
Heim >Technologie-Peripheriegeräte >KI >DeepMind CEO: LLM+Tree Search ist die AGI-Technologielinie für wissenschaftliche Forschung, die auf technischen Fähigkeiten basiert. Closed-Source-Modelle sind sicherer als Open-Source-Modelle.
DeepMind CEO: LLM+Tree Search ist die AGI-Technologielinie für wissenschaftliche Forschung, die auf technischen Fähigkeiten basiert. Closed-Source-Modelle sind sicherer als Open-Source-Modelle.

- PHPznach vorne
- 2024-03-05 12:04:18459Durchsuche
Google wechselte nach Februar plötzlich in den 996-Modus und brachte in weniger als einem Monat fünf Modelle auf den Markt.
Und DeepMind-CEO Hassabis selbst hat auch für seine eigene Produktplattform geworben und viele Insiderinformationen hinter den Kulissen der Entwicklung preisgegeben.
Obwohl noch technologische Durchbrüche nötig sind, ist seiner Ansicht nach der Weg zur AGI für den Menschen jetzt geebnet.
Der Zusammenschluss von DeepMind und Google Brain markiert, dass die Entwicklung der KI-Technologie in eine neue Ära eingetreten ist.
F: DeepMind war schon immer an der Spitze der Technologie. In einem System wie AlphaZero kann der interne intelligente Agent beispielsweise das Endziel durch eine Reihe von Gedanken erreichen. Bedeutet das, dass auch große Sprachmodelle (LLM) in die Riege dieser Art von Forschung aufgenommen werden können?
Hassabis glaubt, dass großmaßstäbliche Modelle ein enormes Potenzial haben und weiter optimiert werden müssen, um ihre Vorhersagegenauigkeit zu verbessern und dadurch zuverlässigere Weltmodelle zu erstellen. Obwohl dieser Schritt von entscheidender Bedeutung ist, reicht er möglicherweise nicht aus, um ein vollständiges System der künstlichen allgemeinen Intelligenz (AGI) aufzubauen.
Auf dieser Basis entwickeln wir einen Planungsmechanismus ähnlich AlphaZero, um Pläne zur Erreichung spezifischer Weltziele durch das Weltmodell zu formulieren.
Dazu gehört das Aneinanderreihen verschiedener Denk- oder Argumentationsketten oder die Verwendung von Baumsuchen, um einen riesigen Raum an Möglichkeiten zu erkunden.
Das sind die fehlenden Glieder in unseren aktuellen Großmodellen.
F: Ist es möglich, ausgehend von reinen Reinforcement-Learning-Methoden (RL) direkt zu AGI überzugehen?
Es scheint, dass große Sprachmodelle das grundlegende Vorwissen bilden werden und dann auf dieser Grundlage weitere Forschungen durchgeführt werden können.
Theoretisch ist es möglich, die Methode zur Entwicklung von AlphaZero vollständig zu übernehmen.
Einige Leute in DeepMind und der RL-Community arbeiten in diese Richtung. Sie fangen bei Null an und verlassen sich nicht auf Vorkenntnisse oder Daten, um ein neues Wissenssystem aufzubauen.
Ich glaube, dass die Nutzung des vorhandenen Weltwissens – wie Informationen im Internet und Daten, die wir bereits sammeln – der schnellste Weg zur Erreichung von AGI sein wird.
Wir verfügen nun über skalierbare Algorithmen – Transformer – die diese Informationen aufnehmen können. Wir können diese vorhandenen Modelle vollständig als Vorwissen für Vorhersagen und Lernen nutzen.
Daher glaube ich, dass das endgültige AGI-System auf jeden Fall die heutigen großen Modelle als Teil der Lösung einbeziehen wird.
Aber ein großes Modell allein reicht nicht aus, wir müssen es auch um weitere Planungs- und Suchfunktionen erweitern.
F: Wie können wir angesichts der enormen Rechenressourcen, die diese Methoden erfordern, einen Durchbruch erzielen?
Sogar ein System wie AlphaGo ist ziemlich teuer, da Berechnungen für jeden Knoten des Entscheidungsbaums durchgeführt werden müssen.
Wir engagieren uns für die Entwicklung stichprobeneffizienter Methoden und Strategien zur Wiederverwendung vorhandener Daten, wie z. B. Experience Replay, sowie für die Erforschung effizienterer Methoden.
Tatsächlich kann Ihre Suche effizienter sein, wenn das Weltmodell gut genug ist.
