
 Technologie-PeripheriegeräteKIGoogle veröffentlicht ASPIRE, ein Modelltrainings-Framework, das es der KI ermöglicht, die Ausgabegenauigkeit unabhängig zu beurteilen
Technologie-PeripheriegeräteKIGoogle veröffentlicht ASPIRE, ein Modelltrainings-Framework, das es der KI ermöglicht, die Ausgabegenauigkeit unabhängig zu beurteilen

Google hat kürzlich eine Pressemitteilung veröffentlicht, in der die Einführung des ASPIRE-Trainingsframeworks angekündigt wird, das speziell für große Sprachmodelle entwickelt wurde. Dieses Framework zielt darauf ab, die selektiven Vorhersagefähigkeiten von KI-Modellen zu verbessern.

Google erwähnte, dass sich große Sprachmodelle beim Verstehen natürlicher Sprache und bei der Generierung von Inhalten schnell entwickeln und zur Entwicklung verschiedener innovativer Anwendungen verwendet wurden, es jedoch immer noch unangemessen ist, sie auf Situationen mit hoher Entscheidungsfindung anzuwenden. Dies liegt an der Unsicherheit und der Möglichkeit einer „Halluzination“ bei Modellvorhersagen. Daher hat Google ein ASPIRE-Trainingsframework entwickelt, das einen „Glaubwürdigkeits“-Mechanismus für eine Reihe von Modellen einführt , jede Die Antworten haben alle einen Wahrscheinlichkeitswert für die Richtigkeit .
Die zweite Stufe ist das „Antwort-Sampling“. Nach einer spezifischen Feinabstimmung kann das Modell die zuvor erlernten einstellbaren Parameter verwenden, um für jede Trainingsfrage unterschiedliche Antworten zu generieren und einen Datensatz für das Selbstbewertungslernen zu generieren eine Reihe von Antworten mit hoher Glaubwürdigkeit. 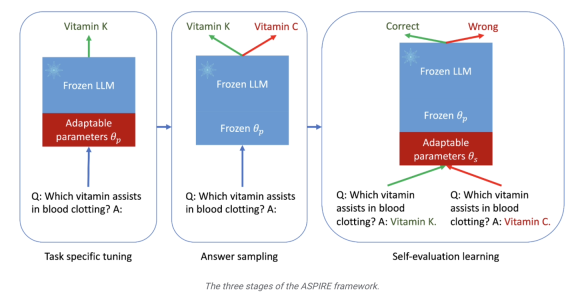 Die Forscher verwendeten außerdem die „Beam Search“-Methode und den Rouge-L-Algorithmus, um die Qualität der Antworten zu bewerten, und gaben die generierten Antworten und Bewertungen erneut in das Modell ein, um die dritte Stufe zu starten
Die Forscher verwendeten außerdem die „Beam Search“-Methode und den Rouge-L-Algorithmus, um die Qualität der Antworten zu bewerten, und gaben die generierten Antworten und Bewertungen erneut in das Modell ein, um die dritte Stufe zu starten
In der dritten Stufe des „Selbstbewertungslernens“ fügten die Forscher dem Modell eine Reihe anpassbarer Parameter hinzu, um insbesondere die Selbstbewertungsfähigkeiten des Modells zu verbessern.  Das Ziel dieser Phase besteht darin, das Modell lernen zu lassen, „die Genauigkeit der Ausgabeantwort selbst zu beurteilen“
Das Ziel dieser Phase besteht darin, das Modell lernen zu lassen, „die Genauigkeit der Ausgabeantwort selbst zu beurteilen“
Google-Forscher verwendeten drei Frage- und Antwortdatensätze, CoQA, TriviaQA und SQuAD, um die Ergebnisse des ASPIRE-Trainingsrahmens zu überprüfen. Es heißt, dass „das von ASPIRE angepasste kleine Modell OPT-2.7B das größere OPT-2.7B bei weitem übertrifft.“ 30B-Modell.“ Die experimentellen Ergebnisse zeigen auch, dass bei entsprechenden Anpassungen in einigen Szenarien sogar ein kleines Sprachmodell ein großes Sprachmodell übertreffen kann.
Die Forscher kamen zu dem Schluss, dass das 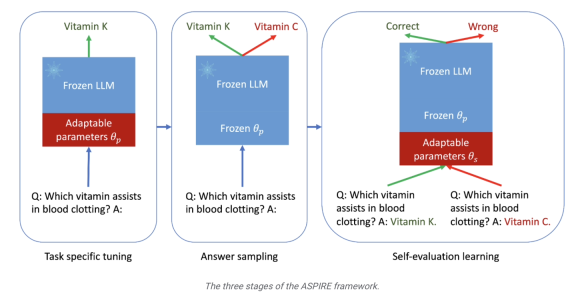 ASPIRE-Framework-Training die Ausgabegenauigkeit großer Sprachmodelle deutlich verbessern kann und selbst kleinere Modelle nach der Feinabstimmung „genaue und sichere“ Vorhersagen machen können
ASPIRE-Framework-Training die Ausgabegenauigkeit großer Sprachmodelle deutlich verbessern kann und selbst kleinere Modelle nach der Feinabstimmung „genaue und sichere“ Vorhersagen machen können
