
Heim >Technologie-Peripheriegeräte >KI >Das reine Textmodell trainiert die „visuelle' Darstellung! Neueste Forschungsergebnisse des MIT: Sprachmodelle können mithilfe von Code Bilder zeichnen
Das reine Textmodell trainiert die „visuelle' Darstellung! Neueste Forschungsergebnisse des MIT: Sprachmodelle können mithilfe von Code Bilder zeichnen

- 王林nach vorne
- 2024-02-01 21:12:121137Durchsuche
Verfügt ein großes Sprachmodell, das nur „lesen“ kann, über eine reale visuelle Wahrnehmung? Was genau kann ein Sprachmodell durch die Modellierung der Beziehungen zwischen Zeichenfolgen über die visuelle Welt lernen?
Kürzlich haben Forscher am MIT Computer Science and Artificial Intelligence Laboratory (MIT CSAIL) Sprachmodelle evaluiert und sich dabei auf ihre visuellen Fähigkeiten konzentriert. Sie testeten die Fähigkeit des Modells, indem sie es aufforderten, immer komplexere visuelle Konzepte zu generieren und zu erkennen, von einfachen Formen und Objekten bis hin zu komplexen Szenen. Die Forscher zeigten auch, wie man ein vorläufiges Lernsystem für die visuelle Darstellung mithilfe eines Nur-Text-Modells trainiert. Mit dieser Forschung legten sie den Grundstein für die Weiterentwicklung und Verbesserung von Lernsystemen für die visuelle Darstellung.

Link zum Papier: https://arxiv.org/abs/2401.01862
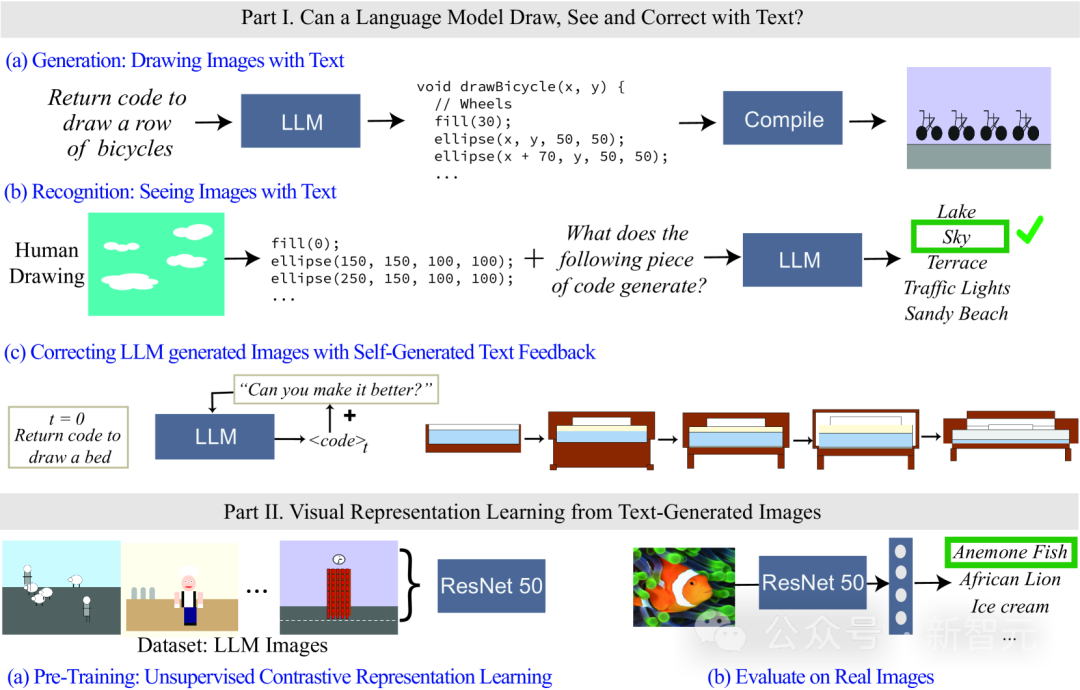
Da das Sprachmodell keine visuellen Informationen verarbeiten kann, wird in der Studie Code zum Rendern von Bildern verwendet.
