
Heim >Technologie-Peripheriegeräte >KI >Das von einem chinesischen Team erstellte Open-Source-Mathematikmodell 7B übertrifft Milliarden von GPT-4
Das von einem chinesischen Team erstellte Open-Source-Mathematikmodell 7B übertrifft Milliarden von GPT-4

- 王林nach vorne
- 2024-02-07 17:03:28733Durchsuche
7B Open-Source-Modell, die mathematische Leistung übertrifft den 100-Milliarden-GPT-4!
Man kann sagen, dass seine Leistung die Grenzen des Open-Source-Modells durchbrochen hat. Sogar Forscher von Alibaba Tongyi beklagten, ob das Skalierungsgesetz versagt hat.

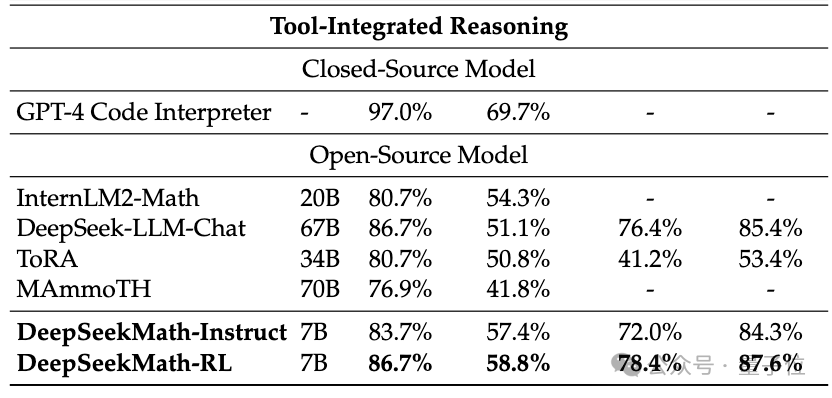
Ohne externe Tools kann eine Genauigkeit von 51,7 % im MATH-Datensatz auf Wettbewerbsebene erreicht werden.
Unter den Open-Source-Modellen ist es das erste, das bei diesem Datensatz die halbe Genauigkeit erreicht und damit sogar die frühen und API-Versionen von GPT-4 übertrifft.
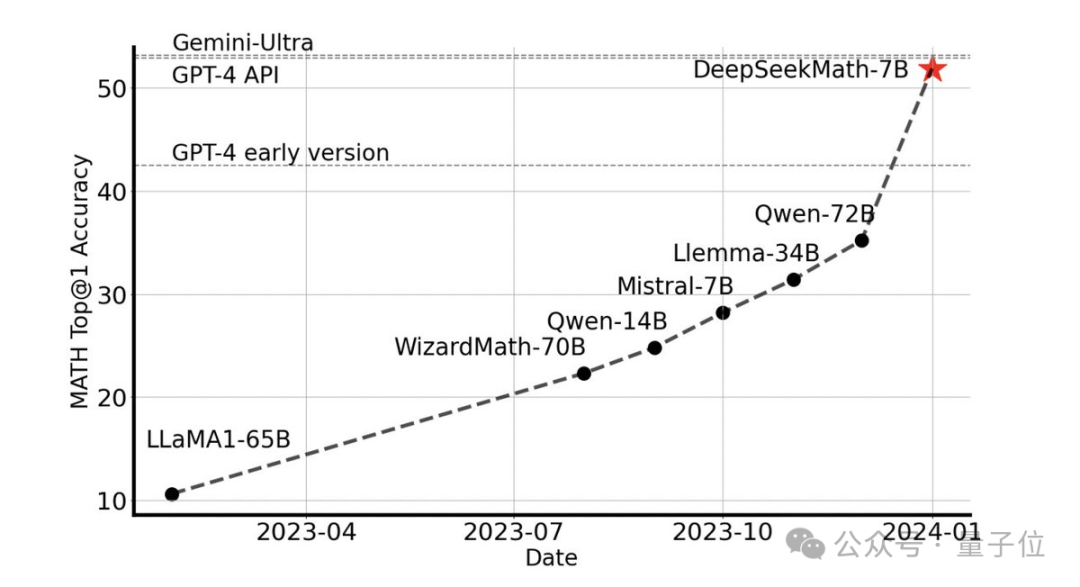
Diese Leistung schockierte die gesamte Open-Source-Community. Emad Mostaque, der Gründer von Stability AI, lobte das Forschungs- und Entwicklungsteam als beeindruckend und mit unterschätztem Potenzial.
