
Heim >Technologie-Peripheriegeräte >KI >Beispielloses UniVision: BEV-Erkennung und gemeinsames Occ-Framework, duales SOTA!
Beispielloses UniVision: BEV-Erkennung und gemeinsames Occ-Framework, duales SOTA!

- 王林nach vorne
- 2024-03-04 15:55:02407Durchsuche
Vorher geschrieben & persönliches Verständnis
In den letzten Jahren hat die visionszentrierte 3D-Wahrnehmung in der autonomen Fahrtechnologie rasante Fortschritte gemacht. Obwohl verschiedene 3D-Wahrnehmungsmodelle viele strukturelle und konzeptionelle Ähnlichkeiten aufweisen, gibt es dennoch einige Unterschiede in der Merkmalsdarstellung, den Datenformaten und Zielen, was die Gestaltung eines einheitlichen und effizienten 3D-Wahrnehmungsrahmens vor Herausforderungen stellt. Daher arbeiten Forscher intensiv daran, Lösungen zu finden, um die Unterschiede zwischen verschiedenen Modellen besser zu integrieren und so vollständigere und effizientere 3D-Wahrnehmungssysteme aufzubauen. Es wird erwartet, dass diese Art von Bemühungen zuverlässigere und fortschrittlichere Technologien in den Bereich des autonomen Fahrens bringen und diese in komplexen Umgebungen leistungsfähiger machen. Insbesondere für Erkennungsaufgaben und Belegungsaufgaben unter BEV ist es immer noch schwierig, gemeinsames Training durchzuführen Unkontrollierbare Effekte bereiten bei vielen Anwendungen Kopfschmerzen. UniVision ist ein einfaches und effizientes Framework, das zwei Hauptaufgaben der visionszentrierten 3D-Wahrnehmung vereint, nämlich Belegungsvorhersage und Objekterkennung. Der Kernpunkt ist ein explizit-implizites Ansichtstransformationsmodul für die komplementäre 2D-3D-Merkmalstransformation. UniVision schlägt ein lokales und globales Merkmalsextraktions- und Fusionsmodul für eine effiziente und adaptive Voxel- und BEV-Merkmalsextraktion, -verbesserung und -interaktion vor.
Im Datenverbesserungsteil schlug UniVision außerdem eine gemeinsame Datenverbesserungsstrategie für die Belegungserkennung und eine progressive Gewichtsanpassungsstrategie vor, um die Effizienz und Stabilität des Multitasking-Framework-Trainings zu verbessern. Es werden umfangreiche Experimente zu verschiedenen Wahrnehmungsaufgaben an vier öffentlichen Benchmarks durchgeführt, darunter szenenfreie Lidar-Segmentierung, szenenfreie Erkennung, OpenOccupancy und Occ3D. UniVision erreichte SOTA mit Zuwächsen von +1,5 mIoU, +1,8 NDS, +1,5 mIoU bzw. +1,8 mIoU bei jedem Benchmark. Das UniVision-Framework kann als leistungsstarke Basis für einheitliche visionszentrierte 3D-Wahrnehmungsaufgaben dienen.
Wenn Sie mit BEV- und Belegungsaufgaben nicht vertraut sind, können Sie gerne unser
BEV-Wahrnehmungs-Tutorialund das Belegungsnetzwerk-Tutorial weiter studieren, um weitere technische Details zu erfahren!
Der aktuelle Stand auf dem Gebiet der 3D-Wahrnehmung3D-Wahrnehmung ist die Hauptaufgabe autonomer Fahrsysteme. Ihr Zweck besteht darin, Daten aus einer Reihe von Sensoren (wie Lidar, Radar und Kameras) zu nutzen, um sie umfassend zu verstehen der Fahrszene für die spätere Nutzungsplanung und Entscheidungsfindung. In der Vergangenheit wurde der Bereich der 3D-Wahrnehmung aufgrund der präzisen 3D-Informationen, die aus Punktwolkendaten abgeleitet wurden, von Lidar-basierten Modellen dominiert. Allerdings sind Lidar-basierte Systeme kostspielig, anfällig für Unwetter und unpraktisch in der Bereitstellung. Im Gegensatz dazu bieten visionsbasierte Systeme viele Vorteile, wie etwa niedrige Kosten, einfache Bereitstellung und gute Skalierbarkeit. Daher hat die visionszentrierte dreidimensionale Wahrnehmung bei Forschern große Aufmerksamkeit erregt.
