
Heim >Technologie-Peripheriegeräte >KI >So lösen Sie die Einschränkungen beim Training großer Modelle mit gemischter Präzision
So lösen Sie die Einschränkungen beim Training großer Modelle mit gemischter Präzision

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-13 20:28:012573Durchsuche
Gemischte Präzision ist für das Training großer Deep-Learning-Modelle zu einer Notwendigkeit geworden, bringt aber auch viele Herausforderungen mit sich. Das Konvertieren von Modellparametern und -verläufen in Datentypen mit geringerer Präzision (z. B. FP16) kann das Training beschleunigen, führt aber auch zu Problemen mit der numerischen Stabilität. Es ist wahrscheinlicher, dass der für das FP16-Training verwendete Gradient überläuft oder unzureichend ist, was zu ungenauen Berechnungen durch den Optimierer und zu Problemen führt, z. B. wenn der Akkumulator den Datentypbereich überschreitet.

In diesem Artikel werden wir das Problem der numerischen Stabilität des hybriden Präzisionstrainings diskutieren. Große Schulungsaufträge werden oft tagelang auf Eis gelegt, um mit numerischen Instabilitäten umzugehen, was zu Projektverzögerungen führt. So können wir Tensor Collection Hook einführen, um die Gradientenbedingungen während des Trainings zu überwachen, damit wir den internen Zustand des Modells besser verstehen und numerische Instabilität schneller erkennen können.
Es ist eine sehr gute Möglichkeit, den internen Zustand des Modells in der frühen Trainingsphase zu verstehen, um festzustellen, ob das Modell im späteren Training zu Instabilität neigt. Wenn in den ersten Stunden des Trainings eine Gradienteninstabilität festgestellt werden kann, ist dies der Fall Helfen Sie uns, die Effizienz erheblich zu verbessern. Daher enthält dieser Artikel eine Reihe von Vorbehalten, die es zu beachten gilt, sowie Abhilfemaßnahmen für numerische Instabilitäten.
Mixed Precision Training
Während sich Deep Learning in Richtung größerer Basismodelle weiterentwickelt. Große Sprachmodelle wie GPT und T5 dominieren jetzt NLP, und kontrastierende Modelle wie CLIP lassen sich im Lebenslauf besser verallgemeinern als herkömmliche überwachte Modelle. Insbesondere die Fähigkeit von CLIP, Texteinbettungen zu lernen, bedeutet, dass es Zero-Shot- und Fow-Shot-Inferenzen durchführen kann, die die Fähigkeiten früherer CV-Modelle übertreffen, deren Training beide eine Herausforderung darstellten.
Diese großen Modelle umfassen typischerweise tiefe Netzwerke von visuellen und textlichen Transformatoren und enthalten Milliarden von Parametern. GPT3 verfügt über 175 Milliarden Parameter und CLIP wird auf Hunderten Terabytes an Bildern trainiert. Aufgrund der Größe des Modells und der Daten dauert das Training der Modelle auf großen GPU-Clustern Wochen oder sogar Monate. Um das Training zu beschleunigen und die Anzahl der erforderlichen GPUs zu reduzieren, werden Modelle häufig mit gemischter Präzision trainiert.
Hybrid Precision Training verlegt einige Trainingsvorgänge in FP16 statt in FP32. In FP16 ausgeführte Vorgänge benötigen weniger Speicher und können auf modernen GPUs bis zu achtmal schneller verarbeitet werden als FP32. Obwohl die meisten im FP16 trainierten Modelle eine geringere Genauigkeit aufweisen, zeigen sie keine Leistungseinbußen aufgrund einer Überparametrisierung.
Mit der Einführung von Tensor Cores von NVIDIA in der Volta-Architektur ist das beschleunigte Gleitkomma-Training mit niedriger Präzision schneller. Da Deep-Learning-Modelle über viele Parameter verfügen, ist der genaue Wert eines einzelnen Parameters normalerweise nicht wichtig. Durch die Darstellung von Zahlen mit 16 Bit anstelle von 32 Bit können mehr Parameter gleichzeitig in Tensor-Core-Registern untergebracht werden, wodurch die Parallelität für jede Operation erhöht wird.