Es ist das neueste Open-Source-7B-Mathematikmodell DeepSeekMath des Deep Search-Teams.
7B-Modell schlägt den Rest
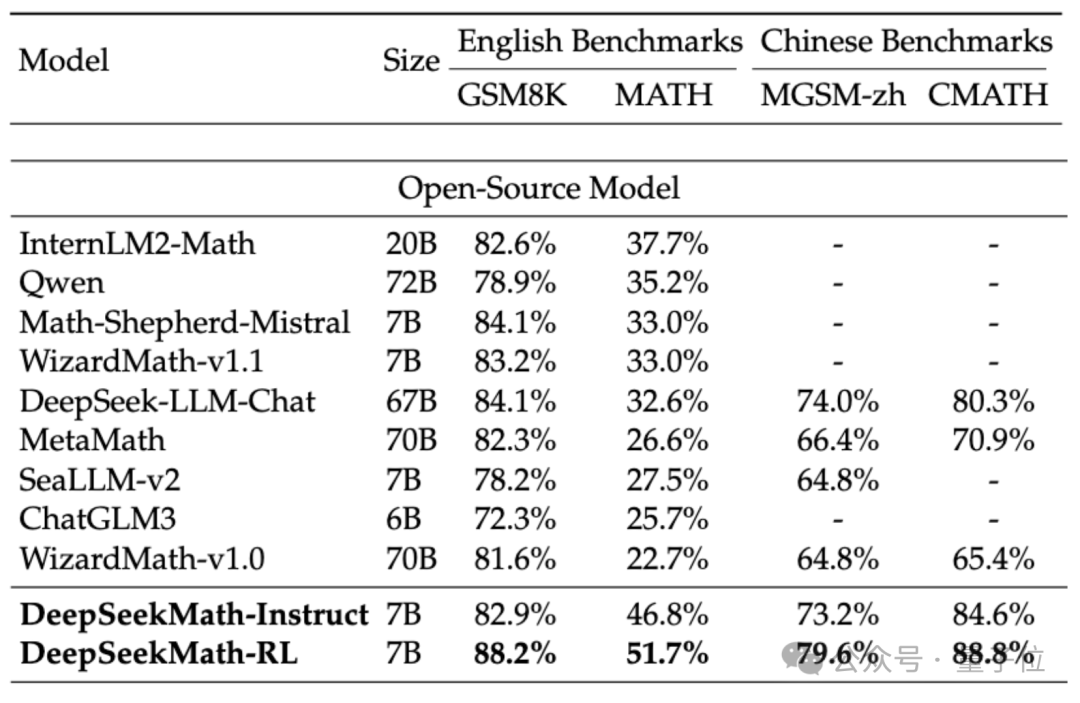
Um die mathematischen Fähigkeiten von DeepSeekMath zu bewerten, verwendete das Forschungsteam zweisprachige Datensätze auf Chinesisch (MGSM-zh, CMATH) Englisch (GSM8K, MATH) zum Testen.
Ohne Hilfswerkzeuge zu verwenden und sich nur auf die Eingabeaufforderungen der Gedankenkette (CoT) zu verlassen, übertraf die Leistung von DeepSeekMath andere Open-Source-Modelle, einschließlich des 70B großen mathematischen Modells MetaMATH.
Verglichen mit dem selbst gestarteten 67B-Universal-Großmodell wurden auch die Ergebnisse von DeepSeekMath deutlich verbessert.
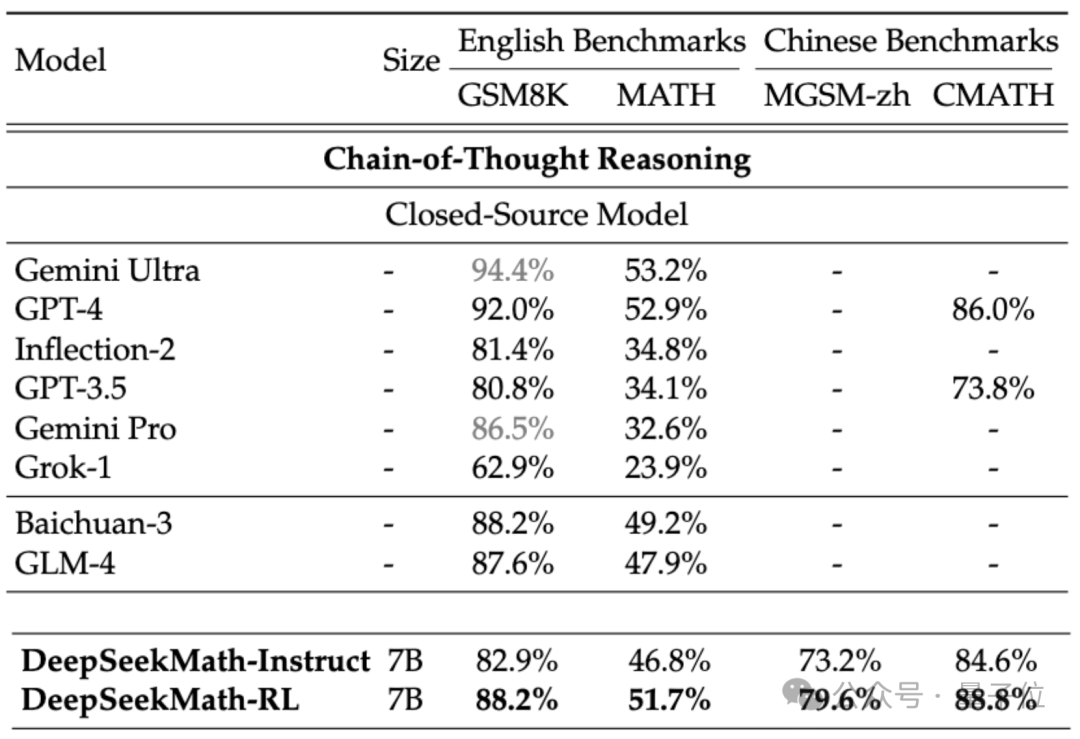
Wenn wir das Closed-Source-Modell betrachten, übertrifft DeepSeekMath auch Gemini Pro und GPT-3.5 bei mehreren Datensätzen, übertrifft GPT-4 bei chinesischem CMATH und seine Leistung bei MATH liegt ebenfalls nahe daran.
Aber es sollte beachtet werden, dass GPT-4 laut durchgesickerten Spezifikationen ein Gigant mit Hunderten von Milliarden Parametern ist, während DeepSeekMath nur 7B Parameter hat.
Wenn das Tool (Python) zur Unterstützung verwendet werden darf, kann die Leistung von DeepSeekMath auf dem Datensatz mit der Wettbewerbsschwierigkeit (MATH) um weitere 7 Prozentpunkte verbessert werden.
Welche Technologien werden also hinter der hervorragenden Leistung von DeepSeekMath eingesetzt?
Basierend auf dem Codemodell erstellt
Um bessere mathematische Fähigkeiten als mit dem allgemeinen Modell zu erhalten, verwendete das Forschungsteam das Codemodell DeepSeek-Coder-v1.5, um es zu initialisieren.
Weil das Team herausgefunden hat, dass Code-Training die mathematischen Fähigkeiten des Modells im Vergleich zu allgemeinem Datentraining verbessern kann, sei es in einem zweistufigen oder einstufigen Trainingsumfeld.
