
Heim >Technologie-Peripheriegeräte >KI >Wie wählen CV-Praktiker in der Post-Sora-Ära Modelle aus? Faltung oder ViT, überwachtes Lernen oder CLIP-Paradigma
Wie wählen CV-Praktiker in der Post-Sora-Ära Modelle aus? Faltung oder ViT, überwachtes Lernen oder CLIP-Paradigma

- PHPznach vorne
- 2024-02-19 09:57:021043Durchsuche
Die ImageNet-Genauigkeit war einst der Hauptindikator zur Bewertung der Modellleistung, aber im heutigen rechnerischen Sichtfeld scheint dieser Indikator allmählich unvollständig zu sein.
Da Computer-Vision-Modelle komplexer geworden sind, hat die Vielfalt der verfügbaren Modelle erheblich zugenommen, von ConvNets bis hin zu Vision Transformers. Die Trainingsmethoden haben sich auch zu selbstüberwachtem Lernen und Bild-Text-Paar-Training wie CLIP weiterentwickelt und sind nicht mehr auf überwachtes Training auf ImageNet beschränkt.
Obwohl die Genauigkeit von ImageNet ein wichtiger Indikator ist, reicht sie nicht aus, um die Leistung des Modells vollständig zu bewerten. Unterschiedliche Architekturen, Trainingsmethoden und Datensätze können dazu führen, dass Modelle bei verschiedenen Aufgaben unterschiedliche Leistungen erbringen. Daher kann es Einschränkungen geben, sich bei der Beurteilung von Modellen ausschließlich auf ImageNet zu verlassen. Wenn ein Modell den ImageNet-Datensatz überpasst und die Genauigkeit die Sättigung erreicht, wird die Generalisierungsfähigkeit des Modells für andere Aufgaben möglicherweise ignoriert. Daher müssen mehrere Faktoren berücksichtigt werden, um die Leistung und Anwendbarkeit des Modells zu bewerten.
Obwohl die ImageNet-Genauigkeit von CLIP der von ResNet ähnelt, ist der visuelle Encoder robuster und übertragbarer. Dies veranlasste die Forscher, die einzigartigen Vorteile von CLIP zu untersuchen, die bei der alleinigen Betrachtung von ImageNet-Metriken nicht offensichtlich waren. Dies unterstreicht die Bedeutung der Analyse anderer Eigenschaften, um nützliche Modelle zu entdecken.
Darüber hinaus können herkömmliche Benchmarks die Fähigkeit eines Modells, reale visuelle Herausforderungen wie verschiedene Kamerawinkel, Lichtverhältnisse oder Verdeckungen zu bewältigen, nicht vollständig bewerten. Modelle, die auf Datensätzen wie ImageNet trainiert werden, haben oft Schwierigkeiten, ihre Leistung in praktischen Anwendungen zu nutzen, da die Bedingungen und Szenarien in der realen Welt vielfältiger sind.
Diese Fragen haben bei Praktikern auf diesem Gebiet für neue Verwirrung gesorgt: Wie misst man ein visuelles Modell? Und wie wählt man ein visuelles Modell aus, das Ihren Anforderungen entspricht?
In einem aktuellen Artikel führten Forscher von MBZUAI und Meta eine ausführliche Diskussion zu diesem Thema.

- Papiertitel: ConvNet vs Transformer, Supervised vs CLIP: Beyond ImageNet Accuracy
- Papierlink: https://arxiv.org/pdf/2311.09215. pdf
Die Forschung konzentriert sich auf das Modellverhalten, das über die ImageNet-Genauigkeit hinausgeht, und analysiert die Leistung wichtiger Modelle im Bereich Computer Vision, einschließlich ConvNeXt und Vision Transformer (ViT), die beide unter überwachter Leistung und CLIP-Trainingsparadigmen Leistung erbringen.
