Dieser Roboter heißt Cassie und stellte einst einen Weltrekord im 100-Meter-Lauf auf. Kürzlich haben Forscher an der University of California in Berkeley einen neuen Deep-Reinforcement-Learning-Algorithmus dafür entwickelt, der es ihm ermöglicht, Fähigkeiten wie scharfe Kurven zu meistern und verschiedenen Störungen zu widerstehen.
 war in der Lage, verschiedene Bewegungsfertigkeiten auszuführen. Ein allgemeiner Rahmen für eine robuste Kontrolle. Die Herausforderung ergibt sich aus der Komplexität der unteraktivierten Dynamik zweibeiniger Roboter und der unterschiedlichen Planung, die mit den einzelnen Bewegungsfähigkeiten verbunden ist. Die Schlüsselfrage, die Forscher zu lösen hoffen, lautet: Wie kann eine Lösung für hochdimensionale zweibeinige Roboter in Menschengröße entwickelt werden? Wie beherrscht man vielfältige, agile und robuste Beinbewegungsfähigkeiten wie Gehen, Laufen und Springen?
war in der Lage, verschiedene Bewegungsfertigkeiten auszuführen. Ein allgemeiner Rahmen für eine robuste Kontrolle. Die Herausforderung ergibt sich aus der Komplexität der unteraktivierten Dynamik zweibeiniger Roboter und der unterschiedlichen Planung, die mit den einzelnen Bewegungsfähigkeiten verbunden ist. Die Schlüsselfrage, die Forscher zu lösen hoffen, lautet: Wie kann eine Lösung für hochdimensionale zweibeinige Roboter in Menschengröße entwickelt werden? Wie beherrscht man vielfältige, agile und robuste Beinbewegungsfähigkeiten wie Gehen, Laufen und Springen?
Eine aktuelle Studie könnte eine gute Lösung liefern.
In dieser Arbeit verwenden Forscher aus Berkeley und anderen Institutionen Reinforcement Learning (RL), um Steuerungen für hochdimensionale nichtlineare Zweibeinroboter in der realen Welt zu entwickeln, um die oben genannten Herausforderungen zu bewältigen. Diese Controller können die propriozeptiven Informationen des Roboters nutzen, um sich an unsichere Dynamiken anzupassen, die sich im Laufe der Zeit ändern, und gleichzeitig in der Lage zu sein, sich an neue Umgebungen und Einstellungen anzupassen, indem sie die Agilität des zweibeinigen Roboters nutzen, um in unerwarteten Situationen robustes Verhalten zu zeigen. Darüber hinaus bietet unser Framework ein allgemeines Rezept für die Reproduktion verschiedener bipedaler Bewegungskompetenzen.
Titel des Papiers: Reinforcement Learning for Versatile, Dynamic, and Robust Bipedal Locomotion Control
-
Link zum Papier: https://arxiv.org/pdf/2401.16889.pdf
Die Hochdimensionalität und Nichtlinearität von drehmomentgesteuerten zweibeinigen Robotern in Menschengröße scheinen auf den ersten Blick Hindernisse für die Steuerung zu sein, diese Eigenschaften haben jedoch den Vorteil, dass sie durch die Hochdimensionalität des Roboters komplexe Implementierungen ermöglichen Dynamik. Agile Bedienung.
Die Fähigkeiten, die dieser Controller dem Roboter verleiht, sind in Abbildung 1 dargestellt, darunter stabiles Stehen, Gehen, Laufen und Springen. Diese Fähigkeiten können auch zur Ausführung verschiedener Aufgaben eingesetzt werden, darunter Gehen mit unterschiedlichen Geschwindigkeiten und Höhen, Laufen mit unterschiedlichen Geschwindigkeiten und Richtungen sowie das Springen zu verschiedenen Zielen, wobei die Robustheit während des tatsächlichen Einsatzes erhalten bleibt. Zu diesem Zweck verwenden Forscher modellfreies RL, um es Robotern zu ermöglichen, durch Versuch und Irrtum die Dynamik des Systems voller Ordnung zu erlernen. Zusätzlich zu realen Experimenten werden die Vorteile der Verwendung von RL zur Beinbewegungskontrolle eingehend analysiert und detailliert untersucht, wie der Lernprozess effektiv strukturiert werden kann, um diese Vorteile wie Anpassungsfähigkeit und Robustheit zu nutzen.
