
Heim >Technologie-Peripheriegeräte >KI >Die Genauigkeitsrate beträgt weniger als 20 %, GPT-4V/Gemini kann keine Comics lesen! Erster Open-Source-Benchmark für Bildsequenzen
Die Genauigkeitsrate beträgt weniger als 20 %, GPT-4V/Gemini kann keine Comics lesen! Erster Open-Source-Benchmark für Bildsequenzen

- 王林nach vorne
- 2024-02-01 19:06:131092Durchsuche
OpenAIs GPT-4V und das multimodale große Sprachmodell Gemini von Google haben in der Industrie und in der Wissenschaft große Aufmerksamkeit erregt. Diese Modelle demonstrieren ein tiefes Verständnis von Video in mehreren Bereichen und demonstrieren sein Potenzial aus verschiedenen Perspektiven. Diese Fortschritte werden allgemein als wichtiger Schritt in Richtung künstlicher allgemeiner Intelligenz (AGI) angesehen.
Aber wenn ich Ihnen sage, dass GPT-4V sogar das Verhalten von Charakteren in Comics falsch interpretieren kann, lassen Sie mich fragen: Yuanfang, was denken Sie?
Werfen wir einen Blick auf diese Mini-Comic-Serie:
 Bilder
Bilder
Wenn Sie die höchste Intelligenz in der biologischen Welt – Menschen, also Leserfreunde, es beschreiben lassen, werden Sie es am meisten tun Sagen Sie wahrscheinlich:
 Bilder
Bilder
Dann wollen wir mal sehen, was die höchste Intelligenz der Maschinenwelt – also GPT-4V – beschreiben wird, wenn es um diese Mini-Comic-Serie geht?
 Bilder
Bilder
GPT - 4V, als Maschinenintelligenz, von der man annahm, dass sie an der Spitze der Missachtungskette steht, hat tatsächlich unverhohlen gelogen.
Was noch empörender ist, ist, dass GPT-4V, selbst wenn ihm echte Bildausschnitte gegeben werden, das Verhalten einer Person, die mit einer anderen Person spricht, während sie die Treppe hinaufgeht, absurderweise als zwei Personen erkennt, die mit „Waffen“ gegeneinander kämpfen. Verspielt (Bild unten).
 Bilder
Bilder
Gemini ist nicht weit dahinter. Derselbe Bildclip zeigt den Prozess, wie ein Mann sich bemüht, nach oben zu gehen, mit seiner Frau streitet und im Haus eingesperrt wird.
 Bilder
Bilder
Diese Beispiele stammen aus den neuesten Ergebnissen des Forschungsteams der University of Maryland und North Carolina Chapel Hill, das Mementos ins Leben gerufen hat, einen Inferenz-Benchmark für Bildsequenzen, der speziell für MLLM entwickelt wurde.
So wie Nolans Memento das Geschichtenerzählen neu definiert hat, definiert Mementos die Grenzen des Testens künstlicher Intelligenz neu.
Als neuer Benchmark-Test stellt er das Verständnis künstlicher Intelligenz für Bildsequenzen wie Erinnerungsfragmente in Frage.
 Bilder
Bilder
Papierlink: https://arxiv.org/abs/2401.10529
Projekthomepage: https://mementos-bench.github.io
Mementos ist der erste speziell für MLLM entwickelte Benchmark für Bildsequenz-Schlussfolgerungen, die sich auf Objekthalluzinationen und Verhaltenshalluzinationen großer Modelle auf aufeinanderfolgenden Bildern konzentrieren.
Es handelt sich um verschiedene Arten von Bildern, die drei Hauptkategorien abdecken: Bilder aus der realen Welt, Roboterbilder und Animationsbilder.
Und enthält 4.761 verschiedene Bildsequenzen unterschiedlicher Länge, jede mit menschlichen Anmerkungen, die die Hauptobjekte und ihr Verhalten in der Sequenz beschreiben.