Nehmen Sie Alpha Zero als Beispiel. Seine Leistung in Spielen wie Go und Schach übertrifft das Weltmeisterschaftsniveau, aber sein Suchbereich ist viel kleiner als bei herkömmlichen Brute-Force-Suchmethoden.
Dies zeigt, dass eine Verbesserung des Modells die Suche effizienter machen und so weitere Ziele erreichen kann.
Aber bei der Definition der Belohnungsfunktion und des Belohnungsziels wird es eine der Herausforderungen sein, vor denen wir stehen, wie wir sicherstellen können, dass sich das System in die richtige Richtung entwickelt.
Warum kann Google in einem halben Monat 5 Modelle produzieren?
F: Können Sie uns erklären, warum Google und DeepMind gleichzeitig an so vielen verschiedenen Modellen arbeiten?
Da wir Grundlagenforschung betreiben, verfügen wir über eine große Menge an Grundlagenforschungsarbeiten, die eine Vielzahl unterschiedlicher Innovationen und Richtungen abdecken.
Das bedeutet, dass während wir die Hauptmodellstrecke – das Kernmodell von Gemini – aufbauen, auch viele weitere Erkundungsprojekte im Gange sind.
Wenn diese Explorationsprojekte einige Ergebnisse haben, werden wir sie im Hauptzweig der nächsten Version von Gemini zusammenführen, weshalb 1.5 unmittelbar nach 1.0 veröffentlicht wird, da wir bereits an der nächsten Version arbeiten. Ja, Da wir mehrere Teams haben, die in unterschiedlichen Zeiträumen arbeiten und abwechselnd arbeiten, können wir auf diese Weise weiterhin Fortschritte machen.
Ich hoffe, dass dies unsere neue Normalität wird und wir Produkte mit dieser hohen Geschwindigkeit auf den Markt bringen, aber natürlich gehen wir auch sehr verantwortungsbewusst vor und bedenken, dass die Veröffentlichung sicherer Modelle für uns oberste Priorität hat.
F: Ich wollte nach Ihrer neuesten großen Veröffentlichung, Gemini 1.5 Pro, fragen. Ihr neues Gemini Pro 1.5-Modell kann bis zu einer Million Token verarbeiten. Können Sie erklären, was das bedeutet und warum das Kontextfenster ein wichtiger technischer Indikator ist?
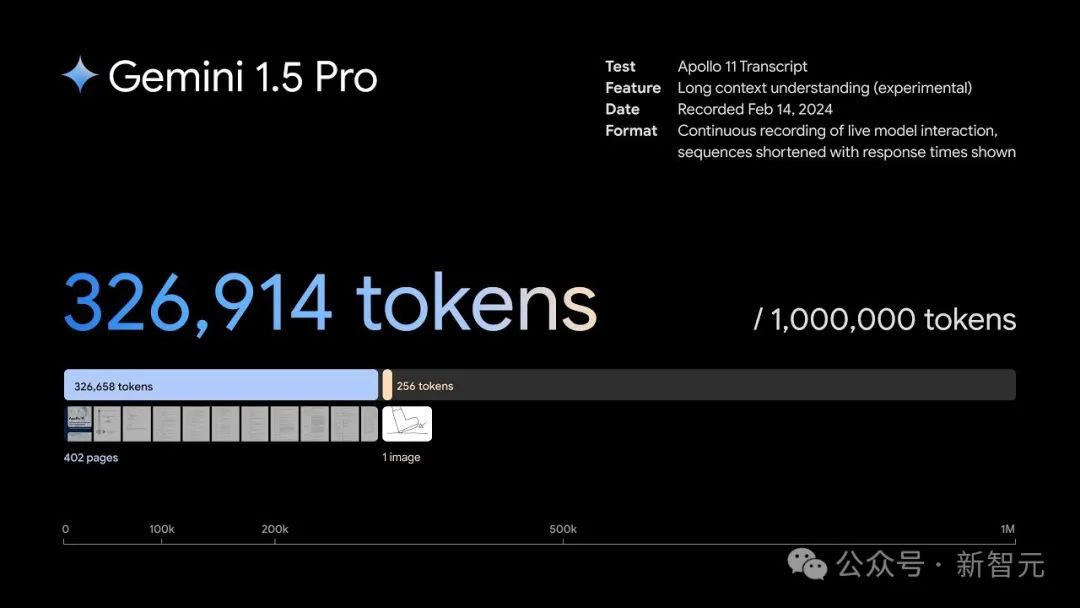
Ja, das ist sehr wichtig. Der lange Kontext kann als Arbeitsgedächtnis des Modells betrachtet werden, d. h. wie viele Daten es sich gleichzeitig merken und verarbeiten kann.