Die ausgewählten Modelle haben eine ähnliche Anzahl von Parametern und nahezu die gleiche Genauigkeit auf ImageNet-1K unter jedem Trainingsparadigma, was einen fairen Vergleich gewährleistet. Die Forscher untersuchten eine Reihe von Modellmerkmalen eingehend, wie z. B. Vorhersagefehlertyp, Generalisierungsfähigkeit, Invarianz erlernter Darstellungen, Kalibrierung usw., wobei sie sich auf die Merkmale des Modells ohne zusätzliches Training oder Feinabstimmung konzentrierten und hofften, direkt Referenzen bereitzustellen von Praktikern, die vorab trainierte Modelle verwenden.
In der Analyse stellten die Forscher fest, dass es erhebliche Unterschiede im Modellverhalten zwischen verschiedenen Architekturen und Trainingsparadigmen gibt. Beispielsweise führten Modelle, die nach dem CLIP-Paradigma trainiert wurden, zu weniger Klassifizierungsfehlern als Modelle, die mit ImageNet trainiert wurden. Das überwachte Modell ist jedoch besser kalibriert und übertrifft im Allgemeinen den ImageNet-Robustheitsbenchmark. ConvNeXt bietet Vorteile gegenüber synthetischen Daten, ist jedoch stärker texturorientiert als ViT. Mittlerweile schneidet das überwachte ConvNeXt bei vielen Benchmarks gut ab, wobei die Übertragbarkeitsleistung mit dem CLIP-Modell vergleichbar ist.
Es zeigt sich, dass verschiedene Modelle ihre Vorteile auf einzigartige Weise zeigen und diese Vorteile nicht durch einen einzigen Indikator erfasst werden können. Die Forscher betonen, dass detailliertere Bewertungsmetriken erforderlich sind, um Modelle in bestimmten Kontexten genau auszuwählen und neue ImageNet-agnostische Benchmarks zu erstellen.
Basierend auf diesen Beobachtungen hat der Chefwissenschaftler von Meta AI, Yann LeCun, die Studie retweetet und ihr gefallen:

Modellauswahl
Für das überwachte Modell verwendeten die Forscher das vorab trainierte DeiT3-Base/16 von ViT, das die gleiche Architektur wie ViT-Base/16 hat, aber die Trainingsmethode wurde zusätzlich verbessert; -Basis wurde verwendet. Für das CLIP-Modell verwendeten die Forscher die visuellen Encoder von ViT-Base/16 und ConvNeXt-Base in OpenCLIP.
Bitte beachten Sie, dass die Leistung dieser Modelle geringfügig vom ursprünglichen OpenAI-Modell abweicht. Alle Modellprüfpunkte finden Sie auf der GitHub-Projekthomepage. Der detaillierte Modellvergleich ist in Tabelle 1 dargestellt:

Für den Modellauswahlprozess gab der Forscher eine detaillierte Erklärung:
1. Da der Forscher ein vorab trainiertes Modell verwendet, kann er das nicht kontrollieren Trainingszeitraum. Die Quantität und Qualität der gesehenen Datenproben.
2. Um ConvNets und Transformers zu analysieren, wurden in vielen früheren Studien ResNet und ViT verglichen. Dieser Vergleich geht im Allgemeinen gegen ConvNet, da ViT typischerweise mit fortgeschritteneren Rezepten trainiert wird und eine höhere ImageNet-Genauigkeit erreicht. ViT verfügt auch über einige architektonische Designelemente, wie z. B. LayerNorm, die bei seiner Erfindung vor vielen Jahren nicht in ResNet integriert waren. Für eine ausgewogenere Bewertung haben wir daher ViT mit ConvNeXt verglichen, einem modernen Vertreter von ConvNet, der mit Transformers vergleichbare Leistungen erbringt und viele Designs teilt.
3. Was den Trainingsmodus betrifft, verglichen die Forscher den überwachten Modus und den CLIP-Modus. Überwachte Modelle haben die Leistung auf dem neuesten Stand der Technik im Bereich Computer Vision gehalten. CLIP-Modelle hingegen schneiden hinsichtlich Generalisierung und Übertragbarkeit gut ab und stellen Eigenschaften zur Verbindung visueller und sprachlicher Darstellungen bereit.