Kürzlich wurde die visionsbasierte 3D-Erkennung durch Feature-Repräsentationstransformation, zeitliche Fusion und überwachtes Signaldesign erheblich verbessert und die Lücke zu Lidar-basierten Modellen kontinuierlich geschlossen. Darüber hinaus haben sich visionsbasierte Belegungsaufgaben in den letzten Jahren rasant weiterentwickelt. Im Gegensatz zur Verwendung von 3D-Boxen zur Darstellung einiger Objekte kann die Belegung die Geometrie und Semantik der Fahrszene umfassender beschreiben und ist weniger auf die Form und Kategorie der Objekte beschränkt.
Obwohl Erkennungsmethoden und Belegungsmethoden viele strukturelle und konzeptionelle Ähnlichkeiten aufweisen, wurde die gleichzeitige Bearbeitung beider Aufgaben und die Erforschung ihrer Wechselbeziehungen nicht gut untersucht. Belegungsmodelle und Erkennungsmodelle extrahieren häufig unterschiedliche Merkmalsdarstellungen. Die Aufgabe der Belegungsvorhersage erfordert umfassende semantische und geometrische Beurteilungen an verschiedenen räumlichen Standorten. Daher werden Voxeldarstellungen häufig verwendet, um feinkörnige 3D-Informationen zu bewahren. Bei Erkennungsaufgaben wird die BEV-Darstellung bevorzugt, da sich die meisten Objekte auf derselben horizontalen Ebene mit geringerer Überlappung befinden.
Im Vergleich zur BEV-Darstellung ist die Voxel-Darstellung verfeinert, aber weniger effizient. Darüber hinaus sind viele fortgeschrittene Operatoren hauptsächlich für 2D-Funktionen konzipiert und optimiert, was ihre Integration in die 3D-Voxeldarstellung nicht so einfach macht. Die BEV-Darstellung ist zeit- und speichereffizienter, für dichte räumliche Vorhersagen jedoch nicht optimal, da sie Strukturinformationen in der Höhendimension verliert. Neben der Merkmalsdarstellung unterscheiden sich verschiedene Wahrnehmungsaufgaben auch in Datenformaten und Zielen. Daher ist es eine große Herausforderung, die Einheitlichkeit und Effizienz des Trainings von Multitasking-3D-Wahrnehmungsrahmen sicherzustellen.
UniVision-NetzwerkstrukturDie Gesamtstruktur des UniVision-Frameworks ist in Abbildung 1 dargestellt. Das Framework empfängt Multi-View-Bilder von N umgebenden Kameras als Eingabe und extrahiert Bildmerkmale über ein Netzwerk zur Bildmerkmalsextraktion. Anschließend werden die 2D-Bildmerkmale mithilfe des Ex-Im-Ansichtstransformationsmoduls, das tiefengesteuerte explizite Merkmalsverbesserung und abfragegesteuerte implizite Merkmalsabtastung kombiniert, auf 3D-Voxelmerkmale aktualisiert. Die Voxel-Merkmale werden durch lokale globale Merkmalsextraktion und Fusionsblock verarbeitet, um lokale kontextbewusste Voxel-Merkmale bzw. globale kontextbewusste BEV-Merkmale zu extrahieren. Anschließend werden Informationen zwischen Voxelmerkmalen und BEV-Merkmalen für verschiedene nachgelagerte Wahrnehmungsaufgaben über das Cross-Representation-Feature-Interaktionsmodul ausgetauscht. In der Trainingsphase übernimmt das UniVision-Framework eine Strategie der kombinierten Occ-Det-Datenverbesserung und der schrittweisen Anpassung der Verlustgewichte, um effektiv zu trainieren.