Obwohl die von LLM generierten Bilder möglicherweise nicht so realistisch sind wie natürliche Bilder, ist es anhand der Generierungsergebnisse und der Selbstkorrektur des Modells in der Lage, Zeichenfolgen/Texte genau zu modellieren, was es dem Sprachmodell ermöglicht, etwas darüber zu lernen die visuelle Welt vieler Konzepte.
Forscher untersuchten auch Methoden für das selbstüberwachte Lernen visueller Darstellungen mithilfe von Bildern, die von Textmodellen generiert wurden. Die Ergebnisse zeigen, dass diese Methode das Potenzial hat, Sehmodelle zu trainieren und eine semantische Bewertung natürlicher Bilder nur unter Verwendung von LLM durchzuführen.
Visuelles Konzept des Sprachmodells
Stellen Sie zunächst eine Frage: Was bedeutet es für Menschen, das visuelle Konzept von „Frosch“ zu verstehen?
Reicht es aus, die Farbe seiner Haut zu kennen, wie viele Beine es hat, die Position seiner Augen, wie es aussieht, wenn es springt usw.?
Menschen denken oft, dass man, um das Konzept der Frösche zu verstehen, Bilder von Fröschen betrachten und sie aus verschiedenen Blickwinkeln und in realen Szenarien betrachten muss.
Inwieweit können wir die visuelle Bedeutung verschiedener Konzepte verstehen, wenn wir nur den Text beobachten?
Aus Sicht des Modelltrainings besteht der Trainingsinput des Large Language Model (LLM) nur aus Textdaten, aber das Modell versteht nachweislich Informationen über Konzepte wie Form und Farbe und kann sie sogar in eine visuelle Darstellung umwandeln durch lineare Transformation in der Darstellung des Modells.
Mit anderen Worten, visuelle Modelle und Sprachmodelle sind sich hinsichtlich der Weltdarstellung sehr ähnlich.
Die meisten vorhandenen Methoden zur Modellcharakterisierung basieren jedoch auf einer Reihe vorab ausgewählter Attribute, um zu untersuchen, welche Informationen das Modell codiert. Diese Methode kann Attribute nicht dynamisch erweitern und erfordert außerdem Zugriff auf die internen Parameter des Modells .
Die Forscher stellten also zwei Fragen:
1 Wie viel weiß das Sprachmodell über die visuelle Welt?
2. Ist es möglich, ein visuelles System zu trainieren, das für natürliche Bilder „nur unter Verwendung von Textmodellen“ verwendet werden kann?
Um herauszufinden, welche Informationen im Modell enthalten waren, testeten sie verschiedene Sprachmodelle beim Rendern (Zeichnen) und Erkennen (Sehen) realer visueller Konzepte. Die Fähigkeit, beliebige Attribute zu erfassen, ohne Merkmalsklassifikatoren trainieren zu müssen einzeln für jedes Attribut.
Obwohl Sprachmodelle keine Bilder generieren können, können große Modelle wie GPT-4 Codes zum Rendern von Objekten generieren. In diesem Artikel wird der Prozess der Textaufforderung -> Code -> Bild verwendet, um die Schwierigkeit des Renderns von Objekten zum Messen des Modells schrittweise zu erhöhen Fähigkeiten.
Forscher fanden heraus, dass LLM überraschend gut darin ist, komplexe visuelle Szenen aus mehreren Objekten zu erzeugen und räumliche Beziehungen effizient zu modellieren, aber die visuelle Welt, einschließlich der Eigenschaften von Objekten, wie Texturen, präzise Form usw., nicht gut erfassen kann Oberflächenkontakt mit anderen Objekten im Bild.
Der Artikel bewertet auch die Fähigkeit von LLM, Wahrnehmungskonzepte zu identifizieren, gibt Gemälde ein, die durch Codes dargestellt werden, und die Codes umfassen die Reihenfolge, Position und Farbe von Formen, und fordert dann das Sprachmodell auf, den in beschriebenen visuellen Inhalt zu beantworten die Codes.

Die experimentellen Ergebnisse ergaben, dass LLM genau das Gegenteil von Menschen ist: Für Menschen ist der Prozess des Codeschreibens schwierig, aber es ist einfach, den Inhalt von Bildern zu überprüfen; Den Inhalt des Codes interpretieren/erkennen, aber es können komplexe Szenen generiert werden.
Darüber hinaus belegen die Forschungsergebnisse auch, dass die visuelle Generierungsfähigkeit von Sprachmodellen durch textbasierte Korrekturen weiter verbessert werden kann.
