
Heim >Technologie-Peripheriegeräte >KI >Neue Arbeit von Chen Danqis Team: Der Llama-2-Kontext wird auf 128.000 erweitert, der 10-fache Durchsatz erfordert nur 1/6 des Speichers
Neue Arbeit von Chen Danqis Team: Der Llama-2-Kontext wird auf 128.000 erweitert, der 10-fache Durchsatz erfordert nur 1/6 des Speichers

- PHPznach vorne
- 2024-03-01 12:20:04846Durchsuche
Das Team von Chen Danqi hat gerade eine neue Methode zur LLM-Kontextfenstererweiterung veröffentlicht:
Sie kann das Llama-2-Fenster auf 128.000 erweitern, indem nur 8.000 Token-Dokumente für das Training verwendet werden. Das Wichtigste ist, dass das Modell in diesem Prozess nur1/6 des ursprünglichen Speichers benötigt und das Modell den 10-fachen Durchsatz erreicht.
Um das 7B-Alpaka 2 mit dieser Methode umzuwandeln, ist nur ein Stück A100 erforderlich
.Das Team sagte:
Wir hoffen, dass diese Methode nützlich und einfach zu verwenden ist und
günstige und effektiveLong-Context-Funktionen für zukünftige LLMs bietet.Derzeit werden Modell und Code auf HuggingFace und GitHub veröffentlicht.
Fügen Sie einfach zwei Komponenten hinzu
CEPE
, der vollständige Name lautet „Context Expansion with Parallel Encoding(Context Expansion with Parallel Encoding)“. Als leichtgewichtiges Framework kann es verwendet werden, um das Kontextfenster jedes vorab trainierten und durch Anweisungen fein abgestimmten Modells zu erweitern.
Für jedes vorab trainierte Nur-Decoder-Sprachmodell erweitert CEPE es um zwei kleine Komponenten:
Eine ist ein kleiner Encoderfür die Blockkodierung von langen Kontexten
Eine ist das Cross-Attention-Force-Modul , eingefügt in jede Schicht des Decoders, wird verwendet, um sich auf die Encoderdarstellung zu konzentrieren.
Die vollständige Architektur sieht wie folgt aus:
In diesem Schema codiert das Encodermodell drei zusätzliche Kontextblöcke parallel und wird mit der endgültigen versteckten Darstellung verkettet, die dann als Eingabe für die Queraufmerksamkeit des Decoders verwendet wird Schicht.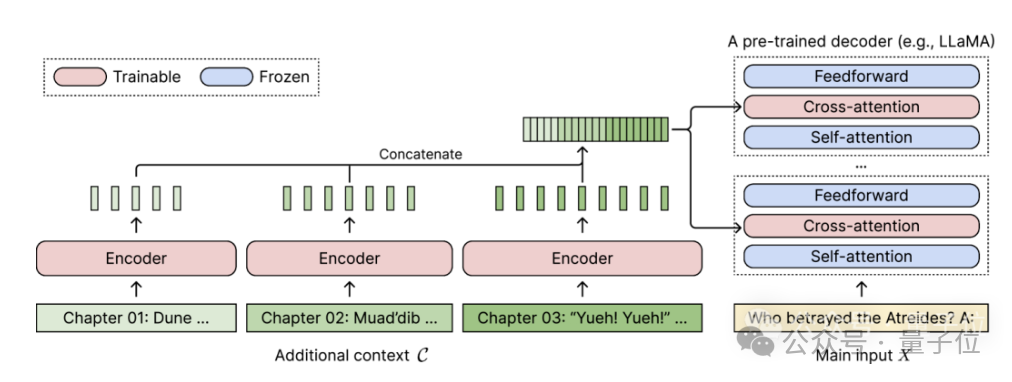 Hier konzentriert sich die Queraufmerksamkeitsschicht hauptsächlich auf die Encoderdarstellung zwischen der Selbstaufmerksamkeitsschicht und der Feed-Forward-Schicht im Decodermodell.
Hier konzentriert sich die Queraufmerksamkeitsschicht hauptsächlich auf die Encoderdarstellung zwischen der Selbstaufmerksamkeitsschicht und der Feed-Forward-Schicht im Decodermodell.
