
Heim >System-Tutorial >LINUX >Forschung zur Optimierung der SQL-Effizienz
Forschung zur Optimierung der SQL-Effizienz

- 王林nach vorne
- 2024-01-28 08:09:051131Durchsuche
Dies ist ein Fall, den Herr Chen Hongyi (Old K) auf der MOORACLE-Konferenz in Shanghai im August 2016 geteilt hat. Durch das Umschreiben einer Merge-SQL in plsql wurde die Ausführungseffizienz erheblich verbessert. Als Tiger Liu diesen Fall sah, bemerkte er zunächst nicht, wie viele Datensätze in jeder Tabelle im Ausführungsplan angezeigt wurden. Er glaubte nicht, dass die Methode zum Umschreiben von plsql effizienter sei als die Methode zum Schreiben analytischer Funktionen Mehrere E-Mail-Diskussionen mit Lehrer Chen. Erst später habe ich mir den Ausführungsplan genauer angesehen.
Die ursprüngliche SQL lautet wie folgt:mit t_customer c zusammenführen
(
wählen Sie a.cstno, a.amount aus t_trade a,
(wählen Sie cstno,max(trade_date) trade_date aus t_trade
Gruppe von cstno) b
wobei a.cstno = b.cstno und a.trade_date=b.trade_date
)m
on(c.cstno = m.cstno)
Wenn es passt, dann
update set c.amount = m.amount;
Diese SQL aktualisiert den letzten Verbrauchsbetrag in der Tabelle mit den Benutzertransaktionsdetails (t_trade) mithilfe der Zusammenführungsoperation in das Verbrauchsbetragsfeld in der Benutzerinformationstabelle (t_customer).
Ausführungsplan:

Tiger Liu Hinweis:
Bevor Sie die Schreibmethode analytischer Funktionen beherrschen, ist der rote Teil von SQL eine übliche Methode zum Schreiben anderer Feldinformationen nach der Gruppierung, was auch die Hauptursache für die schlechte Ausführungseffizienz dieser SQL ist.
Es gibt eine weitere versteckte Gefahr in der ursprünglichen SQL: Wenn das maximale Handelsdatum, das einer bestimmten cstno von t_trade entspricht, wiederholt wird, meldet diese SQL einen ORA-30926-Fehler und kann nicht ausgeführt werden.
Wenn Sie sich den Ausführungsplan (die tatsächlichen Datenvolumeninformationen der beiden Tabellen) nicht genau ansehen, besteht die übliche Optimierungsmethode für diese Art von SQL darin, Analysefunktionen zum Umschreiben zu verwenden:
Methode 1 umschreiben:mit t_customer c zusammenführen
(
Wählen Sie eine CST-Nr. und einen Betrag aus
(Handelsdatum, CST-Nr., Betrag auswählen
row_number()over(partition by cstno order by trade_date desc) RNO from t_trade)a
wo RNO=1
) m
on(c.cstno = m.cstno)
Wenn es passt, dann
update set c.amount = m.amount;
Diese Umschreibungsmethode ist viel effizienter als die ursprüngliche SQL, und es wird kein Problem mit wiederholten Fehlern für das maximale Handelsdatum geben, das einer bestimmten cstno entspricht.
Lehrer Chen verwendete jedoch nicht die Umschreibemethode der Analysefunktion, sondern schrieb das SQL aufgrund des großen Unterschieds im Datenvolumen zwischen den beiden Tabellen in ein effizienteres plsql um:
Methode 2 umschreiben:deklarieren
Vamount-Nummer;
beginnen
für v in (wählen Sie * aus t_customer)
Schleife
Betrag in Betrag umwandeln von
(Betrag aus t_trade auswählen, wobei cstno=v.cstno order by trade_date absteigend ist)
wo rownum
update t_customer set amount = vamount where cstno=v.cstno;
Endschleife
verpflichten;
Ende;
/
Gemäß dem ursprünglichen SQL-Ausführungsplan wissen wir, dass die Anzahl der Datensätze in der Tabelle t_customer relativ gering ist, nur mehr als 1.000, während die Tabelle t_trade 10 Millionen Datensätze enthält, mit einem Verhältnis von 1:10.000 (ich weiß nicht). wissen, ob es sich um echte Daten oder Testdaten handelt, es nur mehr als 1.000 Benutzer gibt und ein Benutzer durchschnittlich 10.000 Verbrauchsangaben hat, was nicht wie echte Daten aussieht).
In einem solchen Sonderfall, in dem die Daten zwischen den beiden Tabellen sehr unterschiedlich sind, ist die Plsql-Schreibmethode tatsächlich effizienter als die Schreibmethode für analytische Funktionen. Diese Umschreibung ist sehr clever.
Lassen Sie uns die Vor- und Nachteile dieser beiden Umschreibungen analysieren:1. Die Umschreibemethode von plsql ist geeignet, wenn die Tabelle t_customer relativ klein ist und das Verhältnis der Anzahl der Datensätze in den Tabellen t_customer und t_trade relativ groß ist, sodass die Ausführungseffizienz höher ist als das Umschreiben der Analysefunktion . Wenn in diesem Beispiel die Anzahl der Datensätze in der Tabelle t_customer 100.000 beträgt, ist die Schreibweise der Analysefunktion Dutzende bis Hundertfache schneller als die Schreibweise von plsql.