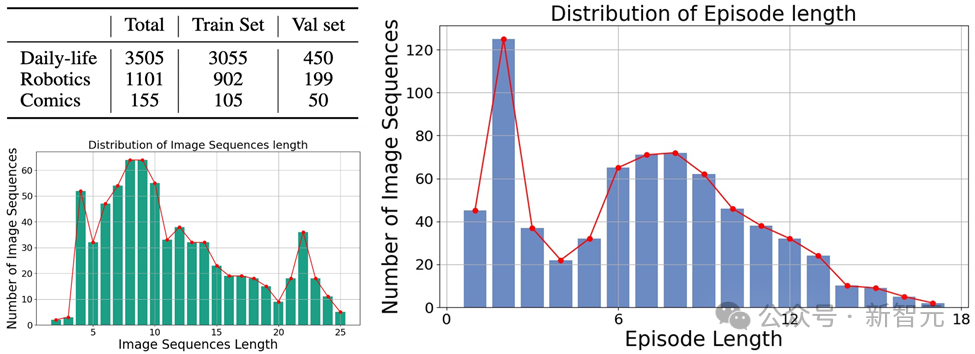 Bilder
Bilder
Die Daten sind derzeit Open Source und werden noch aktualisiert.
Arten von Halluzinationen
In dem Artikel erklärt der Autor zwei Arten von Halluzinationen, die MLLM in Erinnerungsstücken hervorrufen wird: Objekthalluzinationen und Verhaltenshalluzinationen.
Wie der Name schon sagt, handelt es sich bei der Objekthalluzination um die Vorstellung eines nicht existierenden Objekts (Objekts), während es sich bei der Verhaltenshalluzination um die Vorstellung von Handlungen und Verhaltensweisen handelt, die das Objekt nicht ausgeführt hat.
Bewertungsmethode
Um die Verhaltenshalluzination und Objekthalluzination von MLLM auf Erinnerungsstücken genau zu bewerten, entschied sich das Forschungsteam für einen Stichwortabgleich der von MLLM generierten Bildbeschreibung und der Beschreibung der menschlichen Anmerkung.
Um die Leistung jedes MLLM automatisch zu bewerten, verwendet der Autor die GPT-4-Hilfstestmethode zur Bewertung:
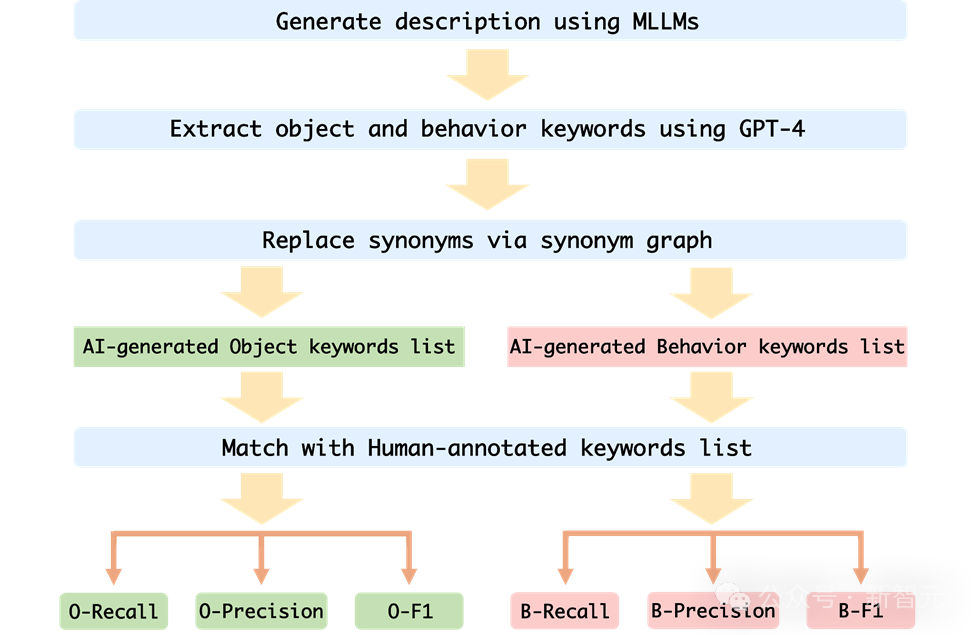 Bilder
Bilder
1 Der Autor verwendet die Bildsequenz und die Eingabeaufforderungswörter als Eingabe für MLLM generiert die entsprechende Beschreibung, die der Bildsequenz entspricht.
2. Fordern Sie GPT-4 auf, die Objekt- und Verhaltensschlüsselwörter in der von der KI generierten Beschreibung zu extrahieren Von der KI generierte Verhaltensschlüsselwortliste;
4. Berechnen Sie die Rückrufrate, die Genauigkeitsrate und den F1-Index der von der KI generierten Objektschlüsselwortliste und der vom Menschen kommentierten Schlüsselwortliste.
