
Heim >Technologie-Peripheriegeräte >KI >So erkunden und visualisieren Sie ML-Daten zur Objekterkennung in Bildern
So erkunden und visualisieren Sie ML-Daten zur Objekterkennung in Bildern

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-02-16 11:33:231287Durchsuche
In den letzten Jahren haben die Menschen ein tieferes Verständnis für die Bedeutung eines tiefgreifenden Verständnisses maschineller Lerndaten (ML-Daten) gewonnen. Da die Erkennung großer Datenmengen jedoch in der Regel einen hohen personellen und materiellen Aufwand erfordert, bedarf die weitverbreitete Anwendung im Bereich Computer Vision noch weiterer Entwicklung.
Normalerweise werden bei der Objekterkennung (eine Teilmenge der Computer Vision) Objekte im Bild durch die Definition von Begrenzungsrahmen positioniert. Es kann nicht nur das Objekt identifiziert werden, sondern auch der Kontext, die Größe und der Kontext des Objekts Beziehung zu anderen Elementen in der Szene. Gleichzeitig hilft ein umfassendes Verständnis der Verteilung von Klassen, der Vielfalt der Objektgrößen und der gemeinsamen Umgebungen, in denen Klassen auftreten, auch dabei, Fehlermuster im Trainingsmodell während der Auswertung und beim Debuggen zu entdecken, sodass zusätzliche Trainingsdaten bereitgestellt werden können gezielter ausgewählt werden.
In der Praxis tendiere ich zu folgendem Ansatz:
- Verwenden Sie vorab trainierte Modelle oder Erweiterungen des Basismodells, um den Daten Struktur zu verleihen. Zum Beispiel: Erstellen verschiedener Bildeinbettungen und Verwenden von Techniken zur Dimensionsreduzierung wie t-SNE oder UMAP. Diese können Ähnlichkeitskarten erstellen, um das Durchsuchen von Daten zu erleichtern. Darüber hinaus kann die Verwendung vorab trainierter Modelle zur Erkennung auch die Kontextextraktion erleichtern.
