In einem Vortrag auf dem Weltwirtschaftsforum 2024 schlug Turing-Preisträger Yann LeCun vor, dass Modelle, die zur Verarbeitung von Videos verwendet werden, lernen sollten, Vorhersagen in einem abstrakten Darstellungsraum und nicht in einem bestimmten Pixelraum zu treffen [1]. Das multimodale Lernen der Videodarstellung mit Hilfe von Textinformationen kann Funktionen extrahieren, die für das Videoverständnis oder die Inhaltsgenerierung von Vorteil sind, was eine Schlüsseltechnologie zur Erleichterung dieses Prozesses darstellt. Das weit verbreitete Rauschkorrelationsphänomen zwischen aktuellen Videos und Textbeschreibungen behindert jedoch das Erlernen der Videodarstellung erheblich. Daher schlagen Forscher in diesem Artikel eine robuste Lernlösung für lange Videos vor, die auf der Theorie der optimalen Übertragung basiert, um dieser Herausforderung zu begegnen. Dieses Papier wurde von ICLR 2024, der führenden Konferenz für maschinelles Lernen, für Oral angenommen. 
- Papiertitel: Multi-granularity Correspondence Learning from Long-term Noisy Videos
- Papieradresse: https://openreview.net/pdf?id=9Cu8MRmhq2
- Projektadresse: https: //lin-yijie.github.io/projects/Norton
- Codeadresse: https://github.com/XLearning-SCU/2024-ICLR-Norton
Hintergrund und Herausforderungen Das Lernen von Videodarstellungen ist eines der heißesten Probleme in der multimodalen Forschung. Ein umfangreiches Vortraining in Videosprache hat bei einer Vielzahl von Videoverständnisaufgaben bemerkenswerte Ergebnisse erzielt, z. B. beim Abrufen von Videos, bei der Beantwortung visueller Fragen, bei der Segmentierung und Lokalisierung von Segmenten usw. Derzeit konzentrieren sich die meisten Vorbereitungsarbeiten zur Videosprache hauptsächlich auf das Segmentverständnis kurzer Videos und ignorieren die langfristigen Beziehungen und Abhängigkeiten, die in langen Videos bestehen. Wie in Abbildung 1 unten dargestellt, besteht die Hauptschwierigkeit beim Lernen langer Videos darin, die zeitliche Dynamik im Video zu kodieren. Aktuelle Lösungen konzentrieren sich hauptsächlich auf die Entwicklung maßgeschneiderter Videonetzwerk-Encoder zur Erfassung langfristiger Abhängigkeiten [2]. ist aber normalerweise mit einem großen Ressourcenaufwand verbunden.
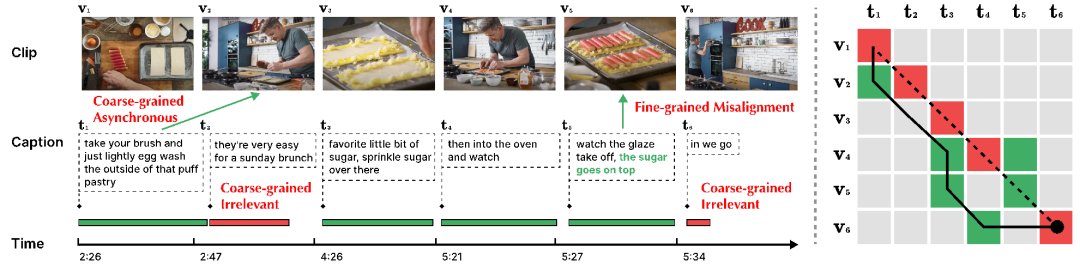
Abbildung 1: Beispiel für lange Videodaten [2]. Das Video enthält eine komplexe Handlung und eine reichhaltige zeitliche Dynamik. Jeder Satz kann nur ein kurzes Fragment beschreiben, und das Verständnis des gesamten Videos erfordert die Fähigkeit zur langfristigen Korrelationsbegründung. Da lange Videos normalerweise die automatische Spracherkennung (ASR) verwenden, um entsprechende Textuntertitel zu erhalten, kann der dem gesamten Video entsprechende Textabsatz (Absatz) basierend auf dem ASR-Textzeitstempel in mehrere kurze Texttitel unterteilt werden ( Untertitel) und ein langes Video (Video) kann entsprechend in mehrere Videoclips (Clip) unterteilt werden. Die Strategie der späten Fusion oder Ausrichtung von Videoclips und Titeln ist effizienter als die direkte Codierung des gesamten Videos und eine optimale Lösung für das langfristige Lernen zeitlicher Assoziationen. Allerdings besteht verrauschte Korrespondenz [3-4], NC) zwischen Videoclips und Textsätzen weithin, d. Wie in Abbildung 2 unten dargestellt, treten zwischen Video und Text Probleme mit der Korrelation von Rauschen mit mehreren Granularitäten auf.
