
Heim >Technologie-Peripheriegeräte >KI >Mit der neuen aufgabenübergreifenden Selbstentwicklungsstrategie der Tsinghua-Universität und der HKU kommen wir der völligen Autonomie einen Schritt näher und ermöglichen es Agenten, „aus Erfahrungen zu lernen'.
Mit der neuen aufgabenübergreifenden Selbstentwicklungsstrategie der Tsinghua-Universität und der HKU kommen wir der völligen Autonomie einen Schritt näher und ermöglichen es Agenten, „aus Erfahrungen zu lernen'.

- PHPznach vorne
- 2024-02-07 09:31:141430Durchsuche
„Aus der Geschichte zu lernen kann uns helfen, die Höhen und Tiefen zu verstehen.“ Die Geschichte des menschlichen Fortschritts ist ein Selbstentwicklungsprozess, der ständig auf Erfahrungen aus der Vergangenheit zurückgreift und die Grenzen der Fähigkeiten verschiebt. Wir lernen aus vergangenen Misserfolgen und korrigieren Fehler; wir lernen aus erfolgreichen Erfahrungen, um Effizienz und Effektivität zu verbessern. Diese Selbstentwicklung zieht sich durch alle Aspekte des Lebens: Indem wir Erfahrungen zusammenfassen, um Arbeitsprobleme zu lösen, Muster verwenden, um das Wetter vorherzusagen, lernen wir weiter und entwickeln uns aus der Vergangenheit weiter.
Die erfolgreiche Gewinnung von Wissen aus vergangenen Erfahrungen und deren Anwendung auf zukünftige Herausforderungen ist ein wichtiger Meilenstein auf dem Weg zur menschlichen Evolution. Können KI-Agenten im Zeitalter der künstlichen Intelligenz dasselbe tun?
In den letzten Jahren haben Sprachmodelle wie GPT und LLaMA erstaunliche Fähigkeiten bei der Lösung komplexer Aufgaben bewiesen. Obwohl sie Tools zur Lösung spezifischer Aufgaben nutzen können, mangelt es ihnen von Natur aus an Erkenntnissen und Erkenntnissen aus vergangenen Erfolgen und Misserfolgen. Dies ist wie bei einem Roboter, der nur eine bestimmte Aufgabe erledigen kann, obwohl er bei der aktuellen Aufgabe gute Leistungen erbringt, bei neuen Herausforderungen jedoch nicht auf seine bisherigen Erfahrungen zurückgreifen kann. Deshalb müssen wir diese Modelle weiterentwickeln, damit sie Wissen und Erfahrungen sammeln und in neuen Situationen anwenden können. Durch die Einführung von Gedächtnis- und Lernmechanismen können wir die Intelligenz dieser Modelle umfassender gestalten, sie in die Lage versetzen, flexibel auf verschiedene Aufgaben und Situationen zu reagieren und uns von früheren Erfahrungen inspirieren zu lassen. Dadurch werden Sprachmodelle leistungsfähiger und zuverlässiger und die Entwicklung künstlicher Intelligenz vorangetrieben.
Als Reaktion auf dieses Problem hat ein gemeinsames Team der Tsinghua University, der Hong Kong University, der Renmin University und Wall-Facing Intelligence kürzlich eine neue Strategie zur Selbstentwicklung intelligenter Agenten vorgeschlagen: Investigate-Consolidate-Exploit, ICE). Ziel ist es, die Anpassungsfähigkeit und Flexibilität von KI-Agenten durch aufgabenübergreifende Selbstentwicklung zu verbessern. Es kann nicht nur die Effizienz und Effektivität des Agenten bei der Bewältigung neuer Aufgaben verbessern, sondern auch die Nachfrage nach den Fähigkeiten des Agentenbasismodells erheblich reduzieren.
Das Aufkommen dieser Strategie hat tatsächlich ein neues Kapitel in der Selbstentwicklung intelligenter Agenten aufgeschlagen und markiert für uns auch einen weiteren Schritt vorwärts auf dem Weg zu vollständig autonomen Agenten.

