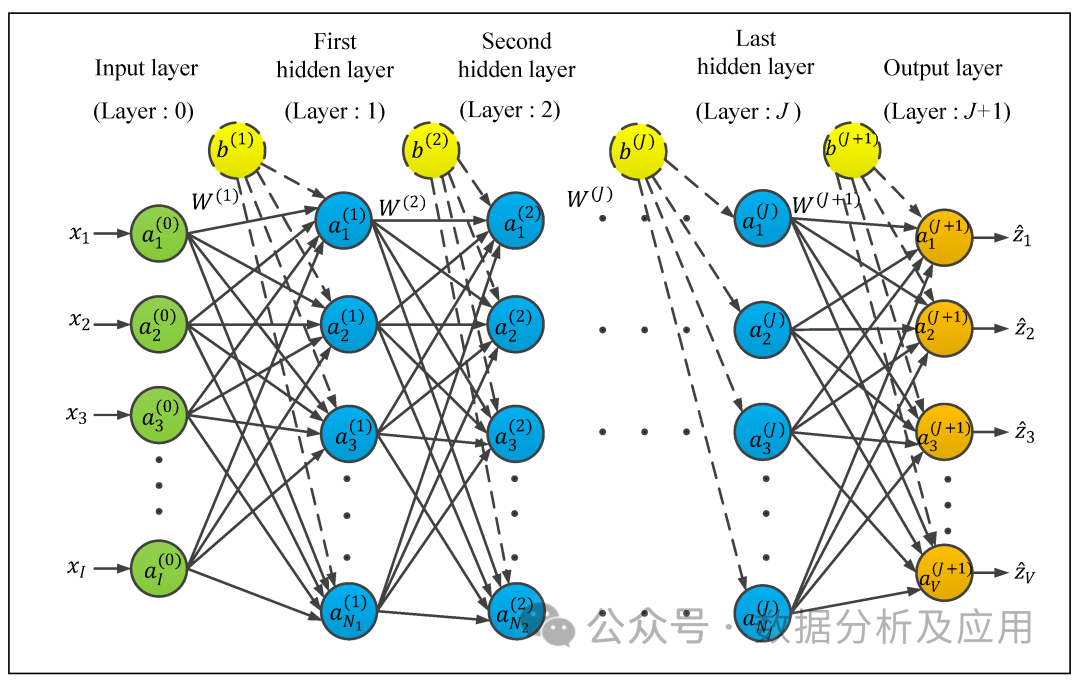
9、神经网络:
模型原理:神经网络是一种模拟人脑神经元结构的计算模型,通过模拟神经元的输入、输出和权重调整机制来实现复杂的模式识别和分类等功能。神经网络由多层神经元组成,输入层接收外界信号,经过各层神经元的处理后,最终输出层输出结果。
模型训练:神经网络的训练是通过反向传播算法实现的。在训练过程中,根据输出结果与实际结果的误差,逐层反向传播误差,并更新神经元的权重和偏置项,以减小误差。
优点:能够处理非线性问题,具有强大的模式识别能力,能够从大量数据中学习复杂的模式。
缺点:容易陷入局部最优解,过拟合问题严重,训练时间长,需要大量的数据和计算资源。
使用场景:适用于图像识别、语音识别、自然语言处理、推荐系统等场景。
示例代码(使用Python的TensorFlow库构建一个简单的神经网络分类器):
import tensorflow as tffrom tensorflow.keras import layers, modelsfrom tensorflow.keras.datasets import mnist# 加载MNIST数据集(x_train, y_train), (x_test, y_test) = mnist.load_data()# 归一化处理输入数据x_train = x_train / 255.0x_test = x_test / 255.0# 构建神经网络模型model = models.Sequential()model.add(layers.Flatten(input_shape=(28, 28)))model.add(layers.Dense(128, activation='relu'))model.add(layers.Dense(10, activation='softmax'))# 编译模型并设置损失函数和优化器等参数model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])# 训练模型model.fit(x_train, y_train, epochs=5)# 进行预测predictions = model.predict(x_test)
10.深度强化学习(DQN):
模型原理:Deep Q-Networks (DQN) 是一种结合了深度学习与Q-learning的强化学习算法。它的核心思想是使用神经网络来逼近Q函数,即状态-动作值函数,从而为智能体在给定状态下选择最优的动作提供依据。
模型训练:DQN的训练过程包括两个阶段:离线阶段和在线阶段。在离线阶段,智能体通过与环境的交互收集数据并训练神经网络。在线阶段,智能体使用神经网络进行动作选择和更新。为了解决过度估计问题,DQN引入了目标网络的概念,通过使目标网络在一段时间内保持稳定来提高稳定性。
优点:能够处理高维度的状态和动作空间,适用于连续动作空间的问题,具有较好的稳定性和泛化能力。
缺点:容易陷入局部最优解,需要大量的数据和计算资源,对参数的选择敏感。
使用场景:适用于游戏、机器人控制等场景。
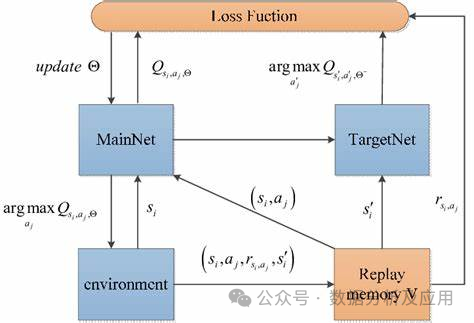
示例代码(使用Python的TensorFlow库构建一个简单的DQN强化学习模型):
import tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Dense, Dropout, Flattenfrom tensorflow.keras.optimizers import Adamfrom tensorflow.keras import backend as Kclass DQN:def __init__(self, state_size, action_size):self.state_size = state_sizeself.action_size = action_sizeself.memory = deque(maxlen=2000)self.gamma = 0.85self.epsilon = 1.0self.epsilon_min = 0.01self.epsilon_decay = 0.995self.learning_rate = 0.005self.model = self.create_model()self.target_model = self.create_model()self.target_model.set_weights(self.model.get_weights())def create_model(self):model = Sequential()model.add(Flatten(input_shape=(self.state_size,)))model.add(Dense(24, activation='relu'))model.add(Dense(24, activation='relu'))model.add(Dense(self.action_size, activation='linear'))return modeldef remember(self, state, action, reward, next_state, done):self.memory.append((state, action, reward, next_state, done))def act(self, state):if len(self.memory) > 1000:self.epsilon *= self.epsilon_decayif self.epsilon
Das obige ist der detaillierte Inhalt vonDie 10 wichtigsten Algorithmen für künstliche Intelligenz. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Implementierung und Anwendung des Python-Algorithmus für neuronale Netze (BP).
- So implementieren Sie einen Auswahlsortierungsalgorithmus in der Sprache C
- Was ist KI-Bildung mit künstlicher Intelligenz?
- Das Verstehen natürlicher Sprache ist ein wichtiges Anwendungsgebiet der künstlichen Intelligenz. Was ist ihr Ziel?
- So verstehen Sie den Seitenersetzungsalgorithmus