Das obige ist der detaillierte Inhalt vonGoogle veröffentlicht ASPIRE, ein Modelltrainings-Framework, das es der KI ermöglicht, die Ausgabegenauigkeit unabhängig zu beurteilen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 GPT-4O gegen OpenAI O1: Ist das neue OpenAI-Modell den Hype wert?Apr 13, 2025 am 10:18 AM
GPT-4O gegen OpenAI O1: Ist das neue OpenAI-Modell den Hype wert?Apr 13, 2025 am 10:18 AMEinführung OpenAI hat sein neues Modell auf der Grundlage der mit Spannung erwarteten „Strawberry“ -Scharchitektur veröffentlicht. Dieses innovative Modell, bekannt als O1
 Feinabstimmung und Schlussfolgerung kleiner SprachmodelleApr 13, 2025 am 10:15 AM
Feinabstimmung und Schlussfolgerung kleiner SprachmodelleApr 13, 2025 am 10:15 AMEinführung Stellen Sie sich vor, Sie bauen einen medizinischen Chatbot auf, und die massiven, ressourcenhungrigen Großsprachenmodelle (LLMs) scheinen für Ihre Bedürfnisse übertrieben zu sein. Hier kommen kleine Sprachmodelle (SLMs) wie Gemma ins Spiel
 So greifen Sie auf die OpenAI O1 API | Analytics VidhyaApr 13, 2025 am 10:14 AM
So greifen Sie auf die OpenAI O1 API | Analytics VidhyaApr 13, 2025 am 10:14 AMEinführung Die O1 -Serienmodelle von OpenAI stellen einen signifikanten Sprung in den Funktionen des Großsprachmodells (LLM) dar, insbesondere für komplexe Argumentationsaufgaben. Diese Modelle führen vor Resp zu tiefen internen Denkprozessen
 Google Sheets Automation mit Python | Analytics VidhyaApr 13, 2025 am 10:01 AM
Google Sheets Automation mit Python | Analytics VidhyaApr 13, 2025 am 10:01 AMGoogle Sheets ist eine der beliebtesten und am häufigsten verwendeten Alternativen zu Excel und bietet eine kollaborative Umgebung mit Funktionen wie Echtzeitbearbeitung, Versionskontrolle und nahtloser Integration in Google Suite, wobei Sie u ermöglicht werden können
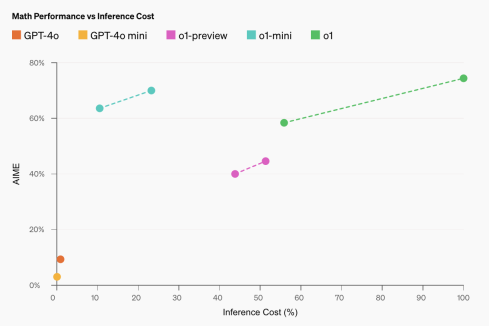 O1-Mini: Ein bahnbrechendes Modell für MINT und ArgumentationApr 13, 2025 am 09:55 AM
O1-Mini: Ein bahnbrechendes Modell für MINT und ArgumentationApr 13, 2025 am 09:55 AMOpenAI führt O1-Mini ein, ein kosteneffizientes Argumentationsmodell mit Schwerpunkt auf STEM-Probanden. Das Modell zeigt eine beeindruckende Leistung in Mathematik und Codierung und ähnelt seinem Vorgänger OpenAI O1 für verschiedene Bewertungen Ben
 Verbesserung von LLMs mit strukturierten Ausgängen und FunktionsaufrufApr 13, 2025 am 09:45 AM
Verbesserung von LLMs mit strukturierten Ausgängen und FunktionsaufrufApr 13, 2025 am 09:45 AMEinführung Nehmen wir an, Sie interagieren mit einem Freund, der sich ausfasst, aber manchmal fehlen keine konkreten/informierten Antworten oder wenn er/sie nicht fließend reagiert, wenn er mit komplizierten Fragen konfrontiert ist. Was wir hier tun
 15 am häufigsten gestellte Fragen zu LLM -AgentenApr 13, 2025 am 09:41 AM
15 am häufigsten gestellte Fragen zu LLM -AgentenApr 13, 2025 am 09:41 AMEinführung LLM -Wirkstoffe (Language Language Model) sind fortschrittliche KI -Systeme, die LLMs als zentrale Computermotor verwenden. Sie haben die Fähigkeit, bestimmte Aktionen auszuführen, Entscheidungen zu treffen und mit externen Werkzeugen zu interagieren oder
 11 YouTube -Kanäle, um generative KI kostenlos zu lernen - Analytics VidhyaApr 13, 2025 am 09:38 AM
11 YouTube -Kanäle, um generative KI kostenlos zu lernen - Analytics VidhyaApr 13, 2025 am 09:38 AMEinführung Da generative KI die Industrie weiterhin von der Erstellung von Inhalten bis zur Automatisierung neu formuliert, ist das Lernen dieser Technologie für aufstrebende KI -Fachkräfte und Enthusiasten gleichermaßen wesentlich geworden. Mit seinem riesigen Bildungssch