4. Da das selbstüberwachte Modell in Vorversuchen ein ähnliches Verhalten zeigte wie das überwachte Modell, wurde es nicht in die Ergebnisse einbezogen. Dies kann auf die Tatsache zurückzuführen sein, dass sie letztendlich auf ImageNet-1K optimiert wurden, was sich auf das Studium vieler Funktionen auswirkt.
Als nächstes werfen wir einen Blick darauf, wie Forscher verschiedene Attribute analysiert haben.
Analyse
Modellfehler
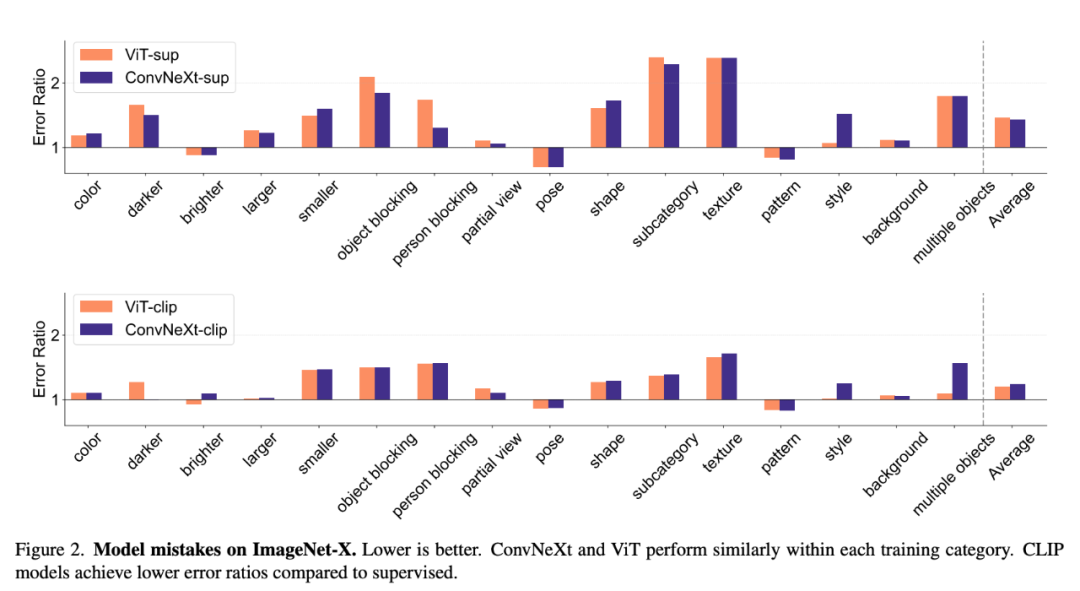
ImageNet-X ist ein Datensatz, der ImageNet-1K erweitert und detaillierte menschliche Anmerkungen zu 16 sich ändernden Faktoren zur Klassifizierung von Bildern enthält. Führen Sie eine eingehende Analyse von Modellfehlern durch In . Es verwendet eine Fehlerverhältnismetrik (je niedriger, desto besser), um die Leistung eines Modells in Bezug auf bestimmte Faktoren im Verhältnis zur Gesamtgenauigkeit zu quantifizieren, was eine differenzierte Analyse von Modellfehlern ermöglicht. Ergebnisse auf ImageNet-X zeigen:
1. Im Vergleich zu überwachten Modellen machen CLIP-Modelle weniger Fehler in der ImageNet-Genauigkeit.
2. Alle Modelle sind hauptsächlich von komplexen Faktoren wie Okklusion betroffen.
3. Die Textur ist der anspruchsvollste Faktor aller Modelle.
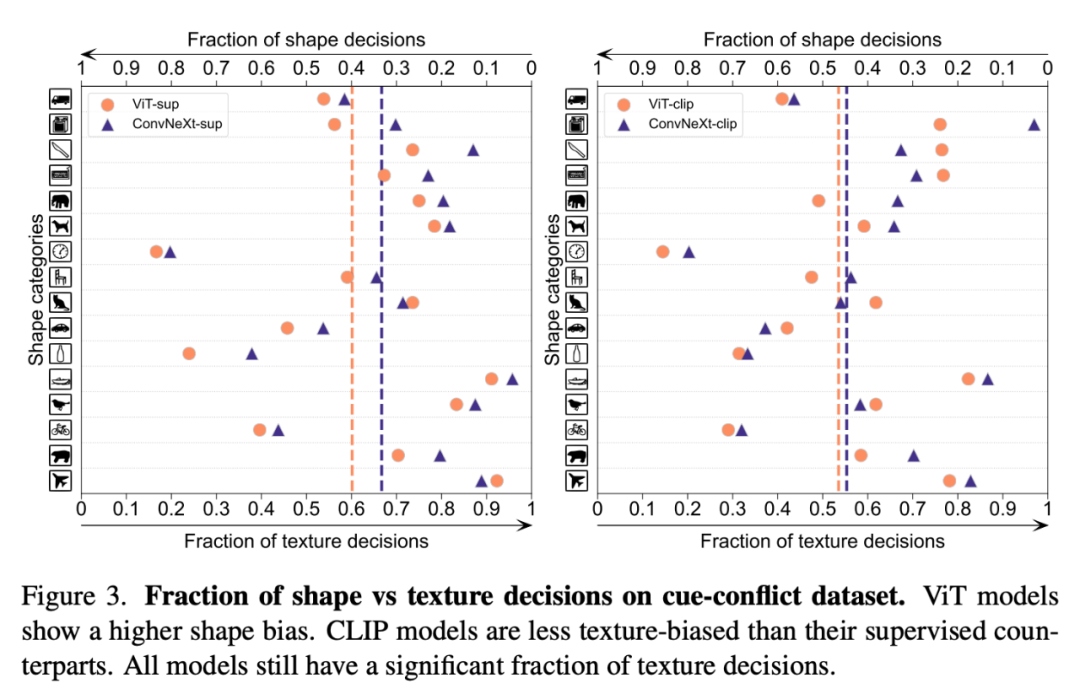
Form-/Texturverzerrung
Die Form-Texturverzerrung erkennt, ob ein Modell auf fragilen Texturverknüpfungen anstelle von Formhinweisen auf hoher Ebene basiert. Diese Verzerrung kann untersucht werden, indem Bilder unterschiedlicher Formen- und Texturkategorien kombiniert werden, bei denen Hinweise widersprüchlich sind. Dieser Ansatz hilft zu verstehen, inwieweit die Entscheidungen eines Modells auf der Form im Vergleich zur Textur basieren. Die Forscher bewerteten die Form-Textur-Verzerrung im Cue-Konflikt-Datensatz und stellten fest, dass die Textur-Verzerrung des CLIP-Modells kleiner war als die des überwachten Modells, während die Form-Verzerrung des ViT-Modells höher war als die von ConvNets.
Modellkalibrierung