1) Ex-Im View Transform
Tiefengesteuerte explizite Funktionserweiterung. Hier wird der LSS-Ansatz verfolgt:
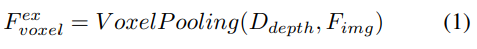
2) Abfragegesteuertes implizites Feature-Sampling. Die Darstellung von 3D-Informationen weist jedoch einige Nachteile auf. Die Genauigkeit von korreliert stark mit der Genauigkeit der geschätzten Tiefenverteilung. Darüber hinaus sind die von LSS generierten Punkte nicht gleichmäßig verteilt. In der Nähe der Kamera sind die Punkte dicht gepackt und in der Ferne spärlich verteilt. Daher verwenden wir weiterhin abfragegesteuertes Feature-Sampling, um die oben genannten Mängel zu kompensieren.
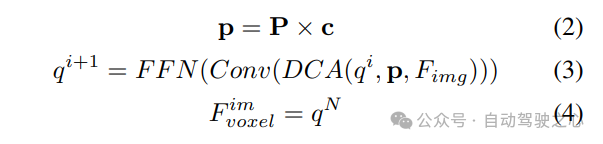
Im Vergleich zu aus LSS generierten Punkten sind Voxelabfragen gleichmäßig im 3D-Raum verteilt und werden aus den statistischen Eigenschaften aller Trainingsmuster gelernt, was unabhängig von den in LSS verwendeten Tiefenvorinformationen ist. Daher ergänzen sie sich gegenseitig und sind als Ausgabemerkmale des Ansichtstransformationsmoduls verbunden:
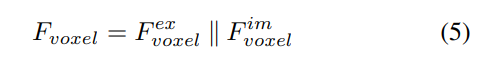
2) Lokale globale Merkmalsextraktion und -fusion
Überlagern Sie bei gegebenen Eingabevoxelmerkmalen zunächst die Merkmale auf dem Z -Achse und verwenden Sie Faltungsschichten, um Kanäle zu reduzieren und BEV-Merkmale zu erhalten:
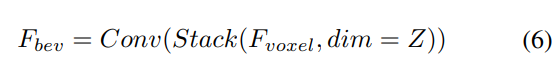
Anschließend wird das Modell zur Merkmalsextraktion und -verbesserung in zwei parallele Zweige unterteilt. Lokale Merkmalsextraktion + globale Merkmalsextraktion und die endgültige darstellungsübergreifende Merkmalsinteraktion! Wie in Abbildung 1(b) dargestellt.
3) Verlustfunktion und Erkennungskopf
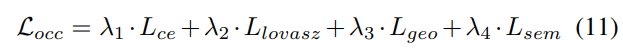
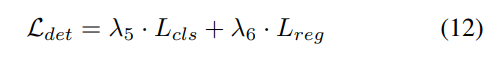
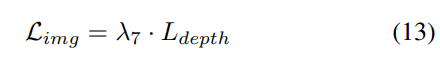
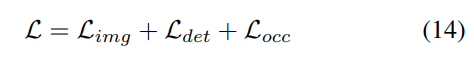
Strategie zur progressiven Gewichtsanpassung. In der Praxis zeigt sich, dass die direkte Einbeziehung der oben genannten Verluste häufig dazu führt, dass der Trainingsprozess fehlschlägt und das Netzwerk nicht konvergiert. In den frühen Phasen des Trainings sind die Voxelmerkmale Fvoxel zufällig verteilt, und die Überwachung im Belegungskopf und Erkennungskopf trägt weniger zu Konvergenzverlusten bei als andere. Gleichzeitig sind Verlustelemente wie der Klassifizierungsverlust Lcls in der Erkennungsaufgabe sehr groß und dominieren den Trainingsprozess, was die Optimierung des Modells erschwert. Um dieses Problem zu lösen, wird eine progressive Strategie zur Anpassung des Verlustgewichts vorgeschlagen, um das Verlustgewicht dynamisch anzupassen. Insbesondere wird ein Steuerparameter δ zu den Verlusten außerhalb der Bildebene (d. h. Belegungsverlust und Erkennungsverlust) hinzugefügt, um das Verlustgewicht in verschiedenen Trainingsepochen anzupassen. Das Kontrollgewicht δ wird zu Beginn auf einen kleinen Wert Vmin eingestellt und steigt in N Trainingsepochen schrittweise auf Vmax an:
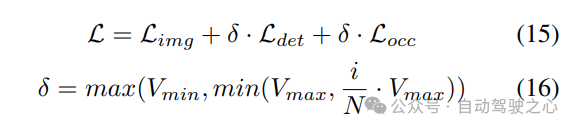
4) Gemeinsame Occ-Det-Geodatenerweiterung
in der 3D-Erkennungsaufgabe, Zusätzlich Neben der üblichen Datenerweiterung auf Bildebene ist auch die Datenerweiterung auf räumlicher Ebene wirksam bei der Verbesserung der Modellleistung. Allerdings ist die Anwendung der Verbesserung der räumlichen Ebene bei Belegungsaufgaben nicht einfach. Wenn wir Datenerweiterungen (z. B. zufällige Skalierung und Rotation) auf diskrete Belegungsbezeichnungen anwenden, ist es schwierig, die resultierende Voxelsemantik zu bestimmen. Daher wenden bestehende Methoden nur einfache räumliche Erweiterungen an, wie z. B. zufälliges Umdrehen bei Belegungsaufgaben.
Um dieses Problem zu lösen, schlägt UniVision eine gemeinsame Occ-Det-Raumdatenerweiterung vor, um eine gleichzeitige Verbesserung von 3D-Erkennungsaufgaben und Belegungsaufgaben im Framework zu ermöglichen. Da es sich bei den 3D-Box-Beschriftungen um kontinuierliche Werte handelt und die erweiterte 3D-Box für das Training direkt berechnet werden kann, wird zur Erkennung die Erweiterungsmethode in BEVDet befolgt. Obwohl Belegungsbezeichnungen diskret und schwer zu manipulieren sind, können Voxelmerkmale als kontinuierlich behandelt und durch Operationen wie Abtastung und Interpolation verarbeitet werden. Es wird daher empfohlen, Voxelmerkmale zu transformieren, anstatt direkt auf Belegungsbezeichnungen zur Datenerweiterung zu arbeiten.
Konkret wird zunächst die räumliche Datenerweiterung abgetastet und die entsprechende 3D-Transformationsmatrix berechnet. Für die Belegungsbezeichnungen und deren Voxel-Indizes berechnen wir deren dreidimensionale Koordinaten. Anschließend wird es auf die Voxel-Indizes in den erweiterten Voxel-Funktionen angewendet und normalisiert. : OpenOccupancy und Occ3D.
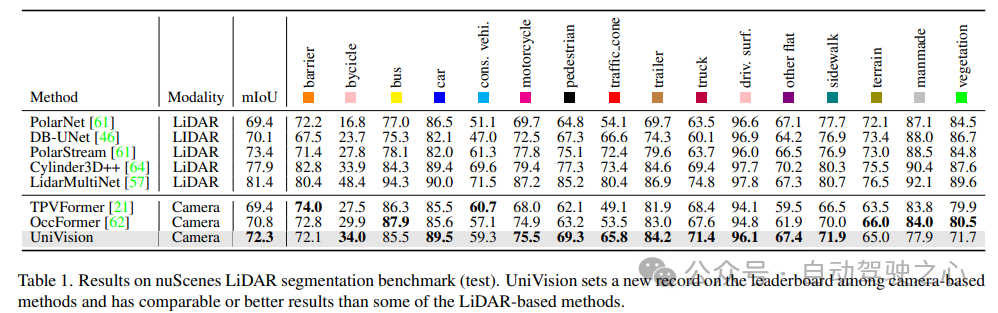
NuScenes LiDAR-Segmentierung: Gemäß dem aktuellen OccFormer und TPVFormer werden Kamerabilder als Eingabe für die LIDAR-Segmentierungsaufgabe verwendet und die LIDAR-Daten werden nur verwendet, um 3D-Standorte für die Abfrage der Ausgabemerkmale bereitzustellen. Verwenden Sie mIoU als Bewertungsmetrik. 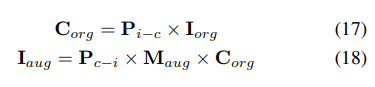
OpenOccupancy: Der OpenOccupancy-Benchmark basiert auf dem nuScenes-Datensatz und bietet semantische Belegungsbezeichnungen mit einer Auflösung von 512×512×40. Die beschrifteten Klassen sind die gleichen wie in der LIDAR-Segmentierungsaufgabe, wobei mIoU als Bewertungsmetrik verwendet wird!