Aber das Training für FP16 ist eine Herausforderung. Weil FP16 keine Zahlen darstellen kann, deren absoluter Wert größer als 65.504 oder kleiner als 5,96e-8 ist. Deep-Learning-Frameworks wie PyTorch verfügen über integrierte Tools, um die Einschränkungen von FP16 (Gradientenskalierung und automatische gemischte Präzision) zu bewältigen. Aber selbst wenn diese Sicherheitskontrollen vorhanden sind, kommt es nicht selten vor, dass große Trainingsaufgaben scheitern, weil Parameter oder Steigungen außerhalb des verfügbaren Bereichs liegen. Einige Komponenten des Deep Learning funktionieren im FP32 gut, aber BN erfordert beispielsweise häufig eine sehr feine Feinabstimmung, die innerhalb der Grenzen des FP16 zu numerischer Instabilität führen oder nicht genügend Genauigkeit liefern kann, damit das Modell korrekt konvergiert. Dies bedeutet, dass Modelle nicht blind auf FP16 umgestellt werden können.
Das Deep-Learning-Framework verwendet also Automatic Mixed Precision (AMP), das anhand einer vordefinierten Liste sicherer FP16-Operationen trainiert wird. AMP konvertiert nur Teile des Modells, die als sicher gelten, während Vorgänge, die eine höhere Präzision erfordern, in FP32 beibehalten werden. Darüber hinaus wird im gemischten Präzisionstrainingsmodell ein größerer Gradient erhalten, indem einige Verluste nahe dem Gradienten Null (unterhalb des Mindestbereichs von FP16) mit einem bestimmten Wert multipliziert werden und dann, wenn der Optimierer angewendet wird, die Modellgewichte aktualisiert werden Die Anpassung zur Lösung des Problems zu kleiner Gradienten wird als Gradientenskalierung bezeichnet.
Das Folgende ist ein Beispiel einer typischen AMP-Trainingsschleife in PyTorch.