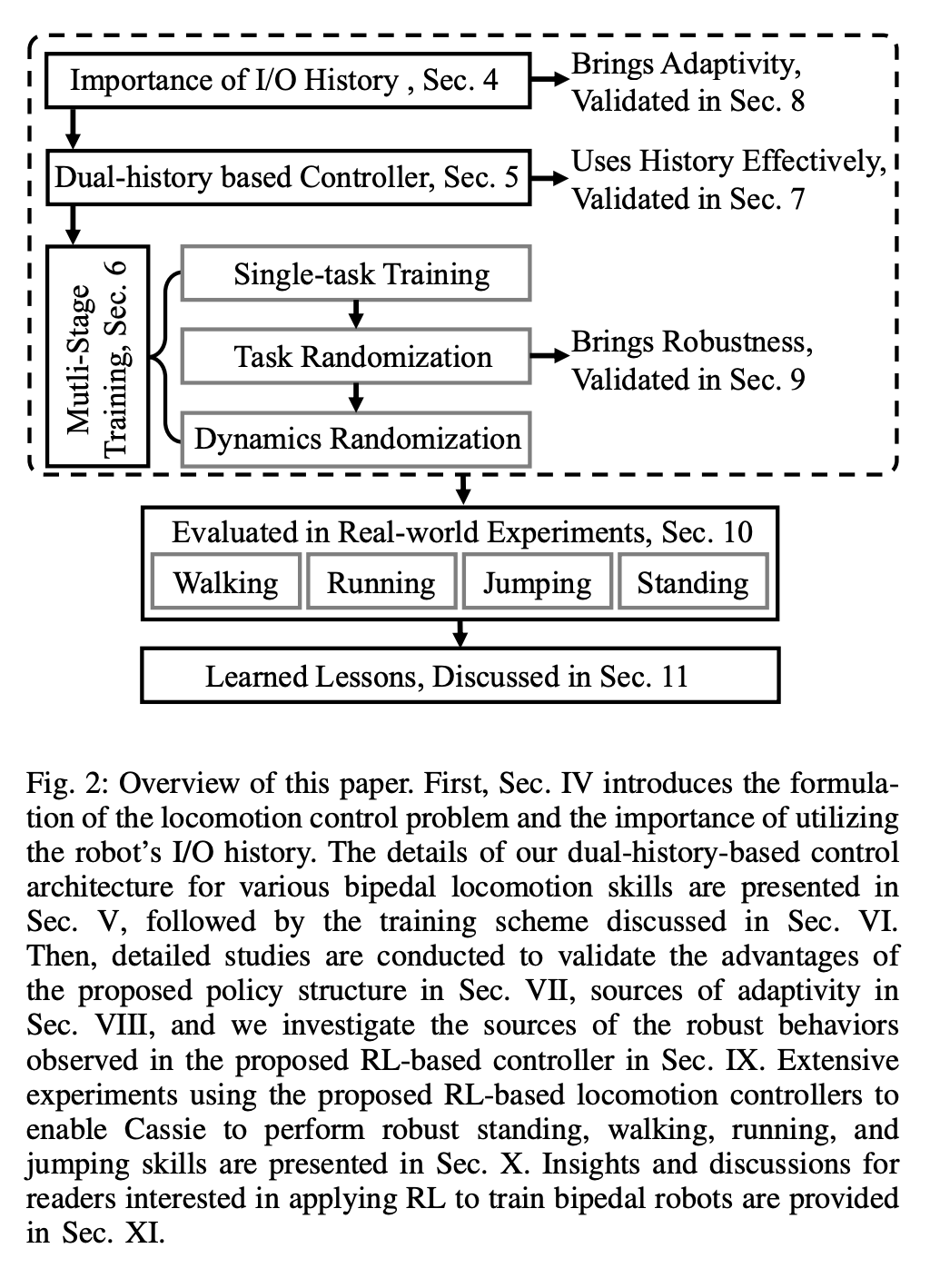
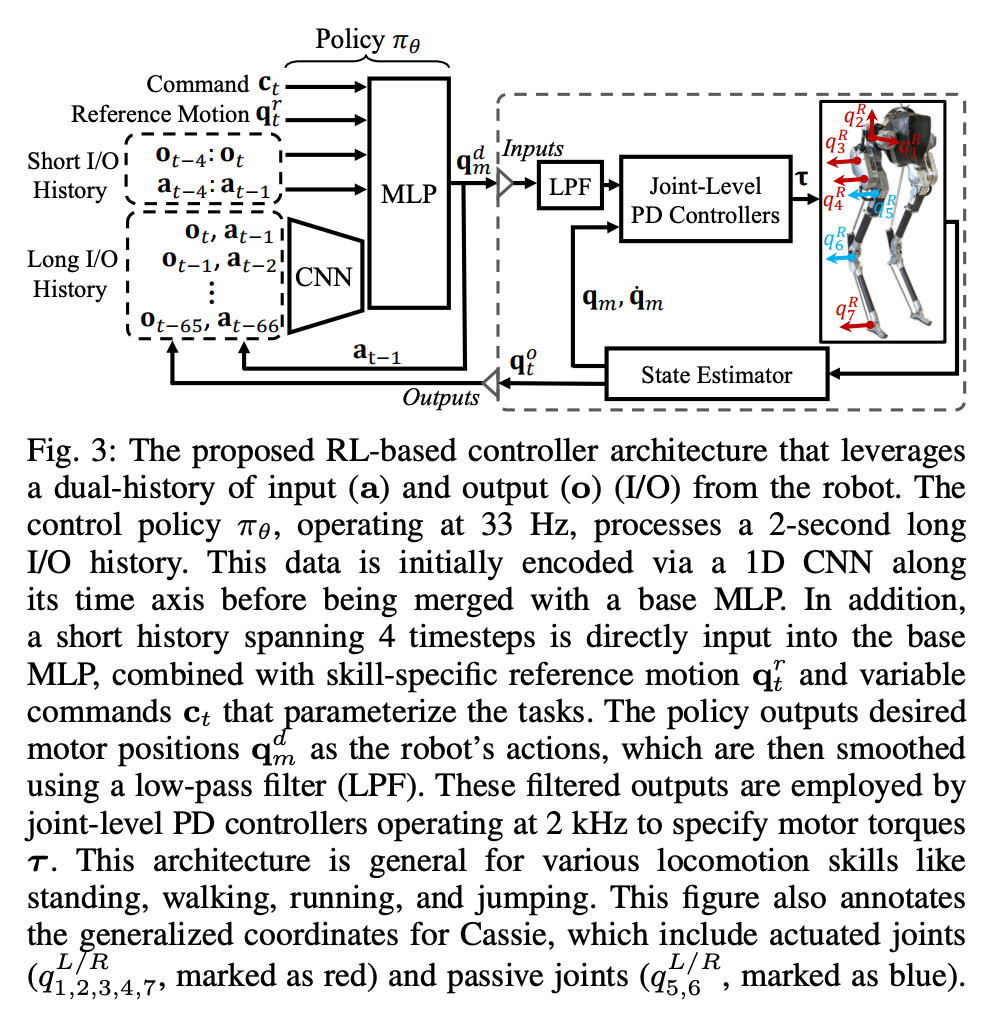
Das RL-System für die universelle bipedale Bewegungssteuerung ist in Abbildung 2 dargestellt: Abschnitt 4 stellt zunächst die Bedeutung der Verwendung der Roboter-E/A-Historie in der Bewegungssteuerung vor. In diesem Abschnitt wird sowohl aus der Steuerungs- als auch aus der RL-Perspektive erläutert Es wird gezeigt, dass die langfristige E/A-Historie des Roboters eine Systemidentifikation und Zustandsschätzung im Echtzeitsteuerungsprozess ermöglichen kann. Abschnitt 5 stellt den Kern der Forschung vor: eine neue Steuerungsarchitektur, die langfristige und kurzfristige I/O-Doppelhistorien von zweibeinigen Robotern nutzt. Insbesondere nutzt diese Steuerungsarchitektur nicht nur die Langzeitgeschichte des Roboters, sondern auch seine Kurzzeitgeschichte.
Der Kontrollrahmen ist wie folgt:
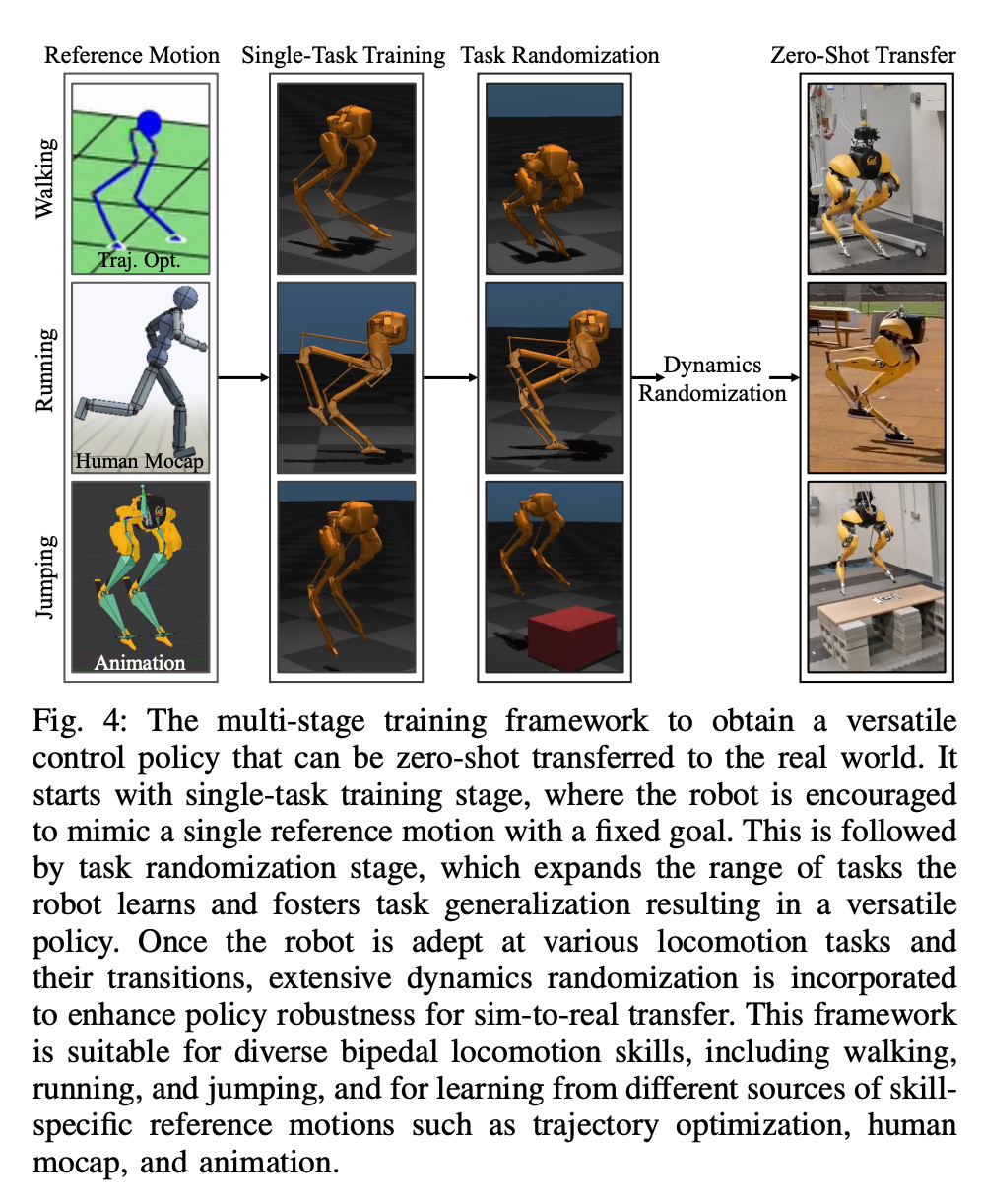
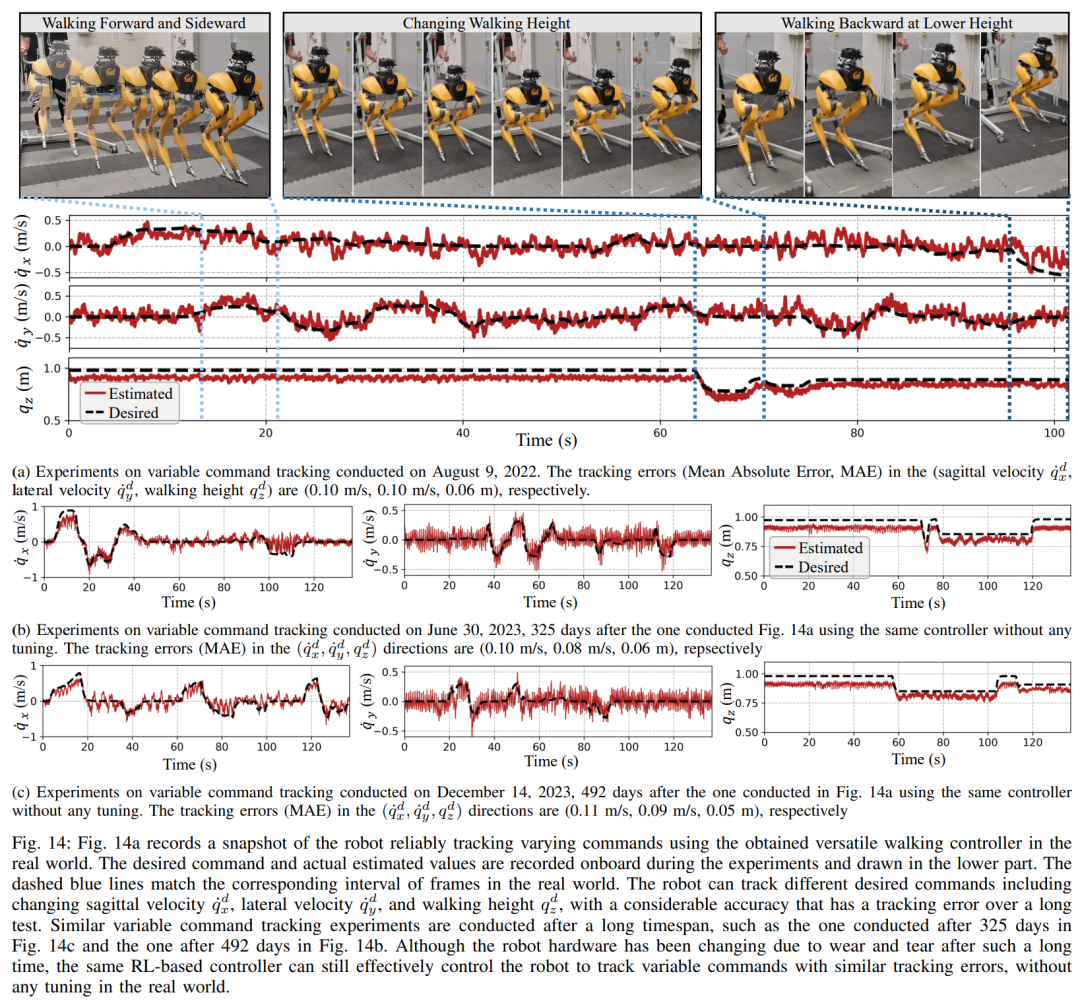
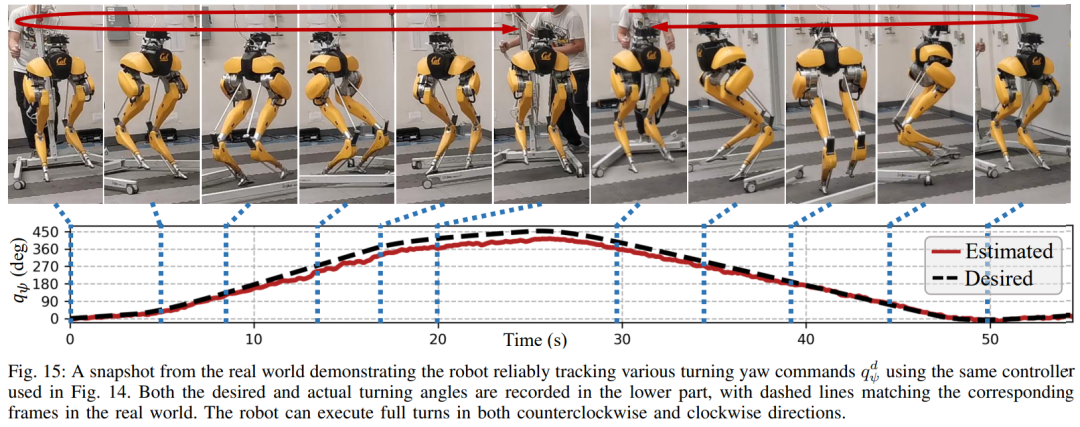
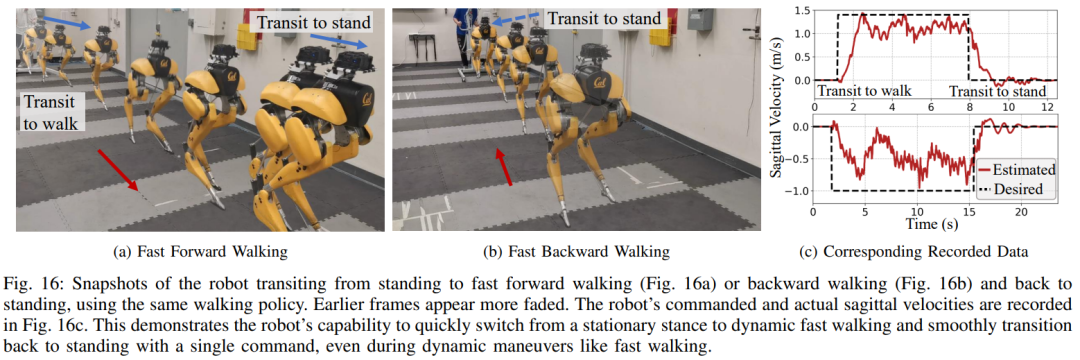
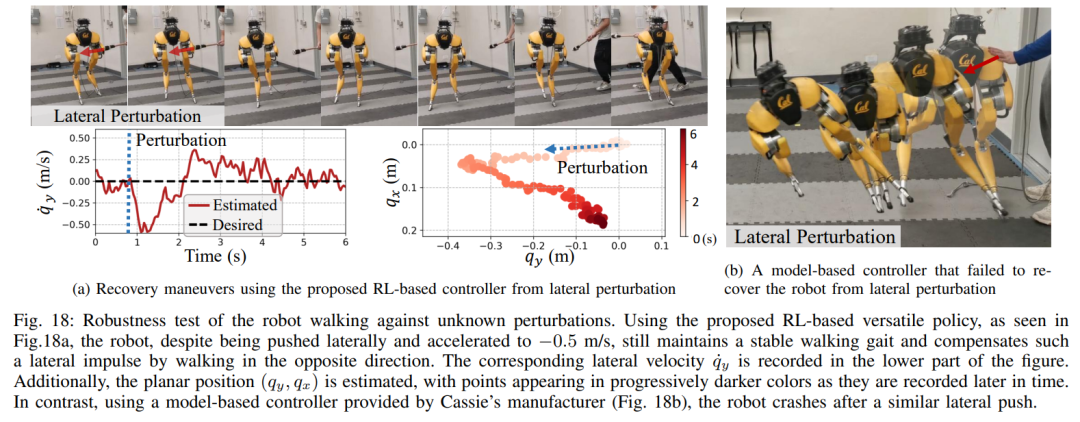
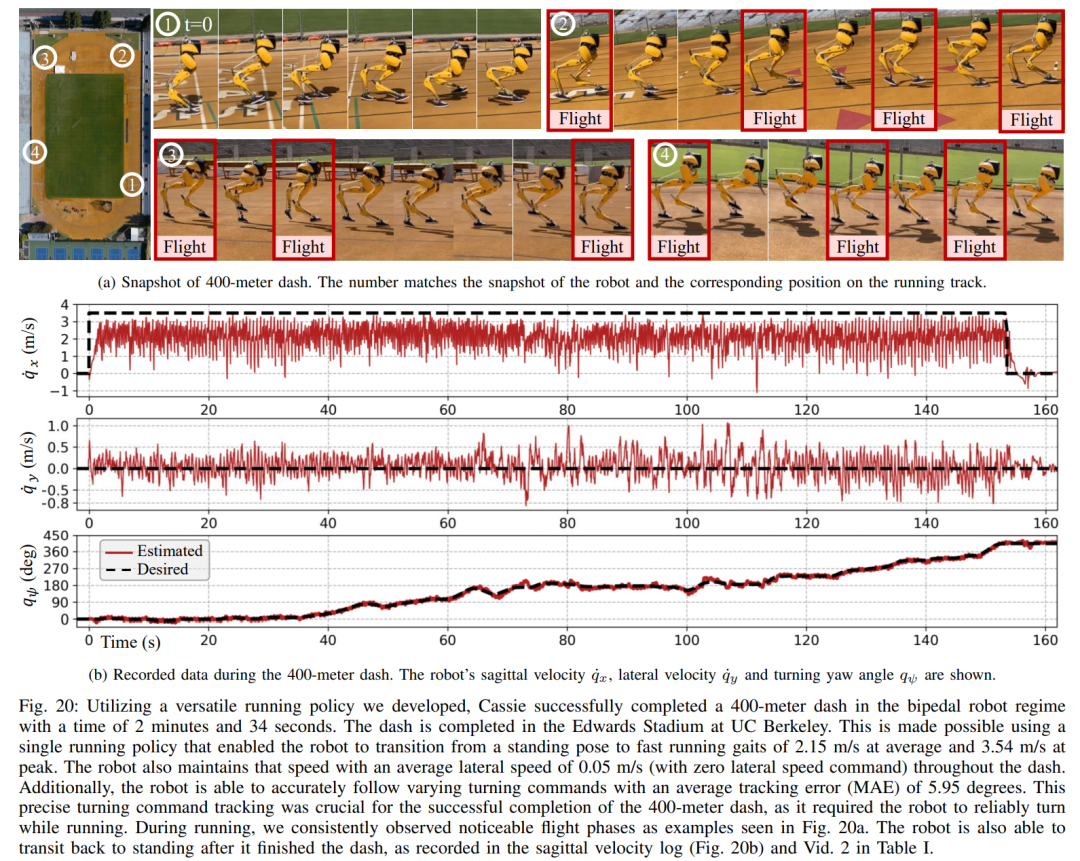
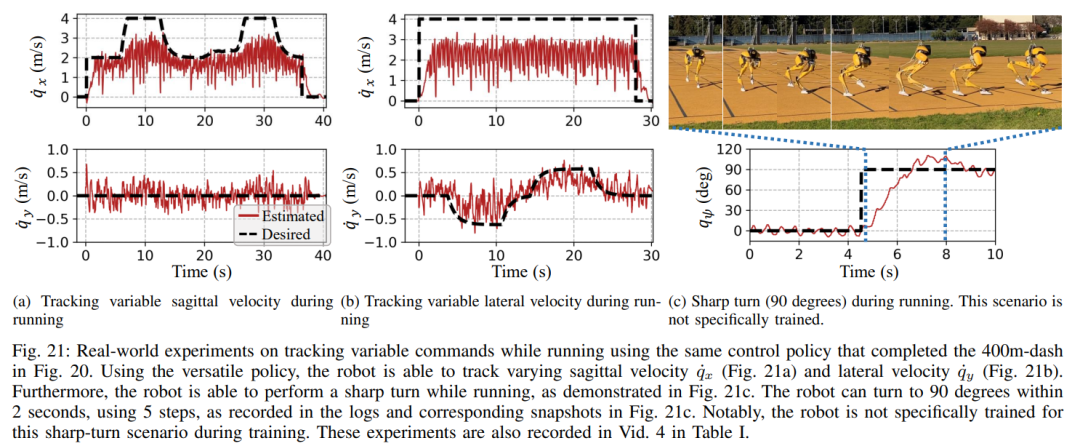
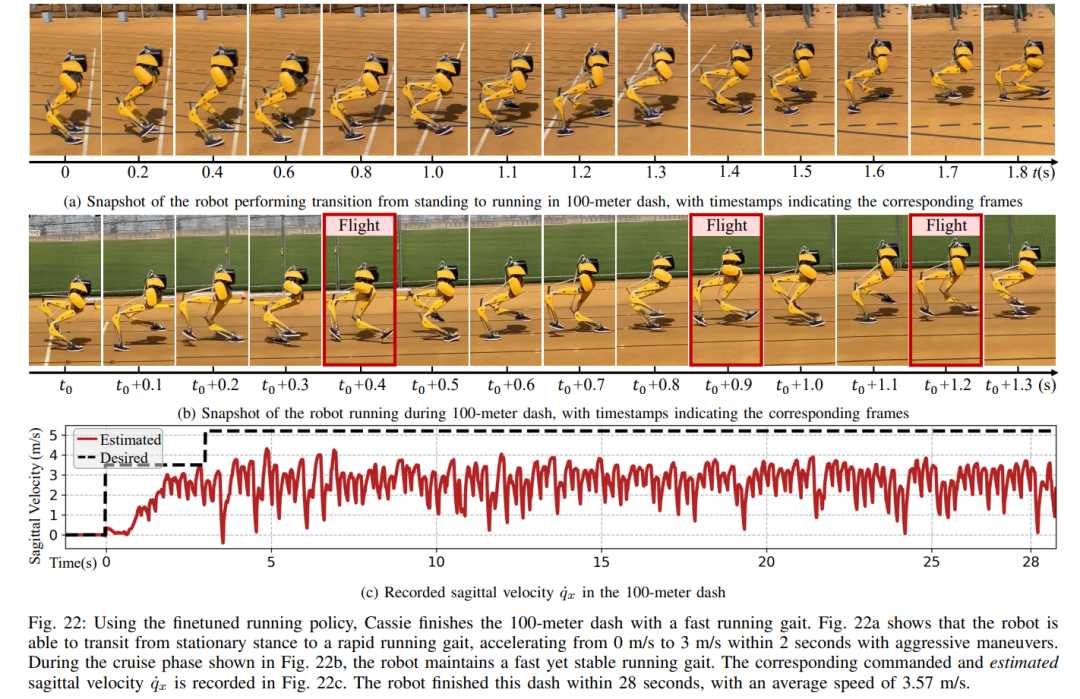
In dieser dualen Historienstruktur bringt die langfristige Historie Anpassungsfähigkeit (überprüft in Abschnitt 8), und die kurzfristige Historie wird durch die Nutzung besser umgesetzt der Langzeithistorie wird durch eine Echtzeitkontrolle ergänzt (validiert in Abschnitt 7). Abschnitt 6 stellt vor, wie durch tiefe neuronale Netze dargestellte Steuerungsstrategien durch modellfreies RL optimiert werden können. Da die Forscher darauf abzielten, einen Controller zu entwickeln, der in der Lage ist, hochdynamische motorische Fähigkeiten zur Bewältigung verschiedener Aufgaben zu nutzen, ist das Training in diesem Abschnitt durch ein mehrstufiges Simulationstraining gekennzeichnet. Diese Trainingsstrategie bietet einen strukturierten Kurs, beginnend mit einem Einzelaufgabentraining, bei dem sich der Roboter auf eine feste Aufgabe konzentriert, dann einer Aufgaben-Randomisierung, die die Trainingsaufgaben, die der Roboter erhält, diversifiziert, und schließlich einer dynamischen Randomisierung, die die dynamischen Parameter des Roboters ändert.Die -Strategie ist in der folgenden Abbildung dargestellt: Diese Trainingsstrategie kann eine vielseitige Steuerungsstrategie bereitstellen, die eine Vielzahl von Aufgaben ausführen und eine Zero-Sample-Migration der Roboterhardware erreichen kann. Darüber hinaus erhöht die Aufgabenrandomisierung auch die Robustheit der resultierenden Richtlinie durch die Verallgemeinerung auf verschiedene Lernaufgaben. Untersuchungen zeigen, dass diese Robustheit es Robotern ermöglichen kann, sich konform gegenüber Störungen zu verhalten, die „orthogonal“ zu den Störungen sind, die durch dynamische Randomisierung verursacht werden. Dies wird in Abschnitt 9 