Bewertungsergebnisse
Der Autor bewertete die Leistung von MLLMs beim Sequence Image Reasoning auf Mementos und führte eine detaillierte Bewertung von neun neuesten MLLMs durch, darunter GPT4V und Gemini.
MLLM wird gebeten, die in der Bildsequenz auftretenden Ereignisse zu beschreiben, um die Argumentationsfähigkeit von MLLM für kontinuierliche Bilder zu bewerten.
Die Ergebnisse zeigen, wie in der folgenden Abbildung dargestellt, dass die Genauigkeit von GPT-4V und Gemini für das Charakterverhalten im Comic-Datensatz weniger als 20 % beträgt.
Bilder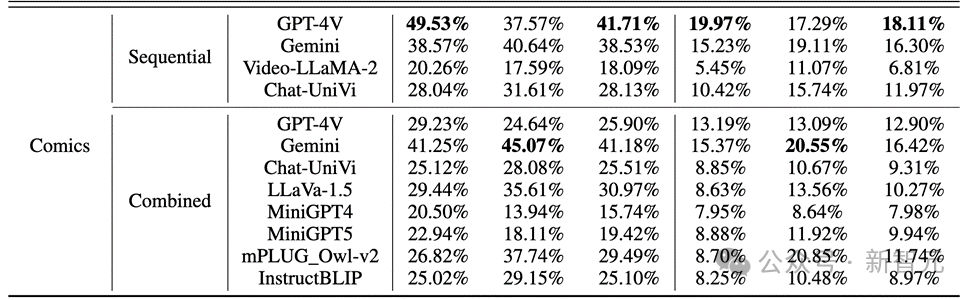 Bei realen Bildern und Roboterbildern ist die Leistung von GPT-4V und Gemini nicht zufriedenstellend:
Bei realen Bildern und Roboterbildern ist die Leistung von GPT-4V und Gemini nicht zufriedenstellend:
Bilder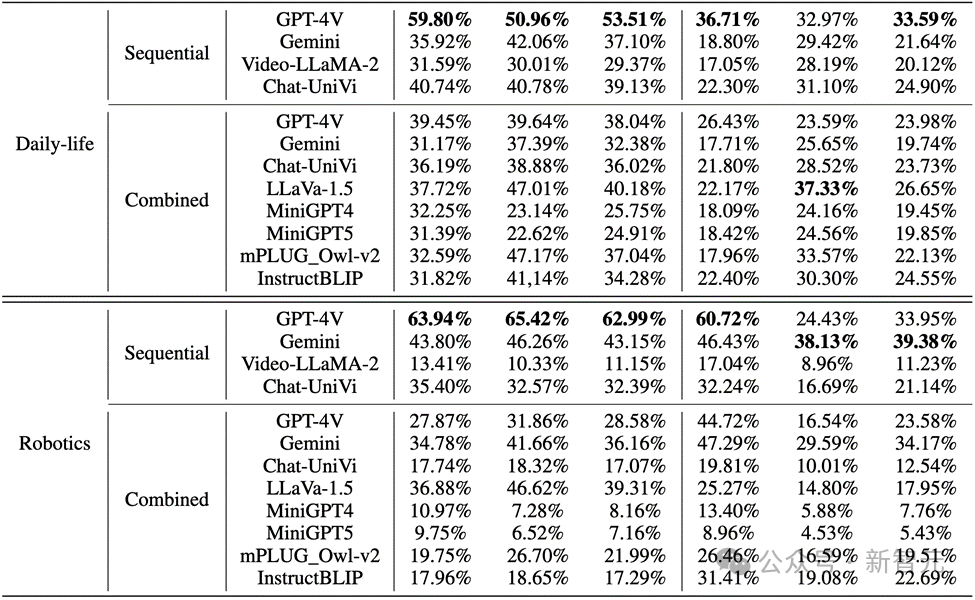 Wichtige Punkte
Wichtige Punkte
1. Bei der Bewertung mehrerer Wenn es Wenn es um modale groß angelegte Sprachmodelle geht, sind GPT-4V und LLaVA-1.5 die leistungsstärksten Modelle in Black-Box- bzw. Open-Source-MLLMs. GPT-4V übertrifft alle anderen MLLMs hinsichtlich der Denkfähigkeit zum Verständnis von Bildsequenzen, während LLaVA-1.5 beim Objektverständnis fast mit dem Black-Box-Modell Gemini mithalten oder es sogar übertrifft.
