
Heim >Technologie-Peripheriegeräte >KI >Erster Artikel: Ein neues Paradigma für das Training von 3D-Belegungsmodellen mit mehreren Ansichten, die nur 2D-Beschriftungen verwenden
Erster Artikel: Ein neues Paradigma für das Training von 3D-Belegungsmodellen mit mehreren Ansichten, die nur 2D-Beschriftungen verwenden

- 王林nach vorne
- 2023-09-30 08:49:061520Durchsuche
Dieser Artikel wird mit Genehmigung des öffentlichen Kontos von Autonomous Driving Heart nachgedruckt. Bitte wenden Sie sich für einen Nachdruck an die Quelle.
[RenderOcc, das erste neue Paradigma zum Trainieren von 3D-Belegungsmodellen mit mehreren Ansichten, die nur 2D-Beschriftungen verwenden] Der Autor extrahiert volumetrische 3D-Darstellungen im NeRF-Stil aus Bildern mit mehreren Ansichten und verwendet die Volumenrendering-Technologie, um 2D-Rekonstruktionen zu erstellen und daraus eine semantische Transformation zu erreichen 2D-Direkte 3D-Überwachung mit Tiefenbeschriftungen reduziert die Abhängigkeit von teuren 3D-Belegungsanmerkungen. Umfangreiche Experimente zeigen, dass RenderOcc eine vergleichbare Leistung wie vollständig überwachte Modelle mit 3D-Beschriftungen erbringt, was die Bedeutung dieses Ansatzes in realen Anwendungen unterstreicht. Bereits Open Source.
Titel: RenderOcc: Vision-Centric 3D Occupancy Prediction with 2DRendering Supervision
Autorenzugehörigkeit: Peking University, Xiaomi Automobile, Hong Kong Chinese MMLAB
Der Inhalt, der neu geschrieben werden muss, ist: Open-Source-Adresse: GitHub – pmj110119/RenderOcc
3D-Besetzungsvorhersage, die 3D-Szenen in semantisch beschriftete Gitterzellen quantifiziert, verspricht wichtige Aussichten in den Bereichen Roboterwahrnehmung und autonomes Fahren. Neuere Arbeiten nutzen zur Überwachung hauptsächlich vollständige Belegungsbezeichnungen im 3D-Voxelraum. Allerdings schränken teure Annotationsverfahren und manchmal mehrdeutige Beschriftungen die Benutzerfreundlichkeit und Skalierbarkeit von 3D-Belegungsmodellen erheblich ein. Um dieses Problem zu lösen, schlagen die Autoren RenderOcc vor, ein neues Paradigma zum Trainieren von 3D-Belegungsmodellen, die nur 2D-Beschriftungen verwenden. Insbesondere extrahieren wir volumetrische 3D-Darstellungen im NeRF-Stil aus Bildern mit mehreren Ansichten und verwenden Volumenrendering-Techniken, um 2D-Rekonstruktionen zu erstellen, was eine direkte 3D-Überwachung anhand von 2D-Semantik- und Tiefenbezeichnungen ermöglicht. Darüber hinaus stellen die Autoren eine Hilfsstrahlmethode zur Lösung des Problems spärlicher Blickwinkel in autonomen Fahrszenen vor, die sequentielle Frames nutzt, um ein umfassendes 2D-Rendering für jedes Ziel zu erstellen. RenderOcc ist der erste Versuch, ein 3D-Belegungsmodell mit mehreren Ansichten nur mithilfe von 2D-Beschriftungen zu trainieren und so die Abhängigkeit von teuren 3D-Belegungsanmerkungen zu reduzieren. Umfangreiche Experimente zeigen, dass RenderOcc eine vergleichbare Leistung wie vollständig überwachte Modelle mit 3D-Beschriftungen erbringt, was die Bedeutung dieses Ansatzes in realen Anwendungen unterstreicht.
Netzwerkstruktur:
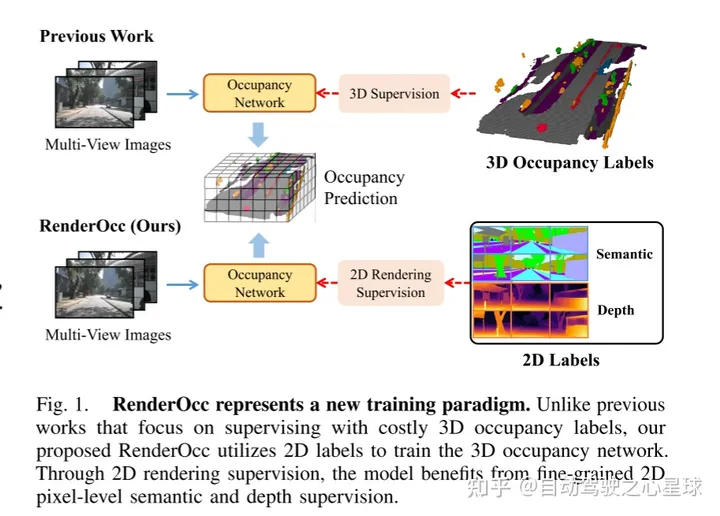
Abbildung 1 zeigt eine neue Trainingsmethode von RenderOcc. Im Gegensatz zu früheren Methoden, die zur Überwachung auf teure 3D-Belegungsetiketten angewiesen sind, verwendet das in diesem Dokument vorgeschlagene RenderOcc 2D-Beschriftungen, um das 3D-Belegungsnetzwerk zu trainieren. Mit der 2D-Rendering-Überwachung kann das Modell von einer feinkörnigen 2D-Pixelebenen-Semantik und Tiefenüberwachung profitieren
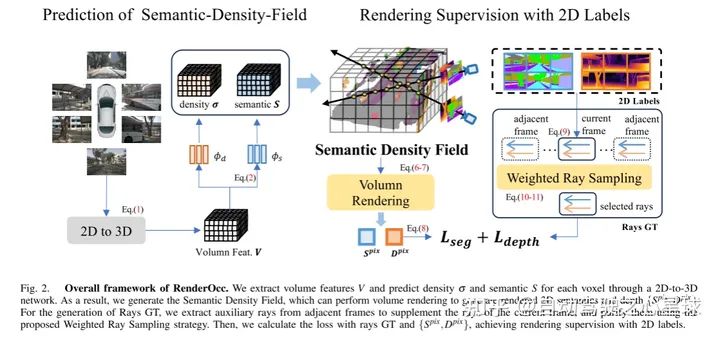
Abbildung 2. Das Gesamtgerüst von RenderOcc. Dieser Artikel extrahiert volumetrische Merkmale über ein 2D-zu-3D-Netzwerk und sagt die Dichte und Semantik jedes Voxels voraus. Daher generiert dieser Artikel ein semantisches Dichtefeld, das Volumenrendering durchführen kann, um gerenderte 2D-Semantik und -Tiefe zu erzeugen. Für die Erzeugung von Rays GT extrahiert dieser Artikel Hilfsstrahlen aus benachbarten Frames, um die Strahlen des aktuellen Frames zu ergänzen, und verwendet die vorgeschlagene gewichtete Ray-Sampling-Strategie, um sie zu reinigen. Dann verwendet dieser Artikel Light GT und {}, um den Verlust zu berechnen und eine Rendering-Überwachung von 2D-Beschriftungen zu erreichen
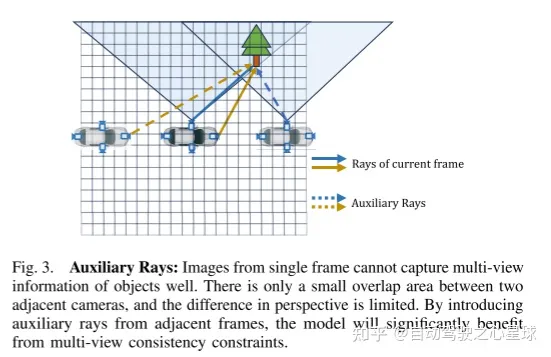
Umgeschriebener Inhalt: Abbildung 3. Hilfslicht: Ein Einzelbild kann die Mehrfachansichtsinformationen des Objekts nicht gut erfassen. Es gibt nur einen kleinen Überlappungsbereich zwischen benachbarten Kameras und der Unterschied im Blickwinkel ist begrenzt. Durch die Einführung von Hilfsstrahlen aus benachbarten Frames kann das Modell erheblich von Konsistenzbeschränkungen bei mehreren Ansichten profitieren

Der Inhalt, der neu geschrieben werden muss, ist: Originallink: https://mp.weixin.qq.com/s/WzI8mGoIOTOdL8irXrbSPQ
Das obige ist der detaillierte Inhalt vonErster Artikel: Ein neues Paradigma für das Training von 3D-Belegungsmodellen mit mehreren Ansichten, die nur 2D-Beschriftungen verwenden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!