- Titel des Papiers: Investigate-Consolidate-Exploit: A General Strategy for Inter-Task Agent Self-Evolution
- Link zum Papier: https://arxiv.org/abs/2401.13996
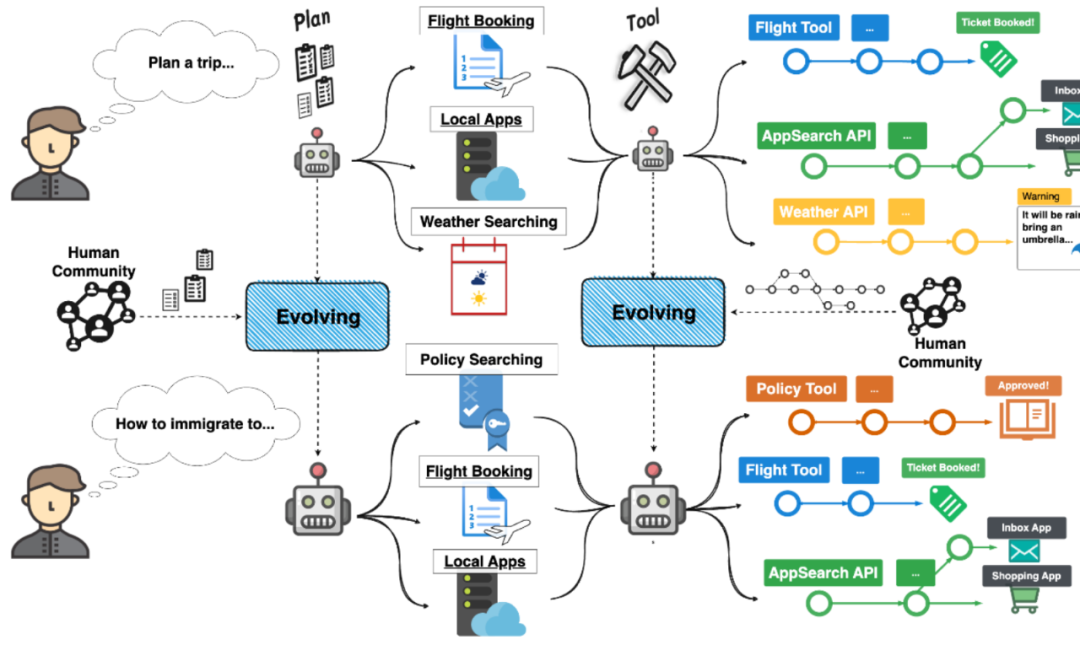 Überblick über den Erfahrungstransfer zwischen Agentenaufgaben, um eine Selbstentwicklung zu erreichen
Überblick über den Erfahrungstransfer zwischen Agentenaufgaben, um eine Selbstentwicklung zu erreichen
Zwei Aspekte der Agentenselbstentwicklung: Planung und Ausführung
Aktuelle komplexe Agenten können hauptsächlich in Aufgaben unterteilt werden Sowohl Planung und Aufgabenausführungsaspekte. Im Hinblick auf die Aufgabenplanung zerlegt der Agent die Benutzerbedürfnisse und entwickelt durch logisches Denken detaillierte Zielstrategien. Im Hinblick auf die Aufgabenausführung nutzt der Agent verschiedene Tools, um mit der Umgebung zu interagieren und die entsprechenden Unterziele zu erreichen.
Um die Wiederverwendung vergangener Erfahrungen besser zu fördern, entkoppelt der Autor in diesem Artikel zunächst die Evolutionsstrategie in zwei Aspekte. Insbesondere verwendet der Autor die Struktur der Baumaufgabenplanung und die Ausführung des ReACT-Kettentools in der XAgent-Agentenarchitektur als Beispiele, um die Implementierungsmethode der ICE-Strategie im Detail vorzustellen.
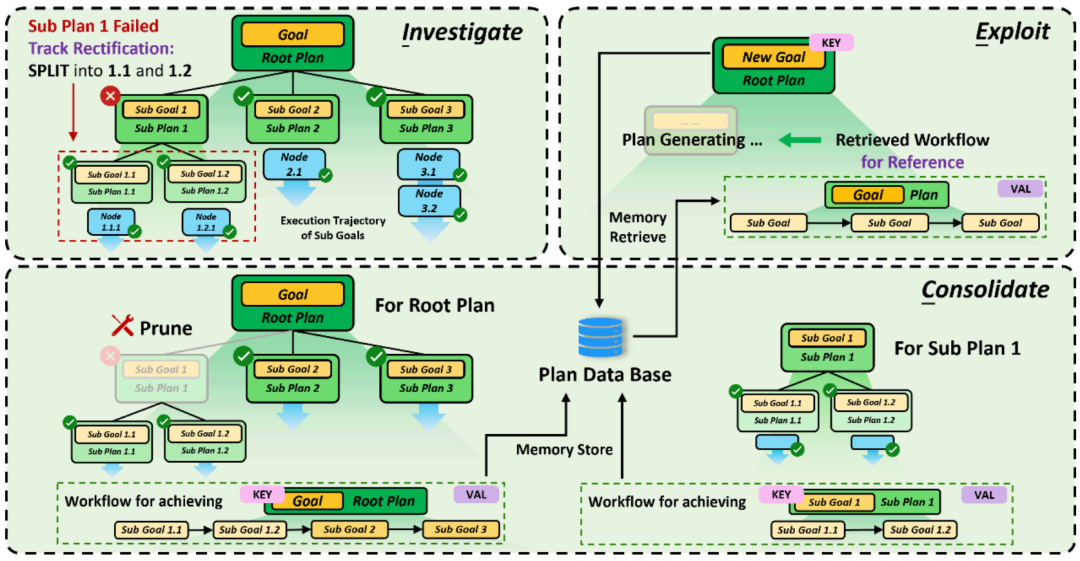 ICE-Selbstentwicklungsstrategie für die Missionsplanung von Agenten
ICE-Selbstentwicklungsstrategie für die Missionsplanung von Agenten
Für die Missionsplanung wird die Selbstentwicklung gemäß ICE in die folgenden drei Phasen unterteilt:
- In der Erkundungsphase zeichnet der Agent die gesamte baumartige Aufgabenplanungsstruktur auf und erkennt gleichzeitig dynamisch den Ausführungsstatus jedes Unterziels.