Durch die sorgfältige Auswahl von Trainingsdaten, die keiner Kennzeichnung bedürfen, trägt CEPE dazu bei, dass das Modell über lange Kontextfähigkeiten verfügt und eignet sich auch gut zum Abrufen von Dokumenten.
Der Autor führt ein, dass ein solches CEPE hauptsächlich drei Hauptvorteile bietet:
(1) Die Länge ist verallgemeinerbar, da sie nicht durch die Positionskodierung eingeschränkt ist. Im Gegenteil, ihr Kontext ist segmentiert und kodiert und jedes Segment Es verfügt über eine eigene Standortkodierung.
(2) Hohe EffizienzDurch die Verwendung kleiner Encoder und paralleler Codierung zur Verarbeitung des Kontexts können die Rechenkosten gesenkt werden.Gleichzeitig konzentriert sich die Queraufmerksamkeit nur auf die Darstellung der letzten Ebene des Encoders und das Sprachmodell, das nur den Decoder verwendet, muss die Schlüssel-Wert-Paare jedes Tokens in jeder Ebene zwischenspeichern Im Vergleich dazu erfordert CEPE eine große Speicherreduzierung.
(3) Reduzieren Sie die Schulungskosten
Im Gegensatz zu vollständigen Feinabstimmungsmethoden passt CEPE nur den Encoder und die Queraufmerksamkeit an, während das große Decodermodell eingefroren bleibt. Der Autor stellte vor, dass durch die Erweiterung des 7B-Decoders zu einem Modell
eine 80-GB-A100-GPU vervollständigt werden kann.
Die Ratlosigkeit nimmt weiter abDas Team wendete CEPE auf Llama-2 an und trainierte mit einer 20 Milliarden Token-gefilterten Version von RedPajama
(nur 1 % des Llama-2-Vortrainingsbudgets).
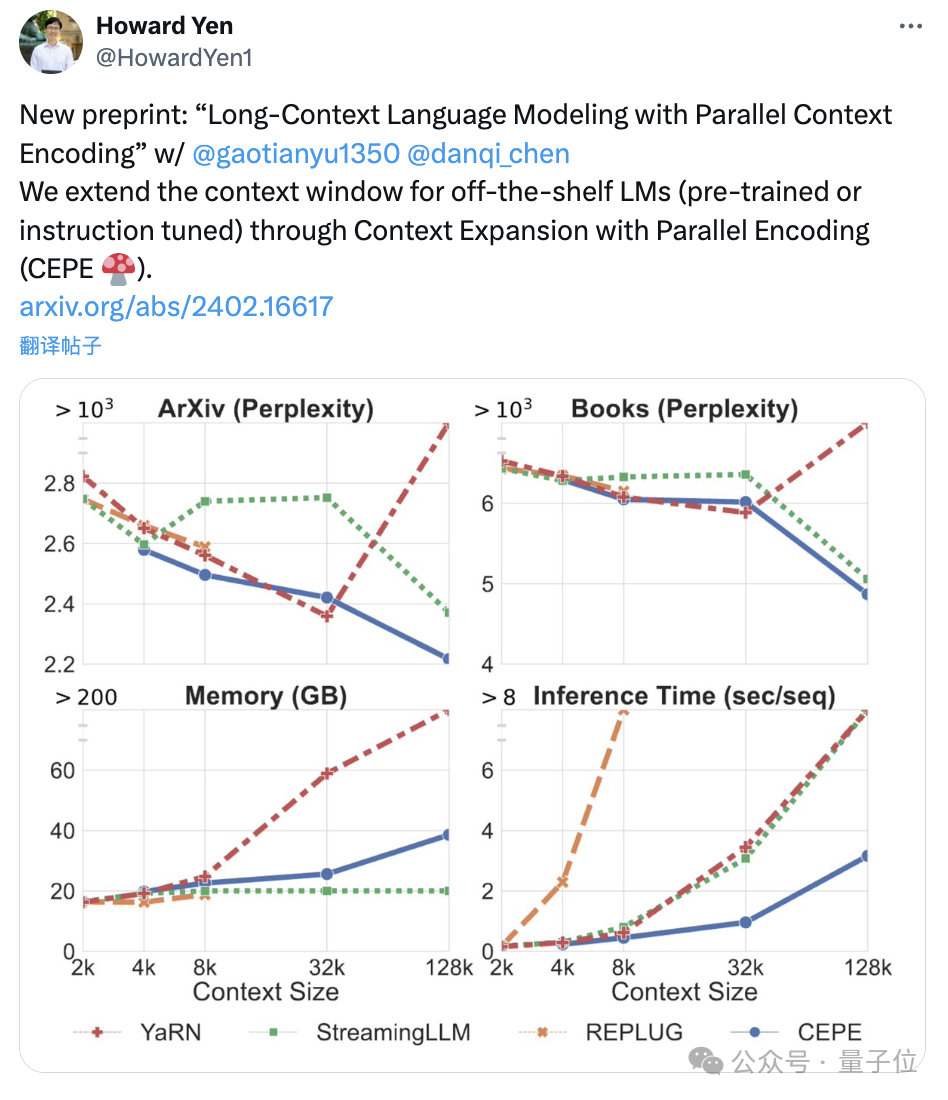
Erstens erreicht CEPE im Vergleich zu zwei vollständig fein abgestimmten Modellen, LLAMA2-32K und YARN-64K, bei allen Datensätzen eine geringere oder vergleichbare Perplexität
bei gleichzeitig geringerer Speichernutzungsrate und höherem Durchsatz.