Der Gradientenskalierer multipliziert den Verlust mit einem variablen Betrag. Wenn nan im Gradienten beobachtet wird, wird der Multiplikator um die Hälfte reduziert, bis das nan verschwindet. Anschließend wird der Multiplikator standardmäßig alle 2000 Schritte schrittweise erhöht, wenn kein nan auftritt. Dadurch bleibt der Gradient im FP16-Bereich und wird gleichzeitig verhindert, dass der Gradient auf Null geht.
Fall von Trainingsinstabilität
Trotz der besten Bemühungen beider Frameworks können die in PyTorch und TensorFlow integrierten Tools die numerische Instabilität, die in FP16 auftritt, nicht verhindern.
In der T5-Implementierung von HuggingFace erzeugten Modellvarianten auch nach dem Training INF-Werte. In sehr tiefen T5-Modellen akkumulieren die Aufmerksamkeitswerte über Schichten hinweg und erreichen schließlich außerhalb des FP16-Bereichs, was zu unendlichen Werten führt, wie z. B. nan in BN-Schichten. Sie lösten dieses Problem, indem sie den INF-Wert bei FP16 auf den Maximalwert änderten und stellten fest, dass dies einen vernachlässigbaren Einfluss auf die Schlussfolgerung hatte.
Ein weiteres häufiges Problem sind die Einschränkungen des ADAM-Optimierers. Als kleines Update verwendet ADAM einen gleitenden Durchschnitt des ersten und zweiten Moments des Gradienten, um die Lernrate jedes Parameters im Modell anzupassen.
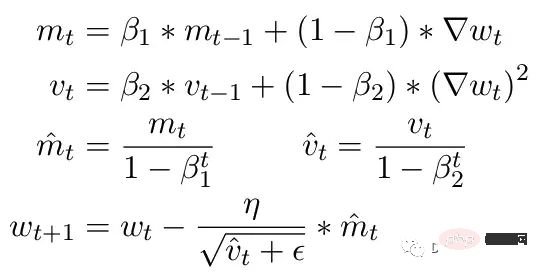
Hier sind Beta1 und Beta2 die Parameter des gleitenden Durchschnitts zu jedem Zeitpunkt, normalerweise auf 0,9 bzw. 0,999 eingestellt. Die Division des Beta-Parameters durch die Potenz der Anzahl der Schritte beseitigt die anfängliche Verzerrung in den Aktualisierungen. Während des Aktualisierungsschritts wird ein kleines Epsilon zum Parameter des zweiten Moments hinzugefügt, um Fehler bei der Division durch Null zu vermeiden. Der typische Standardwert für Epsilon ist 1e-8. Das Minimum für FP16 liegt jedoch bei 5,96e-8. Das heißt, wenn das zweite Moment zu klein ist, wird die Aktualisierung durch Null geteilt. Damit in PyTorch das Training nicht abweicht, werden bei Aktualisierungen Änderungen in diesem Schritt übersprungen. Das Problem besteht jedoch weiterhin. Insbesondere im Fall von Beta2 = 0,999 kann jeder Gradient, der kleiner als 5,96e-8 ist, die Aktualisierung des Parametergewichts für längere Zeit stoppen und der Optimierer gerät in einen instabilen Zustand.
Der Vorteil von ADAM besteht darin, dass durch die Verwendung dieser beiden Momente die Lernrate jedes Parameters angepasst werden kann. Bei langsameren Lernparametern kann die Lerngeschwindigkeit beschleunigt werden, bei schnellen Lernparametern kann die Lerngeschwindigkeit verlangsamt werden. Wenn der Gradient jedoch für mehrere Schritte mit Null berechnet wird, führt selbst ein kleiner positiver Wert dazu, dass das Modell divergiert, bevor die Lernrate Zeit hat, sich nach unten anzupassen.
Außerdem hat PyTorch derzeit ein Problem, bei dem Epsilon automatisch auf 1e-7 geändert wird, wenn gemischte Präzision verwendet wird, was dazu beitragen kann, zu verhindern, dass Gradienten divergieren, wenn zu positiven Werten zurückgekehrt wird. Dies bringt jedoch ein neues Problem mit sich. Wenn wir wissen, dass der Gradient im gleichen Bereich liegt, verringert eine Erhöhung von ε die Fähigkeit des Optimierers, sich an die Lernrate anzupassen. Daher kann eine blinde Erhöhung des Epsilon das Problem der Trainingsstagnation aufgrund eines Nullgradienten nicht lösen.
Gradientenskalierung im CLIP-Training
Um die Instabilitäten, die beim Training auftreten können, weiter zu demonstrieren, haben wir eine Reihe von Experimenten mit dem CLIP-Bildmodell erstellt. CLIP ist ein kontrastives, lernbasiertes Modell, das gleichzeitig Bilder durch einen visuellen Transformator und Texteinbettungen lernt, die diese Bilder beschreiben. Die Vergleichskomponente versucht, Bilder in jedem Datenstapel wieder mit der ursprünglichen Beschreibung abzugleichen. Da der Verlust stapelweise berechnet wird, liefert das Training mit größeren Stapeln nachweislich bessere Ergebnisse.
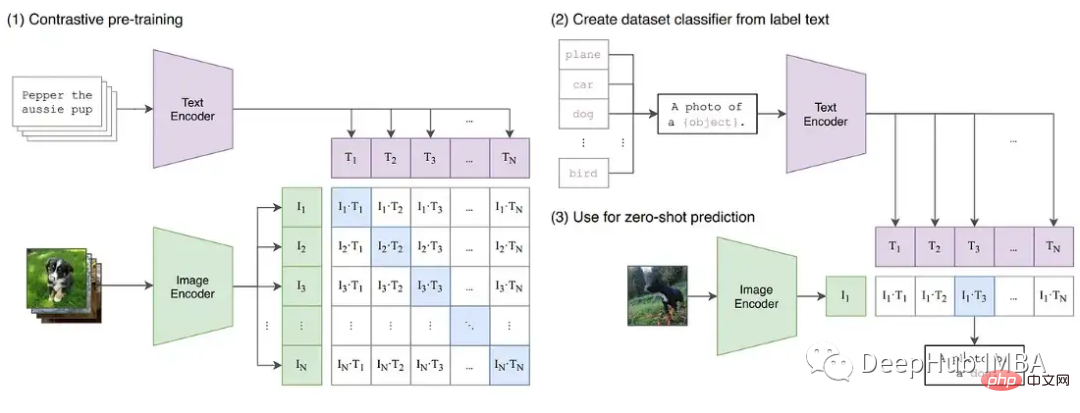
CLIP trainiert gleichzeitig zwei Transformer-Modelle, ein GPT-ähnliches Sprachmodell und ein ViT-Bildmodell. Die Tiefe beider Modelle schafft Möglichkeiten für ein Gradientenwachstum, das die FP16-Grenze überschreitet. Die OpenClip-Implementierung (arxiv 2212.07143) beschreibt Trainingsinstabilität bei Verwendung von FP16.
Tensor Collection Hook
Um den internen Modellzustand während des Trainings besser zu verstehen, haben wir einen Tensor Collection Hook (TCH) entwickelt. TCH kann ein Modell umschließen und regelmäßig zusammenfassende Informationen zu Gewichten, Gradienten, Verlusten, Eingaben, Ausgaben und dem Optimiererstatus sammeln.
In diesem Experiment wollen wir beispielsweise die Steigungsverhältnisse während des Trainings ermitteln und aufzeichnen. Beispielsweise möchten Sie möglicherweise alle 10 Schritte die Gradientennorm, das Minimum, das Maximum, den Absolutwert, den Mittelwert und die Standardabweichung jeder Ebene erfassen und die Ergebnisse in TensorBoard visualisieren.

