
Heim >System-Tutorial >LINUX >Anwendung für maschinelles Lernen für den automatisierten Betrieb und die Wartung von DBMS
Anwendung für maschinelles Lernen für den automatisierten Betrieb und die Wartung von DBMS

- 王林nach vorne
- 2024-01-24 12:21:16674Durchsuche
Ein Datenbankverwaltungssystem (DBMS) ist ein wichtiger Bestandteil jeder datenintensiven Anwendung. Sie können große Datenmengen und komplexe Arbeitslasten bewältigen, sind aber auch schwierig zu verwalten, da es Hunderte oder Tausende von „Knöpfen“ (Konfigurationsvariablen) gibt, die verschiedene Faktoren steuern, beispielsweise wie viel Speicher zum Zwischenspeichern und Schreiben auf die Festplatte verwendet werden soll . Frequenz. Organisationen müssen für die Optimierung oft Experten engagieren, und Experten sind für viele Organisationen zu teuer. Studenten und Forscher der Database Research Group der Carnegie Mellon University entwickeln ein neues Tool namens OtterTune, das automatisch die richtigen Einstellungen für die „Knöpfe“ eines DBMS finden kann. Der Zweck des Tools besteht darin, jedem die Bereitstellung eines DBMS zu ermöglichen, auch ohne Kenntnisse in der Datenbankverwaltung.
OtterTune unterscheidet sich von anderen DBMS-Setup-Tools, da es Kenntnisse über frühere DBMS-Optimierungen nutzt, um ein neues DBMS zu optimieren, was den Zeit- und Ressourcenverbrauch erheblich reduziert. OtterTune erreicht dies durch die Pflege einer Wissensbasis aus früheren Optimierungen. Diese gesammelten Daten werden zum Erstellen von Modellen für maschinelles Lernen (ML) verwendet, um die Reaktion des DBMS auf verschiedene Einstellungen zu erfassen. OtterTune verwendet diese Modelle, um das Experimentieren mit neuen Anwendungen zu leiten und Konfigurationen vorzuschlagen, die Endziele wie die Reduzierung der Latenz und die Erhöhung des Durchsatzes verbessern.
In diesem Artikel besprechen wir jede der Pipeline-Komponenten für maschinelles Lernen von OtterTune und wie sie interagieren, um Ihr DBMS-Setup zu optimieren. Anschließend bewerten wir die Optimierungsleistung von OtterTune auf MySQL und Postgres und vergleichen die optimalen Konfigurationen mit DBAs und anderen automatisierten Optimierungstools.
OtterTune ist ein Open-Source-Tool, das von Studenten und Forschern der Database Research Group der Carnegie Mellon University entwickelt wurde. Der gesamte Code wird auf Github gehostet und unter der Apache License 2.0-Lizenz veröffentlicht.
So funktioniert OtterTuneDas Bild unten zeigt die OtterTune-Komponenten und den Arbeitsablauf
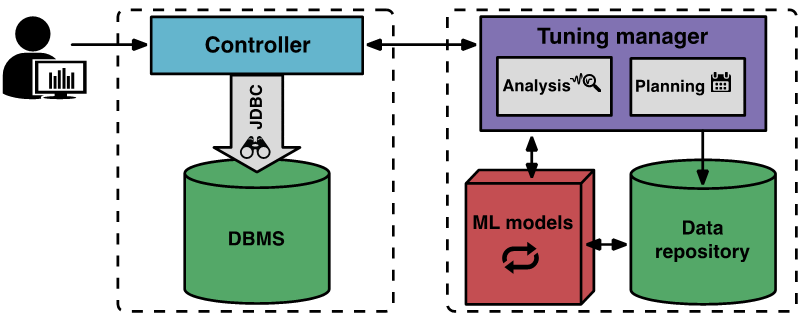
Der Optimierungsprozess beginnt, wenn der Benutzer OtterTune das endgültige Ziel mitteilt, das optimiert werden soll (z. B. Latenz oder Durchsatz), und das Client-Controller-Programm eine Verbindung zum Ziel-DBMS herstellt und den Amazon EC2-Instance-Typ und die aktuelle Konfiguration erfasst.
Dann startet der Controller den ersten Beobachtungszeitraum, um das endgültige Ziel zu beobachten und aufzuzeichnen. Nach der Beobachtung sammelt der Controller DBMS-interne Metriken, wie z. B. die Anzahl der Lese- und Schreibvorgänge auf MySQL-Festplattenseiten. Der Controller gibt diese Daten an das Tuning-Manager-Programm zurück.