Wenn der Kontext auf 128.000 erhöht wird (wobei die Trainingslänge von 8.000 bei weitem überschritten wird), nimmt die Verwirrung von CEPE weiter ab, während gleichzeitig ein niedriger Speicherstatus aufrechterhalten wird. 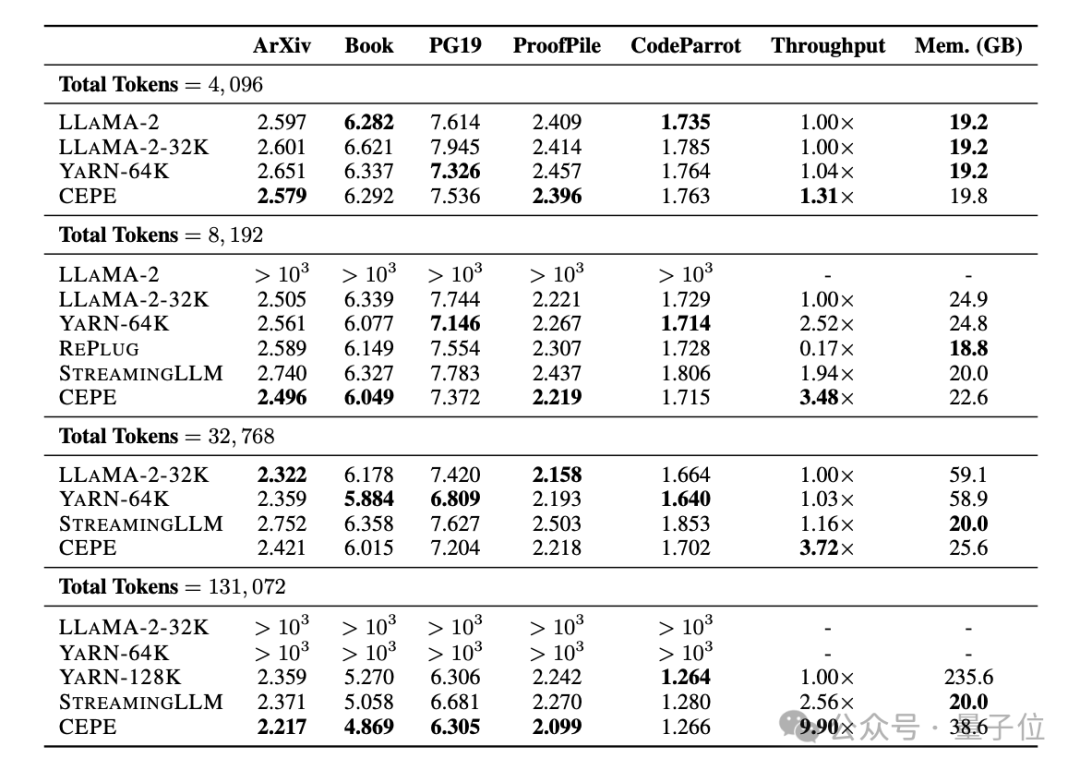
Zweitens werden die