überprüft. Mit diesem Rahmen haben Forscher eine multifunktionale Strategie für die Geh-, Lauf- und Sprungfähigkeiten des zweibeinigen Roboters Cassie entwickelt. Kapitel 10 bewertet die Wirksamkeit dieser Kontrollstrategien in der realen Welt. Forscher führten umfangreiche Experimente mit dem Roboter durch und testeten dabei unter anderem mehrere Fähigkeiten wie Gehen, Laufen und Springen in der realen Welt. Die verwendeten Strategien sind alle in der Lage, reale Roboter nach dem Simulationstraining ohne weitere Anpassungen effektiv zu steuern. Wie in Abbildung 14a gezeigt, demonstriert die Gehstrategie eine effektive Steuerung des Roboters nach verschiedenen Anweisungen. Während des gesamten Testvorgangs ist der Trackingfehler recht gering (der Trackingfehler beträgt bestimmt durch den Wert des auszuwertenden MAE). Darüber hinaus zeigt die Roboterstrategie über längere Zeiträume hinweg eine durchweg gute Leistung und ermöglicht die Verfolgung variabler Befehle auch nach 325 bzw. 492 Tagen, wie in Abbildung 14c bzw. Abbildung 14b dargestellt. Trotz erheblicher kumulativer Änderungen in der Dynamik des Roboters in diesem Zeitraum bewältigt derselbe Controller in Abbildung 14a weiterhin effektiv verschiedene Laufaufgaben mit minimaler Verschlechterung des Spurfehlers. Wie in Abbildung 15 dargestellt, zeigte die in dieser Studie verwendete Strategie eine zuverlässige Steuerung des Roboters, sodass der Roboter verschiedene Drehbefehle