
Heim >Technologie-Peripheriegeräte >KI >Anonyme Zeitungen kommen mit überraschenden Ideen! Dies kann tatsächlich getan werden, um die Langtextfähigkeiten großer Modelle zu verbessern
Anonyme Zeitungen kommen mit überraschenden Ideen! Dies kann tatsächlich getan werden, um die Langtextfähigkeiten großer Modelle zu verbessern

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-02-02 18:21:15672Durchsuche
Wenn es um die Verbesserung der Langtextfunktionen großer Modelle geht, denken Sie an Längenextrapolation oder Kontextfenstererweiterung?
Nein, diese verbrauchen zu viele Hardwareressourcen.
Werfen wir einen Blick auf eine wunderbare neue Lösung:
unterscheidet sich wesentlich vom KV-Cache, der von Methoden wie der Längenextrapolation verwendet wird. Es nutzt die Parameter des Modells, um eine große Menge an Kontextinformationen zu speichern .
Die spezifische Methode besteht darin, ein temporäres Lora-Modul zu erstellen, so dass es während des Langtextgenerierungsprozesses „nur Aktualisierungen streamt“, d. h. es verwendet kontinuierlich zuvor generierte Inhalte als Eingabe und dient als Trainingsdaten Dadurch wird sichergestellt, dass Wissen in Modellparametern gespeichert wird.
DannSobald die Inferenz vollständig ist, werfen Sie sie weg , um sicherzustellen, dass es keine langfristigen Auswirkungen auf die Modellparameter gibt.
Diese Methode ermöglicht es uns, so viele Kontextinformationen zu speichern, wie wir möchten, ohne das Kontextfenster zu erweitern.Speichern Sie so viel, wie Sie möchten. Experimente haben gezeigt, dass diese Methode:
die Qualität von Langtextaufgaben des Modells erheblich verbessern kann, indem eine Reduzierung der Ratlosigkeit um 29,6 % und eine Verbesserung der Übersetzungsqualität von Langtexten um 53,2 % erreicht wird
- (BLAUER Wert)
- ; kann auch mit den meisten vorhandenen Methoden zur Langtextgenerierung kompatibel sein und diese verbessern. Das Wichtigste ist, dass dadurch die Rechenkosten erheblich gesenkt werden können.
- Bei gleichzeitiger Gewährleistung einer leichten Verbesserung der Generierungsqualität (Verwirrung um 3,8 % reduziert) werden die für die Inferenz erforderlichen FLOPs um 70,5 % und die Verzögerung um 51,5 % reduziert!
Lassen Sie uns für die konkrete Situation das Papier öffnen und einen Blick darauf werfen. Erstellen Sie ein temporäres Lora-Modul und werfen Sie es nach der Verwendung weg. Die Methode heißt
Temp-Lora. Das Architekturdiagramm lautet wie folgt:
Der Kern besteht darin, den zuvor generierten Text schrittweise zu verwenden autoregressiv trainieren Temporäres Lora-Modul. Dieses Modul ist sehr anpassungsfähig und kann kontinuierlich angepasst werden, sodass ein tiefes Verständnis für Kontexte unterschiedlicher Entfernung möglich ist.
Der spezifische Algorithmus ist wie folgt: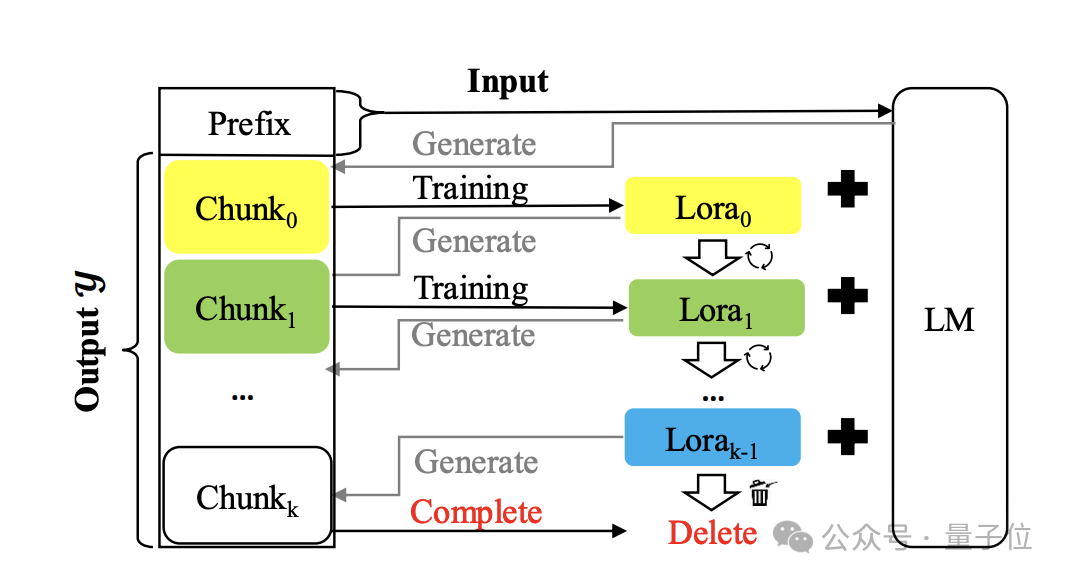 Während des Generierungsprozesses werden Token Block für Block generiert. Jedes Mal, wenn ein Block generiert wird, wird der neueste L
Während des Generierungsprozesses werden Token Block für Block generiert. Jedes Mal, wenn ein Block generiert wird, wird der neueste L
Token als Eingabe X verwendet, um nachfolgende Token zu generieren.