Je länger der Kontext ist, dessen Genauigkeit ebenfalls wichtig ist. Die Genauigkeit beim Abrufen von Dingen aus dem langen Kontext ist ebenfalls wichtig. Je mehr Daten und Kontext Sie berücksichtigen können.
Eine Million bedeutet also, dass Sie mit riesigen Büchern, ganzen Filmen, Tonnen von Audioinhalten und vollständigen Codebasen umgehen können.
Wenn Sie ein kürzeres Kontextfenster haben, sagen wir nur einhunderttausend Ebenen, dann können Sie nur Fragmente davon verarbeiten, und das Modell kann nicht den gesamten Korpus, an dem Sie interessiert sind, begründen oder abrufen.
Das eröffnet also tatsächlich Möglichkeiten für alle Arten neuer Anwendungsfälle, die mit kleinen Kontexten nicht möglich sind.
F: Ich habe von KI-Forschern gehört, dass das Problem mit diesen großen Kontextfenstern darin besteht, dass sie sehr rechenintensiv sind. Wenn Sie beispielsweise einen ganzen Film oder ein Biologielehrbuch hochladen und Fragen dazu stellen würden, wäre mehr Rechenleistung erforderlich, um all diese Informationen zu verarbeiten und zu beantworten. Wenn das viele machen, können sich die Kosten schnell summieren. Hat sich Google DeepMind eine clevere Innovation einfallen lassen, um diese riesigen Kontextfenster effizienter zu machen, oder hat Google nur die Kosten für all diese zusätzlichen Berechnungen getragen?
Ja, das ist eine völlig neue Innovation, denn ohne Innovation kann man keinen so langen Kontext haben.
Da dies jedoch immer noch einen hohen Rechenaufwand erfordert, arbeiten wir hart daran, es zu optimieren.
Wenn Sie das gesamte Kontextfenster ausfüllen. Die erstmalige Verarbeitung der hochgeladenen Daten kann mehrere Minuten dauern.
Aber es ist nicht so schlimm, wenn man bedenkt, dass es so ist, als würde man in ein oder zwei Minuten einen ganzen Film ansehen oder „Krieg und Frieden“ vollständig lesen und dann alle Fragen dazu beantworten können.
Dann möchten wir sicherstellen, dass nach dem Hochladen und Bearbeiten eines Dokuments, Videos oder Audios schneller weitere Fragen und Antworten gestellt werden.
Daran arbeiten wir derzeit und wir sind sehr zuversichtlich, dass wir es auf eine Frage von Sekunden bringen können.
F: Sie sagten, Sie hätten das System mit bis zu 10 Millionen Token getestet.
Hat in unseren Tests wirklich gut funktioniert. Da der Rechenaufwand noch relativ hoch ist, ist der Dienst derzeit nicht verfügbar.
Aber in Bezug auf Genauigkeit und Erinnerung schneidet es sehr gut ab.
F: Ich möchte Sie zu Gemini fragen. Welche besonderen Dinge können Gemini, die frühere Google-Sprachmodelle oder andere Modelle nicht konnten?
Nun, ich denke, das Spannende an Gemini, insbesondere an Version 1.5, ist, dass es von Natur aus multimodal ist und wir es von Grund auf so entwickelt haben, dass es jede Art von Eingabe verarbeiten kann: Text, Bilder, Code, Video.
Wenn Sie es mit einem langen Kontext kombinieren, können Sie sein Potenzial erkennen. Sie können sich zum Beispiel vorstellen, dass Sie sich eine ganze Vorlesung anhören oder dass Sie ein wichtiges Konzept verstehen möchten und schnell dorthin vorspulen möchten.
Jetzt können wir also die gesamte Codebasis in ein Kontextfenster einfügen, was für neue Programmierer, die gerade anfangen, sehr nützlich ist. Nehmen wir an, Sie sind ein neuer Ingenieur, der am Montag mit der Arbeit beginnt. Normalerweise müssen Sie sich Hunderttausende Zeilen Code ansehen.
Sie müssen die Experten zur Codebasis fragen. Aber jetzt können Sie Gemini auf diese unterhaltsame Weise tatsächlich als Codierungsassistenten verwenden. Es wird eine Zusammenfassung zurückgegeben, die Ihnen sagt, wo sich die wichtigen Teile des Codes befinden, und Sie können mit der Arbeit beginnen.