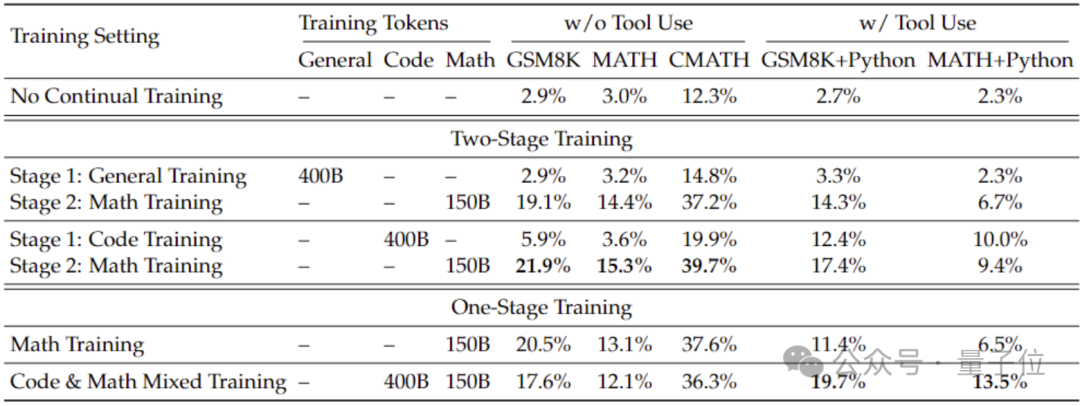
Basierend auf Coder trainierte das Forschungsteam weiterhin 500 Milliarden Token. Die Datenverteilung ist wie folgt:
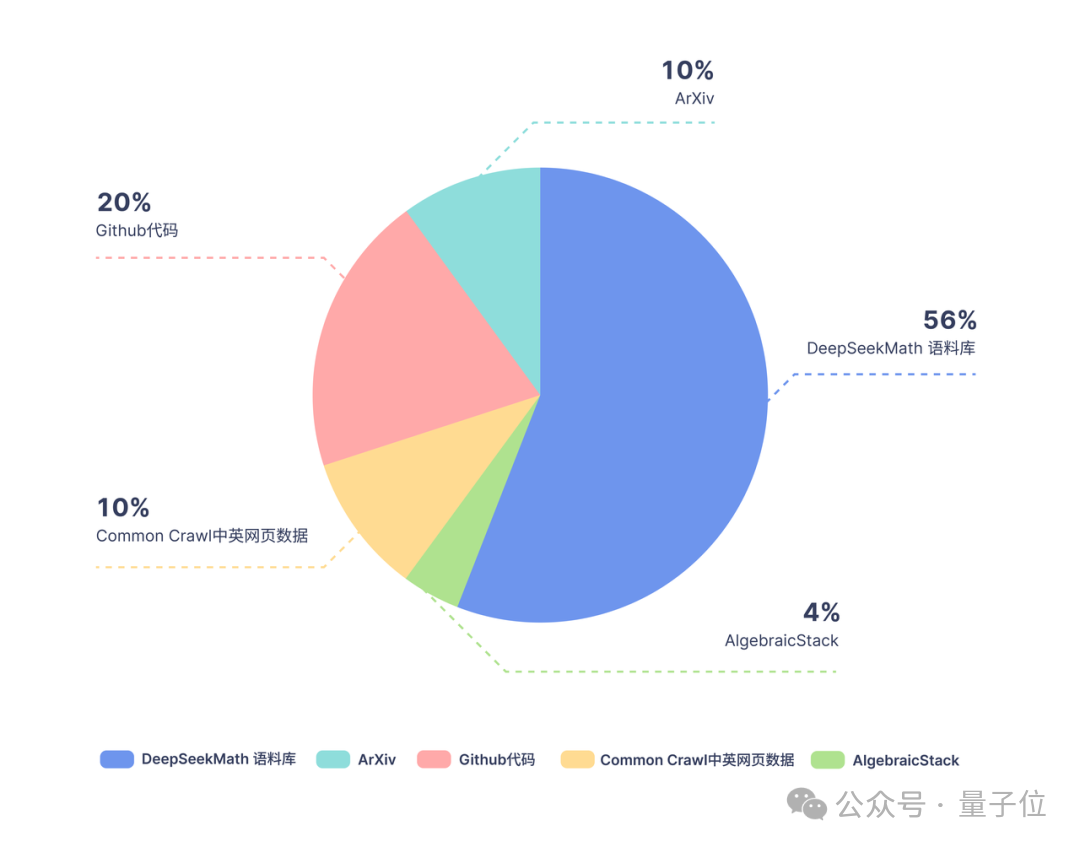
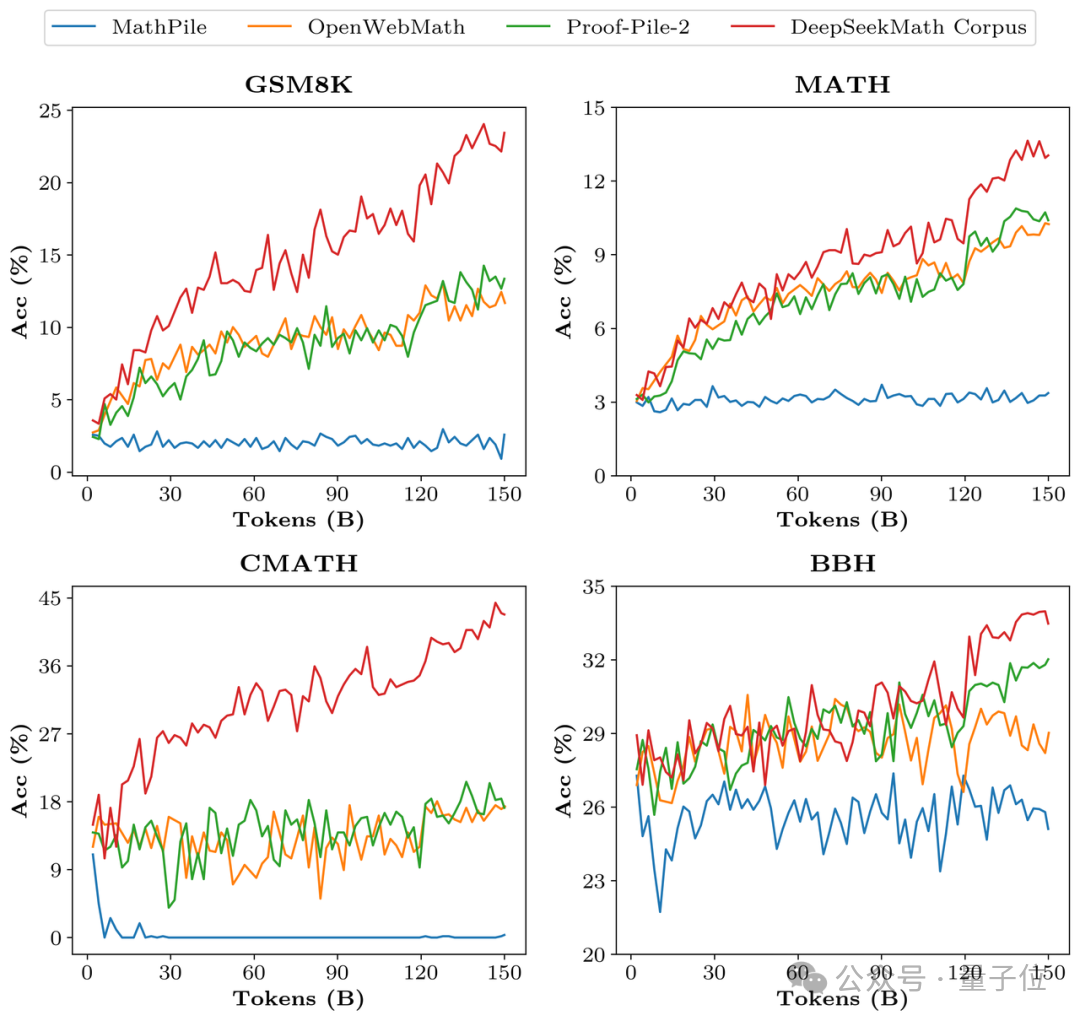
In Bezug auf Trainingsdaten verwendet DeepSeekMath 120 Milliarden hochwertige mathematische Webseitendaten, die aus Common Crawl extrahiert wurden Das DeepSeekMath-Korpus wurde erhalten und das Gesamtdatenvolumen beträgt das Neunfache des Open-Source-Datensatzes OpenWebMath.
Der Datenerfassungsprozess wird iterativ durchgeführt. Nach vier Iterationen sammelte das Forschungsteam mehr als 35 Millionen mathematische Webseiten und die Anzahl der Token erreichte 120 Milliarden.