im oder gegen den Uhrzeigersinn genau verfolgen konnte. Schnelles Gehexperiment. Zusätzlich zu moderaten Gehgeschwindigkeiten demonstrieren die Experimente auch die Fähigkeit der verwendeten Strategie, den Roboter so zu steuern, dass er schnelle Gehbewegungen vorwärts und rückwärts ausführt, wie in Abbildung 16 dargestellt. Der Roboter kann aus einem statischen Zustand schnell eine Vorwärtslaufgeschwindigkeit erreichen, mit einer Durchschnittsgeschwindigkeit von 1,14 m/s (1,4 m/s im Tracking-Befehl erforderlich). Der Roboter kann je nach Befehl auch schnell in eine stehende Haltung zurückkehren , wie in Abbildung 16a dargestellt, Datensatz in Abbildung 16c. Auf unebenem Gelände (ohne Training) kann der Roboter auch effektiv auf Treppen oder bergab rückwärts laufen, wie im Bild unten gezeigt. Anti-Störung. Bei Pulsstörungen beispielsweise leiten Forscher während des Gehens kurzfristige äußere Störungen aus allen Richtungen in den Roboter ein. Wie in Abbildung 18a dargestellt, wirkt auf den Roboter beim Gehen auf der Stelle eine beträchtliche seitliche Störungskraft mit einer seitlichen Spitzengeschwindigkeit von 0,5 m/s. Trotz der Störung erholte sich der Roboter schnell von seitlichen Abweichungen. Wie in Abbildung 18a dargestellt, bewegt sich der Roboter geschickt in die entgegengesetzte seitliche Richtung, wodurch die Störung effektiv ausgeglichen und sein stabiler Gang auf der Stelle wiederhergestellt wird. Während des