Der Tuning-Manager von OtterTune speichert empfangene Messwertdaten in der Wissensdatenbank. OtterTune berechnet anhand dieser Ergebnisse die nächste Konfiguration für das Ziel-DBMS und gibt sie zusammen mit der geschätzten Leistungsverbesserung an den Controller zurück. Der Benutzer kann entscheiden, ob er den Tuning-Vorgang fortsetzt oder abbricht.
AchtungOtterTune führt eine schwarze Liste mit „Knöpfen“ für jede unterstützte DBMS-Version, einschließlich derjenigen, die für die Optimierung unbedeutend sind (z. B. der Pfad zum Speichern von Datendateien) oder derjenigen, die schwerwiegende oder versteckte Folgen haben (z. B. Datenverlust). OtterTune stellt dem Benutzer diese Blacklist zu Beginn des Tuning-Prozesses zur Verfügung, und der Benutzer kann andere „Regler“ hinzufügen, die OtterTune vermeiden soll.
OtterTune hat einige vorgegebene Annahmen, die für einige Benutzer zu bestimmten Einschränkungen führen können. Es wird beispielsweise davon ausgegangen, dass der Benutzer über Administratorrechte verfügt, damit der Controller die DBMS-Konfiguration ändern kann. Andernfalls müssen Benutzer eine Kopie der Datenbank auf anderer Hardware bereitstellen, damit OtterTune Optimierungsexperimente durchführen kann. Dies erfordert, dass Benutzer entweder die Arbeitslast reproduzieren oder Abfragen an das Produktions-DBMS weiterleiten. Die vollständigen Voreinstellungen und Einschränkungen finden Sie in unserem Dokument.
Pipeline für maschinelles LernenDas Bild unten zeigt den Prozess der Datenverarbeitung durch die OtterTune ML-Pipeline. Alle Beobachtungen werden in der Wissensdatenbank gespeichert.
OtterTune leitet zunächst Beobachtungsdaten an die Workload-Charakterisierungskomponente weiter, die einen kleinen Satz von DBMS-Metriken identifizieren kann, mit denen sich Leistungsänderungen und hervorstechende Merkmale verschiedener Workloads am effektivsten erfassen lassen.
Im nächsten Schritt generiert die „Knob-Identifizierungskomponente“ eine Knopf-Rangliste, einschließlich der Knöpfe, die den größten Einfluss auf die DBMS-Leistung haben. OtterTune „füttert“ dann alle diese Informationen an den Automatic Tuner, der die Arbeitslast des Ziel-DBMS der nächstgelegenen Arbeitslast in der Wissensdatenbank zuordnet und diese Arbeitslastdaten wiederverwendet, um eine bessere Konfiguration zu generieren.
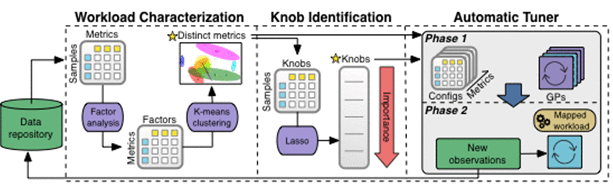
Lassen Sie uns unten näher auf jede Komponente der Machine-Learning-Pipeline eingehen.
Workload-Charakterisierung: OtterTune nutzt die internen Laufzeitmetriken des DBMS, um das Verhalten einer bestimmten Workload zu charakterisieren. Diese Metriken stellen die Workload genau dar, da sie mehrere Aspekte des Workload-Verhaltens erfassen. Viele Indikatoren sind jedoch redundant: Einige stellen dasselbe Maß in unterschiedlichen Einheiten dar, andere stellen eine unabhängige Komponente des DBMS dar, ihre Werte sind jedoch stark korreliert. Das Aussortieren redundanter Maßnahmen ist wichtig, um die Komplexität maschineller Lernmodelle zu reduzieren. Daher gruppieren wir die DBMS-Metriken basierend auf der Korrelation und wählen die repräsentativste aus, insbesondere diejenige, die dem Median am nächsten kommt. Nachfolgende Komponenten des maschinellen Lernens werden diese Maßnahmen nutzen.
Knopfidentifikation: Ein DBMS kann Hunderte von Knöpfen haben, aber nur einige davon wirken sich auf die Leistung aus. OtterTune verwendet eine beliebte Funktionsauswahltechnik namens Lasso, um zu bestimmen, welche Regler den größten Einfluss auf die Gesamtleistung Ihres Systems haben. Mithilfe dieser Technik zur Verarbeitung der Daten in der Wissensdatenbank konnte OtterTune die Wichtigkeitsreihenfolge der DBMS-Regler bestimmen.