Durch die Kalibrierung kann quantifiziert werden, ob die Vorhersagesicherheit des Modells mit seiner tatsächlichen Genauigkeit übereinstimmt, die anhand von Indikatoren wie dem erwarteten Kalibrierungsfehler (ECE) gemessen werden kann Zuverlässigkeitsdiagramme und Konfidenzhistogramme. Visuelle Tools zur Bewertung. Die Kalibrierung wurde auf ImageNet-1K und ImageNet-R ausgewertet und die Vorhersagen in 15 Stufen klassifiziert. Während des Experiments beobachteten die Forscher folgende Punkte:
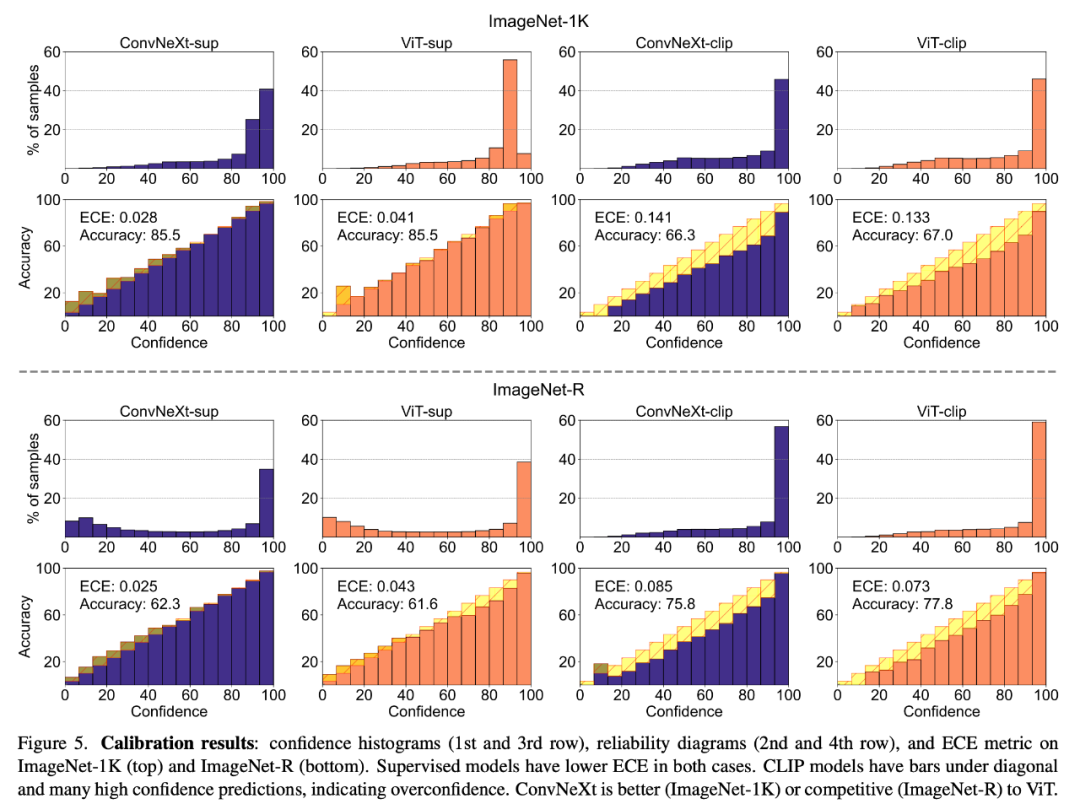
1. Das CLIP-Modell ist zu selbstsicher, während das überwachte Modell leicht zu wenig Selbstvertrauen hat.
2. Überwachtes ConvNeXt führt eine bessere Kalibrierung durch als überwachtes ViT.
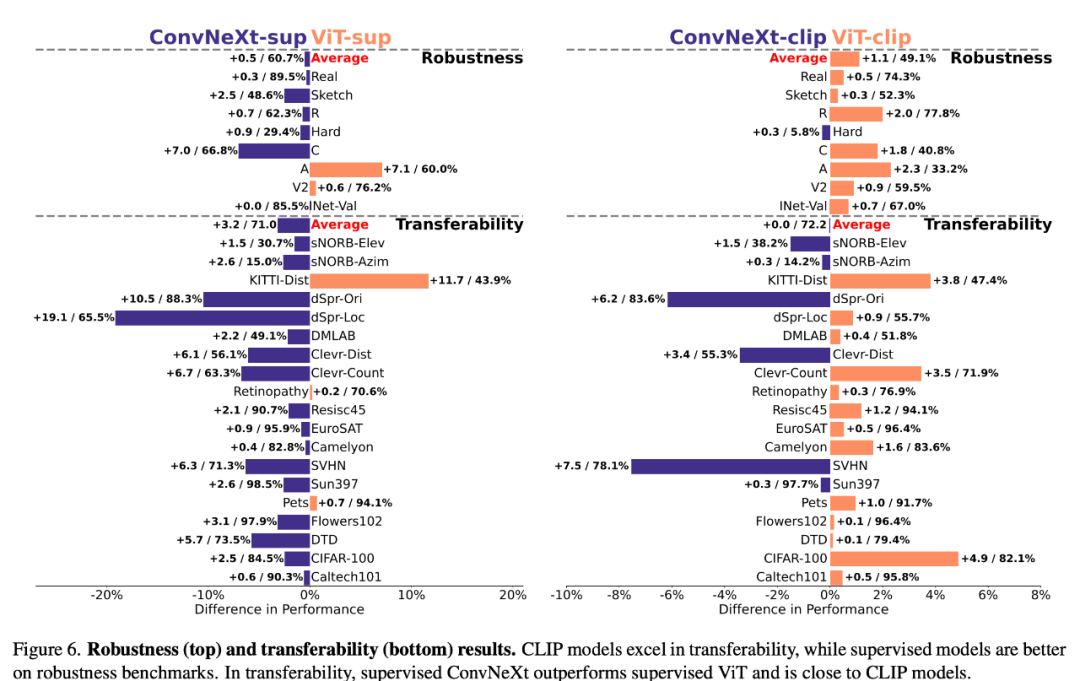
Robustheit und Übertragbarkeit
Robustheit und Übertragbarkeit des Modells sind entscheidend für die Anpassung an Änderungen in der Datenverteilung und neue Aufgaben. Die Forscher bewerteten die Robustheit anhand verschiedener ImageNet-Varianten und stellten fest, dass die durchschnittliche Leistung von ViT- und ConvNeXt-Modellen mit Ausnahme von ImageNet-R und ImageNet-Sketch zwar vergleichbar war, die überwachten Modelle jedoch im Allgemeinen CLIP in Bezug auf die Robustheit übertrafen. In