Der Effekt ist stabiler und die Implementierung ist einfacher.
Der Erfolg großer Sprachmodelle (LLM) ist untrennbar mit „Reinforcement Learning basierend auf menschlichem Feedback (RLHF)“ verbunden. RLHF lässt sich grob in zwei Phasen unterteilen: Zunächst wird ein Belohnungsmodell bei einem Paar bevorzugter und ungünstiger Verhaltensweisen trainiert, um ersteren durch Klassifizierung des Ziels eine höhere Punktzahl zuzuweisen. Diese Belohnungsfunktion wird dann durch eine Art Reinforcement-Learning-Algorithmus optimiert. Allerdings können wesentliche Elemente des Belohnungsmodells einige unerwünschte Auswirkungen haben. Forscher der Carnegie Mellon University (CMU) und Google Research haben gemeinsam eine einfache, theoretisch strenge und experimentell wirksame neue RLHF-Methode vorgeschlagen – Self-Game Preference Optimization (SPO). Dieser Ansatz eliminiert Belohnungsmodelle und erfordert kein gegnerisches Training. 
Papier: Ein minimalmaximalistischer Ansatz zum verstärkenden Lernen aus menschlichem FeedbackPapieradresse: https://arxiv.org/abs/2401.04056Einführung in die Methode SPO Die Methoden umfassen hauptsächlich zwei Aspekte. Erstens eliminiert diese Studie das Belohnungsmodell tatsächlich, indem sie RLHF als Nullsummenspiel konstruiert, wodurch es besser in der Lage ist, mit lauten, nicht-markovianischen Präferenzen umzugehen, die in der Praxis häufig auftreten. Zweitens zeigt diese Studie durch Ausnutzung der Symmetrie des Spiels, dass ein einzelner Agent einfach im Selbstspielmodus trainiert werden kann, wodurch die Notwendigkeit eines instabilen gegnerischen Trainings entfällt. In der Praxis entspricht dies der Stichprobe mehrerer Trajektorien des Agenten, der Aufforderung an den Bewerter oder das Präferenzmodell, jedes Trajektorienpaar zu vergleichen, und der Festlegung der Belohnung auf die Gewinnquote der Trajektorie. SPO vermeidet Belohnungsmodellierung, zusammengesetzte Fehler und kontradiktorisches Training. Durch die Etablierung des Konzepts des Minmax-Gewinners aus der Theorie der sozialen Wahl konstruiert diese Studie RLHF als ein Zwei-Personen-Nullsummenspiel und nutzt die Symmetrie der Auszahlungsmatrix des Spiels, um zu zeigen, dass ein einzelner Agent einfach gegen sich selbst trainiert werden kann.
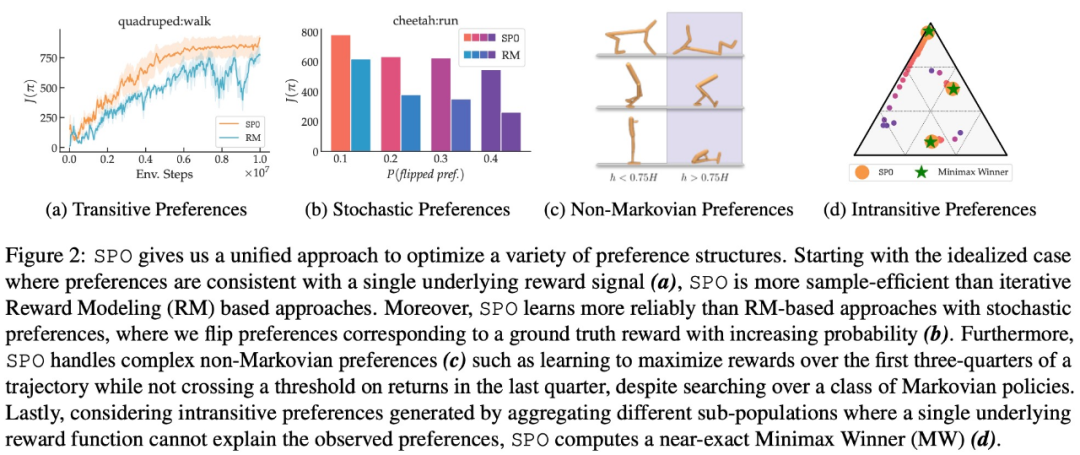
Die Studie analysiert auch die Konvergenzeigenschaften von SPO und beweist, dass SPO bei Vorhandensein der potenziellen Belohnungsfunktion mit einer schnellen Geschwindigkeit, die mit Standardmethoden vergleichbar ist, zur optimalen Richtlinie konvergieren kann. Diese Studie zeigt, dass SPO bei einer Reihe kontinuierlicher Kontrollaufgaben mit realistischen Präferenzfunktionen besser abschneidet als belohnungsmodellbasierte Methoden. SPO ist in der Lage, Stichproben in verschiedenen Präferenzeinstellungen effizienter zu lernen als belohnungsmodellbasierte Methoden, wie in Abbildung 2 unten dargestellt.