Als nächstes muss OtterTune entscheiden, wie viele Knöpfe verwendet werden sollen, wenn es Konfigurationsempfehlungen gibt. Die Verwendung zu vieler Knöpfe verlängert die Abstimmungszeit von OtterTune erheblich, während die Verwendung zu weniger Knöpfen es schwierig macht, die beste Konfiguration zu finden. OtterTune verwendet einen inkrementellen Ansatz, um diesen Prozess zu automatisieren, indem es die Anzahl der während einer Tuning-Sitzung verwendeten Knöpfe schrittweise erhöht. Dieser Ansatz ermöglicht es OtterTune, die Konfiguration zunächst mit einer kleinen Anzahl der wichtigsten Knöpfe zu erkunden und zu verfeinern und sie dann zu erweitern, um weitere Knöpfe zu berücksichtigen.
Auto-Tuner: Die automatische Tuner-Komponente verwendet eine zweistufige Analysemethode, um nach jeder Beobachtungsphase zu entscheiden, welche Konfiguration empfohlen werden soll.
Zuerst verwendet das System die von der Workload-Charakterisierungskomponente gefundenen Leistungsdaten, um den historischen Optimierungsprozess zu identifizieren, der der aktuellen Ziel-DBMS-Workload am nächsten kommt, und vergleicht die beiden Metriken, um zu bestätigen, welche Werte ähnlich auf unterschiedliche Knopfeinstellungen reagieren.
OtterTune versucht dann eine andere Knopfkonfiguration und wendet ein statistisches Modell auf die gesammelten Daten und die nächstgelegenen Arbeitslastdaten in der Wissensdatenbank an. Mit diesem Modell kann OtterTune vorhersagen, wie das DBMS unter jeder möglichen Konfiguration funktionieren wird. OtterTune optimiert die nächste Konfiguration und wechselt dabei zwischen Exploration (Sammeln von Informationen zur Verbesserung des Modells) und Exploitation (gierige Annäherung an die Zielmetrik).
ErreichtOtterTune ist in Python geschrieben.
Für die Komponenten Workload-Charakterisierung und Knopferkennung spielt die Laufzeitleistung keine große Rolle, daher verwenden wir scikit-learn, um den entsprechenden Algorithmus für maschinelles Lernen zu implementieren. Diese Algorithmen laufen in Hintergrundprozessen und übernehmen neu generierte Daten in die Wissensdatenbank.
Für die automatische Abstimmung von Komponenten sind maschinelle Lernalgorithmen sehr wichtig. Jede Beobachtungsphase muss nach Abschluss durchgeführt werden, um neue Daten zu absorbieren, damit OtterTune den nächsten Knopf zum Testen auswählen kann. Da die Leistung berücksichtigt werden muss, verwenden wir TensorFlow zur Implementierung.
Um DBMS-Hardware, Knopfkonfiguration und Laufzeitleistungsmetriken zu erfassen, haben wir das OLTP-Bench-Benchmark-Framework in den Controller von OtterTune integriert.
Experimentelles DesignWir haben die besten OtterTune-Konfigurationen für MySQL und Postgres mit den folgenden Konfigurationsoptionen zur Bewertung verglichen:
Standard: DBMS-Erstkonfiguration
Tuning-Skript: Konfiguration, die von einem Open-Source-Tuning-Vorschlagstool erstellt wurde
DBA: Von einem menschlichen DBA gewählte Konfiguration
RDS: Wenden Sie eine benutzerdefinierte Konfiguration eines von Amazon-Entwicklern verwalteten DBMS auf denselben EC2-Instance-Typ an.
Wir haben alle Experimente auf Amazon EC2 Spot-Instanzen durchgeführt. Jedes Experiment wird auf zwei Instanzen vom Typ m4.large und m3.xlarge ausgeführt: eine für den OtterTune-Controller und eine für die Ziel-DBMS-Bereitstellung. Der OtterTune-Tuning-Manager und die Wissensdatenbank werden lokal auf einem 20-Core-128G-Speicherserver bereitgestellt.
Der Workload verwendet TPC-C, den Industriestandard zur Bewertung der Leistung von Online-Handelssystemen.
BewertungWir haben die Latenz und den Durchsatz für jede Datenbank im Experiment gemessen – MySQL und Postgres – und die folgenden Diagramme zeigen die Ergebnisse. Das erste Diagramm zeigt die Zahl der „99. Perzentil-Latenz“, die die „Worst-Case“-Zeit darstellt, die zum Abschluss einer Transaktion benötigt wird. Das zweite Diagramm zeigt die Durchsatzergebnisse, gemessen als durchschnittliche Anzahl der pro Sekunde ausgeführten Transaktionen.
