
Heim >Technologie-Peripheriegeräte >KI >NextEvo der Ant Group stellt seine KI-Infra-Technologie vollständig als Open-Source-Lösung zur Verfügung, um „autonomes Fahren' im Training großer Modelle zu ermöglichen
NextEvo der Ant Group stellt seine KI-Infra-Technologie vollständig als Open-Source-Lösung zur Verfügung, um „autonomes Fahren' im Training großer Modelle zu ermöglichen

- 王林nach vorne
- 2024-02-02 08:39:021168Durchsuche
Kürzlich hat NextEvo, die Forschungs- und Entwicklungsabteilung für KI-Innovationen der Ant Group, die umfassende Open-Source-KI-Infra-Technologie angekündigt, die die Effizienz des groß angelegten Modelltrainings erheblich verbessern kann. Den Daten zufolge kann diese Technologie den effektiven Anteil der Trainingszeit auf über 95 % steigern und die Automatisierung des Trainingsprozesses realisieren. Dieser bahnbrechende Fortschritt hat die Effizienz der KI-Forschung und -Entwicklung erheblich gesteigert.
Bild: Das automatisierte verteilte Deep-Learning-System DLRover der Ant Group ist jetzt vollständig Open Source
DLRover ist ein technisches Framework, das für groß angelegte verteilte Schulungen entwickelt wurde. Heutzutage werden in vielen Unternehmen Schulungsaufgaben häufig in komplexen und vielfältigen hybriden Bereitstellungsclustern ausgeführt. Egal wie komplex die Umgebung ist, DLRover kommt damit problemlos zurecht, genau wie das Fahren in unwegsamem Gelände.
Die rasante Entwicklung der Großmodelltechnik im Jahr 2023 hat zu einem explosionsartigen Wachstum der Ingenieurspraxis geführt. Wie man Daten effizient verwaltet, die Trainings- und Inferenzeffizienz optimiert und die vorhandene Rechenleistung voll ausnutzt, ist zu einer zentralen Frage geworden.
Um ein großes Modell mit einem Parameterniveau von 100 Milliarden wie GPT-3 fertigzustellen, würde es 32 Jahre dauern, einmal mit einer Karte zu trainieren. Daher ist es sehr wichtig, die Rechenleistung während des Trainingsprozesses voll auszunutzen. Um dieses Ziel zu erreichen, können zwei Ansätze verfolgt werden. Erstens kann die Leistung einer gekauften GPU weiter verbessert werden, um ihr volles Potenzial auszuschöpfen. Zweitens können bisher nicht verfügbare Rechenressourcen wie CPU und Speicher genutzt werden. Um dies zu erreichen, kann dieses Problem durch heterogene Computerplattformen gelöst werden.
DLRover hat kürzlich die Flash Checkpoint (FCP)-Lösung für das Checkpoint-Management während des Modelltrainings integriert. Bei der herkömmlichen Checkpoint-Verwaltungsmethode gibt es Probleme wie einen langen Zeitaufwand, Checkpoints mit hoher Frequenz, die die verfügbare Trainingszeit verkürzen, und übermäßige Verluste bei der Wiederherstellung von Checkpoints mit niedriger Frequenz. Durch die Anwendung der neuen Lösung FCP wird nach dem Training des 100-Milliarden-Parameter-Modells die durch Checkpoint verursachte verschwendete Trainingszeit um etwa das Fünffache und die Persistenzzeit um etwa das 70-fache reduziert. Diese Verbesserung erhöht die effektive Trainingszeit von 90 % auf 95 %. Dies bedeutet, dass die Effizienz des Modelltrainings von DLRover erheblich verbessert wurde.
Wir haben außerdem drei neue Optimierungstechnologien integriert. Der Optimierer ist eine Kernkomponente des maschinellen Lernens und wird zur Aktualisierung neuronaler Netzwerkparameter verwendet, um die Verlustfunktion zu minimieren. Unter anderem ist der AGD-Optimierer (Auto-Switchable Optimizer with Gradient Difference of Adjacent Steps) von Ant bei Vortrainingsaufgaben für große Modelle 1,5-mal schneller als die herkömmliche AdamW-Technologie. AGD wurde in mehreren Szenarien bei Ameisen eingesetzt und erzielte bemerkenswerte Ergebnisse, und verwandte Artikel wurden in NeurIPS '23 aufgenommen.