Diese Studie vergleicht SPO mit der Methode der iterativen Belohnungsmodellierung (RM) aus mehreren Dimensionen und zielt darauf ab, 4 Fragen zu beantworten:
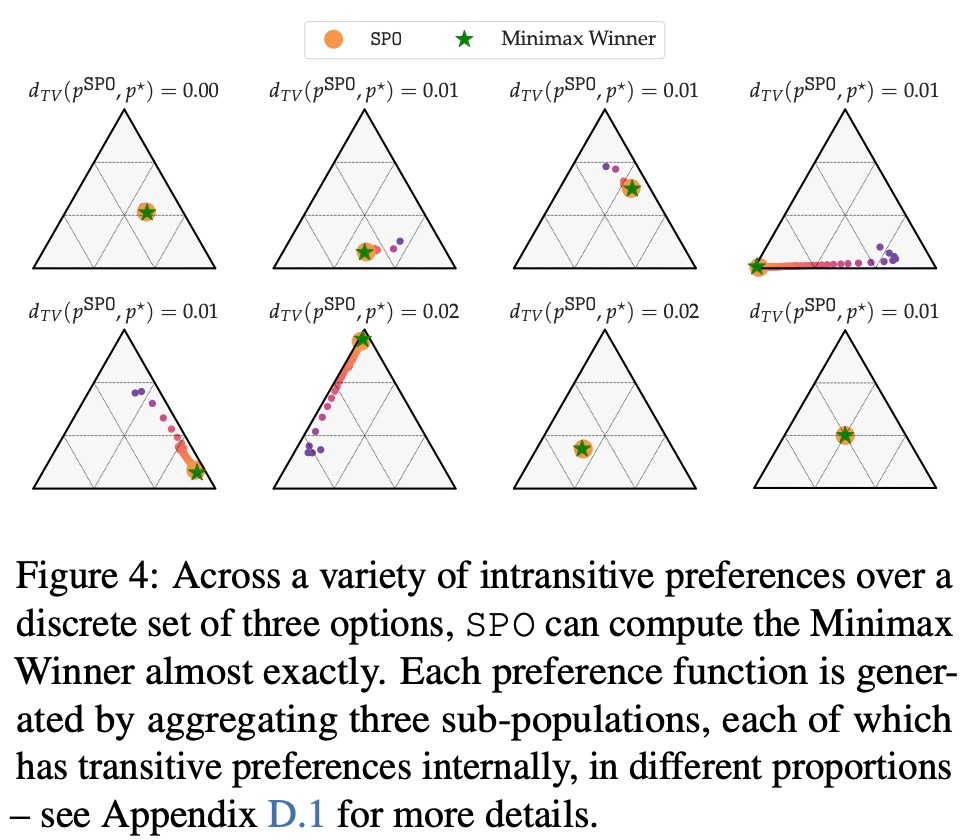
- Wenn intransitive Präferenzen konfrontiert werden, kann SPO berechnen MW?
