
Heim >Technologie-Peripheriegeräte >KI >Im Zeitalter der großen Modelle beschäftigt sich NTU Zhou Zhihua intensiv mit dem Studium von Software, und seine neueste Arbeit ist online
Im Zeitalter der großen Modelle beschäftigt sich NTU Zhou Zhihua intensiv mit dem Studium von Software, und seine neueste Arbeit ist online

- 王林nach vorne
- 2024-01-31 11:06:08941Durchsuche
Maschinelles Lernen hat in verschiedenen Bereichen große Erfolge erzielt und es entstehen ständig zahlreiche hochwertige Modelle für maschinelles Lernen. Für normale Benutzer ist es jedoch nicht einfach, ein für ihre Aufgaben geeignetes Modell zu finden, geschweige denn ein neues Modell von Grund auf zu erstellen. Um dieses Problem zu lösen, schlug Professor Zhou Zhihua von der Universität Nanjing ein Paradigma namens „Learningware“ vor. Durch die Idee von Modellen und Vorschriften wurde ein Learningware-Markt (heute Learningware-Basissystem genannt) aufgebaut, um Benutzern dies zu ermöglichen Unify Wählen Sie Modelle aus und stellen Sie sie bereit, um Ihren Anforderungen gerecht zu werden. Jetzt hat das Learningware-Paradigma seine erste Open-Source-Basisplattform mit dem Namen Beimingwu eingeführt. Diese Plattform stellt Benutzern eine umfangreiche Modellbibliothek und Bereitstellungstools zur Verfügung, wodurch die Verwendung und Anpassung von Modellen für maschinelles Lernen einfacher und effizienter wird. Durch Beimingwu können Benutzer die Leistungsfähigkeit des maschinellen Lernens besser nutzen, um verschiedene praktische Probleme zu lösen.

Um ein Hochleistungsmodell von Grund auf zu trainieren, sind im klassischen Paradigma des maschinellen Lernens eine große Menge hochwertiger Daten, Expertenerfahrung und Rechenressourcen erforderlich, was zweifellos zeitaufwändig ist , arbeitsintensive und kostspielige Aufgabe. Darüber hinaus gibt es auch einige Probleme bei der Wiederverwendung vorhandener Modelle. Beispielsweise ist es schwierig, ein bestimmtes trainiertes Modell an unterschiedliche Umgebungen anzupassen, und während der schrittweisen Verbesserung eines trainierten Modells kann es zu katastrophalem Vergessen kommen. Deshalb müssen wir einen effizienteren und flexibleren Weg finden, mit diesen Herausforderungen umzugehen.
Datenschutz- und Eigentumsprobleme behindern nicht nur den Erfahrungsaustausch zwischen Entwicklern, sondern schränken auch die Anwendungsfähigkeit großer Modelle in datensensiblen Szenarien ein. Die Forschung konzentriert sich oft auf diese Probleme, in der Praxis treten sie jedoch häufig gleichzeitig auf und beeinflussen sich gegenseitig.
Obwohl das Mainstream-Paradigma für die Entwicklung großer Modelle in den Bereichen Verarbeitung natürlicher Sprache und Computer Vision bemerkenswerte Erfolge erzielt hat, sind einige wichtige Probleme noch nicht gelöst. Zu diesen Problemen gehören unbegrenzte ungeplante Aufgaben und Szenarien, ständige Änderungen in der Umgebung, katastrophales Vergessen, hohe Ressourcenanforderungen, Datenschutzbedenken, lokale Bereitstellungsanforderungen sowie Anforderungen an Personalisierung und Anpassung. Daher ist es eine unpraktische Lösung, für jede potenzielle Aufgabe ein entsprechendes großes Modell zu erstellen. Diese Herausforderungen erfordern, dass wir neue Methoden und Strategien finden, um damit umzugehen, wie z. B. die Einführung flexiblerer und anpassbarerer Modellarchitekturen und den Einsatz von Techniken wie Transferlernen und inkrementellem Lernen, um uns an Veränderungen in verschiedenen Aufgaben und Umgebungen anzupassen. Nur durch die Integration mehrerer Ansätze und Strategien können wir diese komplexen Probleme besser lösen.
Um maschinelle Lernaufgaben zu lösen, schlug Professor Zhou Zhihua von der Universität Nanjing 2016 das Konzept der Learnware vor. Er schuf ein neues Paradigma auf Basis von Learningware und schlug das Learningware-Dock-System als Basisplattform vor. Das Ziel dieses Systems besteht darin, von Entwicklern auf der ganzen Welt eingereichte Modelle für maschinelles Lernen einheitlich zu berücksichtigen und Modellfunktionen zu nutzen, um neue Aufgaben basierend auf den Aufgabenanforderungen potenzieller Benutzer zu lösen. Diese Innovation bringt neue Möglichkeiten und Chancen in den Bereich des maschinellen Lernens.
Der Kernentwurf des Learningware-Paradigmas ist folgender: Für hochwertige Modelle aus unterschiedlichen Aufgabenstellungen ist Learningware eine Grundeinheit mit einem einheitlichen Format. Learningware umfasst das Modell selbst und eine Spezifikation, die die Eigenschaften des Modells in einer Darstellung beschreibt. Entwickler können Modelle frei einreichen, und das Learning Dock-System hilft bei der Erstellung von Spezifikationen und speichert die Lernsoftware im Learning Dock. Bei diesem Prozess müssen Entwickler ihre Trainingsdaten nicht an das Lerndock weitergeben. Zukünftig können Benutzer Anforderungen an das Learningware-Basissystem übermitteln und ihre eigenen maschinellen Lernaufgaben lösen, indem sie Learningware finden und wiederverwenden, ohne ihre eigenen Daten an das Learningware-System weiterzugeben. Dieses Design macht das Teilen von Modellen und das Lösen von Aufgaben effizienter, bequemer und privater.