2. Obwohl Video-LLaMA-2 und Chat-UniVi für das Videoverständnis konzipiert sind, zeigen sie keine besseren Vorteile als LLaVA-1.5.
3. Alle MLLMs schneiden bei den drei Indikatoren des Objektdenkens in Bildsequenzen deutlich besser ab als das Verhaltensdenken, was darauf hindeutet, dass aktuelle MLLMs nicht gut darin sind, Verhaltensweisen aus aufeinanderfolgenden Bildern autonom abzuleiten.
4. Das Black-Box-Modell schneidet im Bereich Robotik am besten ab, während das Open-Source-Modell im Bereich des täglichen Lebens relativ gut abschneidet. Dies kann mit der Verteilungsverschiebung der Trainingsdaten zusammenhängen.
5. Die Einschränkungen der Trainingsdaten führen zu schwachen Inferenzfähigkeiten von Open-Source-MLLMs. Dies zeigt die Bedeutung von Trainingsdaten und ihren direkten Einfluss auf die Modellleistung.
Fehlergründe
Die Analyse des Autors der Gründe, warum aktuelle multimodale groß angelegte Sprachmodelle bei der Verarbeitung von Bildsequenzbegründungen versagen, identifiziert hauptsächlich drei Fehlergründe:
1. Die Beziehung zwischen Objekten und Verhaltensillusionen
Die Studie geht davon aus, dass eine falsche Objekterkennung zu einer ungenauen nachfolgenden Handlungserkennung führt. Quantitative Analysen und Fallstudien zeigen, dass Objekthalluzinationen bis zu einem gewissen Grad zu Verhaltenshalluzinationen führen können. Wenn MLLM beispielsweise eine Szene fälschlicherweise als Tennisplatz identifiziert, beschreibt sie möglicherweise eine Tennis spielende Figur, obwohl dieses Verhalten in der Bildsequenz nicht vorhanden ist.
2. Der Einfluss des gleichzeitigen Auftretens auf Verhaltenshalluzinationen
MLLM neigt dazu, Verhaltenskombinationen zu erzeugen, die beim Denken in Bildsequenzen häufig vorkommen, was das Problem von Verhaltenshalluzinationen verschärft. Beispielsweise beschreibt MLLM bei der Verarbeitung von Bildern aus dem Robotikbereich möglicherweise fälschlicherweise einen Roboterarm, der eine Schublade öffnet, nachdem er „den Griff gegriffen“ hat, obwohl die eigentliche Aktion darin bestand, „die Seite der Schublade zu greifen“.
3. Schneeballeffekt der Verhaltensillusion
Mit fortschreitender Bildsequenz können sich Fehler allmählich anhäufen oder verstärken, was als Schneeballeffekt bezeichnet wird. Wenn bei der Bildsequenzbetrachtung Fehler frühzeitig auftreten, können sich diese Fehler in der Sequenz anhäufen und verstärken, was zu einer verringerten Genauigkeit bei der Objekt- und Aktionserkennung führt.
Zum Beispiel
Bild
Wie aus der obigen Abbildung ersichtlich ist, gehören Objekthalluzination und die Korrelation zwischen Objekthalluzination und Verhaltenshalluzination zu den Gründen für das Scheitern von MLLM gleichzeitig auftretende Verhaltensweisen.
Nachdem MLLM beispielsweise die Objekthalluzination „Tennisplatz“ erlebt hatte, zeigte es dann die Verhaltenshalluzination „einen Tennisschläger halten“ (Korrelation zwischen Objekthalluzination und Verhaltenshalluzination) und das gleichzeitig auftretende Verhalten „den Anschein zu erwecken, Tennis zu spielen“. " .
 Bilder
Bilder
Wenn Sie sich das Beispiel im Bild oben ansehen, können Sie sehen, dass MLLM fälschlicherweise glaubte, der Stuhl sei weiter nach hinten geneigt und glaubte, der Stuhl sei kaputt.
Dieses Phänomen zeigt, dass MLLM auch bei statischen Objekten in der Bildsequenz die Illusion erzeugen kann, dass eine Aktion am Objekt stattgefunden hat.
 Bilder
Bilder
In der obigen Bildsequenzanzeige des Roboterarms greift der Roboterarm neben den Griff, und MLLM geht fälschlicherweise davon aus, dass der Roboterarm den Griff ergriffen hat, was beweist, dass MLLM generiert wird Das Bild sind Kombinationen von Verhaltensweisen, die in der Reihenfolge des Denkens häufig auftreten und dadurch Halluzinationen hervorrufen.