Bezug auf die Übertragbarkeit übertrifft das überwachte ConvNeXt ViT und liegt fast auf Augenhöhe mit der Leistung des CLIP-Modells, wie anhand des VTAB-Benchmarks anhand von 19 Datensätzen bewertet.
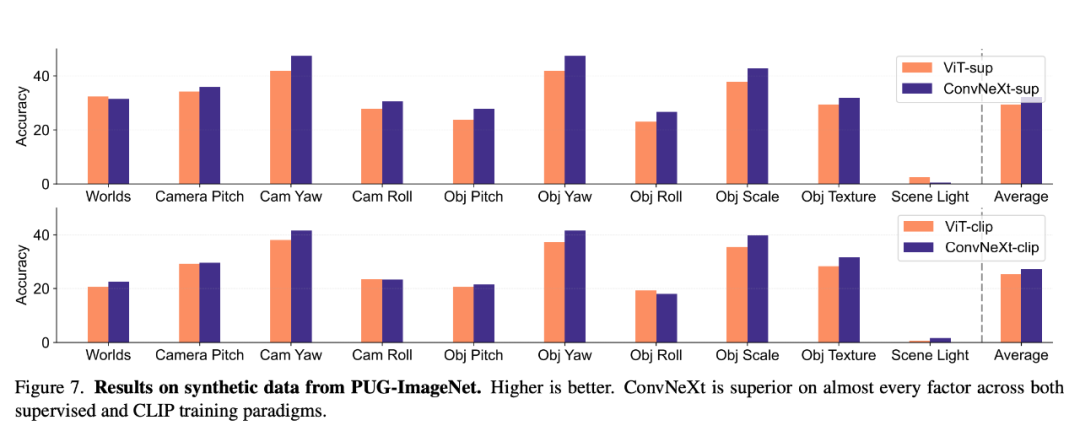
Synthetische Daten
PUG-ImageNet und andere synthetische Datensätze können Faktoren wie Kamerawinkel und Textur genau steuern. Dies ist ein vielversprechender Forschungsweg, daher analysierten die Forscher die Fähigkeit des Modells zur Synthese Leistung auf Daten. PUG-ImageNet enthält fotorealistische ImageNet-Bilder mit systematischen Variationen in Faktoren wie Pose und Beleuchtung, und die Leistung wird als absolute Top-1-Genauigkeit gemessen. Die Forscher liefern Ergebnisse zu verschiedenen Faktoren in PUG-ImageNet und stellen fest, dass ConvNeXt ViT in fast allen Faktoren übertrifft. Dies zeigt, dass ConvNeXt ViT bei synthetischen Daten übertrifft, während die Lücke für das CLIP-Modell kleiner ist, da die Genauigkeit des CLIP-Modells geringer ist als die des überwachten Modells, was möglicherweise mit der geringeren Genauigkeit des ursprünglichen ImageNet zusammenhängt.