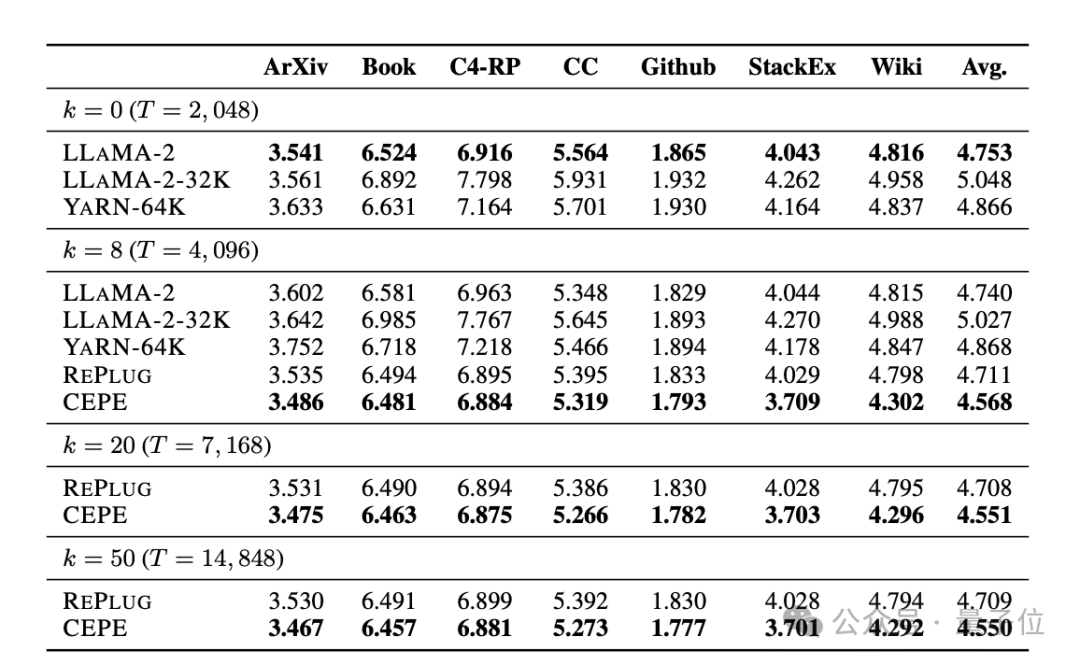
Abruffähigkeiten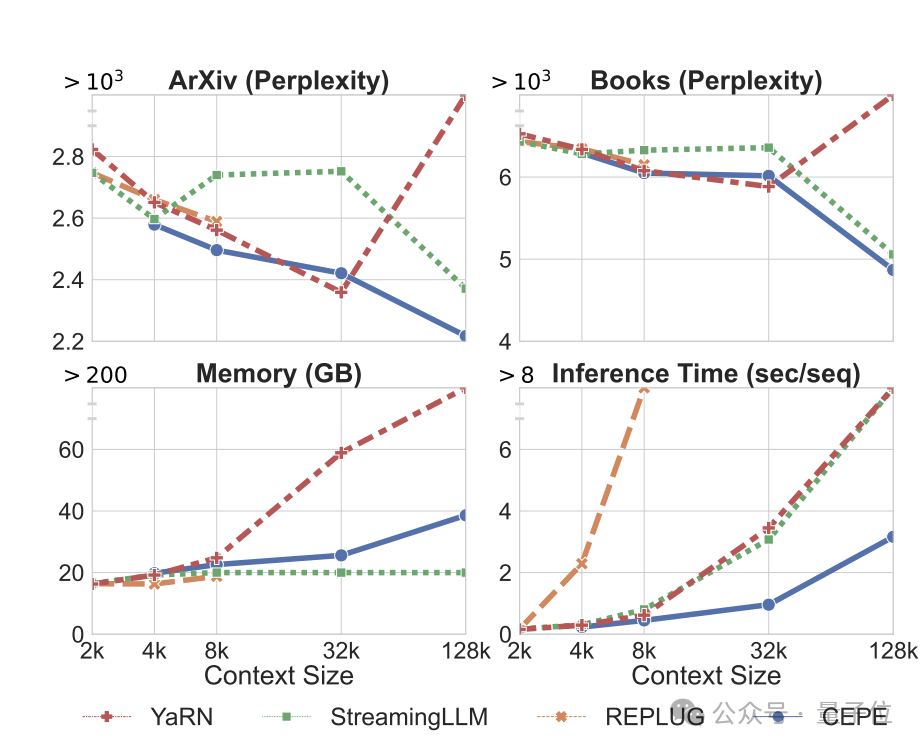
Wie in der folgenden Tabelle gezeigt: Durch die Verwendung des abgerufenen Kontexts kann CEPE die Ratlosigkeit des Modells effektiv verbessern und eine bessere Leistung als RePlug erbringen.