- Verwenden Sie Visualisierungstools, die solche Strukturen mit Statistik- und Überprüfungsfunktionen der Rohdaten integrieren können.
Im Folgenden werde ich vorstellen, wie man mit Renomics Spotlight interaktive Objekterkennungsvisualisierungen erstellt. Als Beispiel werde ich versuchen:
- Eine Visualisierung für einen Personendetektor in einem Bild zu erstellen.
- Die Visualisierungen umfassen Ähnlichkeitskarten, Filter und Statistiken zur einfachen Untersuchung Ihrer Daten.
- Sehen Sie sich jedes Bild im Detail mit der YOLOv8-Erkennung von Ground Truth und Ultralytics an.
Laden Sie die Personenbilder im COCO-Datensatz herunter
Installieren Sie zunächst die erforderlichen Pakete über den Befehl:
!pip install fiftyone ultralytics renumics-spotlightNutzen Sie die Ausfallsicherheits-Download-Funktion von
importpandasaspdimportnumpyasnpimportfiftyone.zooasfoz# 从 COCO 数据集中下载 1000 张带人的图像dataset = foz.load_zoo_dataset( "coco-2017"、split="validation"、label_types=[ "detections"、],classes=["person"]、 max_samples=1000、dataset_name="coco-2017-person-1k-validations"、)
Dann können Sie den folgenden Code verwenden:
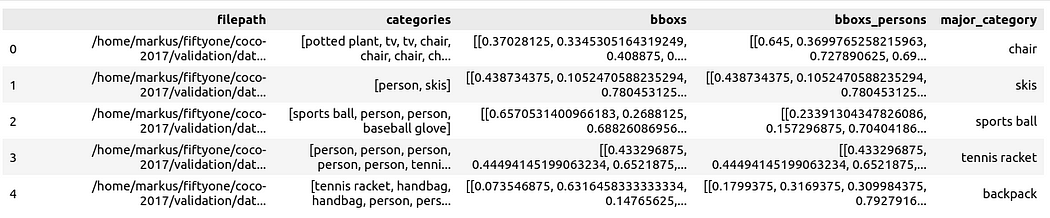
def xywh_too_xyxyn(bbox): "" convert from xywh to xyxyn format """ return[bbox[0], bbox[1], bbox[0] + bbox[2], bbox[1] + bbox[3]].行 = []fori, samplein enumerate(dataset):labels = [detection.labelfordetectioninsample.ground_truth.detections] bboxs = [...bboxs = [xywh_too_xyxyn(detection.bounding_box) fordetectioninsample.ground_truth.detections]bboxs_persons = [bboxforbbox, labelin zip(bboxs, labels)iflabel =="person"] 行。