TensorBoard kann dann mit out_dir als --logdir-Eingabe gestartet werden.

Experimente
Um Trainingsinstabilitäten in CLIP zu reproduzieren, wurde eine Teilmenge des 5-Milliarden-Bilddatensatzes von Laion zum Trainieren von OpenCLIP verwendet. Wir umhüllen das Modell mit TCH und speichern regelmäßig die Modellgradienten, Gewichte und Momentenzustände des Optimierers, damit wir beobachten können, was im Modell passiert, wenn Instabilität auftritt.
Beginnend mit der vvi-h-14-Variante beschreiben die OpenCLIP-Autoren ein Stabilitätsproblem während des Trainings. Erhöhen Sie ausgehend vom Kontrollpunkt vor dem Training die Lernrate auf 1-e4, ähnlich der Lernrate in der zweiten Hälfte des CLIP-Trainings. Wenn das Training 300 Schritte erreicht, werden gezielt 10 schwierigere Trainingsabschnitte nacheinander eingeführt.
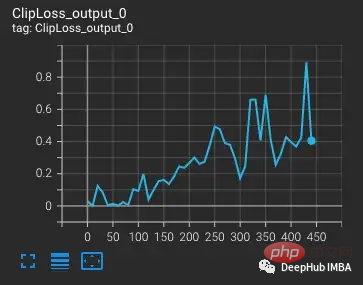
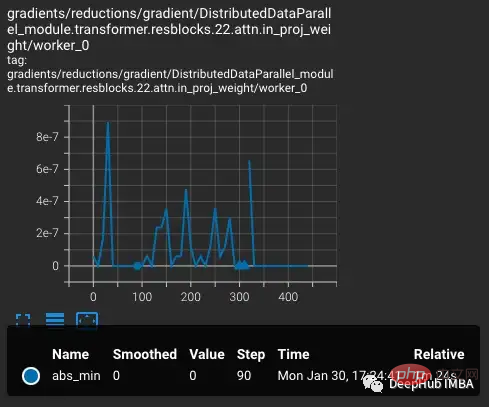
Der Verlust steigt mit zunehmender Lernrate, was zu erwarten ist. Wenn bei Schritt 300 eine schwierigere Situation eingeführt wird, erhöht sich der Verlust geringfügig, aber nicht stark. Das Modell findet schwierige Fälle, aktualisiert jedoch die meisten Gewichte in diesen Schritten nicht, da nan im Gradienten erscheint (im zweiten Diagramm als Dreieck dargestellt). Nach Bestehen dieser schwierigen Fallgruppe fällt der Gradient auf Null.
PyTorch-Gradientenskalierung
Was ist hier los? Das Problem liegt in der Gradientenskalierung von PyTorch. Die Gradientenskalierung ist ein wichtiges Werkzeug im gemischten Präzisionstraining. Denn in Modellen mit Millionen oder Milliarden von Parametern ist der Gradient jedes einzelnen Parameters klein und liegt oft unter dem Mindestbereich von FP16.
Als das hybride Präzisionstraining zum ersten Mal vorgeschlagen wurde, stellten Deep-Learning-Wissenschaftler fest, dass ihre Modelle zu Beginn des Trainings oft wie erwartet trainierten, aber schließlich voneinander abwichen. Mit fortschreitendem Training wird der Gradient tendenziell kleiner und ein Teil des Unterlaufs FP16 geht auf Null, was das Training instabil macht.