Es ist erwähnenswert, dass CEPE die Verwirrung weiter verbessern wird, selbst wenn Absatz k = 50 (Training ist 60).
Dies zeigt, dass CEPE sich gut auf eine Einstellung mit verbessertem Abruf übertragen lässt, während das Vollkontext-Decodermodell in dieser Fähigkeit nachlässt.
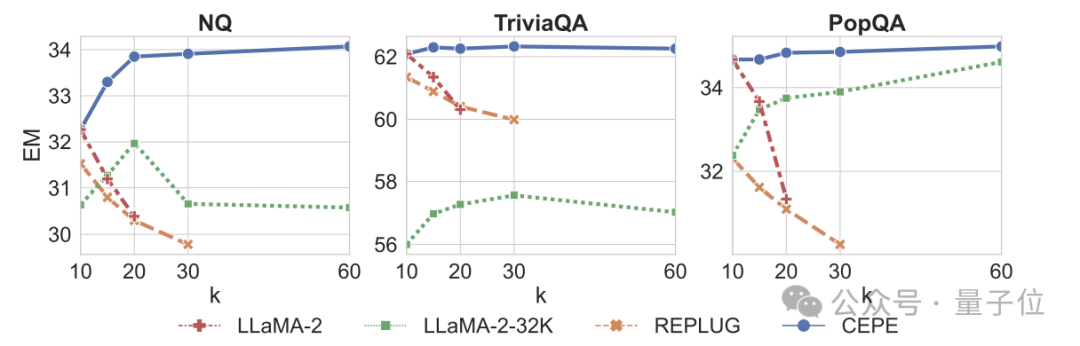
Drittens: Frage- und Antwortmöglichkeiten im offenen Bereichdeutlich übertroffen.
Wie in der Abbildung unten gezeigt, ist CEPE in allen Datensätzen und Absatz-k-Parametern deutlich besser als andere Modelle, und im Gegensatz zu anderen Modellen sinkt die Leistung erheblich, wenn der k-Wert immer größer wird.
Dies zeigt auch, dass CEPE nicht empfindlich auf große Mengen redundanter oder irrelevanter Absätze reagiert.
Zusammenfassend lässt sich sagen, dass CEPE bei allen oben genannten Aufgaben mit viel geringerem Speicher- und Rechenaufwand im Vergleich zu den meisten anderen Lösungen überlegen ist.
Auf der Grundlage dieser Grundlagen schlug der Autor schließlich CEPE-Distilled (CEPED) speziell für Instruktions-Tuning-Modelle vor.
Es werden nur unbeschriftete Daten verwendet, um das Kontextfenster des Modells zu erweitern, wodurch das Verhalten des ursprünglichen anweisungsabgestimmten Modells durch unterstützten KL-Divergenzverlust in eine neue Architektur destilliert wird, wodurch die Notwendigkeit entfällt, teure Daten zur Befehlsverfolgung mit langem Kontext zu verwalten.
Letztendlich kann CEPED das Kontextfenster von Llama-2 erweitern und die Langtextleistung des Modells verbessern, während die Fähigkeit, Anweisungen zu verstehen, erhalten bleibt.
Teamvorstellung
CEPE hat insgesamt 3 Autoren.
Einer ist Yan Heguang(Howard Yen), ein Masterstudent in Informatik an der Princeton University.
Die zweite Person ist Gao Tianyu, ein Doktorand an derselben Schule und Absolvent der Tsinghua-Universität.
Sie sind alle Schüler des korrespondierenden Autors Chen Danqi.

Originaltext des Papiers: https://arxiv.org/abs/2402.16617
Referenzlink: https://twitter.com/HowardYen1/status/1762474556101661158
Das obige ist der detaillierte Inhalt vonNeue Arbeit von Chen Danqis Team: Der Llama-2-Kontext wird auf 128.000 erweitert, der 10-fache Durchsatz erfordert nur 1/6 des Speichers. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!