3. Voraussetzung für dieses Umschreiben von plsql ist, dass ein gemeinsamer Index der beiden Felder cstno + trade_date der t_trade-Tabelle vorhanden sein muss. Das Umschreiben analytischer Funktionen erfordert keine Indexunterstützung.
4. Bei Tabellen mit mehreren zehn Millionen Datensätzen wie t_trade kann die Schreibmethode durch die Aktivierung der Parallelität beschleunigt werden. Wenn Sie die Effizienz beim Neuschreiben von plsql verbessern möchten, müssen Sie die t_customer-Tabelle zuerst nach cstno gruppieren Verwenden Sie mehrere Sitzungen, um es gleichzeitig auszuführen.
Mal sehen, ob Lehrer Chens Plsql mit einem einzigen SQL implementiert werden kann. Der SQL-Code lautet wie folgt:
mit t_customer c zusammenführen
(
wählen Sie tc.cstno,
(Menge auswählen
von t_trade td1
wobei td1.cstno=tc.cstno und td1.trade_date = (select max(trade_date) from t_trade td2 where tc.cstno = td2.cstno) and rownum=1 ) as amount
von t_customer tc
)m
on(c.cstno = m.cstno)
Wenn es passt, dann
update set c.amount = m.amount;
Der Ausführungsplan sieht ungefähr wie folgt aus:
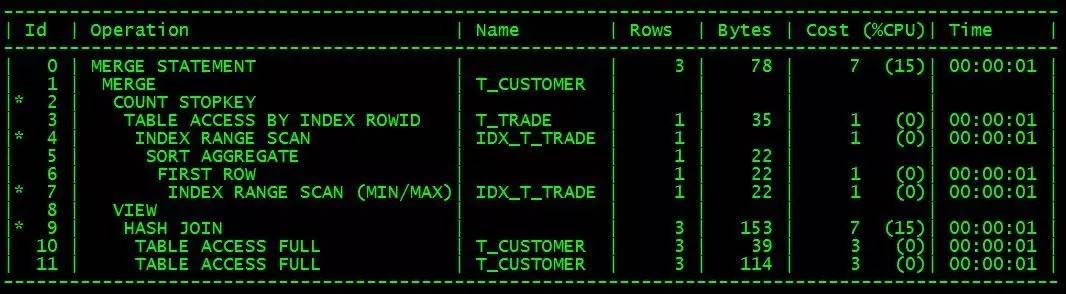
Diese Schreibmethode erfordert außerdem, dass der gemeinsame Index cstno+trade_date (IDX_T_TRADE) in der Tabelle t_trade vorhanden ist, und das Datenvolumen der Tabelle T_customer ist viel geringer als das von T_trade.
Laut Ausführungsplan sollte die Ausführungseffizienz dieses SQL mit der Effizienz beim Schreiben von Plsql vergleichbar sein.
Zusammenfassung:SQL-Optimierung, zusätzlich zur Vermeidung ineffizienten SQL-Schreibens, hängt hauptsächlich von der Datenmenge und der Datenverteilung der Tabelle ab. In einigen Fällen zeigt die Umschreibmethode von plsql eine höhere Effizienz Die Effizienz ist möglicherweise nicht so gut wie beim ursprünglichen SQL. Es lohnt sich jedoch, von den Optimierungsideen zu lernen.
Die Art und Weise, wie die Analysefunktion neu geschrieben wird, ist unabhängig von der Verteilung der Daten effizienter und vielseitiger als das ursprüngliche SQL.
Es sollte noch viele Entwickler und Datenbankadministratoren geben, die SQL verwenden, bevor dieses Beispiel neu geschrieben wurde. Nachdem wir verstanden haben, wie die Analysefunktion verwendet wird, sollte die ineffiziente Art und Weise, die ursprüngliche SQL zu schreiben, vollständig aufgegeben werden.
Das letzte Plsql wird in ein einzelnes SQL umgeschrieben. Die Logik scheint kompliziert und schwer zu verstehen. Es wäre schön, wenn jeder es verstehen würde.
Immer noch derselbe Satz: Es gibt keine eindeutige Formel für die Optimierung, aber das menschliche Gehirn lebt. Nur durch die Beherrschung der Prinzipien kann die SQL-Ausführungseffizienz immer höher werden.
Das obige ist der detaillierte Inhalt vonForschung zur Optimierung der SQL-Effizienz. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Der Unterprozess führt Linux-Befehle stapelweise in Python aus
- Starten Sie den MySQL-Datenbankbetrieb unter einem Linux-System
- Was ist der Befehl zum Öffnen eines Ordners im Linux-System?
- Was ist der Befehl zum Benutzerwechsel unter Linux?
- Wie filtere und klassifiziere ich Protokolle mit Linux-Befehlszeilentools?