Um den Gradientenunterlauf zu beheben, multiplizierten frühe Techniken einfach den Verlust mit einem festen Betrag, berechneten den größeren Gradienten und passten dann die Gewichtsaktualisierungen auf denselben festen Betrag an (während des Hybrid-Präzisionstrainings werden die Gewichte weiterhin gespeichert). im FP32). Doch manchmal reicht dieser Festbetrag dennoch nicht aus. Während neuere Techniken, wie die Gradientenskalierung von PyTorch, mit einem größeren Multiplikator beginnen, normalerweise 65536. Da dieser jedoch so hoch sein kann, dass große Gradienten den FP16-Wert überschreiten, überwacht der Gradientenskalierer Nano-Gradienten, die überlaufen. Wenn nan beobachtet wird, überspringen Sie die Gewichtsaktualisierung in diesem Schritt, um den Multiplikator zu halbieren, und fahren Sie mit dem nächsten Schritt fort. Dies wird so lange fortgesetzt, bis im Gradienten kein Nano mehr beobachtet wird. Wenn der Gradientenskalierer in Schritt 2000 kein Nano erkennt, versucht er, den Multiplikator zu verdoppeln.
Im obigen Beispiel funktioniert der Verlaufsskalierer genau wie erwartet. Wir übergeben ihm eine Reihe von Fällen, in denen der Verlust größer als erwartet ist, was zu größeren Gradienten führt, die zu einem Überlauf führen. Das Problem besteht jedoch darin, dass der Multiplikator jetzt niedrig ist, die kleineren Gradienten auf Null fallen und der Gradientenskalierer Nullgradienten nicht nur nan überwacht.
Das obige Beispiel mag zunächst etwas absichtlich erscheinen, da wir schwierige Beispiele absichtlich gruppiert haben. Aber nach mehreren Trainingstagen wird bei großen Chargen die Wahrscheinlichkeit der Entstehung von Nanoanomalien definitiv steigen. Daher ist die Chance sehr hoch, auf genügend Nano zu stoßen, um den Gradienten auf Null zu bringen. Selbst wenn keine schwierigen Proben eingeführt werden, wird häufig festgestellt, dass der Gradient nach Tausenden von Trainingsschritten immer Null ist.
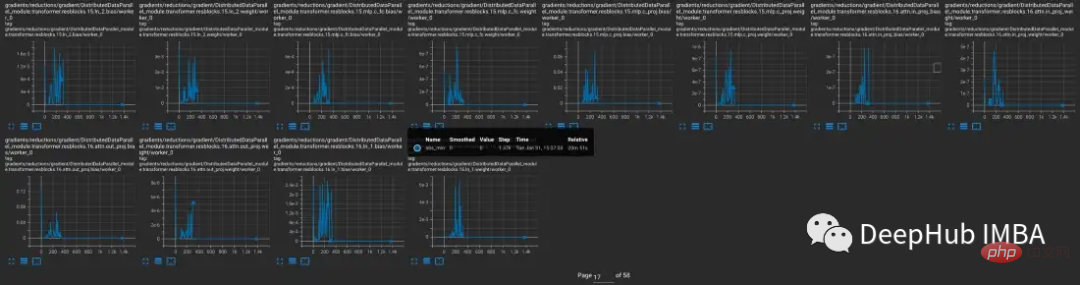
Modelle, die einen Gradientenunterlauf erzeugen
Um weiter zu untersuchen, wann das Problem auftritt und wann nicht, wurde CLIP mit YOLOV5 verglichen, einem kleineren CV-Modell, das typischerweise mit gemischter Präzision trainiert wird. Die Häufigkeit von Nullgradienten in jeder Schicht wurde in beiden Fällen während des Trainings verfolgt.