Transformationsinvarianz
Transformationsinvarianz bezieht sich auf die Fähigkeit des Modells, konsistente Darstellungen zu erzeugen, die nicht durch Eingabetransformationen wie Skalierung oder Bewegung beeinflusst werden und dabei die Semantik beibehalten. Diese Eigenschaft ermöglicht eine gute Verallgemeinerung des Modells auf verschiedene, aber semantisch ähnliche Eingaben. Zu den verwendeten Methoden gehören die Größenänderung von Bildern für Skaleninvarianz, das Verschieben von Ausschnitten für Positionsinvarianz und die Anpassung der Auflösung von ViT-Modellen mithilfe interpolierter Positionseinbettungen.
Sie bewerteten Maßstabs-, Bewegungs- und Auflösungsinvarianz auf ImageNet-1K durch Variation von Zuschnittsmaßstab/-position und Bildauflösung. ConvNeXt übertrifft ViT im betreuten Training. Insgesamt ist das Modell robuster gegenüber Skalierungs-/Auflösungstransformationen als gegenüber Bewegungen. Für Anwendungen, die eine hohe Robustheit gegenüber Skalierung, Verschiebung und Auflösung erfordern, deuten die Ergebnisse darauf hin, dass überwachtes ConvNeXt möglicherweise die beste Wahl ist.

Zusammenfassung
Insgesamt hat jedes Modell seine eigenen einzigartigen Vorteile. Dies legt nahe, dass die Wahl des Modells vom Zielanwendungsfall abhängen sollte, da Standardleistungsmetriken möglicherweise kritische Nuancen einer bestimmten Aufgabe ignorieren. Darüber hinaus sind viele bestehende Benchmarks von ImageNet abgeleitet, was die Bewertung ebenfalls verzerrt. Die Entwicklung neuer Benchmarks mit unterschiedlichen Datenverteilungen ist von entscheidender Bedeutung, um Modelle in einer realistischeren repräsentativen Umgebung zu bewerten.
Das Folgende ist eine Zusammenfassung der Schlussfolgerungen dieses Artikels:
ConvNet mit Transformer
1. Supervised ConvNeXt übertrifft Supervised ViT bei vielen Benchmarks: Es ist besser kalibriert und invarianter Datentransformationen und weist eine bessere Portabilität und Robustheit auf.
2. ConvNeXt schneidet bei synthetischen Daten besser ab als ViT.
3. ViT weist eine größere Formabweichung auf.
Supervision vs. CLIP
1 Obwohl das CLIP-Modell hinsichtlich der Übertragbarkeit überlegen ist, schneidet das überwachte ConvNeXt bei dieser Aufgabe konkurrenzfähig ab. Dies zeigt das Potenzial überwachter Modelle.
2. Überwachte Modelle schneiden bei Robustheits-Benchmarks besser ab, wahrscheinlich weil es sich bei diesen Modellen allesamt um ImageNet-Varianten handelt.
3. Das CLIP-Modell weist im Vergleich zur Genauigkeit von ImageNet eine größere Formverzerrung und weniger Klassifizierungsfehler auf.
Das obige ist der detaillierte Inhalt vonWie wählen CV-Praktiker in der Post-Sora-Ära Modelle aus? Faltung oder ViT, überwachtes Lernen oder CLIP-Paradigma. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wertschätzung von HTML5-Animationsgrafiken und -Texten in 8 visuellen 3D-Effekten
- Was sind im ISO/OSI-Referenzmodell die Hauptfunktionen der Netzwerkschicht?
- Computer Vision-Bildklassifizierung
- Eine kurze Analyse der Roadmap der visuellen Wahrnehmungstechnologie für autonomes Fahren
- Verwenden Sie JavaScript, um 3D-Modelle und visuelle Effekte zu erstellen und anzuzeigen