Die Forscher verwenden zunächst ein Sprachmodell, um Code zu generieren, der das Konzept veranschaulicht, und geben dann kontinuierlich die Aufforderung „Verbessern Sie den generierten Code“ (den generierten Code verbessern) als Bedingung ein, um das endgültige Modell zu ändern Durch diesen iterativen Ansatz verbessert sich die optische Wirkung.

Sehfähigkeitsdatensätze: Auf Szenen zeigen
Die Forscher erstellten drei Textbeschreibungsdatensätze, um die Fähigkeit des Modells zu messen, Bildwiedergabecode zu erstellen, zu erkennen und zu ändern, wobei die Komplexität von einfachen Formen und Kombinationen reicht , Objekte und komplexe Szenen.

1. Formen und ihre Zusammensetzungen
enthält Formzusammensetzungen aus verschiedenen Kategorien, wie Punkte, Linien, 2D-Formen und 3D-Formen, mit 32 Typen. Textur, Position und räumliche Anordnung.
Der vollständige Datensatz enthält mehr als 400.000 Beispiele, von denen 1500 Proben für experimentelle Tests verwendet werden.
2. Objekte
Enthält die 1000 häufigsten Objekte im ADE 20K-Datensatz, der schwieriger zu generieren und zu erkennen ist, da er komplexere Kombinationen von Formen enthält.
3. Szenen
bestehen aus komplexen Szenenbeschreibungen, einschließlich mehrerer Objekte und verschiedener Orte, und werden durch zufällige und gleichmäßige Stichproben von 1000 Szenenbeschreibungen aus dem MS-COCO-Datensatz erhalten.
Die visuellen Konzepte im Datensatz werden in Sprache beschrieben. Die Szene wird beispielsweise als „ein sonniger Sommertag an einem Strand, mit blauem Himmel und ruhigem Meer“ beschrieben. .
Während des Testprozesses wurde LLM gebeten, Code zu generieren und gerenderte Bilder basierend auf der dargestellten Szene zu kompilieren.
Experimentelle Ergebnisse
Die Aufgaben zur Bewertung des Modells bestehen hauptsächlich aus drei:
1. Text generieren/zeichnen: Bewerten Sie die Fähigkeit von LLM, Bildwiedergabecode zu generieren, der einem bestimmten Konzept entspricht.
2. Text erkennen/anzeigen: Testen Sie die Leistung von LLM beim Erkennen visueller Konzepte und Szenen, die im Code dargestellt werden. Wir testen Codedarstellungen menschlicher Zeichnungen an jedem Modell.
3. Korrektur von Zeichnungen mithilfe von Textfeedback: Bewerten Sie die Fähigkeit von LLM, seinen generierten Code mithilfe des von ihm generierten Feedbacks in natürlicher Sprache iterativ zu ändern.
Die Eingabeaufforderung für das Modell im Test lautet: Schreiben Sie Code in der Programmiersprache [Name der Programmiersprache], der ein [Konzept] zeichnet.
Dann kompilieren und rendern Sie ihn entsprechend dem Ausgabecode des Modells und visuell Qualität und Vielfalt des Bildes werden bewertet:
1. Wiedergabetreue
Berechnen Sie die Wiedergabetreue zwischen dem generierten Bild und der tatsächlichen Beschreibung, indem Sie die beste Beschreibung des Bildes abrufen. Der CLIP-Score wird zunächst verwendet, um die Übereinstimmung zwischen jedem Bild und allen potenziellen Beschreibungen in derselben Kategorie (Form/Objekt/Szene) zu berechnen, und dann wird die Rangfolge der wahren Beschreibungen als Prozentsatz angegeben (z. B. bedeutet ein Score von 100 %). dass das wahre Konzept an erster Stelle steht).
2. Diversität
Um die Fähigkeit des Modells zu bewerten, unterschiedliche Inhalte darzustellen, werden LPIPS-Diversity-Scores für Bildpaare verwendet, die dasselbe visuelle Konzept darstellen.
3. Realismus
Für eine Stichprobensammlung von 1K-Bildern von ImageNet verwenden Sie die Fréchet Inception Distance (FID), um den Verteilungsunterschied zwischen natürlichen Bildern und LLM-generierten Bildern zu quantifizieren.