Um eine vorläufige wissenschaftliche Forschungsplattform für das Learningware-Paradigma zu etablieren, hat das Team von Professor Zhou Zhihua kürzlich Beimingwu entwickelt, das erste Open-Source-Learningware-Basissystem für die zukünftige Learningware-Paradigmenforschung. Das entsprechende Papier wurde veröffentlicht und ist 37 Seiten lang.
Auf technischer Ebene hat das Beimingwu-System durch skalierbares System- und Engine-Architekturdesign sowie umfassende technische Implementierung und Optimierung den Grundstein für die zukünftige akademische softwarebezogene Algorithmen- und Systemforschung gelegt. Darüber hinaus integriert das System auch den Basisalgorithmus für den gesamten Prozess und erstellt ein Basisalgorithmus-Bewertungsszenario. Diese Funktionen ermöglichen es dem System nicht nur, Learningware zu unterstützen, sondern bieten auch die Möglichkeit, eine große Anzahl von Learningware zu hosten und ein Learningware-Ökosystem aufzubauen.
- Papiertitel: Beimingwu: A Learnware Dock System
- Papieradresse: https://arxiv.org/pdf/2401.14427.pdf
- Beimingwu-Homepage: https://bmwu .cloud /
- Open-Source-Warehouse von Beimingwu: https://www.gitlink.org.cn/beimingwu/beimingwu
- Open-Source-Warehouse der Kern-Engine: https://www.gitlink.org.cn/beimingwu /learnware
Basierend auf dem Learningware-Paradigma vereinfacht es die Modellentwicklung für Benutzer, um neue Aufgaben zu lösen: Es erreicht Dateneffizienz, erfordert kein Expertenwissen und gibt keine Originaldaten preis;
-
Schlägt ein vollständiges, einheitliches und skalierbares System vor Design der Engine-Architektur;
Entwicklung eines Open-Source-Lernsoftware-Basissystems mit einer einheitlichen Benutzeroberfläche
Wird für die Implementierung und Bewertung von Basisalgorithmen im gesamten Prozess in verschiedenen Szenarien verwendet.
Überblick über das Learningware-Paradigma
Das Learningware-Paradigma wurde 2016 vom Team von Professor Zhou Zhihua vorgeschlagen und in der Arbeit „Learnware: Kleine Modelle machen Großes“ aus dem Jahr 2024 zusammengefasst und weiterentwickelt. Der vereinfachte Prozess dieses Paradigmas ist in Abbildung 1 unten dargestellt: Für qualitativ hochwertige Modelle für maschinelles Lernen jeglicher Art und Struktur können deren Entwickler oder Besitzer die trainierten Modelle freiwillig an das Learningware-Basissystem (früher bekannt als Learningware-Basissystem) übermitteln. Teilemarkt).
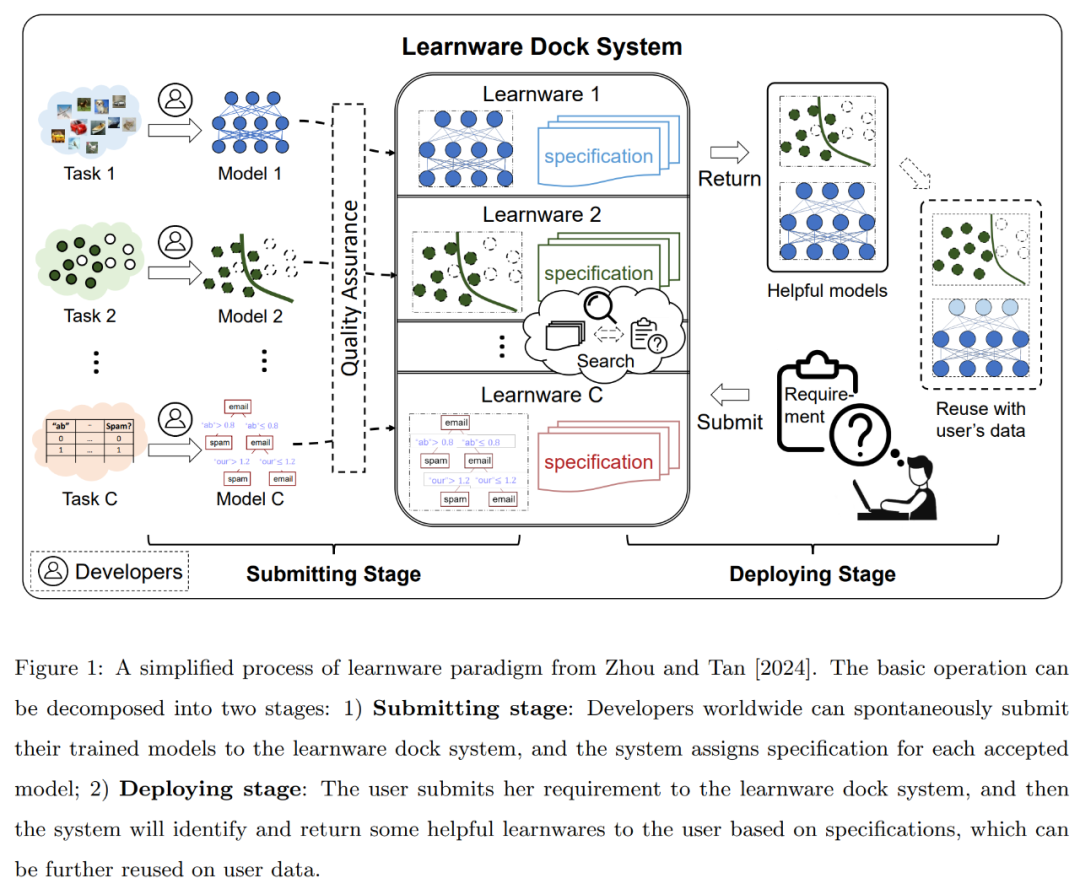
Wie oben eingeführt, schlägt das Learningware-Paradigma vor, ein Learningware-Basissystem zu etablieren, um vorhandene Modelle mit guter Leistung einheitlich aufzunehmen, zu organisieren und zu nutzen und so die Bemühungen aller Communities einheitlich zu nutzen, um Aufgaben neuer Benutzer zu lösen und möglicherweise gleichzeitig einige zu lösen große Probleme, die Anlass zur Sorge geben, darunter fehlende Trainingsdaten und Trainingskompetenzen, katastrophales Vergessen, Schwierigkeiten bei der Erreichung kontinuierlichen Lernens, Datenschutz oder Eigentumsrechte, ungeplante neue Aufgaben in der offenen Welt sowie Duplizierung und Verschwendung von durch Schulungen verursachten Kohlenstoffemissionen usw.