Ich denke, diese Fähigkeit ist sehr hilfreich und macht Ihren täglichen Arbeitsablauf effizienter.
Ich freue mich wirklich darauf zu sehen, wie sich Gemini schlägt, wenn es in etwas wie Slack und Ihren allgemeinen Arbeitsablauf integriert wird. Wie wird der Workflow der Zukunft aussehen? Ich denke, wir fangen gerade erst an, die Veränderungen zu erleben.
Googles oberste Priorität für Open Source ist Sicherheit
F: Ich möchte mich jetzt Gemma zuwenden, einer Reihe leichter Open-Source-Modelle, die Sie gerade veröffentlicht haben. Heutzutage scheint die Frage, ob zugrunde liegende Modelle über Open Source veröffentlicht oder geschlossen bleiben sollen, eines der umstrittensten Themen zu sein. Bisher hat Google sein zugrunde liegendes Modell Closed Source beibehalten. Warum jetzt Open Source wählen? Was halten Sie von der Kritik, dass die Bereitstellung zugrunde liegender Modelle über Open Source das Risiko und die Wahrscheinlichkeit erhöht, dass sie von böswilligen Akteuren genutzt werden?
Ja, ich habe dieses Thema tatsächlich schon oft öffentlich diskutiert.
Eines der Hauptanliegen ist, dass Open Source und Open Research im Allgemeinen eindeutig von Vorteil sind. Aber hier gibt es ein spezifisches Problem, und das hängt mit AGI- und KI-Technologien zusammen, weil sie universell sind.
Sobald Sie sie veröffentlichen, können böswillige Akteure sie für schädliche Zwecke verwenden.
Natürlich haben Sie, sobald Sie etwas als Open-Source-Lösung geöffnet haben, keine wirkliche Möglichkeit, es zurückzugewinnen, im Gegensatz zu Dingen wie dem API-Zugriff, den Sie einfach sperren können, wenn Sie feststellen, dass es nachgelagerte schädliche Anwendungsfälle gibt, an die noch niemand gedacht hat . Zugang.
Ich denke, das bedeutet, dass die Messlatte für Sicherheit, Robustheit und Verantwortlichkeit noch höher liegt. Je näher wir AGIs kommen, desto leistungsfähiger werden sie. Wir müssen daher vorsichtiger sein, wofür sie von böswilligen Akteuren verwendet werden könnten.
Ich habe noch kein gutes Argument von denen gehört, die Open Source unterstützen, wie zum Beispiel die Open-Source-Extremisten, von denen viele meine angesehenen Kollegen in der Wissenschaft sind, wie sie diese Frage beantworten – im Einklang mit der Verhinderung von Open-Source-Modellen mehr böswilligen Akteuren Zugriff auf das Modell gewähren?
Wir müssen mehr über diese Probleme nachdenken, da diese Systeme immer leistungsfähiger werden.
F: Warum hat Gemma Sie wegen dieses Problems nicht beunruhigt?

Ja natürlich, wie Sie feststellen werden, bietet Gemma nur leichte Versionen an, die also relativ klein sind.
Tatsächlich ist die kleinere Größe für Entwickler nützlicher, da normalerweise einzelne Entwickler, Akademiker oder kleine Teams schnell an ihren Laptops arbeiten möchten und daher dafür optimiert sind.
Da es sich nicht um Spitzenmodelle, sondern um kleine Modelle handelt, sind wir beruhigt, dass mit einem Modell keine großen Risiken verbunden sind, da die Fähigkeiten dieser Modelle gründlich getestet wurden und wir sehr gut wissen, wozu sie fähig sind dieser Größe.
Warum DeepMind mit Google Brain fusioniert
F: Letztes Jahr, als Google Brain und DeepMind fusionierten, waren einige Leute, die ich aus der KI-Branche kenne, besorgt. Sie befürchten, dass Google DeepMind in der Vergangenheit beträchtlichen Spielraum für die Arbeit an verschiedenen Forschungsprojekten eingeräumt hat, die das Unternehmen für wichtig hält.
Mit der Fusion muss DeepMind möglicherweise auf Dinge umgelenkt werden, die kurzfristig für Google von Nutzen sind, und nicht auf diese längerfristigen Grundlagenforschungsprojekte. Seit der Fusion ist ein Jahr vergangen. Hat diese Spannung zwischen kurzfristigem Interesse an Google und möglichen langfristigen KI-Fortschritten Ihre Arbeitsmöglichkeiten verändert?