kontinuierlichen Störungstests übten Menschen Störkräfte auf die Roboterbasis aus und zogen den Roboter in zufällige Richtungen, während sie dem Roboter befahlen, auf der Stelle zu gehen. Wie in Abbildung 19a dargestellt, wird beim normalen Gehen des Roboters eine kontinuierliche seitliche Widerstandskraft auf Cassies Basis ausgeübt. Die Ergebnisse zeigen, dass der Roboter diesen äußeren Kräften Folge leistet, indem er deren Richtung folgt, ohne das Gleichgewicht zu verlieren. Dies zeigt auch die Vorteile der in diesem Artikel vorgeschlagenen auf Verstärkungslernen basierenden Strategie für potenzielle Anwendungen wie die Steuerung zweibeiniger Roboter, um eine sichere Mensch-Roboter-Interaktion zu erreichen. Als der Roboter eine zweibeinige Laufstrategie verwendete, erreichte er einen 400-Meter-Sprint in 2 Minuten und 34 Sekunden und einen 100-Meter-Sprint in 27,06 Sekunden mit einem Lauf Neigung bis 10° etc. 400-Meter-Lauf: In der Studie wurden zunächst allgemeine Laufstrategien für die Bewältigung eines 400-Meter-Laufs auf einer Standardlaufbahn im Freien bewertet, wie in Abbildung 20 dargestellt.Während des gesamten Tests wurde dem Roboter befohlen, gleichzeitig auf verschiedene Drehbefehle des Bedieners mit einer Geschwindigkeit von 3,5 m/s zu reagieren. Der Roboter ist in der Lage, reibungslos von der Standhaltung in den Laufgang überzugehen (Abb. 20a 1). Dem Roboter gelang es, auf eine durchschnittliche geschätzte Betriebsgeschwindigkeit