row.append([sample.filepath, labels, bboxs, bboxs_persons])df = pd.DataFrame(row, columns=["filepath","categories", "bboxs", "bboxs_persons"])df["major_category"] = df["categories"].apply( lambdax:max(set(x) -set(["person"]), key=x.count) if len(set(x)) >1 else "only person"。)
, um die Daten als Pandas DataFrame vorzubereiten, wobei die Spalten Folgendes umfassen: Dateipfad, Begrenzungsrahmenkategorie, Rahmenfeld, die im Rahmenfeld enthaltene Person und die Hauptkategorie (obwohl es Personen gibt), um den Kontext der Person im Bild anzugeben:
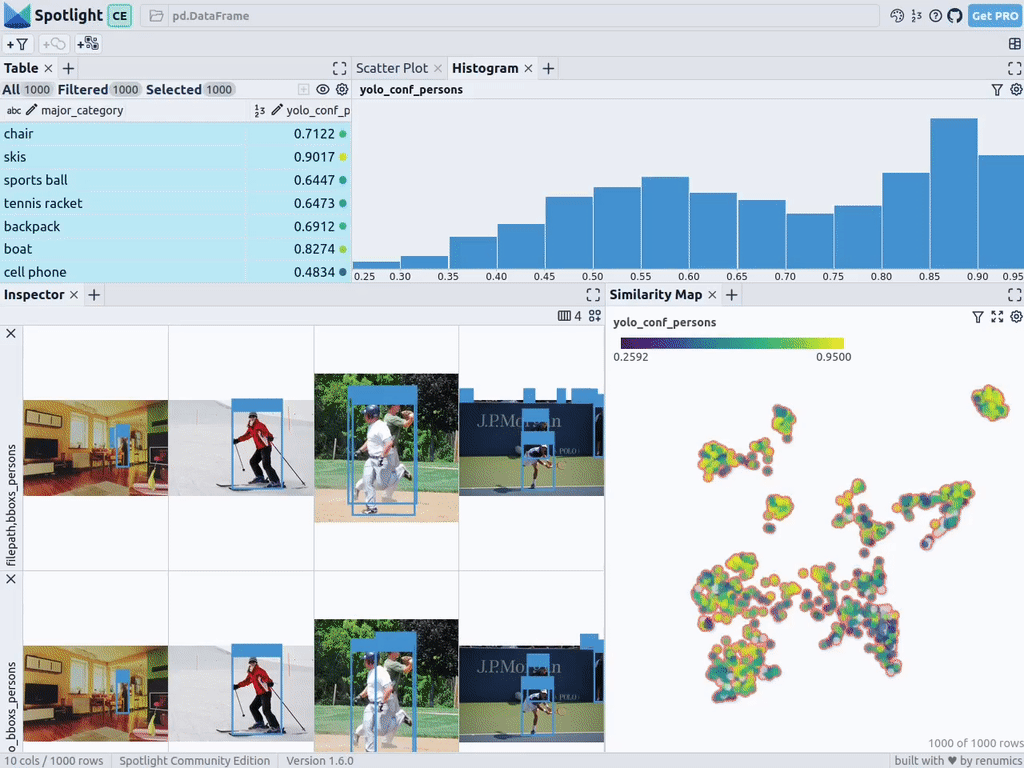
Sie können es dann über Spotlight visualisieren:
From renumics import spotlightspotlight.show(df)
Sie können die Schaltfläche „Ansicht hinzufügen“ in der Inspektoransicht verwenden und bboxs_persons und filepath in der Randansicht auswählen, um den entsprechenden Rand mit dem Bild anzuzeigen:
Rich Data einbetten
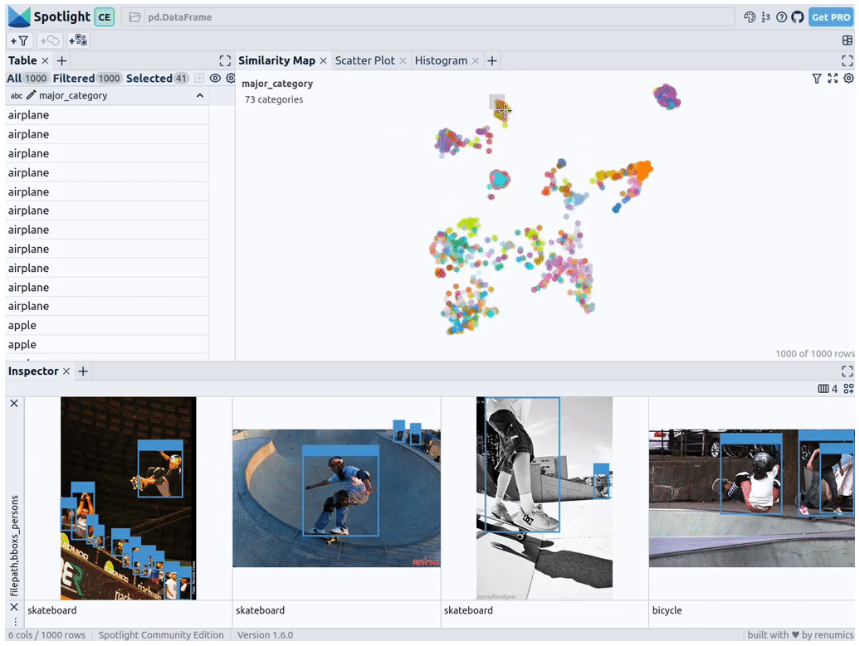
Geben Struktur der Daten können wir Bildeinbettungen verschiedener Grundmodelle übernehmen (d. h. dichte Vektordarstellung). Zu diesem Zweck können Sie weitere Dimensionsreduktionstechniken wie UMAP oder t-SNE verwenden, um Vision Transformer (ViT)-Einbettungen des gesamten Bildes auf die Strukturierung des Datensatzes anzuwenden und so eine 2D-Ähnlichkeitskarte des Bildes bereitzustellen. Darüber hinaus können Sie die Ausgabe eines vortrainierten Objektdetektors verwenden, um Ihre Daten zu strukturieren, indem Sie sie nach der Größe oder Anzahl der darin enthaltenen Objekte klassifizieren. Da der COCO-Datensatz diese Informationen bereits bereitstellt, können wir sie direkt verwenden.