Abbildung 2: Rauschkorrelation mit mehreren Granularitäten. In diesem Beispiel wird der Videoinhalt basierend auf dem Texttitel in 6 Teile unterteilt. (Links) Eine grüne Zeitleiste zeigt an, dass der Text an den Inhalt des Videos angepasst werden kann, während eine rote Zeitleiste angibt, dass der Text nicht an den Inhalt des gesamten Videos angepasst werden kann. Der grüne Text in t5 gibt den Teil an, der sich auf den Videoinhalt v5 bezieht. (Rechtes Bild) Die gepunktete Linie zeigt die ursprünglich angegebene Ausrichtungsbeziehung an, die rote Linie zeigt die falsche Ausrichtungsbeziehung in der ursprünglichen Ausrichtung an und die grüne zeigt die tatsächliche Ausrichtungsbeziehung an. Die durchgezogene Linie stellt das Ergebnis der Neuausrichtung durch den Dynamic Time Wraping-Algorithmus dar, der auch die Herausforderung der Rauschkorrelation nicht gut bewältigt.
- Grobkörniger NC (zwischen Clip-Beschriftung). Grobkörniges NC umfasst zwei Kategorien: asynchron (Asynchron) und irrelevant (Irrelevant). Der Unterschied besteht darin, ob der Videoclip oder Titel einem vorhandenen Titel oder Videoclip entsprechen kann. „Asynchron“ bezieht sich auf die zeitliche Fehlausrichtung zwischen dem Videoclip und dem Titel, z. B. t1 in Abbildung 2. Dadurch kommt es zu einer Diskrepanz zwischen der Abfolge von Aussagen und Handlungen, wie der Erzähler vor und nach der tatsächlichen Ausführung der Handlungen erklärt. „Irrelevant“ bezieht sich auf bedeutungslose Titel, die nicht den Videoclips zugeordnet werden können (z. B. t2 und t6), oder auf irrelevante Videoclips. Laut relevanter Forschung der Oxford Visual Geometry Group [5] sind nur etwa 30 % der Videoclips und Titel im HowTo100M-Datensatz visuell ausgerichtet und nur 15 % sind ursprünglich ausgerichtet
- Feinkörniges NC ( Rahmenwort) . Bei einem Videoclip ist möglicherweise nur ein Teil der Textbeschreibung relevant. In Abbildung 2 steht der Titel t5 „Zucker darüber streuen“ in engem Zusammenhang mit dem visuellen Inhalt v5, die Aktion „Beobachten Sie, wie sich die Glasur ablöst“ hat jedoch keinen Bezug zum visuellen Inhalt. Irrelevante Wörter oder Videobilder können die Extraktion wichtiger Informationen behindern und die Ausrichtung zwischen Segmenten und Titeln beeinträchtigen.
Dieses Papier schlägt eine geräuschrobuste Timing Optimal Transport (Norton) vor, durch Video-Absatz-Ebenen-Vergleichslernen und Segment-Titel-Ebenen-Vergleich Lernen, Lernvideo Darstellungen aus mehreren Granularitäten im Post-Fusion-Verfahren, wodurch der Trainingsaufwand erheblich gespart wird.