von 2,15 m/s zu beschleunigen und eine geschätzte Spitzengeschwindigkeit von 3,54 m/s zu erreichen, wie in Abbildung 20b dargestellt. Diese Strategie ermöglichte es dem Roboter, die gewünschte Geschwindigkeit während des gesamten 400-Meter-Laufs erfolgreich beizubehalten und gleichzeitig verschiedene Wendebefehle genau zu befolgen. Unter der Kontrolle der vorgeschlagenen Laufstrategie absolvierte Cassie erfolgreich den 400-m-Sprint in 2 Minuten und 34 Sekunden und konnte anschließend in eine stehende Position übergehen. Die Studie wurde außerdem mit einem scharfen Kurventest durchgeführt, bei dem dem Roboter eine schrittweise Änderung des Gierbefehls von 0 Grad direkt auf 90 Grad gegeben wurde, wie in Abbildung 21c aufgezeichnet. Der Roboter kann auf einen solchen Schrittbefehl reagieren und in 2 Sekunden und 5 Schritten eine scharfe 90-Grad-Drehung durchführen. 100-Meter-Lauf: Wie in Abbildung 22 dargestellt, absolvierte der Roboter durch Einsatz der vorgeschlagenen Laufstrategie den 100-Meter-Lauf in etwa 28 Sekunden und erreichte die schnellste Laufzeit von 27,06 Sekunden. Durch Experimente fanden die Forscher es schwierig, dem Roboter beizubringen, sich beim Springen auf eine erhöhte Plattform zu drehen, aber die vorgeschlagene Sprungstrategie ermöglichte eine Vielzahl verschiedener Zweibeiner für das Springen des Roboters , einschließlich der Fähigkeit, 1,4 Meter weit zu springen und auf eine 0,44 Meter hohe erhöhte