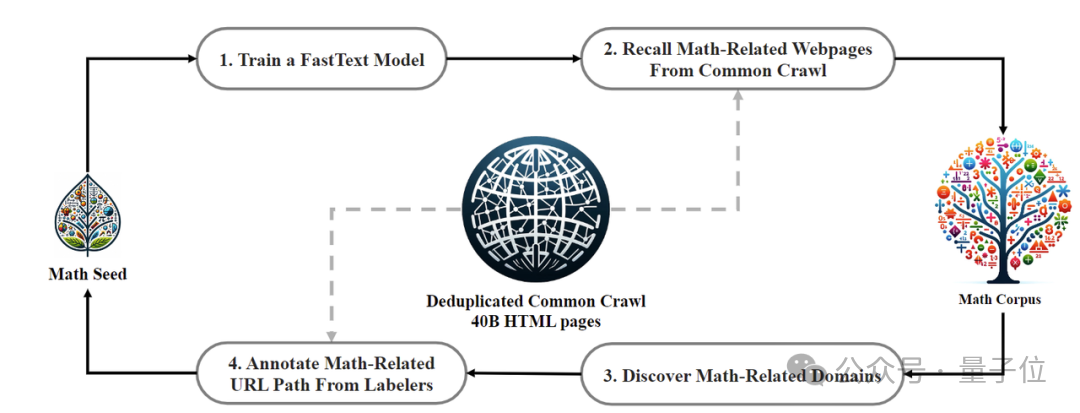
Um sicherzustellen, dass die Trainingsdaten nicht den Inhalt des Testsatzes enthalten (da der Inhalt in GSM8K und MATH in großen Mengen im Internet vorhanden ist), führte das Forschungsteam auch eine spezielle Filterung durch.
Um die Datenqualität von DeepSeekMath Corpus zu überprüfen, trainierte das Forschungsteam 150 Milliarden Token mit mehreren Datensätzen wie MathPile. Dadurch lag Corpus bei mehreren mathematischen Benchmarks deutlich vorne.
In der Ausrichtungsphase erstellte das Forschungsteam zunächst einen 776.000 Stichprobendatensatz für die überwachte Feinabstimmung (SFT) der chinesischen und englischen Mathematik, der drei Formate umfasst: CoT, PoT und werkzeugintegrierte Inferenz.
In der Phase des verstärkenden Lernens (RL) verwendete das Forschungsteam einen effizienten Algorithmus namens „Group Relative Policy Optimization (GRPO) “.
GRPO ist eine Variante der Proximal Policy Optimization(PPO) , bei der die traditionelle Wertfunktion durch eine gruppenbasierte relative Belohnungsschätzung ersetzt wird, die den Rechen- und Speicherbedarf während des Trainings reduzieren kann.
Gleichzeitig wird GRPO durch einen iterativen Prozess trainiert und das Belohnungsmodell wird basierend auf der Ausgabe des Richtlinienmodells kontinuierlich aktualisiert, um eine kontinuierliche Verbesserung der Richtlinie sicherzustellen.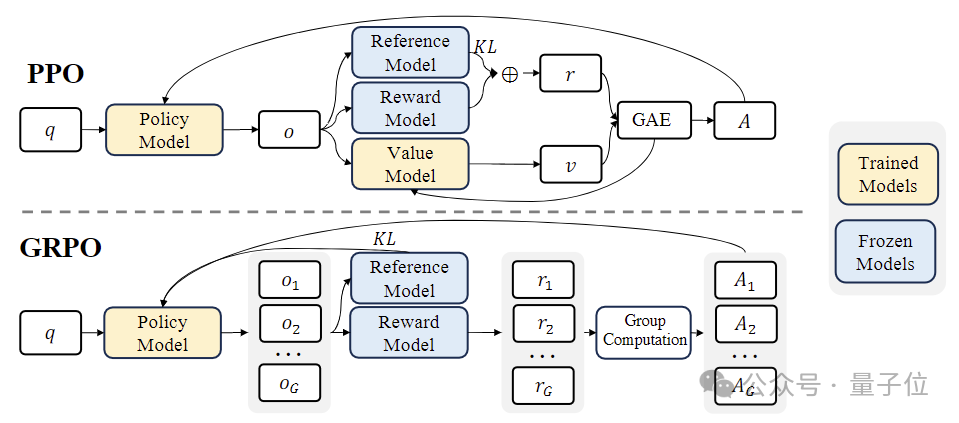

Papieradresse: https://arxiv.org/abs/2402.03300
Das obige ist der detaillierte Inhalt vonDas von einem chinesischen Team erstellte Open-Source-Mathematikmodell 7B übertrifft Milliarden von GPT-4. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!