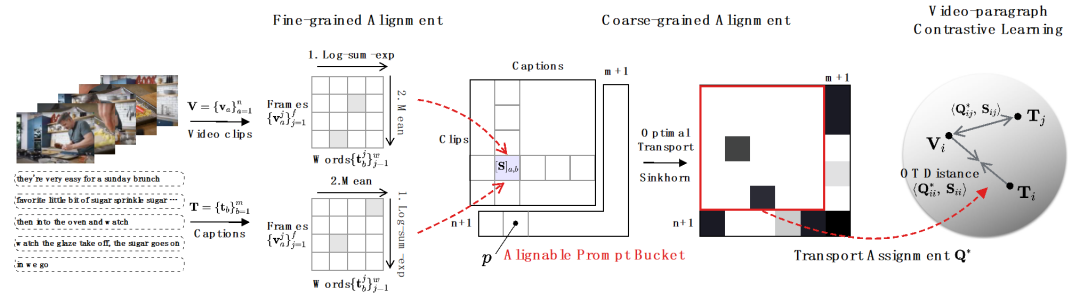
1) Video - Absatzvergleich. Wie in Abbildung 3 dargestellt, verwenden Forscher eine Fein-zu-Grob-Strategie, um Assoziationslernen mit mehreren Granularitäten durchzuführen. Zunächst wird die Rahmen-Wort-Korrelation verwendet, um die Segment-Titel-Korrelation zu erhalten, und eine weitere Aggregation wird verwendet, um die Video-Absatz-Korrelation zu erhalten, und schließlich wird die Langzeitkorrelation durch kontrastives Lernen auf Videoebene erfasst. Für die Multigranularitäts-Rauschenkorrelationsherausforderung lautet die spezifische Antwort wie folgt:
- für feinkörniges NC. Die Forscher verwenden die Log-Summe-Exp-Näherung als Soft-Maximum-Operator, um Schlüsselwörter und Schlüsselbilder in der Frame-Wort- und Wort-Frame-Ausrichtung zu identifizieren, die Extraktion wichtiger Informationen auf feinkörnige interaktive Weise zu realisieren und Ähnlichkeiten zwischen Segmenttiteln zu akkumulieren. Sex.
- Für grobkörnige asynchrone NC. Als Abstandsmaß zwischen Videoclips und Titeln verwendeten die Forscher die optimale Übertragungsentfernung. Gegeben ist eine Videoclip-Texttitel-Ähnlichkeitsmatrix , wobei die Anzahl der Clips und Titel darstellt. Das optimale Übertragungsziel besteht darin, die Gesamtausrichtungsähnlichkeit zu maximieren, die natürlich asynchrone oder eins-zu-viele-Timings verarbeiten kann (z. B. t3 und). v4, v5 entsprechend) komplexe Ausrichtungssituation.
wobei eine gleichmäßige Verteilung ist, die jedem Segment und Titel das gleiche Gewicht verleiht, der Übertragungszuweisungs- oder Neuausrichtungsmoment, der durch den Sinkhorn-Algorithmus gelöst werden kann. - Orientiert an grobkörniger irrelevanter NC. Inspiriert von SuperGlue [6] beim Feature-Matching entwerfen wir einen adaptiven, ausrichtbaren Hinweis-Bucket, um zu versuchen, irrelevante Segmente und Titel zu filtern. Der Prompt-Bucket ist ein Vektor mit demselben Wert in einer Zeile und einer Spalte, gespleißt auf der Ähnlichkeitsmatrix , und sein Wert stellt die Ähnlichkeitsschwelle dar, ob er ausgerichtet werden kann. Tip Buckets lassen sich nahtlos in den Optimal Transport Sinkhorn Solver integrieren.
Die Messung des Sequenzabstands durch optimale Übertragung statt der direkten Modellierung langer Videos kann den Rechenaufwand deutlich reduzieren. Die endgültige Funktion zum Verlust von Videoabsätzen lautet wie folgt, wobei die Ähnlichkeitsmatrix zwischen dem ten langen Video und dem ten Textabsatz darstellt.