 Bild
Bild
Im obigen Fall glaubte der alte Meister nicht, dass das Führen des Hundes erforderlich sei, und „Hundestabhochsprung“ wurde als „Der Brunnen“ erkannt entstand.“
Die große Anzahl von Fehlern spiegelt die Unkenntnis von MLLM im Bereich der zweidimensionalen Animation wider.
Im Anhang zeigt der Autor jede Hauptkategorie detaillierte Fehlerfälle und führte eine tiefgreifende Analyse durch.
Zusammenfassung
In den letzten Jahren haben multimodale groß angelegte Sprachmodelle hervorragende Fähigkeiten bei der Bewältigung verschiedener visuell-linguistischer Aufgaben bewiesen.
Diese Modelle wie GPT-4V und Gemini sind in der Lage, Text in Bezug auf Bilder zu verstehen und zu generieren, was die Entwicklung der Technologie der künstlichen Intelligenz erheblich vorantreibt.
Bestehende MLLM-Benchmarks konzentrieren sich jedoch hauptsächlich auf Rückschlüsse auf der Grundlage eines einzelnen statischen Bildes, während die Fähigkeit, aus Bildsequenzen Rückschlüsse zu ziehen, die für das Verständnis unserer sich verändernden Welt von entscheidender Bedeutung ist, relativ wenig untersucht wurde.
Um dieser Herausforderung zu begegnen, schlagen Forscher einen neuen Benchmark „Mementos“ vor, der darauf abzielt, die Fähigkeiten von MLLMs beim Sequence Image Reasoning zu bewerten.
Mementos enthält 4761 verschiedene Bildsequenzen unterschiedlicher Länge. Darüber hinaus hat das Forschungsteam auch die GPT-4-Hilfsmethode übernommen, um die Inferenzleistung von MLLM zu bewerten.
Durch sorgfältige Auswertung von neun neuesten MLLMs (einschließlich GPT-4V und Gemini) auf Mementos stellte die Studie fest, dass diese Modelle Schwierigkeiten bei der genauen Beschreibung der dynamischen Informationen einer bestimmten Bildsequenz haben, was häufig zu Halluzinationen von Objekten und deren Verhalten führt /falscher Ausdruck.
Quantitative Analyse und Fallstudien identifizieren drei Schlüsselfaktoren, die das Sequenzbilddenken in MLLMs beeinflussen:
1. Zusammenhang zwischen Objekt- und Verhaltensillusionen;
3. Kumulative Auswirkungen von Verhaltenshalluzinationen.
Diese Entdeckung ist von großer Bedeutung für das Verständnis und die Verbesserung der Fähigkeit von MLLMs, dynamische visuelle Informationen zu verarbeiten. Der Mementos-Benchmark zeigt nicht nur die Grenzen aktueller MLLMs auf, sondern bietet auch Hinweise für zukünftige Forschung und Verbesserungen.
Mit der rasanten Entwicklung der Technologie der künstlichen Intelligenz wird die Anwendung von MLLMs im Bereich des multimodalen Verständnisses umfassender und tiefgreifender. Die Einführung des Mementos-Benchmarks fördert nicht nur die Forschung in diesem Bereich, sondern bietet uns auch neue Perspektiven, um zu verstehen und zu verbessern, wie diese fortschrittlichen KI-Systeme unsere komplexe und sich ständig verändernde Welt verarbeiten und verstehen.
Referenzen:
https://github.com/umd-huanglab/Mementos
Das obige ist der detaillierte Inhalt vonDie Genauigkeitsrate beträgt weniger als 20 %, GPT-4V/Gemini kann keine Comics lesen! Erster Open-Source-Benchmark für Bildsequenzen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- ChatGPT-Sonderthema: Die Fähigkeiten und die Zukunft großer Sprachmodelle
- Als erstes inländisches Unternehmen bestand 360 Intelligent Brain die bewährte AIGC-Funktionsbewertung für große Sprachmodelle der China Academy of Information and Communications Technology
- In diesem Artikel lernen Sie das von Tencent unabhängig entwickelte universelle große Sprachmodell kennen – das große Hunyuan-Modell.
- Erstellen Sie in nur drei Minuten schnell eine große KI-Wissensdatenbank für Sprachmodelle
- Huaweis erster Service-Flagship-Store in Südchina eröffnet: Intelligente Roboter helfen Ingenieuren, Teile automatisch zu beschaffen