Im Vergleichsexperiment wurde das durch Stable Diffusion erhaltene Modell als Basislinie verwendet.
Was kann LLM visualisieren?
Forschungsergebnisse ergaben, dass LLM reale Konzepte aus der gesamten visuellen Hierarchie visualisieren, zwei nicht zusammenhängende Konzepte (z. B. einen Kuchen in Form eines Autos) kombinieren, visuelle Phänomene (z. B. unscharfe Bilder) erzeugen und es schaffen kann, den Raum richtig zu interpretieren Beziehungen (z. B. „eine Reihe horizontal angeordneter Fahrräder“).
Wie aus den CLIP-Score-Ergebnissen hervorgeht, siehe, die Die Fähigkeiten des Modells nehmen ab, wenn die konzeptionelle Komplexität von Formen zu Szenen zunimmt.
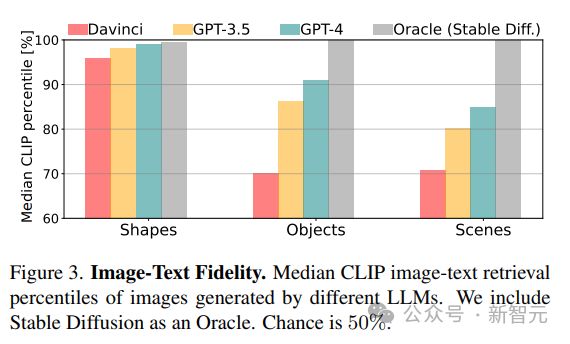
Für komplexere visuelle Konzepte, wie das Zeichnen von Szenen mit mehreren Objekten, sind GPT-3.5 und GPT-4 besser als Python-Matplotlib und Python-Turtle, wenn Szenen mit komplexen Beschreibungen mithilfe von Processing und Tikz präziser gezeichnet werden .
Für Objekte und Szenen zeigt der CLIP-Score, dass Konzepte wie „Menschen“, „Fahrzeuge“ und „Außenszenen“ am einfachsten zu zeichnen sind. Diese Fähigkeit, komplexe Szenen zu rendern, ergibt sich aus der Ausdruckskraft des Rendering-Codes Modell ist in jedem Programmierfähigkeiten innerhalb des Szenarios und der Qualität der internen Darstellung der verschiedenen beteiligten Konzepte.
Was kann LLM nicht visualisieren?
In einigen Fällen ist es schwierig, das Modell selbst für relativ einfache Konzepte zu zeichnen, und die Forscher haben drei häufige Fehlermodi zusammengefasst:
1 Das Sprachmodell kann eine Reihe von Formen und bestimmte Konzepte nicht verarbeiten Raumorganisation;
2. Grobe Zeichnung und fehlende Details, vor allem bei Verwendung von Matplotlib und Turtle-Codierung;
3 Die Beschreibung ist unvollständig, beschädigt oder stellt nur eine Teilmenge dar Konzept (eine typische Kategorie von Szenarien).
4. Alle Modelle können keine Figuren zeichnen.
Vielfalt und Realismus
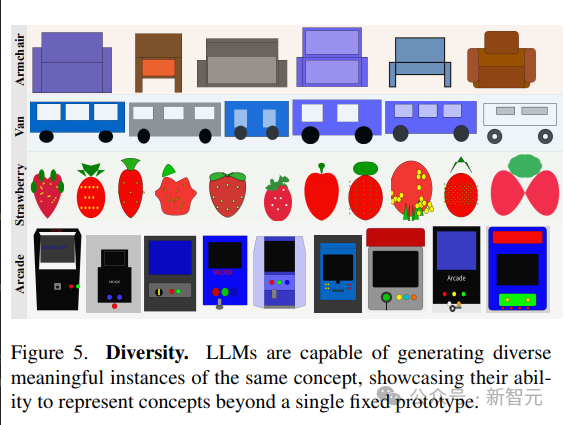
Sprachmodelle demonstrieren die Fähigkeit, verschiedene Visualisierungen desselben Konzepts zu generieren.
Um verschiedene Samples derselben Szene zu generieren, werden in dem Artikel zwei Strategien verglichen:
1. Wiederholtes Sampling aus dem Modell;
2 eine neue Handlung des Konzepts.