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

MinGW – Minimalistisches GNU für Windows
Dieses Projekt wird derzeit auf osdn.net/projects/mingw migriert. Sie können uns dort weiterhin folgen. MinGW: Eine native Windows-Portierung der GNU Compiler Collection (GCC), frei verteilbare Importbibliotheken und Header-Dateien zum Erstellen nativer Windows-Anwendungen, einschließlich Erweiterungen der MSVC-Laufzeit zur Unterstützung der C99-Funktionalität. Die gesamte MinGW-Software kann auf 64-Bit-Windows-Plattformen ausgeführt werden.

MantisBT
Mantis ist ein einfach zu implementierendes webbasiertes Tool zur Fehlerverfolgung, das die Fehlerverfolgung von Produkten unterstützen soll. Es erfordert PHP, MySQL und einen Webserver. Schauen Sie sich unsere Demo- und Hosting-Services an.

Sicherer Prüfungsbrowser
Safe Exam Browser ist eine sichere Browserumgebung für die sichere Teilnahme an Online-Prüfungen. Diese Software verwandelt jeden Computer in einen sicheren Arbeitsplatz. Es kontrolliert den Zugriff auf alle Dienstprogramme und verhindert, dass Schüler nicht autorisierte Ressourcen nutzen.

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)

Dreamweaver Mac
Visuelle Webentwicklungstools