2) Snippet - Titelvergleich . Dieser Verlust stellt die Genauigkeit der Segment-zu-Titel-Ausrichtung bei Video-Absatzvergleichen sicher. Da selbstüberwachtes kontrastives Lernen fälschlicherweise semantisch ähnliche Proben als negative Proben optimiert, nutzen wir die optimale Übertragung, um potenzielle falsch negative Proben zu identifizieren und zu korrigieren:
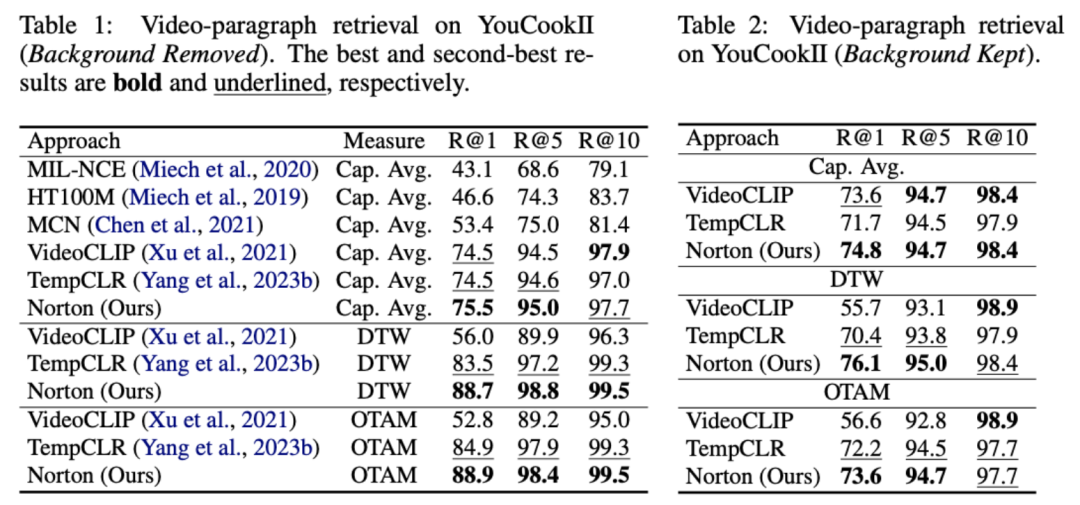
wobei alle Videoclips und Titel in der Trainingsstapelnummer, die Identität, darstellt Matrix stellt das Standardausrichtungsziel im Kreuzentropieverlust des kontrastiven Lernens dar, stellt das Neuausrichtungsziel nach Einbeziehung des optimalen Übertragungskorrekturziels dar und ist der Gewichtungskoeffizient. Dieser Artikel zielt darauf ab, die Rauschkorrelation zu überwinden, um die Fähigkeit des Modells zu verbessern, lange Videos zu verstehen. Wir haben es durch spezifische Aufgaben wie Videoabruf, Frage und Antwort sowie Aktionssegmentierung überprüft. Einige experimentelle Ergebnisse sind wie folgt. Das Ziel dieser Aufgabe besteht darin, das entsprechende lange Video anhand eines Textabsatzes abzurufen. Anhand des YouCookII-Datensatzes testeten die Forscher zwei Szenarien: Beibehaltung des Hintergrunds und Entfernung des Hintergrunds, je nachdem, ob textunabhängige Videoclips beibehalten werden sollen. Sie verwenden drei Ähnlichkeitsmesskriterien: Caption Average, DTW und OTAM. „Caption Average“ findet für jeden Titel im Textabsatz einen optimalen Videoclip und ruft schließlich das lange Video mit der größten Anzahl an Übereinstimmungen ab. DTW und OTAM akkumulieren den Abstand zwischen Video- und Textabsätzen in chronologischer Reihenfolge. Die Ergebnisse sind in den Tabellen 1 und 2 unten aufgeführt.