Occ3D: Der Occ3D-Benchmark basiert auf dem nuScenes-Datensatz und bietet semantische Belegungsbezeichnungen mit einer Auflösung von 200×200×16. Occ3D bietet außerdem sichtbare Masken für Training und Auswertung. Die beschrifteten Klassen sind die gleichen wie in der LIDAR-Segmentierungsaufgabe, wobei mIoU als Bewertungsmetrik verwendet wird!1) Nuscenes LiDAR-Segmentierung
Tabelle 1 zeigt die Ergebnisse des nuScenes LiDAR-Segmentierungs-Benchmarks. UniVision übertrifft die hochmoderne visionsbasierte Methode OccFormer deutlich um 1,5 % mIoU und stellt einen neuen Rekord für visionsbasierte Modelle auf der Bestenliste auf. Insbesondere übertrifft UniVision auch einige Lidar-basierte Modelle wie PolarNe und DB-UNet.2) NuScenes 3D-Objekterkennungsaufgabe
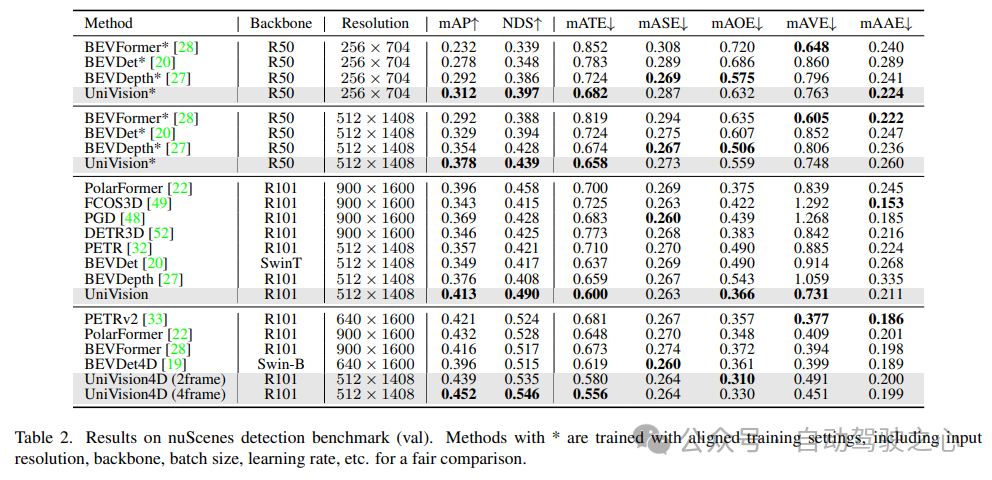
Wie in Tabelle 2 gezeigt, übertrifft UniVision andere Methoden, wenn dieselben Trainingseinstellungen für einen fairen Vergleich verwendet werden. Im Vergleich zu BEVDepth bei einer Bildauflösung von 512×1408 erzielt UniVision Zuwächse von 2,4 % bzw. 1,1 % bei mAP und NDS. Wenn das Modell vergrößert wird und UniVision mit zeitlichen Eingaben kombiniert wird, übertrifft es SOTA-basierte zeitliche Detektoren um ein Vielfaches. UniVision erreicht dies mit einer kleineren Eingabeauflösung und verwendet kein CBGS.