- In der Verfestigungsphase eliminiert der Agent zunächst alle fehlgeschlagenen Ziele Zielknoten und dann für jedes erfolgreich abgeschlossene Ziel ordnet der Agent alle Blattknoten des Teilbaums mit dem Ziel an, um eine Planungskette (Workflow) zu bilden; Diese Planungsketten werden als Referenzbasis für die Zerlegung und Verfeinerung neuer Missionsziele verwendet, um von den erfolgreichen Erfahrungen der Vergangenheit zu profitieren.
ICE-Selbstentwicklungsstrategie für die Ausführung von Agentenaufgaben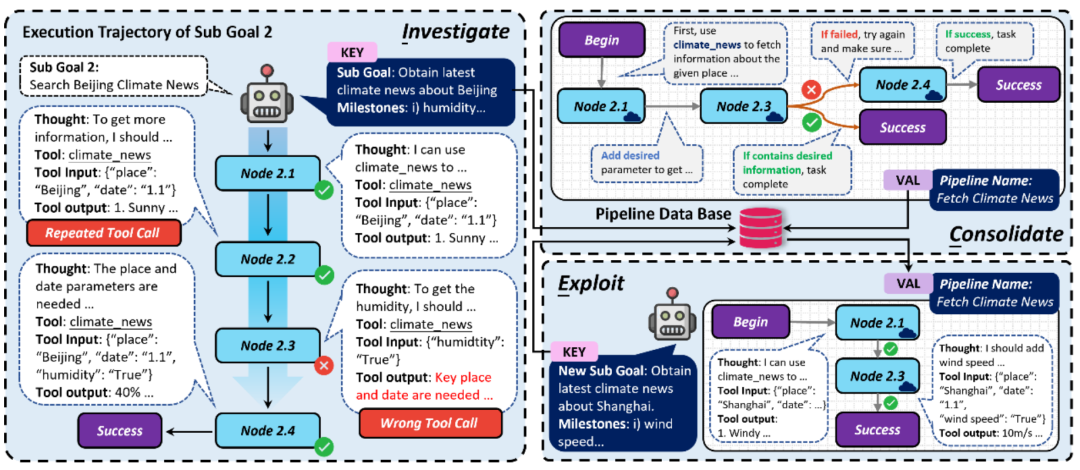
- In der Erkundungsphase die Der Agent zeichnet jede Tool-Aufrufkette dynamisch auf und erkennt und klassifiziert mögliche Probleme, die beim Tool-Aufruf auftreten
- Pipeline-Struktur , die Tool-Aufrufsequenz und die Übertragungsbeziehung zwischen Aufrufen werden festgelegt, wiederholte Aufrufe werden entfernt, Verzweigungslogik hinzugefügt usw., um den automatisierten Ausführungsprozess des Automaten robuster zu machen
- In der Nutzungsphase automatisiert der Agent für ähnliche Ziele direkt die Ausführung der Pipeline und verbessert so die Effizienz der Aufgabenerledigung. Selbstentwicklungsexperiment unter dem XAgent-Framework
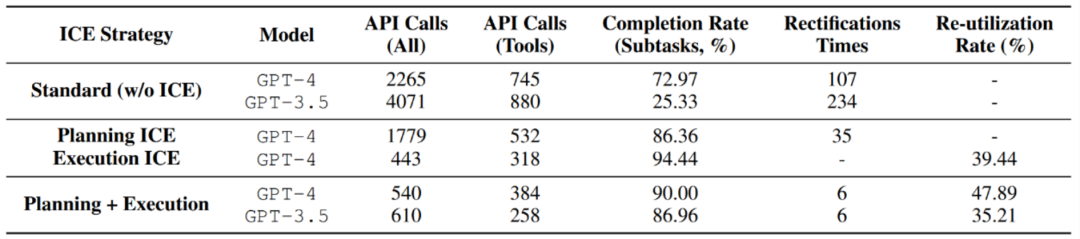
- Der Autor testete die vorgeschlagene ICE-Selbstentwicklungsstrategie in der Anzahl der Modellaufrufe, wodurch die Effizienz verbessert und der Overhead reduziert wurde.