In letzter Zeit haben das Learningware-Paradigma und seine Kernideen immer mehr Aufmerksamkeit erhalten. Aber die Schlüsselfrage und die größte Herausforderung lautet: Wenn man bedenkt, dass ein Lernbasissystem Tausende oder sogar Millionen von Modellen aufnehmen kann, wie kann man dann den Lernteil oder die Lernteile identifizieren und auswählen, die für die Aufgabe eines neuen Benutzers am hilfreichsten sind? Offensichtlich ist die direkte Übermittlung von Benutzerdaten an das System zum Experimentieren teuer und legt die Originaldaten des Benutzers offen.
Das Kerndesign des Lernparadigmas liegt im Protokoll. Neuere Forschungen basieren hauptsächlich auf dem RKME-Protokoll (Reduced Kernel Mean Embedding).
Obwohl die bestehende theoretische und empirische Analyseforschung die Wirksamkeit der protokollbasierten Learningware-Identifizierung bewiesen hat, fehlt die Implementierung des Learningware-Basissystems immer noch und steht vor großen Herausforderungen. Ein neues, auf Protokollen basierendes Architekturdesign ist erforderlich, um mit vielfältig orientierten Realitäten umzugehen -Weltaufgaben und -modelle sowie die einheitliche Suche und Wiederverwendung einer großen Anzahl von Lernmaterialien entsprechend den Benutzeraufgabenanforderungen.
Forscher haben das erste Learningware-Basissystem entwickelt – Beimingwu, das Unterstützung für den gesamten Prozess bietet, einschließlich Einreichung, Usability-Tests, Organisation, Verwaltung, Identifizierung, Bereitstellung und Wiederverwendung von Learningware.
Verwenden Sie Beimingwu, um Lernaufgaben zu lösen
Basierend auf der ersten Systemimplementierung des Learningware-Paradigmas vereinfacht Beimingwu den Prozess der Erstellung maschineller Lernmodelle für neue Aufgaben erheblich. Jetzt können wir das Modell nach dem Prozess des Learningware-Paradigmas erstellen. Dank der einheitlichen Lernsoftwarestruktur, des einheitlichen Architekturdesigns und der einheitlichen Benutzeroberfläche können alle eingereichten Modelle in Beimingwu einheitlich identifiziert und wiederverwendet werden.
Das Spannende ist, dass der Benutzer bei einer neuen Benutzeraufgabe, wenn Beimingwu über die Lernsoftware verfügt, die diese Aufgabe lösen kann, das darin enthaltene hochwertige Modell mit nur wenigen Codezeilen problemlos abrufen und bereitstellen kann, was nicht erforderlich ist eine große Menge an Daten und Expertenwissen und Ihre eigenen Rohdaten werden nicht verloren gehen.
Abbildung 2 unten ist ein Codebeispiel für die Verwendung von Beimingwu zur Lösung von Lernaufgaben.

Abbildung 3 unten zeigt den gesamten Arbeitsablauf bei der Verwendung von Beimingwu, einschließlich der Erstellung statistischer Spezifikationen, der Identifizierung von Lernstücken, dem Laden und der Wiederverwendung. Basierend auf der technischen Implementierung und dem einheitlichen Schnittstellendesign kann jeder Schritt durch eine Zeile Schlüsselcode erreicht werden.

Die Forscher sagten, dass der Modellentwicklungsprozess unter Verwendung des auf Beimingwu basierenden Lernsoftware-Paradigmas die folgenden wesentlichen Vorteile hat:
Erfordert keine große Datenmenge und Rechenressourcen
Erfordert nicht viel Fachwissen im Bereich maschinelles Lernen.