Plattform zu springen. Springen und Drehen: Wie in Abbildung 25a gezeigt, kann der Roboter mit einer einzigen Sprungstrategie verschiedene vorgegebene Zielsprünge ausführen, z. B. bei einer Drehung um 60° auf der Stelle springen, rückwärts springen und 0,3 Meter dahinter landen . Auf erhöhte Plattform springen: Wie in Abbildung 25b gezeigt, kann der Roboter präzise zu Zielen an verschiedenen Orten springen, z. B. 1 Meter vor oder 1,4 Meter vor ihm. Er kann auch zu Orten in unterschiedlichen Höhen springen Sprung auf 0,44 Meter Höhe (wenn man bedenkt, dass der Roboter selbst nur 1,1 Meter groß ist). Weitere Informationen finden Sie im Originalpapier. Das obige ist der detaillierte Inhalt vonDas Laufen mit Ihnen ist schnell und stabil, der Roboter-Laufpartner ist da. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!


 war in der Lage, verschiedene Bewegungsfertigkeiten auszuführen. Ein allgemeiner Rahmen für eine robuste Kontrolle. Die Herausforderung ergibt sich aus der Komplexität der unteraktivierten Dynamik zweibeiniger Roboter und der unterschiedlichen Planung, die mit den einzelnen Bewegungsfähigkeiten verbunden ist.
war in der Lage, verschiedene Bewegungsfertigkeiten auszuführen. Ein allgemeiner Rahmen für eine robuste Kontrolle. Die Herausforderung ergibt sich aus der Komplexität der unteraktivierten Dynamik zweibeiniger Roboter und der unterschiedlichen Planung, die mit den einzelnen Bewegungsfähigkeiten verbunden ist.