Tabelle 1, 2 Vergleich der Leistung beim Abruf langer Videos im YouCookII-Datensatz. 2) Rauschkorrelations-Robustheitsanalyse Videos in HowTo100M, durchgeführt von der Oxford Visual Geometry Group. Manuelle Neuannotation wurde durchgeführt, um jeden Texttitel mit dem richtigen Zeitstempel neu zu kommentieren. Der resultierende HTM-Align-Datensatz [5] enthält 80 Videos und 49.000 Texte. Der Videoabruf dieses Datensatzes überprüft hauptsächlich, ob das Modell die Rauschkorrelation überpasst. Die Ergebnisse sind in Tabelle 9 unten aufgeführt.
[3][4]——Eingehende Fortsetzung der Dateninkongruenz/Fehlerkorrelation, Untersuchung des Multigranularitäts-Rauschenkorrelationsproblems, mit dem man konfrontiert ist Durch das multimodale Video-Text-Vortraining kann die vorgeschlagene Lernmethode für lange Videos mit geringerem Ressourcenaufwand auf eine breitere Palette von Videodaten ausgeweitet werden.
Mit Blick auf die Zukunft können Forscher die Korrelation zwischen mehreren Modalitäten weiter untersuchen. Beispielsweise können Videos häufig visuelle, Text- und Audiosignale enthalten. Sie können versuchen, externe große Sprachmodelle (LLM) oder multimodale Modelle zu kombinieren (BLIP). -2) Den Textkorpus bereinigen und neu organisieren und die Möglichkeit untersuchen, Rauschen als positiven Anreiz für das Modelltraining zu nutzen, anstatt nur die negativen Auswirkungen von Rauschen zu unterdrücken. 1. Diese Seite, „Yann LeCun: Generative Modelle eignen sich nicht für die Verarbeitung von Videos, KI muss Vorhersagen im abstrakten Raum treffen“, 23.01.2024.
2. Sun, Y., Xue, H., Song, R., Liu, B., Yang, H. & Fu, J. (2022). mit multimodalem zeitlichem Kontrastlernen, 35, 38032-38045.3. Huang, Z., Niu, G., Liu, X., Ding, W., Xiao, ., Wu, H., & Peng, , Yang, M., Yu, J., Hu, P., Zhang, C., & Peng, X. (2023). Tagungsband der internationalen IEEE/CVF-Konferenz zum Thema Computer Vision der IEEE/CVF-Konferenz zu Computer Vision und Mustererkennung (S. 2906–2916). . Superglue: Learning Feature Matching mit graphischen neuronalen Netzen. In Proceedings der IEEE/CVF-Konferenz zu Computer Vision und Mustererkennung (S. 4938-4947).Das obige ist der detaillierte Inhalt vonICLR 2024 Mündlich: Rauschkorrelationslernen in langen Videos, Einzelkartentraining dauert nur 1 Tag. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!




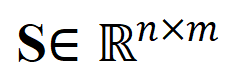 , wobei
, wobei 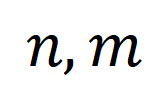 die Anzahl der Clips und Titel darstellt. Das optimale Übertragungsziel besteht darin, die Gesamtausrichtungsähnlichkeit zu maximieren, die natürlich asynchrone oder eins-zu-viele-Timings verarbeiten kann (z. B. t3 und). v4, v5 entsprechend) komplexe Ausrichtungssituation.
die Anzahl der Clips und Titel darstellt. Das optimale Übertragungsziel besteht darin, die Gesamtausrichtungsähnlichkeit zu maximieren, die natürlich asynchrone oder eins-zu-viele-Timings verarbeiten kann (z. B. t3 und). v4, v5 entsprechend) komplexe Ausrichtungssituation. 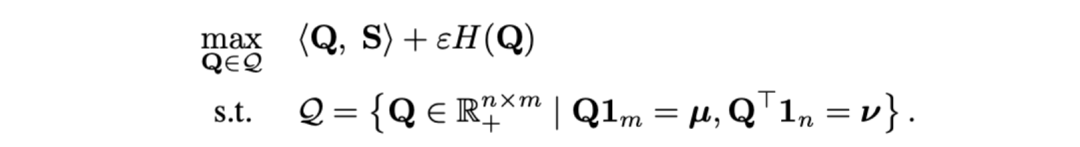
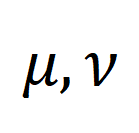 eine gleichmäßige Verteilung ist, die jedem Segment und Titel das gleiche Gewicht verleiht,
eine gleichmäßige Verteilung ist, die jedem Segment und Titel das gleiche Gewicht verleiht, 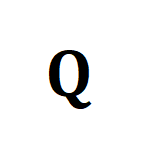 der Übertragungszuweisungs- oder Neuausrichtungsmoment, der durch den Sinkhorn-Algorithmus gelöst werden kann.