Bietet eine einheitliche und einfache lokale Bereitstellung für verschiedene Modelle.
Datenschutz: Die Originaldaten der Benutzer werden nicht verloren.
Derzeit verfügt Beimingwu im Frühstadium nur über 1.100 Lerntools, die auf Open-Source-Datensätzen basieren, was nicht viele Szenarien abdeckt und seine Fähigkeit, eine große Anzahl spezifischer und unsichtbarer Szenarien zu bewältigen, noch begrenzt ist. Basierend auf dem skalierbaren Architekturdesign kann Beimingwu als Forschungsplattform für Learningware-Paradigmen verwendet werden und bietet eine praktische Algorithmenimplementierung und experimentelles Design für die Learningware-bezogene Forschung.
Gleichzeitig wird die Fähigkeit des Systems zur Lösung von Aufgaben weiter verbessert und die Wiederverwendung vorhandener gut trainierter Modelle durch das System zur Lösung darüber hinausgehender Probleme verbessert, indem es sich auf grundlegende Implementierung und skalierbare Architekturunterstützung verlässt Die Reichweite der Entwickler Die Fähigkeit, neue Aufgaben auf dem ursprünglichen Ziel auszuführen. Die kontinuierliche Weiterentwicklung der Learningware-Basissysteme wird es ihnen in Zukunft ermöglichen, auf eine zunehmende Anzahl von Benutzeraufgaben ohne katastrophales Vergessen zu reagieren und natürlich lebenslanges Lernen zu ermöglichen.
Beimingwu-Design
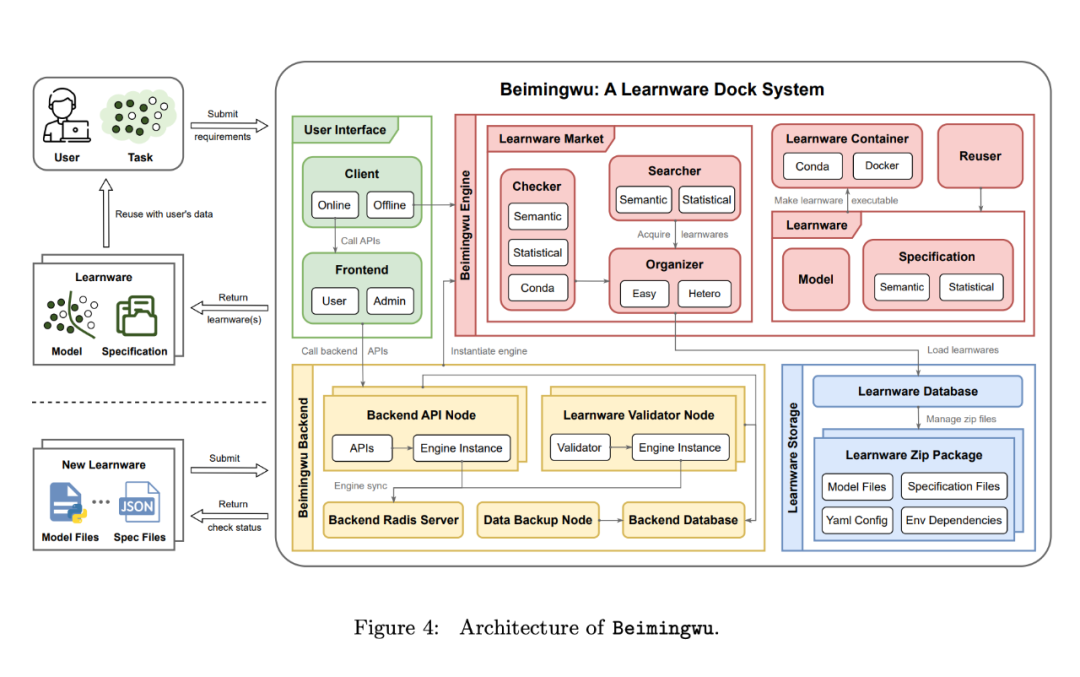
Abschnitt 4 des Papiers stellt das Design des Beimingwu-Systems vor. Wie in Abbildung 4 dargestellt, umfasst das gesamte System vier Ebenen: Lernsoftwarespeicher, System-Engine, Systemhintergrund und Benutzeroberfläche. In diesem Abschnitt wird zunächst ein Überblick über jede Schicht gegeben, dann die Kern-Engine des Systems basierend auf dem Protokolldesign vorgestellt und schließlich die im System implementierten Algorithmen vorgestellt.
Werfen wir zunächst einen Blick auf die Übersicht der einzelnen Ebenen:
Learningware Storage Layer. In Beimingwu werden Lernmaterialien in komprimierten Paketen gespeichert. Diese komprimierten Pakete umfassen hauptsächlich vier Arten von Dateien: Modelldateien, Spezifikationsdateien, Abhängigkeitsdateien für die Modellausführungsumgebung und Konfigurationsdateien für Lernsoftware.
Diese komprimierten Lernsoftware-Pakete werden zentral von der Lernsoftware-Datenbank verwaltet. Die Lernelementtabelle in der Datenbank speichert wichtige Informationen, einschließlich der Lernelement-ID, des Speicherpfads und des Lernelementstatus (z. B. nicht bestätigt und verifiziert). Diese Datenbank bietet eine einheitliche Schnittstelle für die nachfolgenden Kern-Engines von Beimingwu für den Zugriff auf Lerninformationen.