In den ersten 9000 Schritten des Trainings zeigen 5–20 % der Ebenen in CLIP einen Gradientenunterlauf, während Ebenen in Yolo nur gelegentlich einen Unterlauf zeigen. Auch die Unterlaufrate in CLIP nimmt mit der Zeit zu, wodurch das Training weniger stabil wird.
Die Verwendung der Gradientenskalierung löst dieses Problem nicht, da die Gradientengröße im CLIP-Bereich viel größer ist als die Gradientengröße im YOLO-Bereich. Im Fall von CLIP verschiebt der Gradient Scaler im FP16 die größeren Gradienten näher an das Maximum, während die kleinsten Gradienten unter dem Minimum bleiben.
So beheben Sie die Gradienteninstabilität beim Lösen von CLIP
In einigen Fällen kann das Anpassen der Parameter des Gradientenskalierers dazu beitragen, einen Unterlauf zu verhindern. Im Fall von CLIP könnte man Modifikationen ausprobieren, um mit einem größeren Multiplikator zu beginnen und das Erhöhungsintervall zu verkürzen.

Aber wir haben festgestellt, dass der Multiplikator sofort abfällt, um einen Überlauf zu verhindern und den kleinen Gradienten wieder auf Null zu zwingen.

Eine Lösung zur Verbesserung der Skalierung besteht darin, sie besser an den Parameterbereich anpassbar zu machen. Beispielsweise wird in dem Artikel „Adaptive Verlustskalierung für gemischtes Präzisionstraining“ empfohlen, die Verlustskalierung schichtweise anstelle des gesamten Modells durchzuführen, um einen Unterlauf zu verhindern. Und unsere Experimente zeigen die Notwendigkeit eines adaptiveren Ansatzes. Da die Gradienten innerhalb der CLIP-Schicht immer noch den gesamten FP16-Bereich abdecken, muss die Skalierung an jeden einzelnen Parameter angepasst werden, um die Trainingsstabilität sicherzustellen. Eine solche detaillierte Skalierung erfordert jedoch viel Speicher, was die Größe des Trainingsstapels verringert.
Neuere Hardware bietet effizientere Lösungen. Beispielsweise ist BFloat16 (BF16) ein weiterer 16-Bit-Datentyp, der Präzision gegen größere Reichweite eintauscht. FP16 verarbeitet 5,96e-8 bis 65.504, während BF16 1,17e-38 bis 3,39e38 verarbeiten kann, der gleiche Bereich wie FP32. Allerdings ist die Genauigkeit von BF16 geringer als die von FP16, was dazu führt, dass einige Modelle nicht konvergieren. Bei großen Transformatormodellen hat sich jedoch nicht gezeigt, dass BF16 die Konvergenz verringert.
Wir führen den gleichen Test durch und fügen eine Reihe harter Beobachtungen ein. In BF16 steigt der Gradient an, wenn harte Fälle eingeführt werden, und kehrt dann zum regulären Training zurück, da aufgrund des beobachteten größeren NaN-Bereichs nie eine Gradientenskalierung im Gradienten auftritt.

Beim Vergleich des CLIP von FP16 und BF16 haben wir festgestellt, dass es in BF16 nur gelegentlich zu Gradientenunterläufen kommt.

In PyTorch 1.12 und höher ist es möglich, BF16 mit einer kleinen Änderung an AMP zu aktivieren.