Sobald die Anzahl der generierten Token die vordefinierte Blockgröße Δ erreicht, starten Sie das Training des Temp-Lora-Moduls mit dem neuesten Block und starten Sie dann die nächste Blockgenerierung.
Im Experiment setzt der Autor Δ+Lx
auf W, um die Kontextfenstergröße des Modells voll auszunutzen. Für das Training des Temp-Lora-Moduls stellt das Erlernen der bedingungslosen Generierung neuer Blöcke möglicherweise kein wirksames Trainingsziel dar und führt zu einer ernsthaften Überanpassung. Um dieses Problem zu lösen, integrieren die Autoren L
Um dieses Problem zu lösen, integrieren die Autoren L
-Tags vor jedem Block in den Trainingsprozess und verwenden sie als Eingabe und den Block als Ausgabe. Schließlich schlägt der Autor auch eine Strategie namens
Cache-Wiederverwendung (Cache-Wiederverwendung)vor, um effizientere Schlussfolgerungen zu erzielen. Im Allgemeinen müssen wir nach der Aktualisierung des Temp-Loramo-Moduls im Standard-Framework den KV-Status mit den aktualisierten Parametern neu berechnen.
Alternativ können Sie den vorhandenen zwischengespeicherten KV-Status wiederverwenden und gleichzeitig das aktualisierte Modell für die nachfolgende Textgenerierung verwenden. Konkret verwenden wir das neueste Temp-Lora-Modul, um den KV-Zustand nur dann neu zu berechnen, wenn das Modell eine maximale Länge (Kontextfenstergröße W) generiert.
Eine solche Cache-Wiederverwendungsmethode kann die Generierung beschleunigen, ohne die Generierungsqualität wesentlich zu beeinträchtigen.
Das ist die Einführung in die Temp-Lora-Methode. Schauen wir uns hauptsächlich den folgenden Test an.
Je länger der Text, desto besser der EffektDer Autor bewertete das Temp-Lora-Framework für die Modelle Llama2-7B-4K, Llama2-13B-4K, Llama2-7B-32K und Yi-Chat-6B und behandelte diese beiden Arten von Langtextaufgaben sind Generierung und Übersetzung.
Der Testdatensatz ist eine Teilmenge des Langtext-Sprachmodellierungs-Benchmarks PG19, aus dem 40 Bücher zufällig ausgewählt wurden.
Bei der anderen handelt es sich um eine zufällig ausgewählte Teilmenge des Guofeng-Datensatzes von WMT 2023, der 20 chinesische Online-Romane enthält, die von Fachleuten ins Englische übersetzt wurden.
Schauen wir uns zunächst die Ergebnisse von PG19 an.
Die folgende Tabelle zeigt den PPL
(Ratlosigkeit, spiegelt die Unsicherheit des Modells für eine bestimmte Eingabe wider, je niedriger, desto besser)Vergleich verschiedener Modelle auf PG19 mit und ohne Temp-Lora-Modul. Teilen Sie jedes Dokument in Segmente von 0-100.000 bis 500.000+Tokens auf. Es ist ersichtlich, dass die PPL aller Modelle nach Temp-Lora deutlich gesunken ist, und je länger die Clips werden, desto offensichtlicher ist der Einfluss von Temp-Lora (1-100K sank nur um 3,6 %, 500K+ sank um 13,2%) .
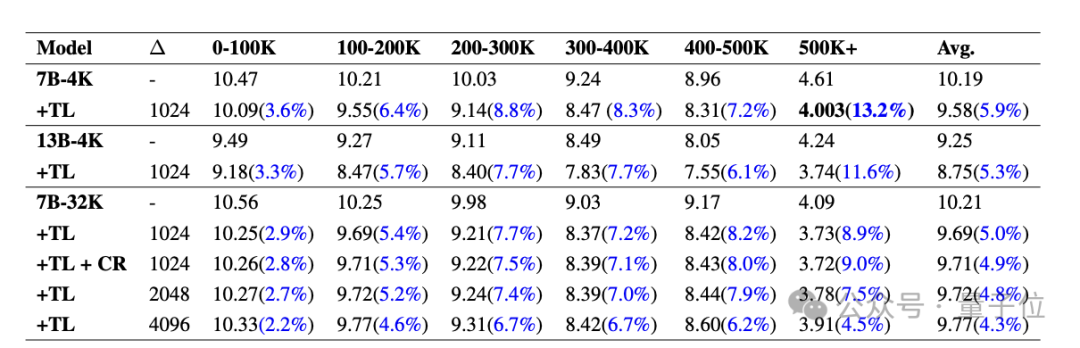
Daher können wir einfach schlussfolgern: Je mehr Text vorhanden ist, desto stärker ist die Notwendigkeit, Temp-Lora zu verwenden.