Darüber hinaus kann die Datenbank mit SQLite (geeignet für die einfache Einrichtung in Entwicklungs- und Experimentalumgebungen) oder PostgreSQL (empfohlen für die stabile Bereitstellung in Produktionsumgebungen) erstellt werden, wobei beide die gleiche Schnittstelle verwenden.
Kern-Engine-Schicht. Um die Einfachheit und Struktur von Beimingwu beizubehalten, trennten die Autoren die Kernkomponenten und Algorithmen von einer Vielzahl technischer Details. Diese extrahierten Komponenten können nun als Lernsoftware-Python-Pakete verwendet werden, die den Kernmotor von Beimingwu bilden.
Als Systemkern deckt diese Engine alle Prozesse im Learningware-Paradigma ab, einschließlich der Einreichung von Learningware, Usability-Tests, Organisation, Identifizierung, Bereitstellung und Wiederverwendung. Es läuft unabhängig vom Hintergrund und Vordergrund und bietet eine umfassende Algorithmusschnittstelle zum Erlernen softwarebezogener Aufgaben und Forschungsexperimente.
Darüber hinaus sind Spezifikationen die Kernkomponente der Engine, die jedes Modell aus semantischer und statistischer Sicht darstellt und verschiedene wichtige Komponenten im Lernsoftwaresystem verbindet. Zusätzlich zu den Spezifikationen, die generiert werden, wenn Entwickler Modelle einreichen, kann die Engine auch Systemwissen nutzen, um neue Systemspezifikationen für Lernsoftware zu generieren und so die Verwaltung von Lernsoftware zu verbessern und ihre Fähigkeiten weiter zu charakterisieren.
Bestehende Modellverwaltungsplattformen wie Hugging Face sammeln und hosten Modelle nur passiv, sodass Benutzer selbst über die Fähigkeiten und Relevanz des Modells für die Aufgabe entscheiden können. Im Gegensatz dazu verwendet Beimingwu seine Engine, um ein völlig neues Modell zu erstellen Die Systemarchitektur verwaltet Lernmaterialien proaktiv. Diese aktive Verwaltung beschränkt sich nicht auf die Sammlung und Speicherung. Das System organisiert Lernmaterialien gemäß Protokollen, kann relevante Lernmaterialien entsprechend den Aufgabenanforderungen des Benutzers abgleichen und stellt entsprechende Wiederverwendungs- und Bereitstellungsmethoden für Lernsoftware bereit.
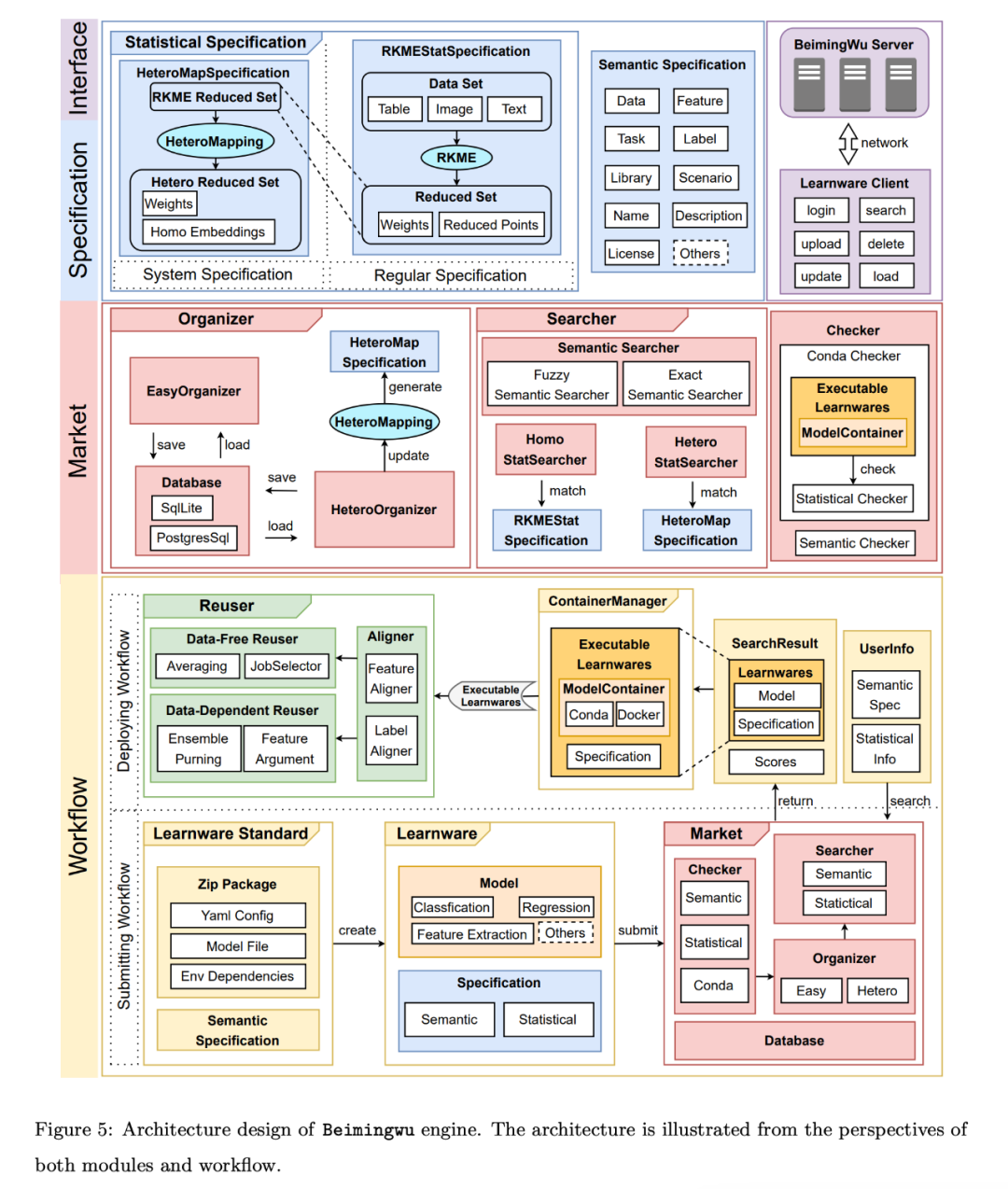
Das Kernmoduldesign ist wie folgt:
System-Backend-Schicht. Um eine stabile Bereitstellung von Beimingwu zu erreichen, entwickelte der Autor das System-Backend basierend auf der Kern-Engine-Schicht. Durch den Entwurf mehrerer Module und einen großen Umfang an technischer Entwicklung ist Beimingwu nun in der Lage, eine stabile Online-Bereitstellung durchzuführen und eine einheitliche Back-End-Anwendungsprogrammschnittstelle für das Front-End und den Client bereitzustellen.