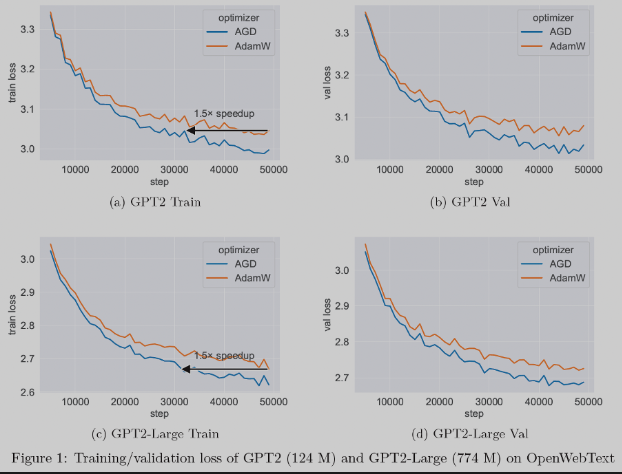
Bild: Bei großen Modell-Pre-Training-Aufgaben kann AGD im Vergleich zu AdamW um das 1,5-fache beschleunigen
Als automatisiertes verteiltes Deep-Learning-System umfasst das Funktionsmodul „Autonomes Fahren“ von DLRover auch: Atorch, ein The PyTorch Die verteilte Trainingserweiterungsbibliothek kann eine Rechenleistungsauslastung von 60 % für das Training auf Kilokalorienebene von Hunderten von Milliarden Parametermodellen erreichen und hilft Entwicklern so, die Hardware-Rechenleistung weiter zu reduzieren.
DLRover nutzt das Konzept von „ML for System“, um die Intelligenz des verteilten Trainings zu verbessern. Ziel ist es, ein System zu verwenden, das es Entwicklern ermöglicht, die Einschränkungen der Ressourcenzuweisung vollständig zu beseitigen und sich auf das Modelltraining selbst zu konzentrieren. Ohne Eingaben zur Ressourcenkonfiguration kann DLRover dennoch eine optimale Ressourcenkonfiguration für jeden Trainingsauftrag bereitstellen.
Es versteht sich, dass die Ant Group weiterhin in Technologie im Bereich der künstlichen Intelligenz investiert. Vor Kurzem hat die Ant Group eine interne Forschungs- und Entwicklungsabteilung für KI-Innovation NextEvo eingerichtet, die für die gesamte Kerntechnologieforschung und -entwicklung von Ant AI verantwortlich ist Alle Forschungs- und Entwicklungsarbeiten des Bailing-Großmodells, einschließlich Kerntechnologien wie KI-Algorithmen, KI-Engineering, NLP und AIGC, sowie Technologieforschung und -entwicklung und Produktinnovation in Bereichen wie dem Layout multimodaler Großmodelle und digital Menschen.
Gleichzeitig hat die Ant Group auch das Tempo von Open Source beschleunigt, die relevanten inländischen Technologielücken geschlossen und die rasante Entwicklung der Branche der künstlichen Intelligenz gefördert.
DLRover Open-Source-Adresse: https://www.php.cn/link/cf372cbe6eae54c6a6dfb3ebbcdc3404
Das obige ist der detaillierte Inhalt vonNextEvo der Ant Group stellt seine KI-Infra-Technologie vollständig als Open-Source-Lösung zur Verfügung, um „autonomes Fahren' im Training großer Modelle zu ermöglichen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Die University of Wisconsin-Madison und andere haben gemeinsam einen Artikel veröffentlicht! Das neueste multimodale große Modell LLaVA wird veröffentlicht und sein Niveau liegt nahe an GPT-4
- Entdeckung der drei wichtigsten Python-Modelle und der zehn häufigsten Algorithmusbeispiele
- Lassen Sie uns gemeinsam das digitale Guangxi aufbauen und gemeinsam in eine digitale Zukunft gehen! Die ökologische Konferenz der Industrie für künstliche Intelligenz in Guangxi Kunpeng Shengteng 2023 wurde erfolgreich abgehalten
- Standards prägen ein besseres Leben. In Suzhou fand eine Konferenz zur Förderung der Standardisierung der Roboter- und CNC-Werkzeugmaschinenindustrie statt
- Robin Li: Das rekonstruierte Werbesystem von Wenxin Big Model wird Baidu im vierten Quartal zusätzliche Einnahmen in Höhe von Hunderten Millionen Yuan bescheren