Ja, dieses erste Jahr war alles großartig, wie du erwähnt hast. Ein Grund dafür ist, dass wir denken, dass jetzt der richtige Zeitpunkt ist, und ich denke, dass es aus Forschersicht der richtige Zeitpunkt ist.
Vielleicht gehen wir fünf oder sechs Jahre zurück, als wir Dinge wie AlphaGo machten, im KI-Bereich haben wir explorativ untersucht, wie wir zu AGI gelangen, welche Durchbrüche erforderlich sind, worauf man setzen sollte usw Es gibt ein breites Spektrum an Dingen, die man tun möchte. Ich denke, das ist eine sehr explorative Phase.
Ich denke, in den letzten zwei, drei Jahren ist klar geworden, was die Hauptbestandteile von AGI sein werden, wie ich bereits erwähnt habe, obwohl wir immer noch neue Innovationen brauchen.

Ich denke, Sie haben gerade den langen Kontext von Gemini1.5 gesehen, und ich denke, dass viele neue Innovationen wie diese erforderlich sein werden, daher ist Grundlagenforschung immer noch so wichtig wie eh und je.
Aber jetzt müssen wir auch hart in die technische Richtung arbeiten, das heißt, bekannte Technologien erweitern und nutzen und sie an ihre Grenzen bringen. Dies erfordert sehr kreatives Engineering im Maßstab, von der Hardware auf Prototypenebene bis hin zum Rechenzentrumsmaßstab. und die damit verbundenen Effizienzprobleme.
Ein weiterer Grund ist, dass man, wenn man vor fünf oder sechs Jahren KI-gesteuerte Produkte herstellen würde, eine KI hätte entwickeln müssen, die sich völlig von der AGI-Forschungsstrecke unterschied.
Es kann nur Aufgaben in speziellen Szenarien für bestimmte Produkte ausführen. Es handelt sich um eine Art maßgeschneiderte KI, „handgemachte KI“.
Aber heute ist alles anders. Um KI für Produkte einzusetzen, ist es jetzt am besten, allgemeine KI-Technologien und -Systeme zu nutzen, da diese ein ausreichendes Maß an Komplexität und Leistungsfähigkeit erreicht haben.
Das ist also tatsächlich ein Konvergenzpunkt, sodass Sie jetzt sehen können, dass der Forschungs-Track und der Produkt-Track zusammengeführt wurden.
Zum Beispiel werden wir jetzt einen KI-Sprachassistenten entwickeln, und das Gegenteil ist ein Chatbot, der Sprache wirklich versteht. Sie sind jetzt integriert, sodass keine Notwendigkeit besteht, diese Dichotomie oder koordinierte und angespannte Beziehung zu berücksichtigen.
Der zweite Grund ist, dass eine enge Rückkopplungsschleife zwischen Forschung und realer Anwendung für die Forschung tatsächlich sehr vorteilhaft ist.
Aufgrund der Art und Weise, wie das Produkt es Ihnen ermöglicht, wirklich zu verstehen, wie gut Ihr Modell funktioniert, können Sie akademische Metriken verwenden, aber der eigentliche Test besteht darin, dass Millionen von Benutzern Ihr Produkt verwenden. Finden sie es nützlich? Ist es nützlich? Ist es hilfreich und ist es gut für die Welt?
Man wird natürlich viel Feedback bekommen und das wird dann zu sehr schnellen Verbesserungen des zugrunde liegenden Modells führen, daher denke ich, dass wir uns gerade in dieser sehr, sehr aufregenden Phase befinden.
Das obige ist der detaillierte Inhalt vonDeepMind CEO: LLM+Tree Search ist die AGI-Technologielinie für wissenschaftliche Forschung, die auf technischen Fähigkeiten basiert. Closed-Source-Modelle sind sicherer als Open-Source-Modelle.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Praktisches Schulungsvideo-Tutorial zum funktionalen Design von Java-Softwaresystemen
- Wie vergleiche ich zwei Tabellen, um dieselben Daten herauszufiltern?
- So wählen Sie schnell eine Datenspalte aus
- Das Training von ViT und MAE reduziert den Rechenaufwand um die Hälfte! Sea und die Peking-Universität haben gemeinsam den effizienten Optimierer Adan vorgeschlagen, der für tiefe Modelle verwendet werden kann
- Musk kündigt an, dass er Microsoft wegen der Verwendung von Twitter-Daten zum Trainieren künstlicher Intelligenz verklagen wird