Um einen effizienten und stabilen Betrieb des Systems sicherzustellen, hat der Autor eine Reihe technischer Optimierungen in der Backend-Schicht des Systems durchgeführt, darunter asynchrone Lernsoftwareüberprüfung, hohe Parallelität über mehrere Backend-Knoten hinweg, Berechtigungsverwaltung auf Schnittstellenebene und Backend Datenbank-Lese-Schreib-Trennung und automatische Sicherung der Systemdaten.
Benutzeroberflächenschicht. Um Beimingwu-Benutzern die Verwendung zu erleichtern, entwickelte der Autor die entsprechende Benutzeroberflächenschicht, einschließlich eines netzwerkbasierten Browser-Frontends und eines Befehlszeilen-Clients.
Das webbasierte Frontend bietet sowohl Benutzer- als auch Administratorversionen und stellt verschiedene Benutzerinteraktions- und Systemverwaltungsseiten bereit. Darüber hinaus unterstützt es die Bereitstellung mehrerer Knoten für einen reibungslosen Zugriff auf das Beimingwu-System.
Der Befehlszeilen-Client ist in das Learningware-Python-Paket integriert. Durch den Aufruf der entsprechenden Schnittstelle können Nutzer über das Frontend die Backend-Online-API aufrufen und auf die relevanten Module und Algorithmen der Lernsoftware zugreifen.
Experimentelle Evaluierung
In Abschnitt 5 konstruiert der Autor verschiedene Arten grundlegender experimenteller Szenarien, um Benchmark-Algorithmen für die Spezifikationsgenerierung, Lernware-Identifizierung und Wiederverwendung von Tabellen-, Bild- und Textdaten zu evaluieren.
Experimente mit tabellarischen Daten
An verschiedenen tabellarischen Datensätzen bewerten die Autoren zunächst die Leistung der Identifizierung und Wiederverwendung von Learningware aus dem Learningware-System, das über denselben Funktionsraum wie die Benutzeraufgabe verfügt. Da Tabellenaufgaben in der Regel aus unterschiedlichen Merkmalsräumen stammen, bewerteten die Autoren außerdem auch die Identifizierung und Wiederverwendung von Lernartefakten aus unterschiedlichen Merkmalsräumen.
Homogener Fall
Im homogenen Fall fungieren die 53 Geschäfte im PFS-Datensatz als 53 unabhängige Benutzer. Jeder Store nutzt seine eigenen Testdaten als Benutzeraufgabendaten und verfolgt einen einheitlichen Feature-Engineering-Ansatz. Diese Benutzer können dann das Basissystem nach homogenen Lernelementen durchsuchen, die denselben Funktionsraum wie ihre Aufgabe haben.