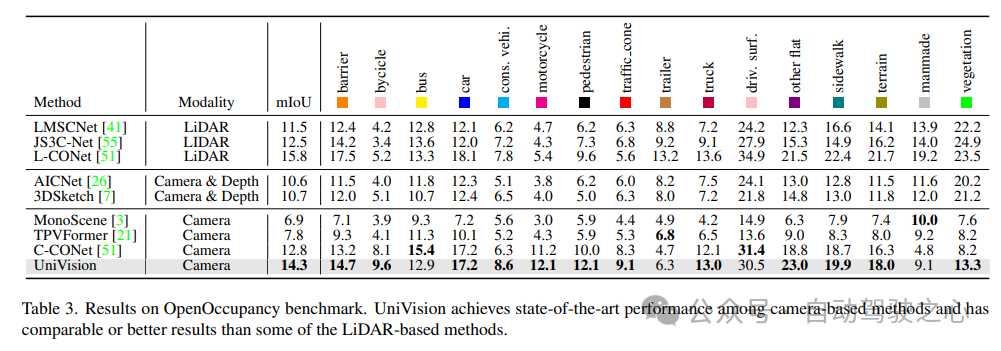
3) OpenOccupancy-Ergebnisvergleich
Die Ergebnisse des OpenOccupancy-Benchmarktests sind in Tabelle 3 dargestellt. UniVision übertrifft aktuelle visionsbasierte Belegungsmethoden, einschließlich MonoScene, TPVFormer und C-CONet, in Bezug auf mIoU deutlich um 7,3 %, 6,5 % bzw. 1,5 %. Darüber hinaus übertrifft UniVision einige Lidar-basierte Methoden wie LMSCNet und JS3C-Net.
4) Occ3D-Experimentalergebnisse
Tabelle 4 listet die Ergebnisse des Occ3D-Benchmarks auf. UniVision übertrifft aktuelle visionsbasierte Methoden in Bezug auf mIoU bei unterschiedlichen Eingabebildauflösungen deutlich um mehr als 2,7 % bzw. 1,8 %. Es ist erwähnenswert, dass BEVFormer und BEVDet-stereo vorab trainierte Gewichte laden und zeitliche Eingaben in der Inferenz verwenden, während UniVision diese nicht verwendet, aber dennoch eine bessere Leistung erzielt.
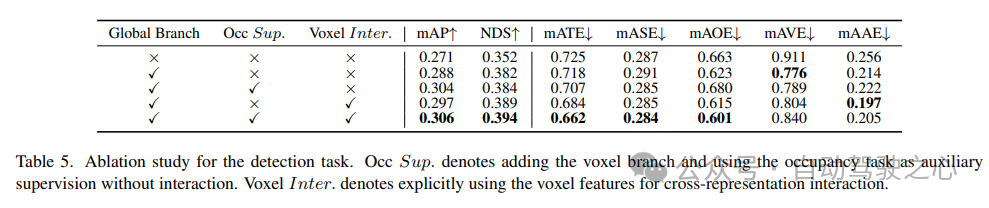
5) Wirksamkeit von Komponenten bei Erkennungsaufgaben
Die Ablationsstudie für Erkennungsaufgaben ist in Tabelle 5 dargestellt. Wenn der BEV-basierte globale Merkmalsextraktionszweig in das Basismodell eingefügt wird, verbessert sich die Leistung um 1,7 % mAP und 3,0 % NDS. Wenn die voxelbasierte Belegungsaufgabe als Hilfsaufgabe zum Detektor hinzugefügt wird, erhöht sich der mAP-Gewinn des Modells um 1,6 %. Wenn Kreuzdarstellungsinteraktionen explizit aus Voxelmerkmalen eingeführt werden, erzielt das Modell die beste Leistung und verbessert mAP und NDS um 3,5 % bzw. 4,2 % im Vergleich zur Basislinie von
 ist in Tabelle 6 für die Ablationsstudie zur Belegungsaufgabe dargestellt. Das voxelbasierte lokale Merkmalsextraktionsnetzwerk bringt eine Verbesserung von 1,96 % mIoU-Gewinn gegenüber dem Basismodell. Wenn die Erkennungsaufgabe als zusätzliches Überwachungssignal eingeführt wird, verbessert sich die Modellleistung um 0,4 % mIoU.