Da Spotlight die Unterstützung für google/vit-base-patch16-224-in21k(ViT)-Modelle und UMAP integriert, wird beim Erstellen verschiedener Einbettungen mithilfe von Dateipfaden automatisch Folgendes angewendet:
spotlight.show(df, embed=["filepath"])
通过上述代码,Spotlight 将各种嵌入进行计算,并应用 UMAP 在相似性地图中显示结果。其中,不同的颜色代表了主要的类别。据此,您可以使用相似性地图来浏览数据:
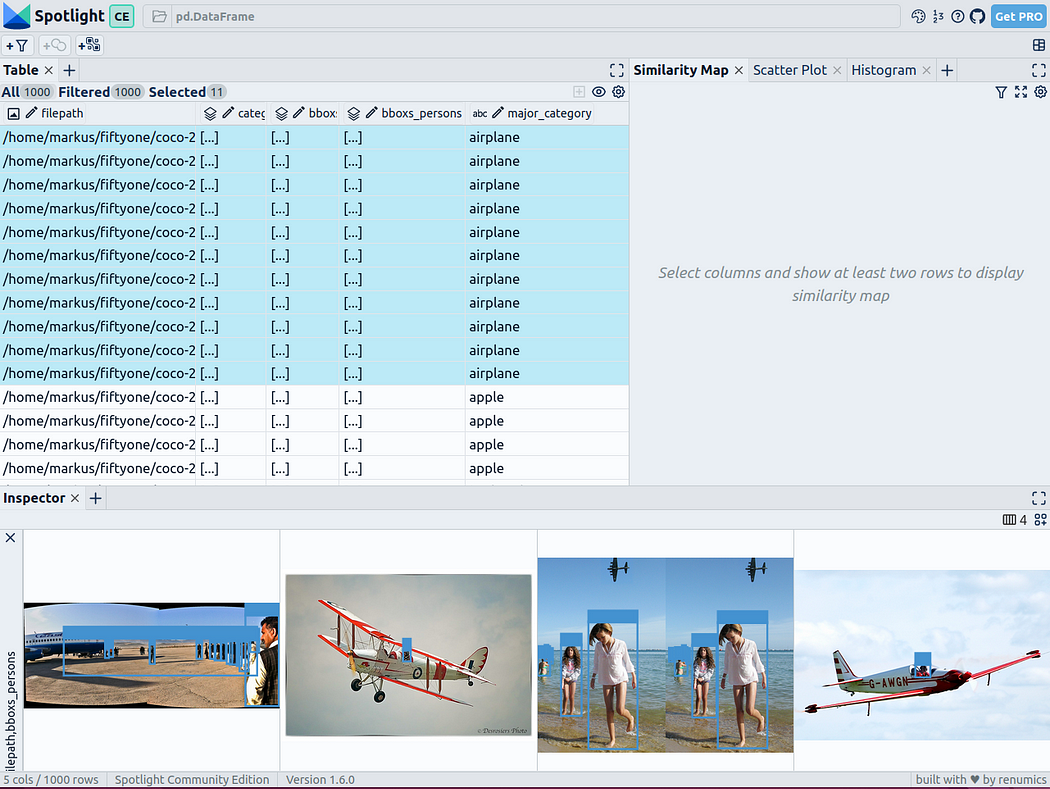
预训练YOLOv8的结果
可用于快速识别物体的Ultralytics YOLOv8,是一套先进的物体检测模型。它专为快速图像处理而设计,适用于各种实时检测任务,特别是在被应用于大量数据时,用户无需浪费太多的等待时间。
为此,您可以首先加载预训练模型:
From ultralytics import YOLOdetection_model = YOLO("yolov8n.pt")并执行各种检测:
detections = []forfilepathindf["filepath"].tolist():detection = detection_model(filepath)[0]detections.append({ "yolo_bboxs":[np.array(box.xyxyn.tolist())[0]forboxindetection.boxes]、 "yolo_conf_persons": np.mean([np.array(box.conf.tolist())[0]. forboxindetection.boxes ifdetection.names[int(box.cls)] =="person"]), np.mean(]), "yolo_bboxs_persons":[np.array(box.xyxyn.tolist())[0] forboxindetection.boxes ifdetection.names[int(box.cls)] =="person],"yolo_categories": np.array([np.array(detection.names[int(box.cls)])forboxindetection.boxes], "yolo_categories": np.array(),})df_yolo = pd.DataFrame(detections)在12gb的GeForce RTX 4070 Ti上,上述过程在不到20秒的时间内便可完成。接着,您可以将结果包含在DataFrame中,并使用Spotlight将其可视化。请参考如下代码:
df_merged = pd.concat([df, df_yolo], axis=1)spotlight.show(df_merged, embed=["filepath"])
下一步,Spotlight将再次计算各种嵌入,并应用UMAP到相似度图中显示结果。不过这一次,您可以为检测到的对象选择模型的置信度,并使用相似度图在置信度较低的集群中导航检索。毕竟,鉴于这些图像的模型是不确定的,因此它们通常有一定的相似度。
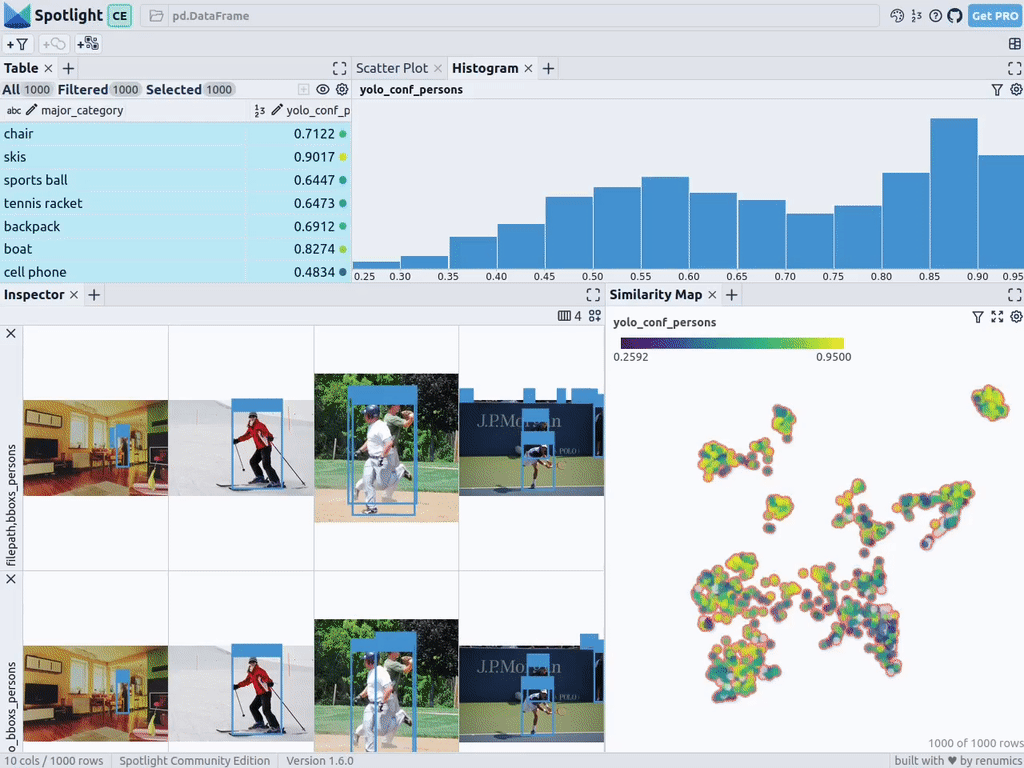
当然,上述简短的分析也表明了,此类模型在如下场景中会遇到系统性的问题:
- 由于列车体积庞大,站在车厢外的人显得非常渺小
- 对于巴士和其他大型车辆而言,车内的人员几乎看不到
- 有人站在飞机的外面
- 食物的特写图片上有人的手或手指
您可以判断这些问题是否真的会影响您的人员检测目标,如果是的话,则应考虑使用额外的训练数据,来增强数据集,以优化模型在这些特定场景中的性能。
小结
综上所述,预训练模型和 Spotlight 等工具的使用,可以让我们的对象检测可视化过程变得更加容易,进而增强数据科学的工作流程。您可以使用自己的数据去尝试和体验上述代码。
译者介绍
陈峻(Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。
原文标题:How to Explore and Visualize ML-Data for Object Detection in Images,作者:Markus Stoll
链接:https://itnext.io/how-to-explore-and-visualize-ml-data-for-object-detection-in-images-88e074f46361。
Das obige ist der detaillierte Inhalt vonSo erkunden und visualisieren Sie ML-Daten zur Objekterkennung in Bildern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Die 10 wichtigsten Algorithmen für maschinelles Lernen, die Sie kennen müssen
- Einführung in den maschinellen Lernalgorithmus sklearn von Python
- Implementierung von Algorithmen für maschinelles Lernen (ML) mit PHP
- Detaillierte Erläuterung des Deep-Learning-Pre-Training-Modells in Python
- Spezifische vorab trainierte Modelle für den biomedizinischen NLP-Bereich: PubMedBERT