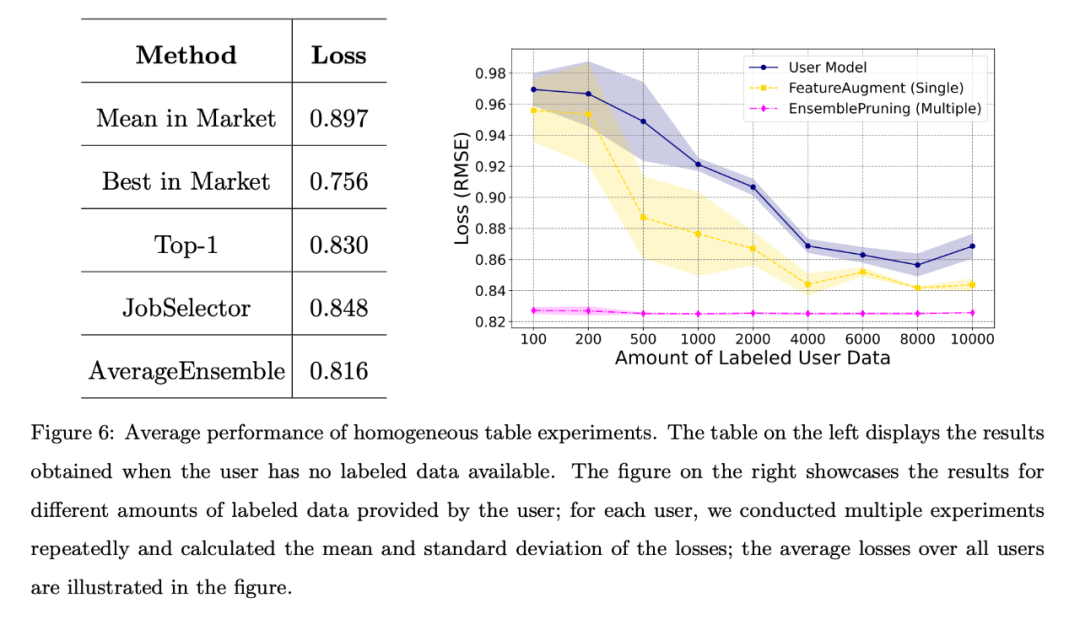
Wenn der Benutzer keine gekennzeichneten Daten hat oder die Menge der gekennzeichneten Daten begrenzt ist, hat der Autor verschiedene Basisalgorithmen verglichen. Der durchschnittliche Verlust aller Benutzer ist in Abbildung 6 dargestellt. Die linke Tabelle zeigt, dass der datenfreie Ansatz viel besser ist als die zufällige Auswahl und Bereitstellung einer Lernware vom Markt. Das rechte Diagramm zeigt, dass die Identifizierung und Wiederverwendung einzelner oder mehrerer Lernware besser ist als die vom Benutzer trainierte Modelle. Bessere Leistung.
Heterogene Fälle
Basierend auf der Ähnlichkeit zwischen Software auf dem Markt und Benutzeraufgaben können heterogene Fälle weiter in verschiedene Feature-Engineering- und verschiedene Aufgabenszenarien unterteilt werden.
Unterschiedliche Feature-Engineering-Szenarien: Die auf der linken Seite von Abbildung 7 gezeigten Ergebnisse zeigen, dass die Lernsoftware im System auch dann eine starke Leistung zeigen kann, wenn dem Benutzer Anmerkungsdaten fehlen, insbesondere die AverageEnsemble-Methode, die mehrere Lernsoftware wiederverwendet.
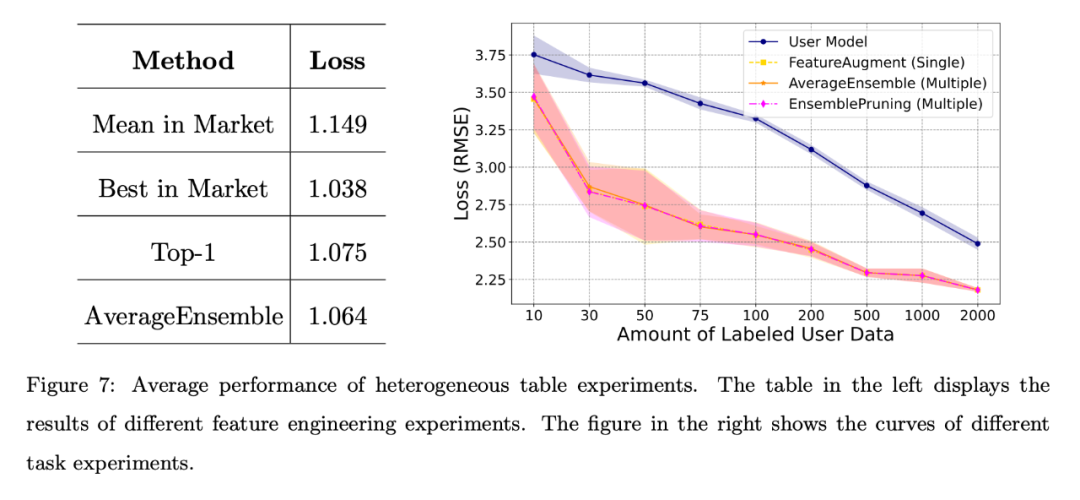
Verschiedene Missionsszenarien. Die rechte Seite von Abbildung 7 zeigt die Verlustkurven des vom Benutzer selbst trainierten Modells und mehrerer Methoden zur Wiederverwendung von Lernware. Offensichtlich ist die experimentelle Überprüfung heterogener Lernkomponenten von Vorteil, wenn die Menge der vom Benutzer kommentierten Daten begrenzt ist, und hilft dabei, sich besser an den Funktionsraum des Benutzers anzupassen.
Experimente mit Bild- und Textdaten
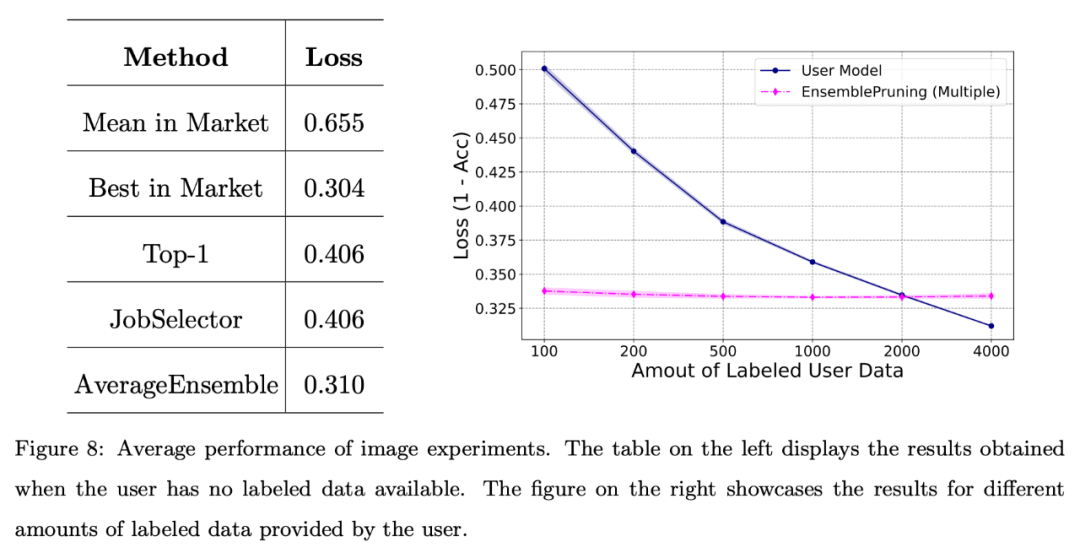
Darüber hinaus führte der Autor eine grundlegende Bewertung des Systems anhand von Bilddatensätzen durch.
Abbildung 8 zeigt, dass die Nutzung eines Lernbasissystems zu einer guten Leistung führen kann, wenn Benutzer mit einem Mangel an annotierten Daten konfrontiert sind oder nur über eine begrenzte Datenmenge (weniger als 2000 Instanzen) verfügen.
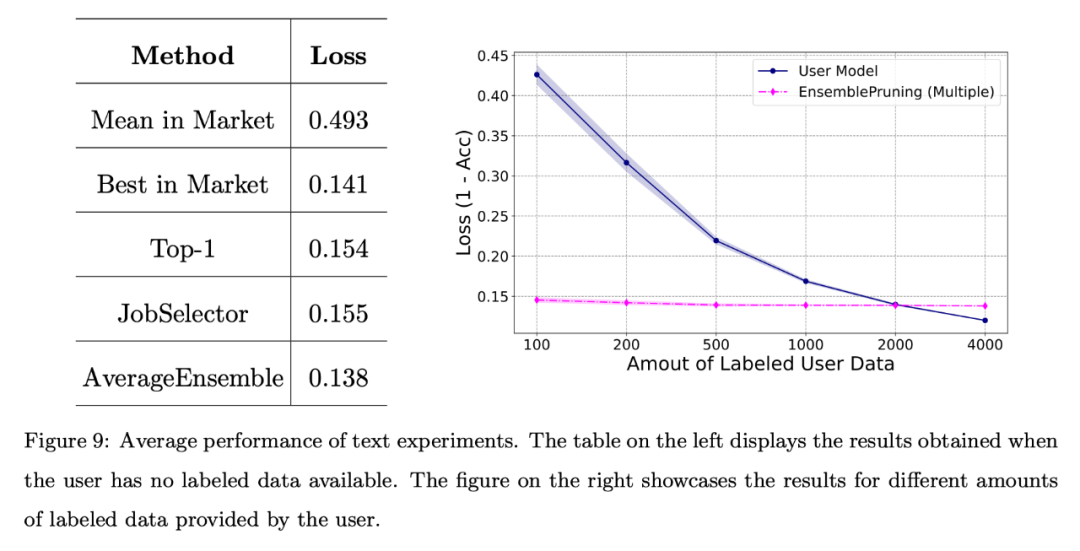
Abschließend führte der Autor eine grundlegende Bewertung des Systems anhand eines Benchmark-Textdatensatzes durch. Feature-Space-Ausrichtung über einen einheitlichen Feature-Extraktor.
Die Ergebnisse sind in Abbildung 9 dargestellt. Auch wenn keine Anmerkungsdaten bereitgestellt werden, ist die durch Lernware-Identifizierung und -Wiederverwendung erzielte Leistung mit der besten Lernware im System vergleichbar. Darüber hinaus führte die Verwendung des Lernbasissystems zu etwa 2.000 Stichproben weniger im Vergleich zum Training des Modells von Grund auf.
Weitere Forschungsdetails finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonIm Zeitalter der großen Modelle beschäftigt sich NTU Zhou Zhihua intensiv mit dem Studium von Software, und seine neueste Arbeit ist online. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wo ist die Adresse der World VR Industry Conference?
- Um die Entwicklung der 5G-Technologie zu beschleunigen, wurde die weltweit erste 5G-RedCap-Industrieallianz gegründet
- Mit dem „Exhibition Express' erkundet der Qingdao Artificial Intelligence Industrial Park neue Wege, um Investitionen anzuziehen
- Leitartikel|Der Bedarf an Rechenleistung explodiert unter dem Boom großer KI-Modelle: Lingang will eine zig-Milliarden-Industrie aufbauen, und SenseTime wird der „Kettenmeister'
- Lassen Sie uns gemeinsam das digitale Guangxi aufbauen und gemeinsam in eine digitale Zukunft gehen! Die ökologische Konferenz der Industrie für künstliche Intelligenz in Guangxi Kunpeng Shengteng 2023 wurde erfolgreich abgehalten