Das gespeicherte Erlebnis weist im Rahmen der ICE-Strategie eine hohe Wiederverwendungsrate auf, was die Wirksamkeit von ICE beweist.
Die ICE-Strategie kann die Abschlussrate von Unteraufgaben verbessern und gleichzeitig die Anzahl geplanter Reparaturen reduzieren.
- Mit der Unterstützung vergangener Erfahrungen konnten die Anforderungen an die Modellfähigkeiten zur Aufgabenausführung deutlich reduziert werden. Insbesondere durch die Verwendung von GPT-3.5 in Kombination mit vorheriger Erfahrung in der Aufgabenplanung und -ausführung kann der Effekt direkt mit GPT-4 vergleichbar sein.
- Nach der Untersuchung und Festigung der Erfahrungsspeicherung wurde die Leistung der Testsatzaufgabe unter verschiedenen Agenten-ICE-Strategien untersucht.
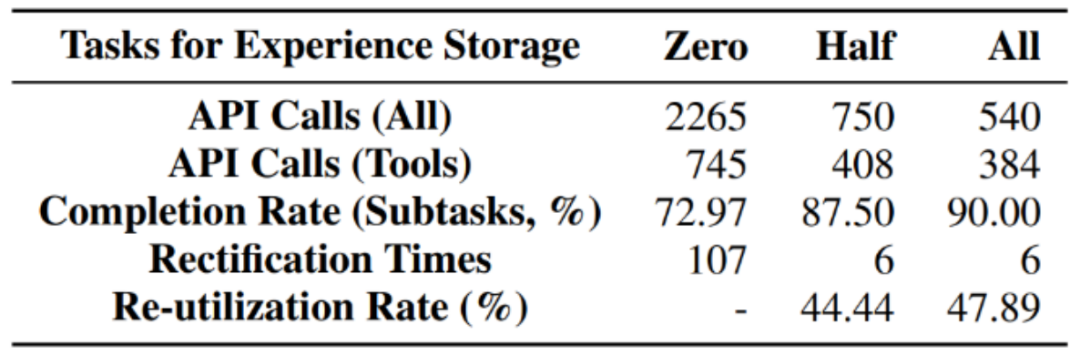
- Gleichzeitig führte der Autor auch zusätzliche Ablationsexperimente durch: Als die Speichererfahrung allmählich zunahm, Wird die Leistung des Agenten immer besser? Die Antwort ist ja. Von null Erfahrung, halber Erfahrung bis hin zu voller Erfahrung nimmt die Anzahl der Aufrufe des Basismodells allmählich ab, während die Erledigung von Teilaufgaben allmählich zunimmt und auch die Wiederverwendungsrate zunimmt. Dies zeigt, dass mehr Erfahrungen aus der Vergangenheit die Agentenausführung besser fördern und Skaleneffekte erzielen können.
 Schlussfolgerung
Schlussfolgerung
Stellen Sie sich vor, dass in einer Welt, in der jeder Agenten einsetzen kann, die Anzahl erfolgreicher Erfahrungen so groß sein wird wie der Einzelne Da sich die Aufgaben des Agenten immer weiter häufen, können Benutzer diese Erfahrungen auch in der Cloud und der Community teilen. Diese Erfahrungen werden den intelligenten Agenten dazu veranlassen, kontinuierlich Fähigkeiten zu erwerben, sich weiterzuentwickeln und nach und nach vollständige Autonomie zu erlangen. Wir sind einer solchen Ära einen Schritt näher gekommen.
Das obige ist der detaillierte Inhalt vonMit der neuen aufgabenübergreifenden Selbstentwicklungsstrategie der Tsinghua-Universität und der HKU kommen wir der völligen Autonomie einen Schritt näher und ermöglichen es Agenten, „aus Erfahrungen zu lernen'.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!