Die Fähigkeit des Modells, vielfältige Umsetzungen visueller Konzepte darzustellen, spiegelt sich in der hohen LPIPS-Diversitätsbewertung wider; die Fähigkeit, vielfältige Bilder zu erzeugen, zeigt, dass LLM in der Lage ist, visuelle Konzepte auf vielfältige Weise darzustellen, ohne auf eine beschränkt zu sein limitiertes Set Prototyp.
Die von LLM erzeugten Bilder sind weitaus weniger realistisch als natürliche Bilder, und das Modell schneidet bei der FID-Metrik im Vergleich zu Stable Diffusion sehr schlecht ab, aber moderne Modelle schneiden besser ab als ältere Modelle.
Lernen visueller Systeme aus Text
Training und Bewertung
Die Forscher nutzten das vorab trainierte visuelle Modell, das durch unbeaufsichtigtes Lernen erhalten wurde, als Rückgrat des Netzwerks und generierten mithilfe der MoCo-v2-Methode 1,3 Millionen 384× in LLM Das ResNet-50-Modell wird auf dem 384-Bilddatensatz für insgesamt 200 Epochen trainiert. Nach dem Training werden zwei Methoden verwendet, um die Leistung des auf jedem Datensatz trainierten Modells zu bewerten:
1 ImageNet-1 k-Klassifizierung Trainieren Sie die lineare Schicht auf dem Backbone für 100 Epochen,
2 Verwenden Sie den 5-nächsten Nachbarn (kNN)-Abruf auf ImageNet-100.

Wie aus den Ergebnissen hervorgeht, kann das Modell, das nur mit den von LLM generierten Daten trainiert wurde, leistungsstarke Darstellungsmöglichkeiten für natürliche Bilder bereitstellen, ohne dass lineare Ebenen trainiert werden müssen.
Ergebnisanalyse
Die Forscher verglichen die von LLM generierten Bilder mit denen, die von bestehenden Programmen generiert wurden, darunter einfache generative Programme wie Dead-Levaves, Fraktale und StyleGAN, um sehr unterschiedliche Bilder zu erzeugen.
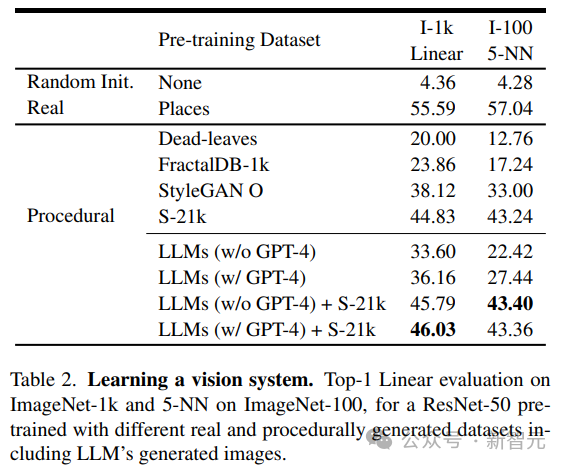
Aus den Ergebnissen geht hervor, dass die LLM-Methode besser ist als Dead-Levaves und Fraktale, aber nicht Sota; nach manueller Prüfung der Daten führten die Forscher diese Minderwertigkeit auf einen Mangel an Textur in den meisten LLM-generierten Bildern zurück .
Um dieses Problem anzugehen, kombinierten die Forscher den Shaders-21k-Datensatz mit von LLM erhaltenen Proben, um texturreiche Bilder zu erzeugen.
Wie aus den Ergebnissen hervorgeht, kann diese Lösung die Leistung erheblich verbessern und andere programmgenerierte Lösungen übertreffen.
Das obige ist der detaillierte Inhalt vonDas reine Textmodell trainiert die „visuelle' Darstellung! Neueste Forschungsergebnisse des MIT: Sprachmodelle können mithilfe von Code Bilder zeichnen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Funktionen des TCP/IP-Vierschichtmodells
- Welches Farbmodell wird von Computermonitoren verwendet?
- Sie können das vorab trainierte Modell für die chinesische Sprache nicht finden? Die chinesische Version Wav2vec 2.0 und HuBERT kommen
- So lösen Sie die Einschränkungen beim Training großer Modelle mit gemischter Präzision
- Maßgeschneidertes Training von Deep-Learning-Modellen mithilfe von Transfer-Learning-Techniken