der Übertragungszuweisungs- oder Neuausrichtungsmoment, der durch den Sinkhorn-Algorithmus gelöst werden kann. 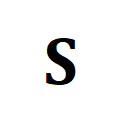 , und sein Wert stellt die Ähnlichkeitsschwelle dar, ob er ausgerichtet werden kann. Tip Buckets lassen sich nahtlos in den Optimal Transport Sinkhorn Solver integrieren.
, und sein Wert stellt die Ähnlichkeitsschwelle dar, ob er ausgerichtet werden kann. Tip Buckets lassen sich nahtlos in den Optimal Transport Sinkhorn Solver integrieren. 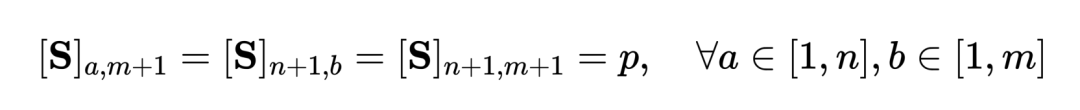
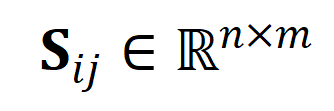 die Ähnlichkeitsmatrix zwischen dem
die Ähnlichkeitsmatrix zwischen dem 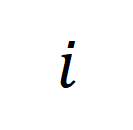 ten langen Video und dem
ten langen Video und dem 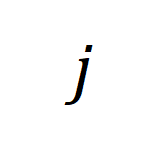 ten Textabsatz darstellt.
ten Textabsatz darstellt. 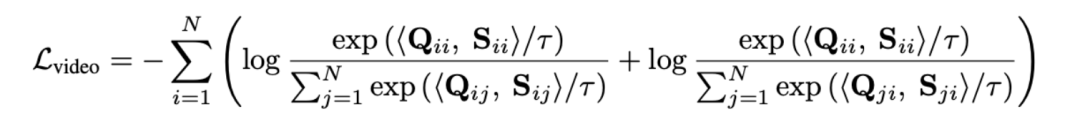
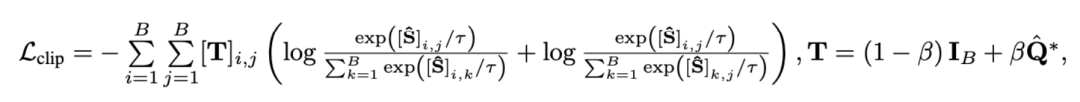
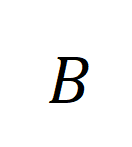 alle Videoclips und Titel in der Trainingsstapelnummer, die Identität, darstellt Matrix
alle Videoclips und Titel in der Trainingsstapelnummer, die Identität, darstellt Matrix 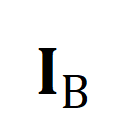 stellt das Standardausrichtungsziel im Kreuzentropieverlust des kontrastiven Lernens dar,
stellt das Standardausrichtungsziel im Kreuzentropieverlust des kontrastiven Lernens dar, 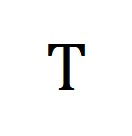 stellt das Neuausrichtungsziel nach Einbeziehung des optimalen Übertragungskorrekturziels
stellt das Neuausrichtungsziel nach Einbeziehung des optimalen Übertragungskorrekturziels 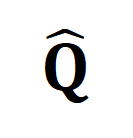 dar und
dar und 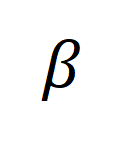 ist der Gewichtungskoeffizient.
ist der Gewichtungskoeffizient.