Wenn Sie eine höhere Präzision benötigen, können Sie den Datentyp Tensorfloat32 (TF32) ausprobieren. TF32, das von Nvidia in Ampere-GPUs eingeführt wurde, ist ein 19-Bit-Gleitkomma, das die zusätzlichen Bereichsbits von BF16 hinzufügt und gleichzeitig die Präzision von FP16 beibehält. Im Gegensatz zu FP16 und BF16 soll es FP32 direkt ersetzen und nicht in gemischter Präzision aktiviert werden. Um TF32 in PyTorch zu aktivieren, fügen Sie zu Beginn des Trainings zwei Zeilen hinzu.

Hier etwas zu beachten: Vor PyTorch 1.11 war TF32 standardmäßig auf GPUs aktiviert, die diesen Datentyp unterstützten. Ab PyTorch 1.11 muss es manuell aktiviert werden. Die Trainingsgeschwindigkeit von TF32 ist langsamer als die von BF16 und FP16. Die theoretischen FLOPS betragen nur die Hälfte von FP16, sind aber immer noch viel schneller als die Trainingsgeschwindigkeit von FP32.
Wenn Sie Amazon AWS verwenden: BF16 und TF32 sind auf P4d-, P4de-, G5-, Trn1- und DL1-Instances verfügbar.
Probleme beheben, bevor sie auftreten
Das obige Beispiel zeigt, wie man FP16-weite Einschränkungen erkennt und behebt. Diese Probleme treten jedoch häufig erst später im Training auf. Zu Beginn des Trainings, wenn das Modell höhere Verluste erzeugt und weniger empfindlich auf Ausreißer reagiert, wie es beim OpenCLIP-Training der Fall ist, kann es Tage dauern, bis Probleme auftreten, was teure Rechenzeit verschwendet.
Sowohl FP16 als auch BF16 haben Vor- und Nachteile. Die Einschränkungen des FP16 können zu instabilem und stockendem Training führen. Allerdings bietet BF16 eine geringere Genauigkeit und möglicherweise eine schlechtere Konvergenz. Daher möchten wir auf jeden Fall frühzeitig im Training Modelle identifizieren, die anfällig für FP16-Instabilität sind, damit wir fundierte Entscheidungen treffen können, bevor Instabilität auftritt. Wenn man also noch einmal die Modelle vergleicht, die eine nachfolgende Trainingsinstabilität aufweisen bzw. nicht, lassen sich zwei Trends feststellen.

Sowohl das in FP16 trainierte YOLO-Modell als auch das in BF16 trainierte CLIP-Modell zeigen, dass die Gradientenunterlaufrate im Allgemeinen weniger als 1 % beträgt und über die Zeit stabil ist.

Das im FP16 trainierte CLIP-Modell weist in den ersten 1000 Trainingsschritten eine Unterlaufrate von 5–10 % auf und zeigt im Laufe der Zeit einen Aufwärtstrend.
Durch die Verwendung von TCH zur Verfolgung der Gradientenunterlaufrate können wir den Trend einer höheren Gradienteninstabilität innerhalb der ersten 4–6 Stunden des Trainings erkennen. Wechseln Sie zu BF16, wenn dieser Trend beobachtet wird.
Zusammenfassung
Hybrides Präzisionstraining ist ein wichtiger Bestandteil des Trainings bestehender großer Basismodelle, erfordert jedoch besondere Aufmerksamkeit auf die numerische Stabilität. Das Verständnis des internen Zustands eines Modells ist wichtig für die Diagnose, wann ein Modell auf die Einschränkungen von Datentypen mit gemischter Genauigkeit stößt. Durch die Umhüllung des Modells mit einem TCH ist es möglich, zu verfolgen, ob sich Parameter oder Gradienten numerischen Grenzen nähern, und Trainingsänderungen durchzuführen, bevor Instabilität auftritt, wodurch möglicherweise die Anzahl der Tage erfolgloser Trainingsläufe reduziert wird.
Das obige ist der detaillierte Inhalt vonSo lösen Sie die Einschränkungen beim Training großer Modelle mit gemischter Präzision. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr