
Heim >Technologie-Peripheriegeräte >KI >Kuaishou und Beida multimodale Großmodelle: Bilder sind Fremdsprachen, vergleichbar mit dem Durchbruch von DALLE-3
Kuaishou und Beida multimodale Großmodelle: Bilder sind Fremdsprachen, vergleichbar mit dem Durchbruch von DALLE-3

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-30 16:36:28834Durchsuche
Dynamische visuelle Wortsegmentierung vereint Grafik- und Textdarstellung. Kuaishou und die Peking-Universität haben gemeinsam das Basismodell LaVIT vorgeschlagen, um die Liste der multimodalen Verständnis- und Generierungsaufgaben zu erweitern.
Aktuelle groß angelegte Sprachmodelle wie GPT, LLaMA usw. haben im Bereich der Verarbeitung natürlicher Sprache erhebliche Fortschritte gemacht und sind in der Lage, komplexe Textinhalte zu verstehen und zu generieren. Haben wir jedoch darüber nachgedacht, dieses leistungsstarke Verständnis und die Generierungsfähigkeit auf multimodale Daten zu übertragen? Dadurch können wir große Mengen an Bildern und Videos problemlos verstehen und reich illustrierte Inhalte erstellen. Um diese Vision zu verwirklichen, haben Kuaishou und die Peking-Universität kürzlich gemeinsam ein neues multimodales Großmodell namens LaVIT entwickelt. LaVIT setzt diese Idee schrittweise in die Realität um und wir freuen uns auf die weitere Entwicklung.

Papiertitel: Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization
Papieradresse: https://arxiv.org/abs/2309.04669
Codemodelladresse: https: //github.com/jy0205/LaVIT
Modellübersicht
LaVIT ist ein neues allgemeines multimodales Basismodell, ähnlich einem Sprachmodell, das visuelle Inhalte verstehen und generieren kann. Das Trainingsparadigma von LaVIT basiert auf der erfolgreichen Erfahrung großer Sprachmodelle und verwendet einen autoregressiven Ansatz, um das nächste Bild- oder Text-Token vorherzusagen. Nach dem Training kann LaVIT als multimodale universelle Schnittstelle dienen, die ohne weitere Feinabstimmung multimodale Verständnis- und Generierungsaufgaben ausführen kann. LaVIT verfügt beispielsweise über die folgenden Funktionen:
LaVIT ist ein fortschrittliches Bildgenerierungsmodell, das auf der Grundlage von Textaufforderungen hochwertige Bilder mit mehreren Seitenverhältnissen und hoher Ästhetik erzeugen kann. Die Bilderzeugungsfunktionen von LaVIT schneiden im Vergleich zu hochmodernen Bilderzeugungsmodellen wie Parti, SDXL und DALLE-3 gut ab. Es kann effektiv eine qualitativ hochwertige Text-zu-Bild-Generierung erreichen und Benutzern mehr Auswahlmöglichkeiten und ein besseres visuelles Erlebnis bieten.

Bildgenerierung basierend auf multimodalen Eingabeaufforderungen: Da in LaVIT Bilder und Texte einheitlich als diskretisierte Token dargestellt werden, kann es mehrere modale Kombinationen (z. B. Text, Bild + Text, Bild + Bild) als Eingabeaufforderung akzeptieren ohne Feinabstimmung das entsprechende Bild zu erzeugen.

Bildinhalt verstehen und Fragen beantworten: Bei einem Eingabebild ist LaVIT in der Lage, den Bildinhalt zu lesen und seine Semantik zu verstehen. Das Modell kann beispielsweise Bildunterschriften für Eingabebilder bereitstellen und entsprechende Fragen beantworten.

Methodenübersicht
Die Modellstruktur von LaVIT ist in der folgenden Abbildung dargestellt. Der gesamte Optimierungsprozess umfasst zwei Phasen:
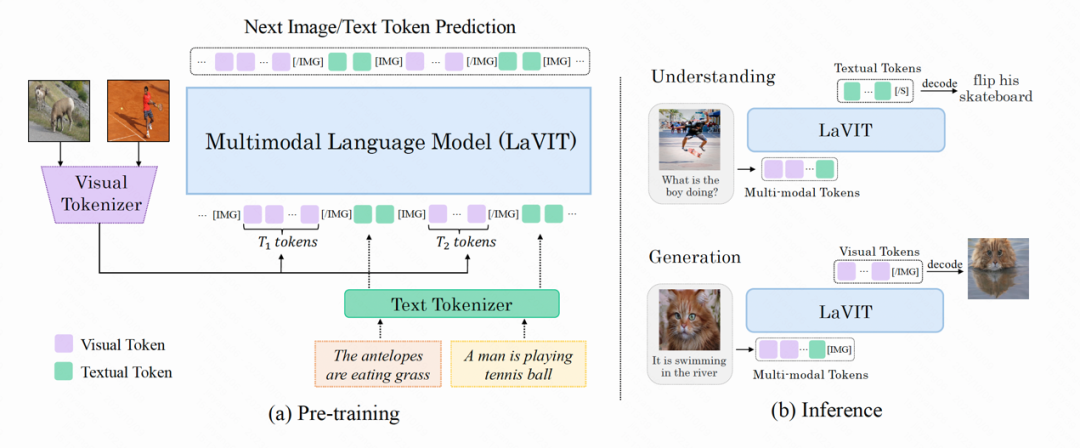
Abbildung: Die Gesamtarchitektur des LaVIT-Modells
Phase 1: Dynamischer visueller Tokenizer
Um visuelle Inhalte wie natürliche Sprache verstehen und generieren zu können, führt LaVIT einen gut gestalteten visuellen Tokenizer ein, um visuelle Inhalte (kontinuierliche Signale) in Token-Sequenzen wie Text umzuwandeln Wie Fremdsprachen, die LLM verstehen kann. Der Autor ist der Ansicht, dass der visuelle Tokenizer (Tokenizer) die folgenden zwei Merkmale aufweisen sollte, um eine einheitliche Vision und Sprachmodellierung zu erreichen:
Diskretisierung: Visuelle Token sollten als diskretisierte Formen wie Text dargestellt werden. Dabei wird eine einheitliche Darstellungsform für die beiden Modalitäten verwendet, was dazu beiträgt, dass LaVIT denselben Klassifizierungsverlust für die multimodale Modellierungsoptimierung unter einem einheitlichen autoregressiven generativen Trainingsrahmen verwendet.
Dynamischeifizierung: Im Gegensatz zu Text-Tokens weisen Bild-Patches erhebliche gegenseitige Abhängigkeiten auf, sodass es relativ einfach ist, einen Patch von einem anderen abzuleiten. Daher verringert diese Abhängigkeit die Wirksamkeit des Optimierungsziels der ursprünglichen LLM-Vorhersage für das nächste Token. LaVIT schlägt vor, die Redundanz zwischen visuellen Patches durch die Verwendung von Token-Merging zu reduzieren, das eine dynamische Anzahl visueller Token basierend auf der unterschiedlichen semantischen Komplexität verschiedener Bilder codiert. Auf diese Weise verbessert die Verwendung der dynamischen Token-Kodierung für Bilder unterschiedlicher Komplexität die Effizienz des Vortrainings weiter und vermeidet redundante Token-Berechnungen.
Die folgende Abbildung ist die von LaVIT vorgeschlagene visuelle Wortsegmentierungsstruktur:
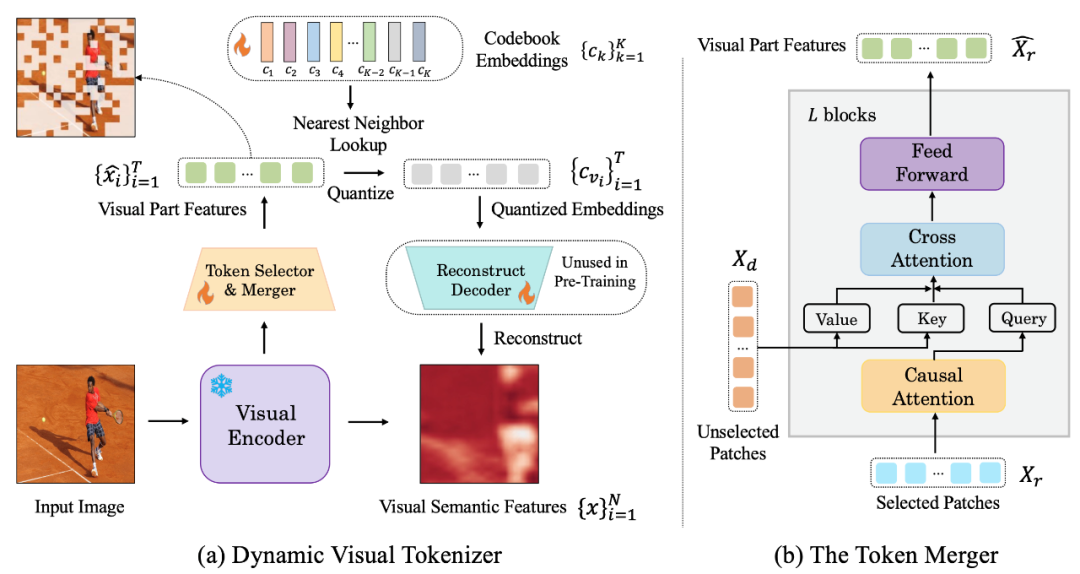
Abbildung: (a) Dynamischer visueller Token-Generator (b) Token-Combiner
Der dynamische visuelle Tokenizer umfasst einen Token-Selektor und einen Token-Combiner. Wie in der Abbildung gezeigt, wird der Token-Selektor verwendet, um die informativsten Bildblöcke auszuwählen, während die Token-Zusammenführung die Informationen dieser nicht informativen visuellen Blöcke in die beibehaltenen Token komprimiert, um die Zusammenführung redundanter Token zu erreichen. Der gesamte dynamische visuelle Wortsegmentierer wird trainiert, indem die semantische Rekonstruktion des Eingabebilds maximiert wird.
Token-Selektor
Der Token-Selektor empfängt N Bildblock-Level-Funktionen als Eingabe. Sein Ziel besteht darin, die Wichtigkeit jedes Bildblocks zu bewerten und den Block mit der höchsten Informationsmenge auszuwählen, um die gesamte Semantik darzustellen. Um dieses Ziel zu erreichen, wird ein leichtes Modul bestehend aus mehreren MLP-Schichten verwendet, um die Verteilung π vorherzusagen. Durch Abtasten aus der Verteilung π wird eine binäre Entscheidungsmaske generiert, die angibt, ob der entsprechende Bildbereich beibehalten werden soll.
Token-Combiner
Token-Combiner unterteilt N Bildblöcke in zwei Gruppen: X_r beibehalten und X_d gemäß der generierten Entscheidungsmaske verwerfen. Im Gegensatz zum direkten Verwerfen von X_d kann der Token-Combiner die detaillierte Semantik des Eingabebilds maximal beibehalten. Der Token-Combiner besteht aus L gestapelten Blöcken, von denen jeder eine kausale Selbstaufmerksamkeitsschicht, eine Queraufmerksamkeitsschicht und eine Feed-Forward-Schicht enthält. In der kausalen Selbstaufmerksamkeitsschicht achtet jedes Token in X_r nur auf sein vorheriges Token, um die Konsistenz mit der Text-Token-Form in LLM sicherzustellen. Diese Strategie schneidet im Vergleich zur bidirektionalen Selbstaufmerksamkeit besser ab. Die Cross-Attention-Schicht nimmt das beibehaltene Token X_r als Abfrage und führt die Token in X_d basierend auf ihrer semantischen Ähnlichkeit zusammen.
Phase 2: Einheitliches generatives Vortraining
Die vom visuellen Wortsegmentierer verarbeiteten visuellen Token werden mit den Text-Tokens verbunden, um eine multimodale Sequenz als Eingabe während des Trainings zu bilden. Um die beiden Modalitäten zu unterscheiden, fügt der Autor am Anfang und Ende der Bild-Token-Sequenz spezielle Token ein: [IMG] und [/IMG], die verwendet werden, um den Anfang und das Ende des visuellen Inhalts anzuzeigen. Um Text und Bilder generieren zu können, verwendet LaVIT zwei Bild-Text-Verbindungsformen: [Bild, Text] und [Text;
Für diese multimodalen Eingabesequenzen verwendet LaVIT einen einheitlichen, autoregressiven Ansatz, um die Wahrscheinlichkeit jeder multimodalen Sequenz für das Vortraining direkt zu maximieren. Diese vollständige Vereinheitlichung von Darstellungsraum und Trainingsmethoden hilft LLM, multimodale Interaktion und Ausrichtung besser zu erlernen. Nach Abschluss des Vortrainings ist LaVIT in der Lage, Bilder wahrzunehmen und Bilder wie Text zu verstehen und zu generieren.
Experimente
Multimodales Null-Shot-Verstehen
LaVIT hat modernste Ergebnisse bei multimodalen Zero-Shot-Verständnisaufgaben wie der Generierung von Bildunterschriften (NoCaps, Flickr30k) und der visuellen Beantwortung von Fragen (VQAv2) erzielt , OKVQA, GQA, VizWiz) Führende Leistung.
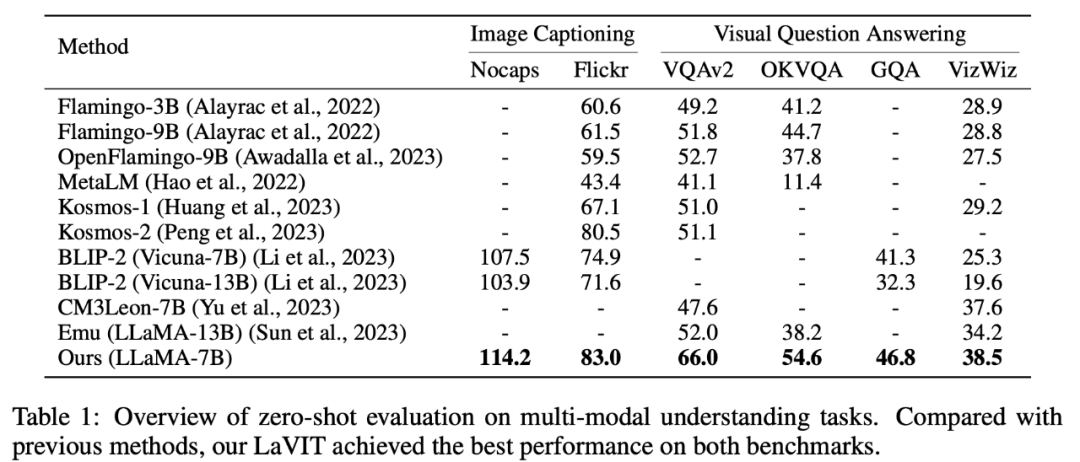
Tabelle 1 Zero-Shot multimodale Verständnisaufgabenbewertung
Zero-Shot multimodale Generierung
Da in diesem Experiment der vorgeschlagene visuelle Tokenizer das Bild als Diskretisierungstoken darstellen kann, LaVIT verfügt über die Fähigkeit, Bilder zu synthetisieren, indem durch Autoregression textähnliche visuelle Token generiert werden. Der Autor führte eine quantitative Bewertung der Bildsyntheseleistung des Modells unter Textbedingungen ohne Stichprobe durch. Die Vergleichsergebnisse sind in Tabelle 2 aufgeführt.
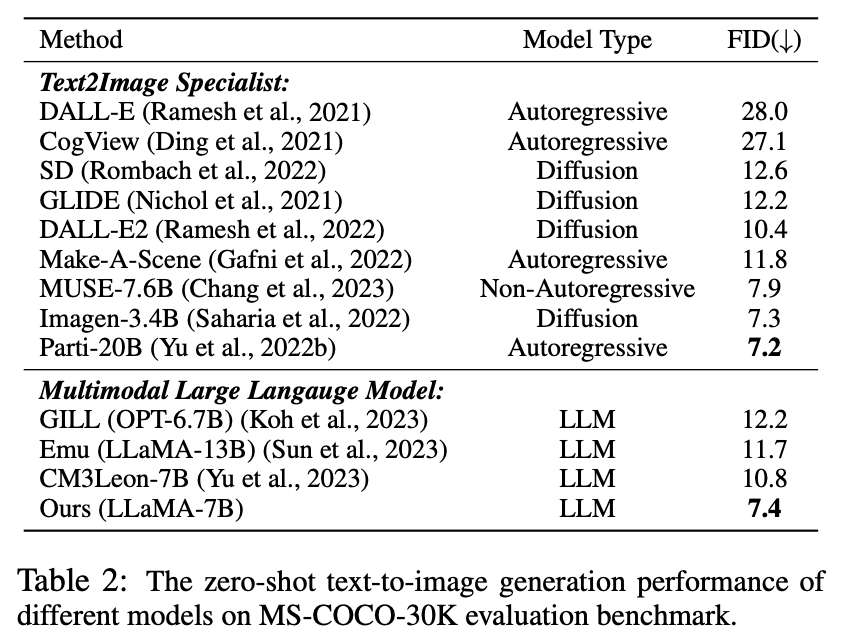
Tabelle 2 Zero-Shot-Text-zu-Bild-Generierungsleistung verschiedener Modelle
Wie aus der Tabelle ersichtlich ist, übertrifft LaVIT alle anderen multimodalen Sprachmodelle. Im Vergleich zu Emu erzielt LaVIT weitere Verbesserungen bei kleineren LLM-Modellen und demonstriert hervorragende visuell-verbale Ausrichtungsfähigkeiten. Darüber hinaus erreicht LaVIT eine vergleichbare Leistung wie der hochmoderne Text-zu-Bild-Experte Parti und verbraucht dabei weniger Trainingsdaten.
Multimodale Erzeugung von Aufforderungsbildern
LaVIT ist in der Lage, mehrere modale Kombinationen nahtlos als Aufforderungen zu akzeptieren und entsprechende Bilder ohne Feinabstimmung zu generieren. LaVIT generiert Bilder, die den Stil und die Semantik eines bestimmten multimodalen Hinweises genau widerspiegeln. Und es kann das ursprüngliche Eingabebild mit multimodalen Hinweisen der Eingabe modifizieren. Herkömmliche Bilderzeugungsmodelle wie Stable Diffusion können diese Fähigkeit ohne zusätzliche fein abgestimmte Downstream-Daten nicht erreichen.

Beispiel für multimodale Bildgenerierungsergebnisse
Qualitative Analyse
Wie in der Abbildung unten gezeigt, kann der dynamische Tokenizer von LaVIT dynamisch die informativsten Bildblöcke basierend auf dem Bildinhalt auswählen und der gelernte Code kann eine visuelle Codierung mit Semantik auf hoher Ebene erzeugen.

Visualisierung des dynamischen visuellen Tokenizers (links) und des erlernten Codebuchs (rechts)
Zusammenfassung
Die Entstehung von LaVIT bietet ein innovatives Paradigma für die Verarbeitung multimodaler Aufgaben und erbt das Erfolgreiche autoregressives generatives Lernparadigma von LLM durch Verwendung eines dynamischen visuellen Tokenizers, um Vision und Sprache in einer einheitlichen diskreten Token-Darstellung darzustellen. Durch die Optimierung unter einem einheitlichen Generierungsziel kann LaVIT Bilder wie eine Fremdsprache behandeln und sie wie Text verstehen und generieren. Der Erfolg dieser Methode liefert neue Inspiration für die Entwicklungsrichtung zukünftiger multimodaler Forschung und nutzt die leistungsstarken Argumentationsfähigkeiten von LLM, um neue Möglichkeiten für ein intelligenteres und umfassenderes multimodales Verständnis und eine bessere Generierung zu eröffnen.
Das obige ist der detaillierte Inhalt vonKuaishou und Beida multimodale Großmodelle: Bilder sind Fremdsprachen, vergleichbar mit dem Durchbruch von DALLE-3. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wo ist die Adresse der World VR Industry Conference?
- Der Industriepark auf Dorfebene Foshan wird wiedergeboren: Die Auf- und Abstiegstreppen in der intelligenten Roboterfertigungsstadt sind die vor- und nachgelagerten, und der Industriepark ist die Industriekette
- Leitartikel|Der Bedarf an Rechenleistung explodiert unter dem Boom großer KI-Modelle: Lingang will eine zig-Milliarden-Industrie aufbauen, und SenseTime wird der „Kettenmeister'
- Branchenallianz für Gehirn-Computer-Schnittstellen veröffentlicht zehn Schlüsseltechnologien für Gehirn-Computer-Schnittstellen
- Die 2023 Artificial Intelligence Computing Conference (AICC) fand in Peking statt und konzentrierte sich auf branchenrelevante Diskussionen über groß angelegte Modelle und intelligente Rechenleistung