

 Technologie-PeripheriegeräteKIInterpretation des Konzepts der Zielverfolgung in der Computer Vision
Technologie-PeripheriegeräteKIInterpretation des Konzepts der Zielverfolgung in der Computer Vision

Objektverfolgung ist eine wichtige Aufgabe in der Bildverarbeitung und wird häufig in der Verkehrsüberwachung, Robotik, medizinischen Bildgebung, automatischen Fahrzeugverfolgung und anderen Bereichen eingesetzt. Es verwendet Deep-Learning-Methoden, um die Position des Zielobjekts in jedem aufeinanderfolgenden Bild im Video vorherzusagen oder abzuschätzen, nachdem die Anfangsposition des Zielobjekts bestimmt wurde. Die Objektverfolgung hat im realen Leben ein breites Anwendungsspektrum und ist im Bereich Computer Vision von großer Bedeutung.
Bei der Objektverfolgung handelt es sich normalerweise um den Prozess der Objekterkennung. Hier ist ein kurzer Überblick über die Schritte der Objektverfolgung:
1. Objekterkennung, bei der der Algorithmus Objekte klassifiziert und erkennt, indem er Begrenzungsrahmen um sie herum erstellt.
2. Weisen Sie jedem Objekt eine eindeutige Identifikation (ID) zu.
3. Verfolgen Sie die Bewegung erkannter Objekte in Bildern und speichern Sie gleichzeitig relevante Informationen.
Arten der Zielverfolgung
Es gibt zwei Arten der Zielverfolgung: Bildverfolgung und Videoverfolgung.
Bildverfolgung
Bildverfolgung ist die Aufgabe, Bilder automatisch zu identifizieren und zu verfolgen. Hauptsächlich im Bereich Augmented Reality (AR) eingesetzt. Wenn beispielsweise ein 2D-Bild durch eine Kamera geleitet wird, erkennt der Algorithmus ein planares 2D-Bild, das dann zum Überlagern von 3D-Grafikobjekten verwendet werden kann.
Video-Tracking
Video-Tracking ist die Aufgabe, sich bewegende Objekte in Videos zu verfolgen. Die Idee der Videoverfolgung besteht darin, ein Zielobjekt so zuzuordnen oder eine Beziehung zwischen ihm herzustellen, wie es in jedem Videobild erscheint. Mit anderen Worten: Beim Video-Tracking werden Videobilder nacheinander analysiert und der frühere Standort eines Objekts mit seinem aktuellen Standort verknüpft, indem Begrenzungsrahmen um das Objekt herum vorhergesagt und erstellt werden.
Video-Tracking wird häufig in der Verkehrsüberwachung, bei selbstfahrenden Autos und im Sicherheitsbereich eingesetzt, da es Live-Aufnahmen verarbeiten kann.
4 Phasen des Zielverfolgungsprozesses
Phase 1: Zielinitialisierung
Beinhaltet die Definition des Objekts oder Ziels. Kombiniert mit dem Prozess des Zeichnens eines Begrenzungsrahmens um den ersten Frame des Videos. Der Tracker muss dann die Position des Objekts in den verbleibenden Frames schätzen oder vorhersagen, während er Begrenzungsrahmen zeichnet.
Phase Zwei: Erscheinungsbildmodellierung
Bei der Erscheinungsbildmodellierung wird das visuelle Erscheinungsbild eines Objekts modelliert. Wenn ein Zielobjekt verschiedene Szenarien wie Lichtverhältnisse, Winkel, Geschwindigkeiten usw. durchläuft, kann es das Erscheinungsbild des Objekts verändern und dazu führen, dass Fehlerinformationen vorliegen und der Algorithmus die Verfolgung des Objekts verliert. Daher ist eine Erscheinungsbildmodellierung erforderlich, damit der Modellierungsalgorithmus die verschiedenen Änderungen und Verzerrungen erfassen kann, die durch die Bewegung des Zielobjekts entstehen.
Erscheinungsmodellierung besteht aus zwei Teilen:
- Visuelle Darstellung: Sie konzentriert sich auf die Erstellung robuster Merkmale und Darstellungen, die Objekte beschreiben können.
- Statistische Modellierung: Sie verwendet statistische Lerntechniken, um Modelle für die Objekterkennung effektiv zu erstellen.
Phase 3: Bewegungsschätzung
Die Bewegungsschätzung extrapoliert typischerweise die Vorhersagefähigkeiten des Modells, um den zukünftigen Standort eines Objekts genau vorherzusagen.
Phase 4: Ziellokalisierung
Sobald der Standort des Objekts angenähert ist, können wir das visuelle Modell verwenden, um den genauen Standort des Ziels zu ermitteln.
Objektverfolgungsebenen
Objektverfolgung kann in zwei Ebenen definiert werden:
Einzelobjektverfolgung (SOT)
Einzelobjektverfolgung (SOT) zielt darauf ab, eine einzelne Objektklasse und nicht mehrere Objekte zu verfolgen. Wird manchmal auch als visuelle Objektverfolgung bezeichnet. Bei SOT wird der Begrenzungsrahmen des Zielobjekts im ersten Frame definiert. Das Ziel des Algorithmus besteht darin, dasselbe Objekt in den verbleibenden Bildern zu lokalisieren.
SOT fällt in die Kategorie des erkennungsfreien Trackings, da der erste Begrenzungsrahmen dem Tracker manuell bereitgestellt werden muss. Dies bedeutet, dass ein einzelner Objekt-Tracker in der Lage sein sollte, jedes gegebene Objekt zu verfolgen, auch Objekte, für die kein Klassifizierungsmodell für das Training verfügbar ist.
Multiple Object Tracking (MOT)
Multiple Object Tracking (MOT) bezieht sich auf die Methode, mit der der Tracking-Algorithmus jedes einzelne interessierende Objekt in einem Video verfolgt. Zunächst bestimmt der Tracking-Algorithmus die Anzahl der Objekte in jedem Frame und verfolgt dann die Identität jedes Objekts von einem Frame zum nächsten, bis es den Frame verlässt.
Deep-Learning-basierte Zielverfolgungsmethoden
Zielverfolgung hat viele Methoden eingeführt, um die Genauigkeit und Effizienz von Verfolgungsmodellen zu verbessern. Bei einigen Methoden handelt es sich um klassische Methoden des maschinellen Lernens wie k-Nearest Neighbors oder Support Vector Machines. Im Folgenden besprechen wir einige Deep-Learning-Algorithmen für Zielverfolgungsaufgaben.
MDNet
Ein Zielverfolgungsalgorithmus, der große Datenmengen für das Training nutzt. MDNet besteht aus Vortraining und visueller Online-Verfolgung.
Vor dem Training: Im Vortraining muss das Netzwerk die Darstellung mehrerer Domänen lernen. Um dieses Ziel zu erreichen, wird der Algorithmus anhand mehrerer annotierter Videos trainiert, um Darstellungen und räumliche Merkmale zu lernen.
Visuelles Online-Tracking: Sobald das Vortraining abgeschlossen ist, werden domänenspezifische Schichten entfernt und im Netzwerk verbleiben nur noch gemeinsame Schichten, die die erlernten Darstellungen enthalten. Bei der Inferenz wird eine binäre Klassifizierungsschicht hinzugefügt, die online trainiert oder feinabgestimmt wird.
Diese Technik spart Zeit und hat sich als effektiver online-basierter Tracking-Algorithmus erwiesen.
GOTURN
Das Deep Regression Network ist ein Modell, das auf Offline-Training basiert. Der Algorithmus lernt eine allgemeine Beziehung zwischen Objektbewegung und -erscheinung und kann zur Verfolgung von Objekten verwendet werden, die nicht im Trainingssatz erscheinen.
Die universelle Objektverfolgung mithilfe von Regressionsnetzwerken oder GOTURN verwendet regressionsbasierte Methoden zur Verfolgung von Objekten. Im Wesentlichen regressieren sie direkt, um das Zielobjekt in nur einem Feedforward-Durchgang durch das Netzwerk zu lokalisieren. Das Netzwerk akzeptiert zwei Eingaben: den Suchbereich des aktuellen Frames und das Ziel des vorherigen Frames. Anschließend vergleicht das Netzwerk diese Bilder, um das Zielobjekt im aktuellen Bild zu finden.
ROLO
ROLO ist eine Kombination aus rekurrentem neuronalem Netzwerk und YOLO. Im Allgemeinen eignet sich LSTM besser für die Verwendung in Verbindung mit CNN.
ROLO kombiniert zwei neuronale Netzwerke: eines ist CNN, das zum Extrahieren räumlicher Informationen verwendet wird, das andere ist ein LSTM-Netzwerk, das zum Ermitteln der Flugbahn von Zielobjekten verwendet wird. Bei jedem Zeitschritt werden räumliche Informationen extrahiert und an das LSTM gesendet, das dann den Standort des verfolgten Objekts zurückgibt.
DeepSORT
DeepSORT ist einer der beliebtesten Zielverfolgungsalgorithmen und eine Erweiterung von SORT.
SORT ist ein onlinebasierter Tracking-Algorithmus, der einen Kalman-Filter verwendet, um die Position eines Objekts anhand seiner vorherigen Position zu schätzen. Der Kalman-Filter ist sehr wirksam gegen Okklusionen.
Nachdem wir SORT verstanden haben, können wir Deep-Learning-Technologie kombinieren, um den SORT-Algorithmus zu verbessern. Tiefe neuronale Netze ermöglichen es SORT, den Standort von Objekten genauer abzuschätzen, da diese Netze nun die Eigenschaften des Zielbilds beschreiben können.
SiamMask
wurde entwickelt, um den Offline-Trainingsprozess vollständig konvolutioneller siamesischer Netzwerke zu verbessern. Das siamesische Netzwerk akzeptiert zwei Eingaben: ein zugeschnittenes Bild und ein größeres Suchbild, um eine dichte räumliche Merkmalsdarstellung zu erhalten.
Das siamesische Netzwerk erzeugt eine Ausgabe, die die Ähnlichkeit zweier Eingabebilder misst und bestimmt, ob in beiden Bildern dasselbe Objekt vorhanden ist. Durch die Erhöhung des Verlusts mithilfe binärer Segmentierungsaufgaben ist dieses Framework sehr effektiv für die Objektverfolgung.
JDE
JDE ist ein Single-Shot-Detektor, der zur Lösung von Lernproblemen mit mehreren Aufgaben entwickelt wurde. JDE lernt die Objekterkennung und die Einbettung des Erscheinungsbilds in ein gemeinsames Modell.
JDE verwendet Darknet-53 als Rückgrat, um die Funktionsdarstellung auf jeder Ebene zu erhalten. Diese Merkmalsdarstellungen werden dann mithilfe von Upsampling und Restverbindungen zusammengeführt. Anschließend wird ein Vorhersageheader an die zusammengeführte Feature-Darstellung angehängt, was zu einer dichten Vorhersagekarte führt. Um die Objektverfolgung durchzuführen, generiert JDE Bounding-Box-Klassen und Einbettungen des Erscheinungsbilds aus dem Vorhersagekopf. Diese Erscheinungseinbettungen werden mithilfe einer Affinitätsmatrix mit Einbettungen zuvor erkannter Objekte verglichen.
Tracktor++
Tracktor++ ist ein Online-Tracking-Algorithmus. Es verwendet Objekterkennungsmethoden, um eine Verfolgung durchzuführen, indem ein neuronales Netzwerk nur auf die Erkennungsaufgabe trainiert wird. Im Wesentlichen Vorhersage der Position des Objekts im nächsten Frame durch Berechnung einer Bounding-Box-Regression. Es führt kein Training oder eine Optimierung der Tracking-Daten durch.
Der Objektdetektor von Tracktor++ ist normalerweise schnelleres R-CNN mit 101 Schichten ResNet und FPN. Es verwendet den Regressionszweig von Faster R-CNN, um Merkmale aus dem aktuellen Frame zu extrahieren.
Das obige ist der detaillierte Inhalt vonInterpretation des Konzepts der Zielverfolgung in der Computer Vision. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Jeder kann besser KI verwenden: Gedanken zur Stimmung codierenApr 19, 2025 am 11:17 AM
Jeder kann besser KI verwenden: Gedanken zur Stimmung codierenApr 19, 2025 am 11:17 AMSie können sich ansehen, was auf Konferenzen und Handelsshows passiert. Sie können Ingenieure fragen, was sie tun, oder sich mit einem CEO wenden. Überall, wo Sie aussehen, ändern sich die Dinge mit brezdemschneller Geschwindigkeit. Ingenieure und Nicht-Ingenieure Was ist der Unterschied?
 Raketenstartsimulation und -analyse unter Verwendung von Rocketpy - Analytics VidhyaApr 19, 2025 am 11:12 AM
Raketenstartsimulation und -analyse unter Verwendung von Rocketpy - Analytics VidhyaApr 19, 2025 am 11:12 AMSimulieren Raketenstarts mit Rocketpy: Eine umfassende Anleitung Dieser Artikel führt Sie durch die Simulation von Rocketpy-Starts mit hoher Leistung mit Rocketpy, einer leistungsstarken Python-Bibliothek. Wir werden alles abdecken, von der Definition von Raketenkomponenten bis zur Analyse von Simula
 5 KOSTENLOSE Datenanalysekurse - Analytics VidhyaApr 19, 2025 am 11:11 AM
5 KOSTENLOSE Datenanalysekurse - Analytics VidhyaApr 19, 2025 am 11:11 AMBefreien Sie sich auf eine datengesteuerte Karrierereise, ohne die Bank zu brechen! In diesem Artikel werden fünf außergewöhnliche kostenlose Datenanalysekurse hervorgehoben, die sich sowohl für erfahrene Fachleute als auch für die seltsamen Neuankömmlinge, um t zu erkunden, perfekt zu erweitern, perfekt
 Wie baue ich autonome AI -Agenten mit OpenAgi? - Analytics VidhyaApr 19, 2025 am 11:10 AM
Wie baue ich autonome AI -Agenten mit OpenAgi? - Analytics VidhyaApr 19, 2025 am 11:10 AMNutzen Sie die Kraft von AI -Agenten mit OpenAgi: Ein umfassender Leitfaden Stellen Sie sich einen unermüdlichen Assistenten vor, der immer verfügbar ist, um Ihre Aufgaben zu optimieren und aufschlussreiche Empfehlungen zu geben. Das ist das Versprechen von AI -Agenten, und Openagi befähigt Sie, sie aufzubauen
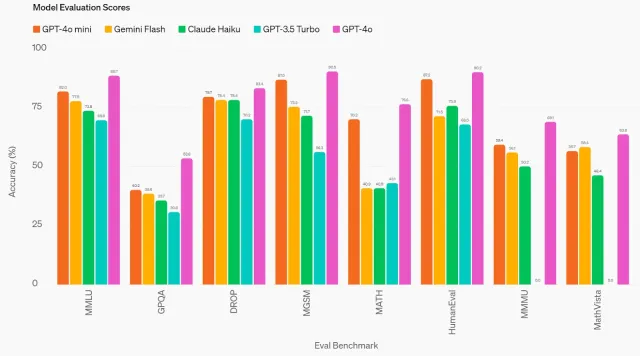 GPT-4O Mini: Wie offenes Modell von Openai stapelt sich?Apr 19, 2025 am 11:09 AM
GPT-4O Mini: Wie offenes Modell von Openai stapelt sich?Apr 19, 2025 am 11:09 AMDas neueste Angebot von Openai, GPT-4O Mini, markiert einen erheblichen Schritt in Richtung erschwinglicher und zugänglicher fortgeschrittener KI. Dieses kleine Sprachmodell (SLM) fordert die Wettbewerber wie Lama 3 und Gemma 2 direkt heraus und verfügt über eine geringe Latenz, die Kosteneffizienz und ein
 Vom Tech -Innovator bis zum Gesundheitswesen Pioneer: Dr. Geetha Manjunaths AI -GeschichteApr 19, 2025 am 11:02 AM
Vom Tech -Innovator bis zum Gesundheitswesen Pioneer: Dr. Geetha Manjunaths AI -GeschichteApr 19, 2025 am 11:02 AMDiese Episode von "Lead With Data" zeigt Dr. Geetha Manjunath, Gründerin und CEO von Niramai Analytix. Dr. Manjunath, der einen Doktortitel am indischen Institut für Wissenschaft und einen MBA FRO hat
 Vereinfachung der lokalen LLM -Bereitstellung mit Ollama - Analytics VidhyaApr 19, 2025 am 11:01 AM
Vereinfachung der lokalen LLM -Bereitstellung mit Ollama - Analytics VidhyaApr 19, 2025 am 11:01 AMNutzen Sie die Kraft der Open-Source-LLMs lokal mit Ollama: Ein umfassender Leitfaden Das Ausführen von großsprachigen Modellen (LLMs) lokal bietet eine beispiellose Steuerung und Transparenz. Die Einrichtung der Umgebung kann jedoch entmutigend sein. Ollama vereinfacht diesen Prozess
 Wie man große Sprachmodelle mit Monsterapi feinstimmenApr 19, 2025 am 10:49 AM
Wie man große Sprachmodelle mit Monsterapi feinstimmenApr 19, 2025 am 10:49 AMNutzen Sie die Kraft der fein abgestimmten LLMs mit Monsterapi: eine umfassende Anleitung Stellen Sie sich einen virtuellen Assistenten vor, der Ihre Bedürfnisse perfekt versteht und vorwegnimmt. Dies wird dank Fortschritten in Großsprachmodellen (LLMs) in die Realität. Allerdings a


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

MinGW – Minimalistisches GNU für Windows
Dieses Projekt wird derzeit auf osdn.net/projects/mingw migriert. Sie können uns dort weiterhin folgen. MinGW: Eine native Windows-Portierung der GNU Compiler Collection (GCC), frei verteilbare Importbibliotheken und Header-Dateien zum Erstellen nativer Windows-Anwendungen, einschließlich Erweiterungen der MSVC-Laufzeit zur Unterstützung der C99-Funktionalität. Die gesamte MinGW-Software kann auf 64-Bit-Windows-Plattformen ausgeführt werden.

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

EditPlus chinesische Crack-Version
Geringe Größe, Syntaxhervorhebung, unterstützt keine Code-Eingabeaufforderungsfunktion

Herunterladen der Mac-Version des Atom-Editors
Der beliebteste Open-Source-Editor

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