ist in Tabelle 6 für die Ablationsstudie zur Belegungsaufgabe dargestellt. Das voxelbasierte lokale Merkmalsextraktionsnetzwerk bringt eine Verbesserung von 1,96 % mIoU-Gewinn gegenüber dem Basismodell. Wenn die Erkennungsaufgabe als zusätzliches Überwachungssignal eingeführt wird, verbessert sich die Modellleistung um 0,4 % mIoU.
7) Sonstiges
 Tabelle 5 und Tabelle 6 zeigen, dass im UniVision-Framework Erkennungsaufgaben und Belegungsaufgaben einander ergänzen. Bei Erkennungsaufgaben kann die Belegungsüberwachung die mAP- und mATE-Metriken verbessern, was darauf hindeutet, dass Voxel-semantisches Lernen die Wahrnehmung der Objektgeometrie, d. h. Zentralität und Skalierung, durch den Detektor effektiv verbessert. Für die Belegungsaufgabe verbessert die Erkennungsüberwachung die Leistung der Vordergrundkategorie (d. h. der Erkennungskategorie) erheblich, was zu einer Gesamtverbesserung führt.
Tabelle 5 und Tabelle 6 zeigen, dass im UniVision-Framework Erkennungsaufgaben und Belegungsaufgaben einander ergänzen. Bei Erkennungsaufgaben kann die Belegungsüberwachung die mAP- und mATE-Metriken verbessern, was darauf hindeutet, dass Voxel-semantisches Lernen die Wahrnehmung der Objektgeometrie, d. h. Zentralität und Skalierung, durch den Detektor effektiv verbessert. Für die Belegungsaufgabe verbessert die Erkennungsüberwachung die Leistung der Vordergrundkategorie (d. h. der Erkennungskategorie) erheblich, was zu einer Gesamtverbesserung führt.
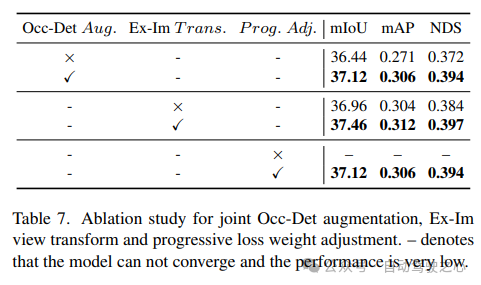
zeigt die Wirksamkeit der kombinierten räumlichen Occ-Det-Verbesserung, des Ex-Im-Ansichtskonvertierungsmoduls und der progressiven Gewichtsanpassungsstrategie in Tabelle 7. Mit der vorgeschlagenen räumlichen Erweiterung und dem vorgeschlagenen Ansichtstransformationsmodul zeigt es erhebliche Verbesserungen bei Erkennungsaufgaben und Belegungsaufgaben für mIoU-, mAP- und NDS-Metriken. Mit der Strategie zur Gewichtsanpassung kann das Multitasking-Framework effektiv trainiert werden. Ohne dies kann das Training des einheitlichen Frameworks nicht konvergieren und die Leistung ist sehr gering.
Referenz
 Link zum Dokument: https://arxiv.org/pdf/2401.06994.pdf
Link zum Dokument: https://arxiv.org/pdf/2401.06994.pdf
Name des Dokuments: UniVision: A Unified Framework for Vision-Centric 3D Perception
Das obige ist der detaillierte Inhalt vonBeispielloses UniVision: BEV-Erkennung und gemeinsames Occ-Framework, duales SOTA!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!