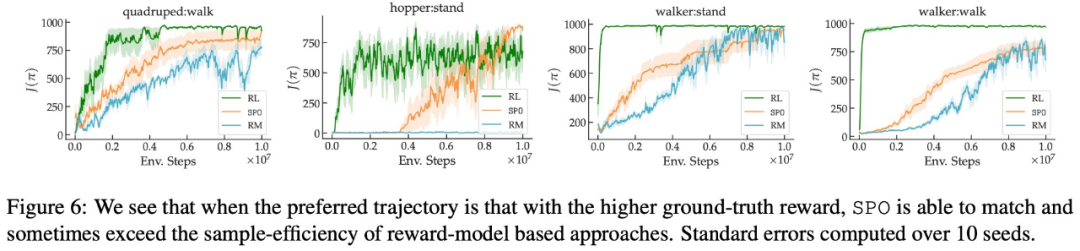
- Kann SPO die RM-Stichprobeneffizienz bei Problemen mit einzigartigen Copeland-Gewinnern/optimalen Strategien erreichen oder übertreffen?
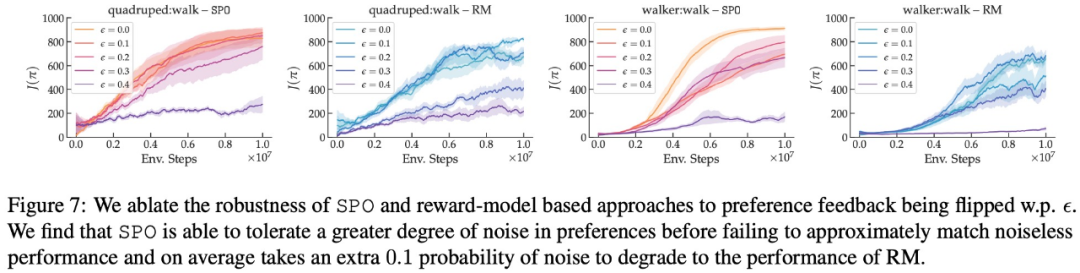
- Wie robust ist SPO gegenüber zufälligen Präferenzen?
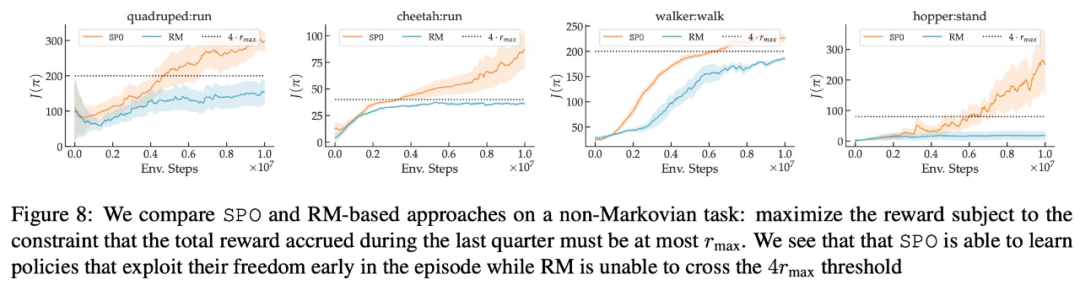
- Kann SPO mit nicht-markovianischen Präferenzen umgehen?
In Bezug auf maximale Belohnungspräferenz, Lärmpräferenz und Nicht-Markov-Präferenz sind die experimentellen Ergebnisse dieser Studie in den Abbildungen 6, 7 bzw. 8 dargestellt:
Interessierte Leser können den Originaltext des Artikels lesen, um mehr über den Forschungsinhalt zu erfahren. Das obige ist der detaillierte Inhalt vonGoogle schlägt eine neue RLHF-Methode vor: die Eliminierung von Belohnungsmodellen und die Eliminierung der Notwendigkeit einer gegnerischen Schulung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!