Darüber hinaus können wir feststellen, dass die Anpassung der Blockgröße von 1024 auf 2048 und 4096 zu einem leichten Anstieg des PPL führt.
Das ist nicht verwunderlich, schließlich wird das Temp-Lora-Modul auf den Daten des vorherigen Blocks trainiert.
Diese Daten zeigen uns hauptsächlich, dass die Wahl der Blockgröße ein wichtiger Kompromiss zwischen Erzeugungsqualität und Recheneffizienz ist (weitere Analysen finden Sie im Artikel) .
Schließlich können wir auch feststellen, dass die Wiederverwendung des Caches keinen Leistungsverlust verursacht. Der Autor sagte: Das sind sehr ermutigende Neuigkeiten.Das Folgende sind die Ergebnisse des Guofeng-Datensatzes.
Es ist ersichtlich, dass Temp-Lora auch einen erheblichen Einfluss auf literarische Langtextübersetzungsaufgaben hat. Signifikante Verbesserungen bei allen Metriken im Vergleich zum Basismodell: -29,6 % Reduzierung des PPL, +53,2 % Verbesserung des BLEU-Scores(Ähnlichkeit von maschinell übersetztem Text mit hochwertigen Referenzübersetzungen), +53,2 % Verbesserung des COMET-Scores (Auch ein Qualitätsindikator) um +8,4 % verbessert.
 Abschließend geht es um die Erforschung der Recheneffizienz und -qualität.
Abschließend geht es um die Erforschung der Recheneffizienz und -qualität.
Der Autor hat durch Experimente herausgefunden, dass die Verwendung der
„wirtschaftlichsten“ Temp-Lora-Konfiguration (Δ=2K, W=4K) den PPL um 3,8 % reduzieren und gleichzeitig 70,5 % der FLOPs und 51,5 % Verzögerung einsparen kann. Im Gegenteil, wenn wir den Rechenaufwand völlig ignorieren und
die „luxuriöseste“ Konfiguration (Δ=1K und W=24K) verwenden, können wir auch eine PPL-Reduzierung von 5,0 % und weitere 17 erreichen % FLOP-Anstieg und 19,6 % Latenz. Verwendungsvorschläge
Um die obigen Ergebnisse zusammenzufassen, gibt der Autor außerdem drei Vorschläge für die praktische Anwendung von Temp-Lora:
1 Für Anwendungen, die ein Höchstmaß an Langtextgenerierung erfordern, integrieren Sie Temp, ohne Parameter zu ändern. -Lora kann zu bestehenden Modellen hinzugefügt werden, um die Leistung bei relativ geringen Kosten deutlich zu verbessern.
2. Für Anwendungen, die Wert auf minimale Latenz oder Speichernutzung legen, können die Rechenkosten erheblich reduziert werden, indem die Eingabelänge und die in Temp-Lora gespeicherten Kontextinformationen reduziert werden.
In dieser Einstellung können wir eine feste kurze Fenstergröße
(z. B. 2 KB oder 4 KB)verwenden, um nahezu unendlich langen Text (500 KB+ in den Experimenten des Autors) zu verarbeiten. 3. Bitte beachten Sie abschließend, dass Temp-Lora in Szenarien, die keine große Textmenge enthalten, beispielsweise wenn der Kontext im Vortraining kleiner ist als die Fenstergröße des Modells, nutzlos ist.
Der Autor stammt von einer vertraulichen Organisation
Es ist erwähnenswert, dass der Autor für die Erfindung einer so einfachen und innovativen Methode nicht viele Quelleninformationen hinterlassen hat:
Der Name der Organisation ist direkt mit „Sekretärorganisation“ signiert. und die Namen der drei Autoren sind nur vollständige Nachnamen.
 Den E-Mail-Informationen zufolge könnte es sich jedoch um Schulen wie die City University of Hong Kong und die Hong Kong Chinese Language School handeln.
Den E-Mail-Informationen zufolge könnte es sich jedoch um Schulen wie die City University of Hong Kong und die Hong Kong Chinese Language School handeln.
Was halten Sie abschließend von dieser Methode?
Papier:Das obige ist der detaillierte Inhalt vonAnonyme Zeitungen kommen mit überraschenden Ideen! Dies kann tatsächlich getan werden, um die Langtextfähigkeiten großer Modelle zu verbessern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Welche Datenmodelle werden am häufigsten verwendet?
- Welche drei Arten von Datenbankdatenmodellen gibt es?
- Was sind die vier gängigen Softwareentwicklungsmodelle?
- Eine weitere Revolution im Reinforcement Learning! DeepMind schlägt eine „Algorithmus-Destillation' vor: einen erforschbaren, vorab trainierten Reinforcement-Learning-Transformer
- Yunshenchen und Shengteng CANN arbeiten zusammen, um ein ROS-Trainingslager für die Entwicklung vierbeiniger Roboterhunde zu eröffnen