MySQL-ExperimentergebnisseDie von OtterTune generierte optimale Konfiguration im Vergleich zur Konfiguration des Tuning-Skripts und RDS reduzierte die MySQL-Latenz um etwa 60 % und erhöhte den Durchsatz um 22 % bis 35 %. OtterTune generiert außerdem eine Konfiguration, die fast so gut ist wie DBA.
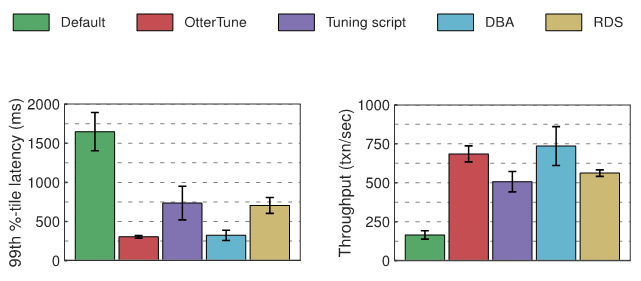
Unter TPC-C-Lasten beeinträchtigen nur wenige MySQL-Regler die Leistung erheblich. Die Konfiguration von OtterTune und DBA stellt diese Regler auf gute Werte ein. RDS schnitt etwas schlechter ab, da einem Knopf ein suboptimaler Wert zugewiesen wurde. Das Tuning-Skript schnitt am schlechtesten ab, da nur ein Knopf geändert wurde.
Postgres-Experimentergebnisse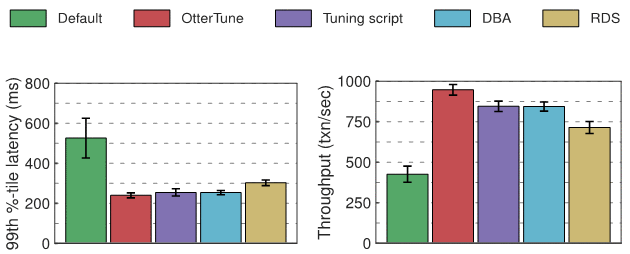
In Bezug auf die Latenz haben die Konfigurationen von OtterTune, Tuning-Tools, DBA und RDS im Vergleich zur Postgres-Standardkonfiguration ähnliche Verbesserungen erzielt. Wir können dies wahrscheinlich auf den Netzwerk-Overhead zwischen dem OLTP-Bench-Client und dem DBMS zurückführen. In Bezug auf den Durchsatz ist Postgres bei Konfiguration mit OtterTune 12 % höher als DBA und Tuning-Skripte und 32 % höher als RDS.
FazitOtterTune automatisiert den Prozess der Suche nach optimalen Werten für DBMS-Konfigurationsknöpfe. Es optimiert ein neu bereitgestelltes DBMS durch Wiederverwendung von Trainingsdaten, die aus früheren Optimierungsprozessen gesammelt wurden. Da OtterTune keinen Initialisierungsdatensatz generieren muss, um sein maschinelles Lernmodell zu trainieren, wird die Optimierungszeit erheblich verkürzt.
Was kommt als nächstes? Im Einklang mit der wachsenden Beliebtheit von DBaaS (wo eine Remote-Anmeldung beim DBMS-Host nicht möglich ist) wird OtterTune bald in der Lage sein, die Hardwarefunktionen des Ziel-DBMS automatisch zu prüfen, ohne dass eine Remote-Anmeldung erforderlich ist.
Um mehr über OtterTune zu erfahren, schauen Sie sich unser Paper und den Code auf GitHub an. Behalten Sie diese Seite im Auge, denn wir werden OtterTune bald zu einem Online-Tuning-Dienst machen.
Das obige ist der detaillierte Inhalt vonAnwendung für maschinelles Lernen für den automatisierten Betrieb und die Wartung von DBMS. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist Red Hat Linux?
- Der Linux-Open-Source-Bruder Red Hat wurde für 34 Milliarden US-Dollar von IBM übernommen
- So verwenden Sie den Linux-ZIP-Komprimierungsbefehl
- Wie filtere und klassifiziere ich Protokolle mit Linux-Befehlszeilentools?
- Oracle, SUSE und CIQ schließen sich zur Open Enterprise Linux Association zusammen, um gemeinsam Distributionen zu entwickeln, die mit Red Hat RHEL Enterprise Edition kompatibel sind