
Heim >Technologie-Peripheriegeräte >KI >Die groß angelegte Rangliste der Inferenzkosten, angeführt von Jia Yangqings hoher Effizienz, wird veröffentlicht
Die groß angelegte Rangliste der Inferenzkosten, angeführt von Jia Yangqings hoher Effizienz, wird veröffentlicht

- 王林nach vorne
- 2024-01-26 14:15:34701Durchsuche
„Sind große Modell-APIs ein verlustbringendes Geschäft?“
Mit der Einführung der Technologie für große Sprachmodelle haben viele Technologieunternehmen große Modell-APIs für Entwickler eingeführt. Allerdings kommen wir nicht umhin, uns zu fragen, ob ein auf großen Modellen basierendes Geschäft überlebensfähig ist, insbesondere wenn man bedenkt, dass OpenAI täglich 700.000 US-Dollar verbrennt.
Diesen Donnerstag hat das KI-Startup Martian es sorgfältig für uns berechnet.
Ranking-Link: https://leaderboard.withmartian.com/
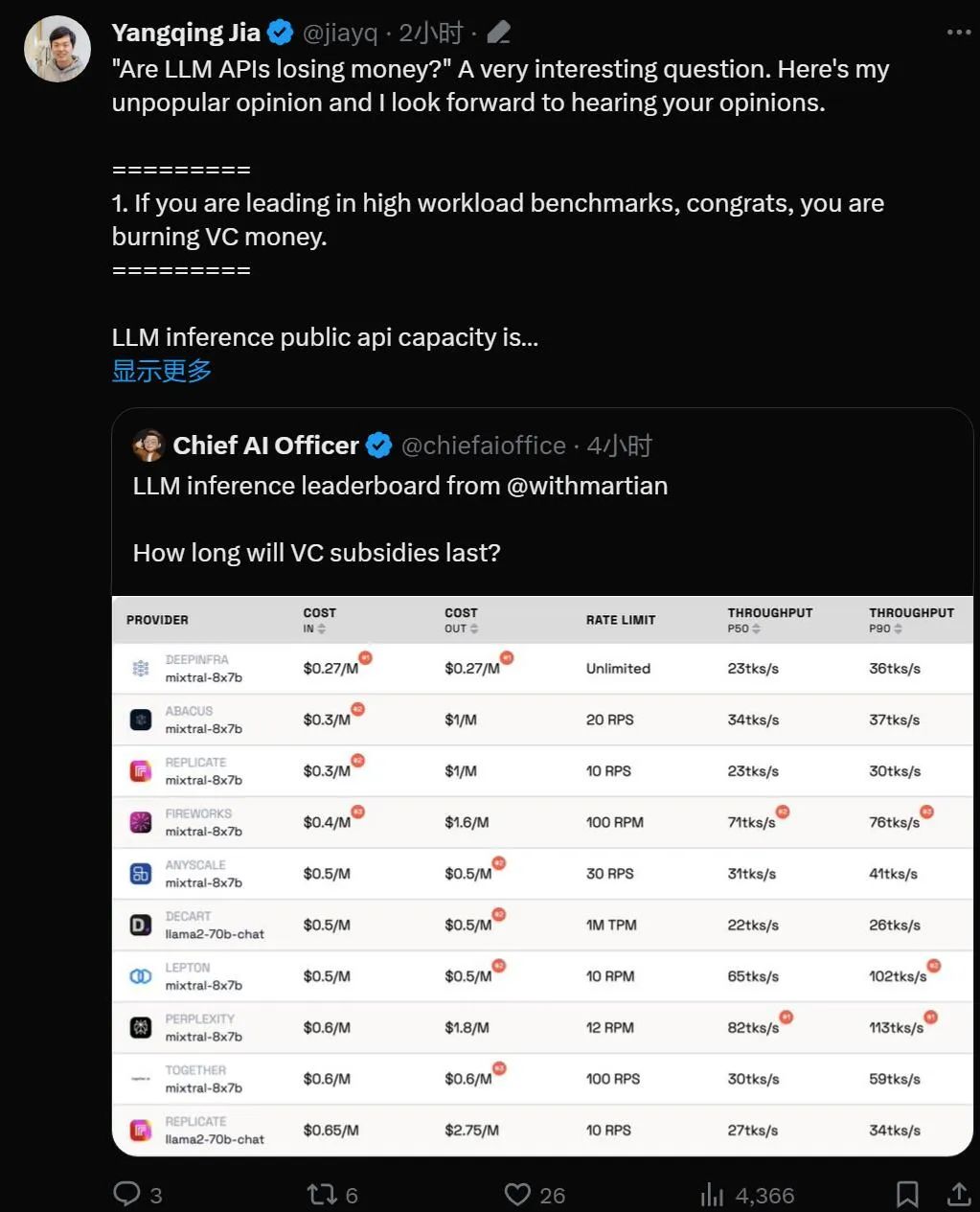
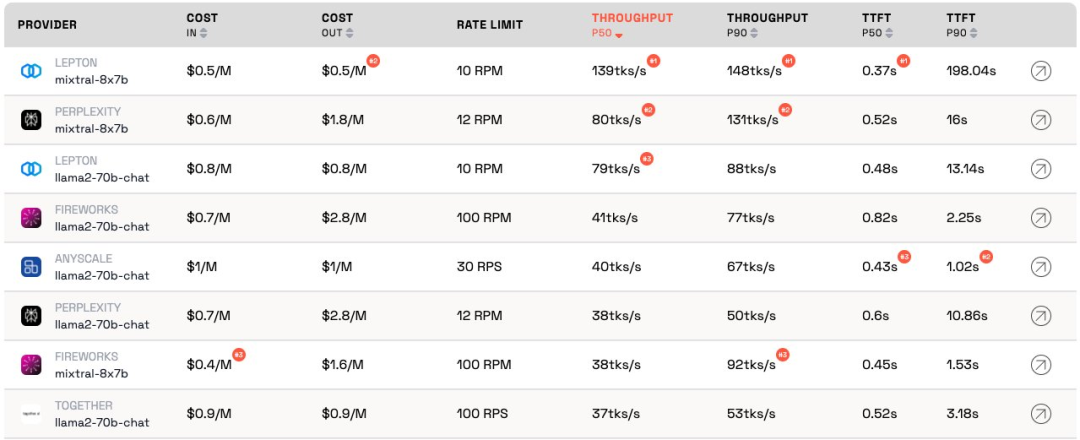
Das LLM Inference Provider Leaderboard ist ein Open-Source-Ranking von API-Inferenzprodukten für große Modelle. Es bewertet die Kosten und Ratengrenzen , Durchsatz und P50- und P90-TTFT für die öffentlichen Endpunkte Mixtral-8x7B und Llama-2-70B-Chat jedes Anbieters Bei den Kosten gibt es erhebliche Unterschiede im Durchsatz und bei der Ratenbegrenzung. Diese Unterschiede übersteigen den 5-fachen Kostenunterschied, den 6-fachen Durchsatzunterschied und noch größere Unterschiede bei den Ratenbegrenzungen. Die Auswahl verschiedener APIs ist für die Erzielung der besten Leistung von entscheidender Bedeutung, auch wenn dies nur ein Teil des Geschäftsbetriebs ist.
Laut aktuellem Ranking weist der von Anyscale bereitgestellte Dienst den besten Durchsatz bei mittlerer Dienstlast von Llama-2-70B auf. Bei großen Servicelasten schnitt Together AI mit P50- und P90-Durchsatz auf Llama-2-70B und Mixtral-8x7B am besten ab.
Darüber hinaus zeigte Jia Yangqings LeptonAI den besten Durchsatz bei der Bewältigung kleiner Aufgabenlasten mit kurzen Eingabe- und langen Ausgabe-Cues. Sein P50-Durchsatz von 130 tks/s ist der schnellste unter den Modellen, die derzeit von allen Herstellern auf dem Markt angeboten werden.
Jia Yangqing, ein bekannter KI-Wissenschaftler und Gründer von Lepton AI, kommentierte unmittelbar nach der Veröffentlichung der Rangliste. Mal sehen, was er sagte.
Jia Yangqing erläuterte zunächst den aktuellen Stand der Branche im Bereich der künstlichen Intelligenz, bekräftigte dann die Bedeutung von Benchmark-Tests und wies schließlich darauf hin, dass LeptonAI Benutzern dabei helfen wird, die beste grundlegende KI-Strategie zu finden. 
1. Große Modell-API „verbrennt Geld“
Wenn das Modell in Benchmarks mit hoher Arbeitsbelastung führt, dann herzlichen Glückwunsch, es verbrennt „Geld“.
LLM Über die Kapazität einer öffentlichen API nachzudenken ist wie die Führung eines Restaurants: Sie haben einen Koch und müssen den Kundenverkehr schätzen. Einen Koch zu engagieren, kostet Geld. Latenz und Durchsatz können als „wie schnell Sie für Kunden kochen können“ verstanden werden. Für ein vernünftiges Geschäft braucht man eine „angemessene“ Anzahl an Köchen. Mit anderen Worten: Sie möchten in der Lage sein, den normalen Verkehr zu transportieren, und keine plötzlichen Verkehrsstöße, die innerhalb von Sekunden auftreten. Ein Verkehrsanstieg bedeutet Warten, sonst hat der „Koch“ nichts zu tun.
In der Welt der künstlichen Intelligenz spielt die GPU die Rolle des „Kochs“. Die Grundlasten sind stoßartig. Bei geringer Auslastung wird die Grundlast in den normalen Datenverkehr eingemischt und die Messungen liefern eine genaue Darstellung der Leistung des Dienstes unter aktueller Auslastung.
Szenarien mit hoher Servicelast sind interessant, weil sie zu Unterbrechungen führen. Der Benchmark wird nur ein paar Mal pro Tag/Woche ausgeführt, es handelt sich also nicht um den regelmäßigen Datenverkehr, den man erwarten sollte. Stellen Sie sich vor, 100 Leute strömen in ein lokales Restaurant, um zu sehen, wie schnell der Koch kocht. Das Ergebnis wäre großartig. Um die Terminologie der Quantenphysik zu übernehmen, nennt man dies den „Beobachtereffekt“. Je stärker die Störung (also je größer die Burst-Belastung) ist, desto geringer ist die Genauigkeit. Mit anderen Worten: Wenn Sie einen Dienst plötzlich stark auslasten und feststellen, dass der Dienst sehr schnell reagiert, wissen Sie, dass der Dienst über ziemlich viel ungenutzte Kapazität verfügt. Wenn Sie als Investor diese Situation sehen, sollten Sie sich fragen: Ist diese Art der Geldverbrennung verantwortungsvoll?
2. Das Modell wird irgendwann eine ähnliche Leistung erzielen
Der Bereich der künstlichen Intelligenz liebt Wettbewerbe, was in der Tat interessant ist. Alle sind sich schnell auf die gleiche Lösung einig und Nvidia gewinnt am Ende immer aufgrund der GPU. Dies ist großartigen Open-Source-Projekten zu verdanken, vLLM ist ein großartiges Beispiel. Das bedeutet, dass Sie als Anbieter, wenn Ihr Modell deutlich schlechter abschneidet als andere, leicht aufholen können, indem Sie sich Open-Source-Lösungen ansehen und gutes Engineering anwenden. 3. „Als Kunde sind mir die Kosten des Anbieters egal“ Für KI-Anwendungsentwickler haben wir Glück: Es gibt immer API-Anbieter, die bereit sind, „Geld zu verbrennen“. Die KI-Branche verbrennt Geld, um Traffic zu gewinnen, und der nächste Schritt besteht darin, sich um die Gewinne zu sorgen. Benchmarking ist eine mühsame und fehleranfällige Aufgabe. Im Guten wie im Schlechten kommt es normalerweise vor, dass die Gewinner Sie loben und die Verlierer Ihnen die Schuld geben. Dies war bei der letzten Runde der Benchmarks für Faltungs-Neuronale Netze der Fall. Es ist keine leichte Aufgabe, aber Benchmarking wird uns dabei helfen, das nächste Zehnfache der KI-Infrastruktur zu erreichen. Basierend auf dem Framework für künstliche Intelligenz und der Cloud-Infrastruktur hilft LeptonAI Benutzern, die beste KI-Grundstrategie zu finden.
Das obige ist der detaillierte Inhalt vonDie groß angelegte Rangliste der Inferenzkosten, angeführt von Jia Yangqings hoher Effizienz, wird veröffentlicht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was soll ich tun, wenn Win10 keine Airpods finden kann?
- Sie können das vorab trainierte Modell für die chinesische Sprache nicht finden? Die chinesische Version Wav2vec 2.0 und HuBERT kommen
- Detaillierte Erläuterung des Deep-Learning-Pre-Training-Modells in Python
- Erster Artikel: Ein neues Paradigma für das Training von 3D-Belegungsmodellen mit mehreren Ansichten, die nur 2D-Beschriftungen verwenden